alias: Zhu2023a
tags: 超标记 注意力
rating: ⭐
share: false
ptype: article
BiFormer: Vision Transformer with Bi-Level Routing Attention
* Authors: [[Lei Zhu]], [[Xinjiang Wang]], [[Zhanghan Ke]], [[Wayne Zhang]], [[Rynson Lau]]
初读印象
comment:: Biformer通过双层路由利用动态稀疏注意力,通过内容感知更灵活地分配计算。它在粗略的区域级别上过滤掉不相关的键值对,并在其余的候选区域中应用细粒度的token-to-token attention。这种方法可以节省计算和内存,同时保持良好的性能和较高的计算效率。
Why
自注意力的优点:
- 它能够捕捉数据中的长程依赖性
- 它几乎没有归纳偏差,因此使模型更灵活地适应大量数据
自注意力的缺点:
- 由于注意力计算的是所有空间位置的成对标记亲和性,因此计算复杂度高,内存占用大
- 稀疏注意力使用不同的策略来合并或选择键/值标记,但要么使用手工制作的静态模式,要么在所有查询中共享键值对的采样子集。然而,根据预训练的 ViT和 DETR的可视化结果,不同语义区域的查询实际上关注的键值对大相径庭。因此,强迫所有查询都关注同一组标记可能不是最佳选择。
 ###What
###What
Bi-Level Routing Attention
在粗略的区域级别上过滤掉大部分无关的键值对,从而只保留一小部分路由区域。然后,在这些路由区域的结合部应用细粒度的token-to-token- attention。复杂度为:
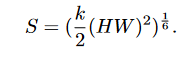
Region partition and input projection
给定2D特征图\(X\in R^{H\times W\times C}\),切割成\(S\times S\)的非重叠区域,得到\(X^r \in R^{S^2\times \frac{HW}{S^2}\times C}\)。
利用线性映射
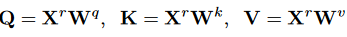 得到
得到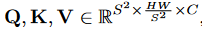
Region-to-region routing with directed graph
通过构建一个有向图寻找注意关系。
首先对\(Q,K\)做区域平均池化得到区域级query和key:
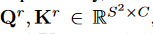 得到区域亲和矩阵\(A^r\in R^{S^2\times S^2}\)用于衡量两个区域在语义上的相关程度。:
得到区域亲和矩阵\(A^r\in R^{S^2\times S^2}\)用于衡量两个区域在语义上的相关程度。:
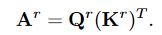
剪切亲和图,只保留每个区域的前 k 个连接,得出路由索引矩阵\(I_r \in N^{S^2 \times k}\)
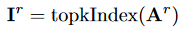 \(I_r\)的第 i 行包含与第 i 个区域最相关的 k 个区域的索引。
\(I_r\)的第 i 行包含与第 i 个区域最相关的 k 个区域的索引。
Token-to-token attention
收集key和value的向量:\(K^g,V^g\in R^{S^2\times \frac{kHW}{S^2}\times C}\)
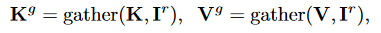
做自注意力
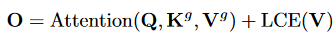 LCE是一个depth-wise卷积。
LCE是一个depth-wise卷积。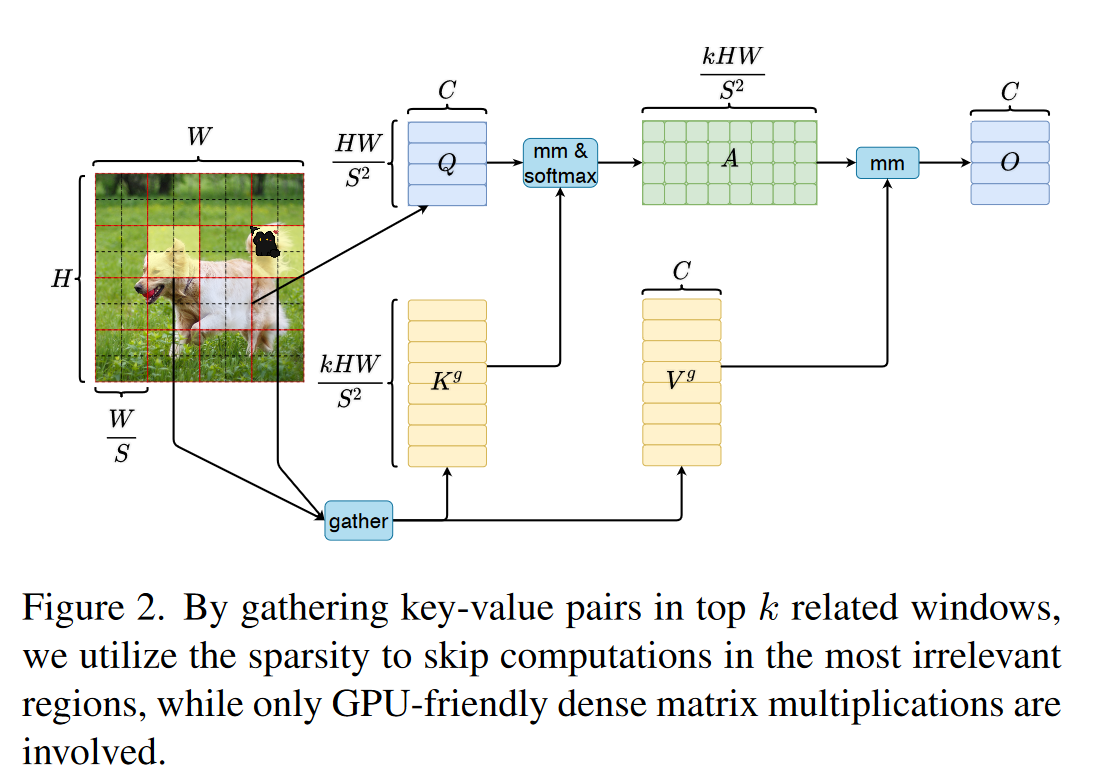
Overall Architecture
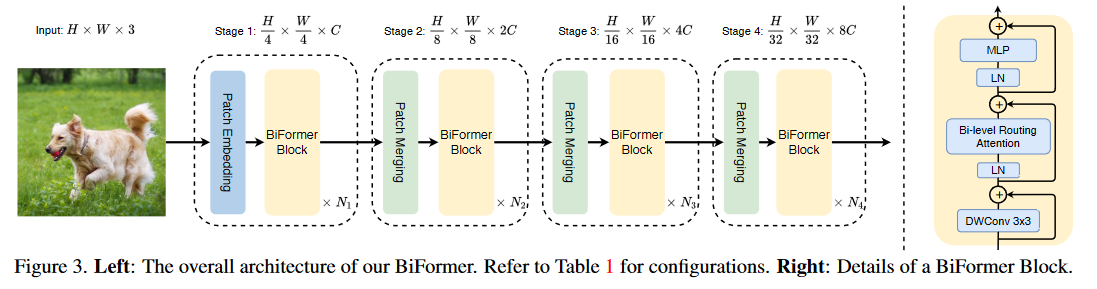 ###How
###How
- 轻量 Transformer 标记 Attention BiFormer轻量transformer标记attention transformer attention need all cross-attention classification multi-scale transformer crossformer cross-scale transformer attention transformer attention vision论文 self-attention transformer attention网络 transformer attention mlps bert 轻量 轻量级transformer视觉 biformer attention