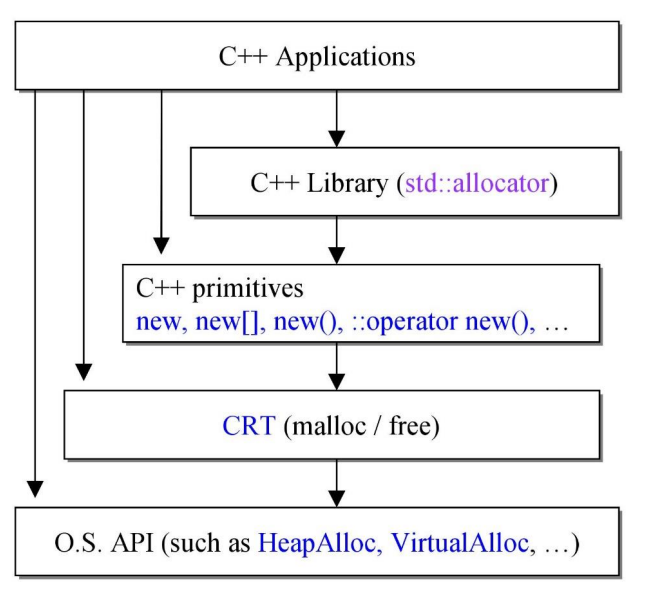
从内核到C++应用
整个系统的不同层级有着不同的内存管理器。
- linux内核: 伙伴系统(以页为单位进行管理)、slab分配器(定制化的内存管理器)。
- malloc\free库函数:使用系统调用mmap、sbrk,以及bins管理多个空闲链表(内存池)。有合并空闲块的操作。有两种方式管理内存:
- 如果分配内存大于mmap分配阈值(见下一节),直接使用mmap分配;如果释放的内存大于mmap分配阈值,直接使用mummap释放,直接返还给操作系统
- 否则,通过内存池分配算法分配,且用户层free的内存块,不一定立刻返回给操作系统,而是缓存在内存池中以供后续的请求。
- C++ stl分配器:16个链表,分别管理16种小于128 B的对象(内存池),没有合并空闲块操作,如果分配\释放的内存大于128B直接调用malloc\free交由库函数处理。

glibc 内存管理
参考资料:
glibc的malloc和free使用的ptmalloc实现,详见这篇文章的解析:Glibc内存管理 —— 华庭
首先,glibc的设计假设是这样的,我把我觉得比较重要的内容高亮了出来:

“malloc如果分配的内存大于128KB,则使用mmap分配内存,否则使用sbrk分配内存”。正确吗?
这句话并不绝对正确,如上图所示,使用mmap分配的阈值是动态变化的,因此不一定分配128KB的malloc请求一定会使用mmap系统调用。请参考下图,假设malloc的初始mmap阈值为128KB,表示分配内存大于128KB时直接使用mmap而不用通过内存池机制;如果某一时刻释放了一个大于128KB的页,比如256KB,那么mmap阈值将被调整为256KB,表示分配内存大于256KB时才使用mmap,此时如果分配的内存大小为128KB,那么这个请求还是会走内存池机制,而且释放128Kb的内存块时也不会使用mumap直接将其返还给操作系统了。当然mmap阈值不能无限增加,见下图的描述。

而且通过mmap分配的内存如果被释放了,那么这片地址就直接返回给操作系统了,如果再次引用这篇地址,则会引发segmentation fault
glibc内存池机制
除了使用mmap分配大内存块,glibc还有一种内存池机制,使用一种chunk的数据结构来管理堆内存。chunk结构中包括用户数据,以及为了维护内存池的一些其他信息(比如下一个chunk的指针、本chunk的大小等),在侯捷老师的课程中,这些除用户信息以外的管理信息被称作cookie,在glibc中以32位系统为例,每个chunk的cookie大小位16B。
空闲的chunk使用bins来管理。用户free掉的内存并不会马上归还给操作系统,而是缓存在各种bin中。ptmalloc会统一管理 heap 和 mmap 映射区间的空闲chunk,当用户需求来临时,它首先在bins中找到空闲的chunk返回给用户,如果找不到则使用系统调用再向操作系统申请内存。这样就避免了频繁的系统调用,较少分配开支。
bins有很多种:
- fast bins, 存放大小小于等于64B的chunk, 这个bin是为了加快热点小内存块的分配
- unsorted bins,可以看做是 bins 的一个缓冲区,增加它只是为了加快分配的速度
- small bins,有62种规格,每一种规格相差8B,(16B - 576B),每个small bin管理的chunk大小都相同
- large bins,有63个,每个bin都管理在一定范围内的内存块,也就是说每个large bin种的chunk大小不同,但是会按照大小从大到小排列。
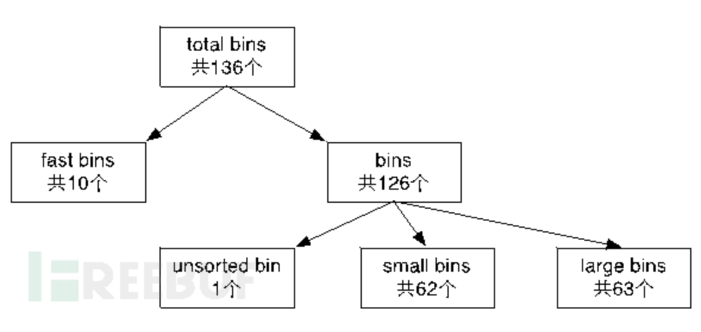
还有两种不属于任何bin的chunk:
- mmaped chunk: 直接使用mmap分配的内存块,在释放时使用ummap直接返还给操作系统
- top chunk: heap最高处的一块空闲chunk,它的大小是随着分配和回收不停变化的。
具体的分配和回收算法参考Glibc内存管理 —— 华庭 3.2.4和3.2.5节。
那么,通过内存池分配的内存会返还给操作系统吗?什么情况下会返还?
还是在上面的参考资料的3.2.5节的free流程中有详细解释:

简单讲,就是在free时会判断释放块前后是否有空闲块,如果有则迭代地进行合并,如果最后合并到到的空闲块与topchunk相邻(topchunk是一定为空闲的),那么将它与topchunk合并,如果合并而得的topchunk大于mmap的收缩阈值,则归还topchunk中的一部分给操作系统。
从这里可以隐隐看出 Glibc内存管理 —— 华庭 这篇文章中提到的内存暴增问题的一个原因了:
-
收缩内存(将内存归还给操作系统)是从topchunk开始的,
如果topchunk相邻的chunk不是空闲的,那么topchunk以下的chunk都不能归还给操作系统,因此会堆积越来越多的空闲chunk而不返还给操作系统。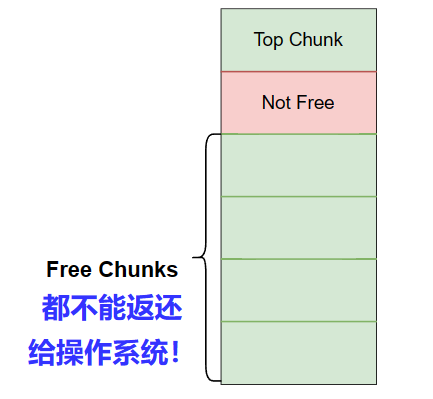
-
一种缓解方法:绕过glibc的内存池系统,每次分配的内存都大于等于mmap分配阈值的最大值(在64为系统上是32MB),那么malloc将直接使用mmap分配内存,且free时一定会将内存返还给操作系统。这样的话malloc\free就是mmap和mumap系统调用的简单封装,可以考虑直接使用系统调用mmap和mumap进行内存分配管理。
C++ primitives
参考资料:
- 侯捷老师的视频讲解
new delete表达式

new表达式(new后不加其他任何参数)会被编译器转化为两个步骤
- 调用operator new 分配内存,调用的函数版本为(
operator new(size_t)),对象大小由编译器算出并自动传入 - 然后调用对象的构造函数,在得到的内存上创建object
此外,operator new 可能抛出异常,需要用try catch处理异常。
而operator new 内部直接调用C运行库的 malloc, 当内存分配失败时,执行_callnewh, 这个函数主要释放一些内存,看看能不能空出一些来给新对象
如果operator new函数分配内存成功了,但是构造函数却抛出异常。这时候,就要取消第一个步骤中分配的内存,否则就会导致内存泄漏。
这个责任落在C++运行库上,由它调用相应的operator delete(什么叫相应的delete,见effective C++,条款52)取消已经分配的内存。
delete表达式会也被编译器转化为两个步骤
- 调用对象的析构函数,调用的函数版本为(
operator new(size_t)) - 调用 operator delete
operator delete内部调用C运行库的 free 释放内存

array new
使用了array new 之后就要使用array delete,否则就会只调用一次析构函数,这样有可能发生内存泄漏,仅限于class with pointer member 的对象,见下图示意。泄漏的内存不是array本身,而是array的元素所指向的内存。
下图的cookie大多是记录了array new 操作分配了多少个objext
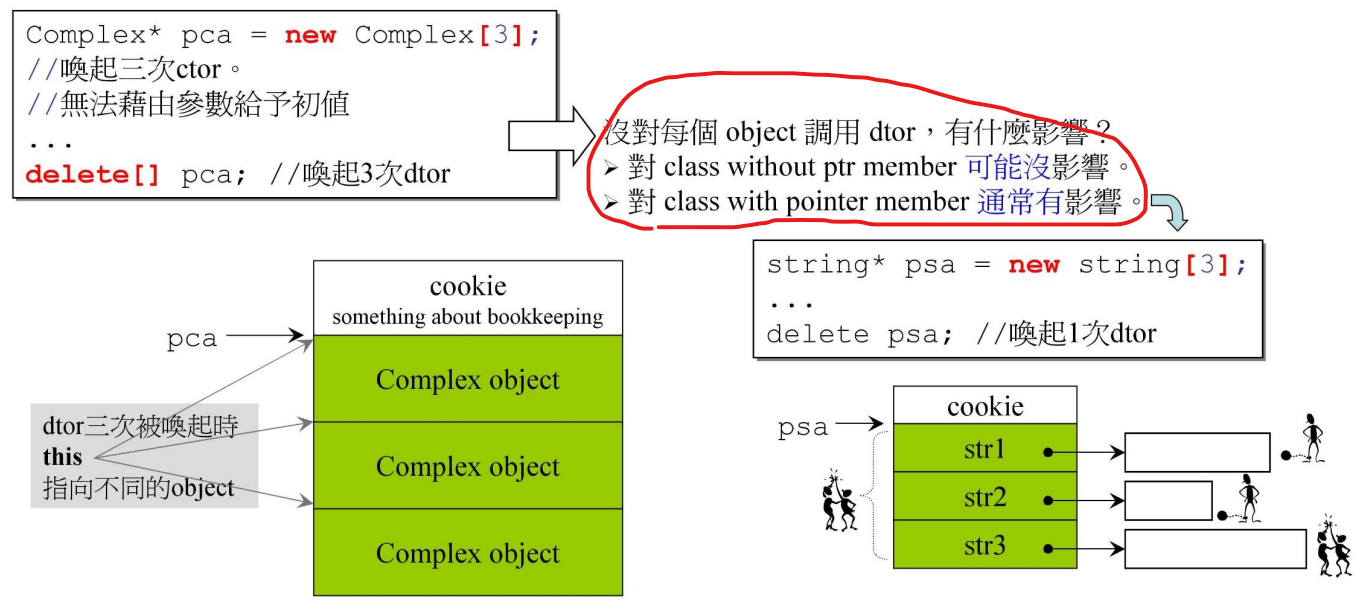
如果
int* p = new int[10] // array new
delete p // 但不 array delete
或者向上图那样的无指针成员的对象Complex,不会造成内存泄漏。
palcement new
operator new函数如果接收的参数除了一定会有的哪个size_t之外,如果还有其他参数,那么它就属于placement new(见重载oeprator new 一节)
placement new 等同于直接调用构造函数,不会像new 表达式那样先分配内存。
// 像这样使用placement new
char* buf = new char[sizeof(Complex)]; // 首先分配内存
Complex* p = new(buf)Compelx(1,1) // new后传入参数buf指针,表示在这个地址上构造Complex(1,1)
重载operator new
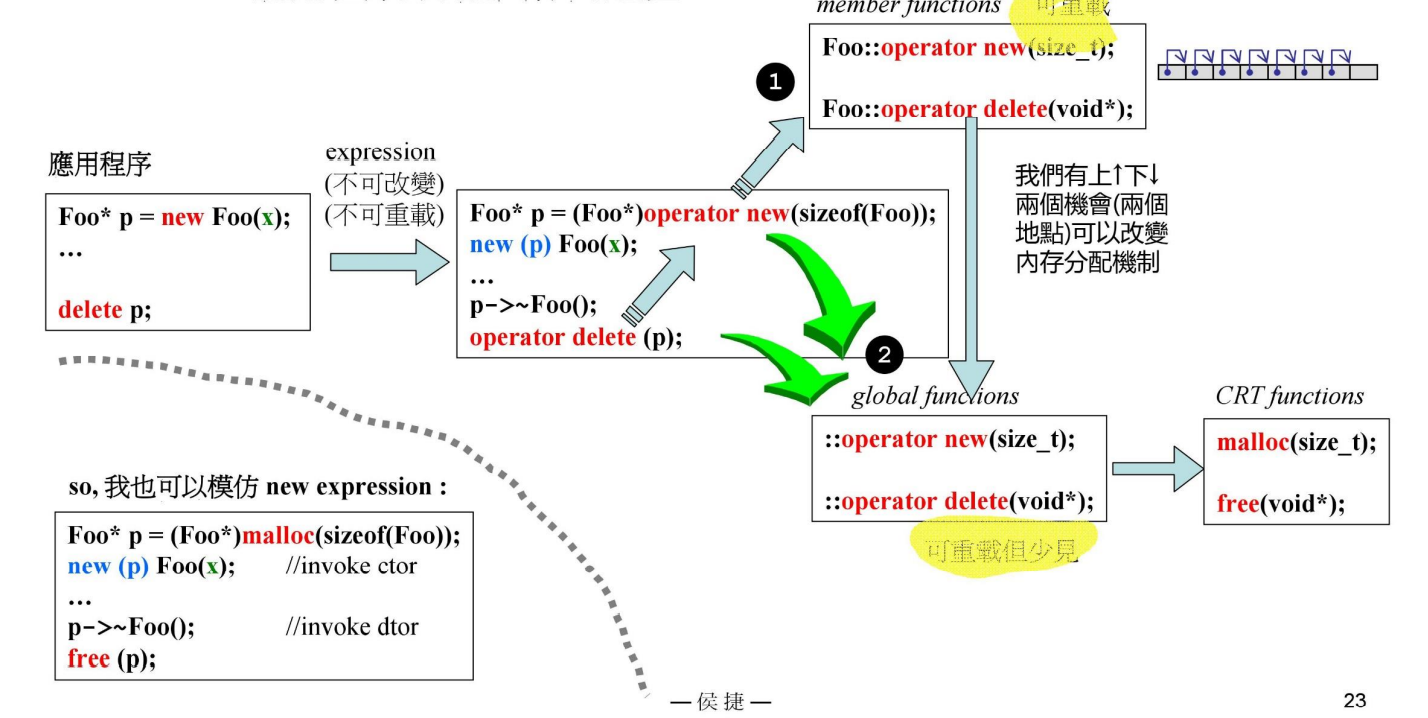
new表达式内部调用 operator new 函数,侯捷老师说我们可以在两个地方重载operator new 函数来实现自己的内存分配函数。
一开始不理解什么较做“在两个地方”,后来查了些资料明白了这与C++的名称查找规则(Name lookup rule)有关。当C++编译器在class scope内碰到一个name后,首先在class内搜寻这个name,看看有没有它的declaration,如果没有再去全局域找找。
因此,如果我们在类内重载了operator new,那么全局的operator new根本不会被搜寻,更不用说执行了。
相比重载全局的operator new,重载class scope的做法更安全些。
下例摘自 cppreference,注意类内的operator new函数一定是static的,无论定义式加不加static关键词,编译器一律视类内的operator new函数为static
operator new 函数的参数一般是对象的大小,当我们写 new Obj() 时, Obj对象的大小会自动被当作operator new的第一个参数。
struct X
{
static void* operator new(std::size_t count)
{
std::cout << "custom new for size " << count << '\n';
return ::operator new(count); // 调用全局的operator new
}
static void* operator new[](std::size_t count)
{
std::cout << "custom new[] for size " << count << '\n';
return ::operator new[](count);//// 调用全局的operator new
}
};
int main()
{
X* p1 = new X;
delete p1;
X* p2 = new X[10];
delete[] p2;
}
也可以在重载函数中直接调用malloc,而不使用全局operator new,因为operator new只是分配了内存我们自己可以实现它。如果对应构造函数也不抛出异常,那么整个new表达式就不会抛出异常!(前面说过,new 表达式会转化为 1.operator new,分配内存 + 2.调用构造函数两部,其中全局operator new会有异常的抛出)
struct X
{
static void* operator new(std::size_t count)
{
std::cout << "custom new for size " << count << '\n';
return malloc(count);
}
static void* operator new[](std::size_t count)
{
std::cout << "custom new[] for size " << count << '\n';
return malloc(count);
}
};
我们可以重载多个operator new 版本:

其中第一个版本就是new 表达式(new后不加任何其他参数)会自动转化成的版本
注意当在class内声明operator的各种函数时,可能会被继承增加复杂性
class Base {
public:
static void* operator new(size_t size) throw(std:: badalloc){
// 一些针对Base Class的操作
}
...
};
public Derived {
public:
// 未申明operator new ,从分类继承operator new
}
这样当new一个Derived对象时,调用的是Baseclass中定义的operator new,二这可能带来很多不确定因素。
解决这样的做法是在Baseclass的operator new中加入判断 size是否等于Baseclass大小的逻辑
class Base {
public:
static void* operator new(size_t size) throw(std:: badalloc){
if (size != sizeof(Base)) { // 如果创建的不是Basevlass对象
return ::operator new(size); // 转发至全局的operator new 函数
}
}
...
};
这样当使用BaseClass定义的operator new 函数去分配一个Derived对象时,改用全局operator new 函数,这样可万无一失。
GNUC 2.9版本std::alloc
主要看SGI的实现,有两个空间配置器
- _malloc_alloc_template<0>
- __default_alloc_template<...>
用户可以选择单独使用第一个分配器,或者一起使用两个分配器。
当用户选择使用两个分配器时,编译器会分别将上述两个分配器typedef成 malloc_alloc 和 alloc, 容器的分配器默认使用alloc,即第二个分配器。
两个配置器的接口都有allocate() deallocate() reallocate(),这里主要聚焦于前两个接口。
第一个配置器(malloc_alloc)的allocate()从typedef的名字上可以看出,它只是简单调用malloc(), deallocate()也只是简单调用free(),唯一的特别之处是,这个配置器能够模拟C++ new 运算符的set_new_handler()以处理内存不足的情况。
而第二个配置器(alloc), 当内存小于128字节时则由自己管理这些内存块,会自己管理一个内存池;当分配的内存大于128字节时,直接调用malloc::allocate()。如果系统空间不足,那么也调用malloc::allocate(),因为它有处理程序处理内存不足的情况。
为什么对于小于128bytes的内存块使用内存池来管理?
1.防止内存碎片
2.若使用malloc直接分配的内存,每块都带有一些cookie,若小内存偏分配次数多,那么cookie的占用空间相比于有用空间会很大,空间利用率不高。
alloc配置器如何管理内存池?这里只记个大概,细节看书。
alloc管理一个16个长度的数组,数组的每个元素都指向一个free_list, 每个free list都管理一种大小的空闲数据块。
内存块大小有8bytes 、16bytes、24bytes ... 128bytes。 因此一共要16个free list来进行空闲块的管理。
最初,alloc的内存池空无一物,当有请求来时,比如要申请8字节的空间,就调用malloc向系统申请空间大小为8 * 40,将其中的1块返回给用户,其中19块做切割处理后交给对应的free list管理,剩余的20块留给内存池的备用。当再有8字节申请时,则直接从这个free list中拨给用户空闲空间。当有16字节申请时,从内存池中的备用空间中找空闲内存,如果不够则再调用malloc重复刚刚的操作,但是在当前情景中,确实是存在备用内存的(刚刚分配8字节内存时剩余的20块)。
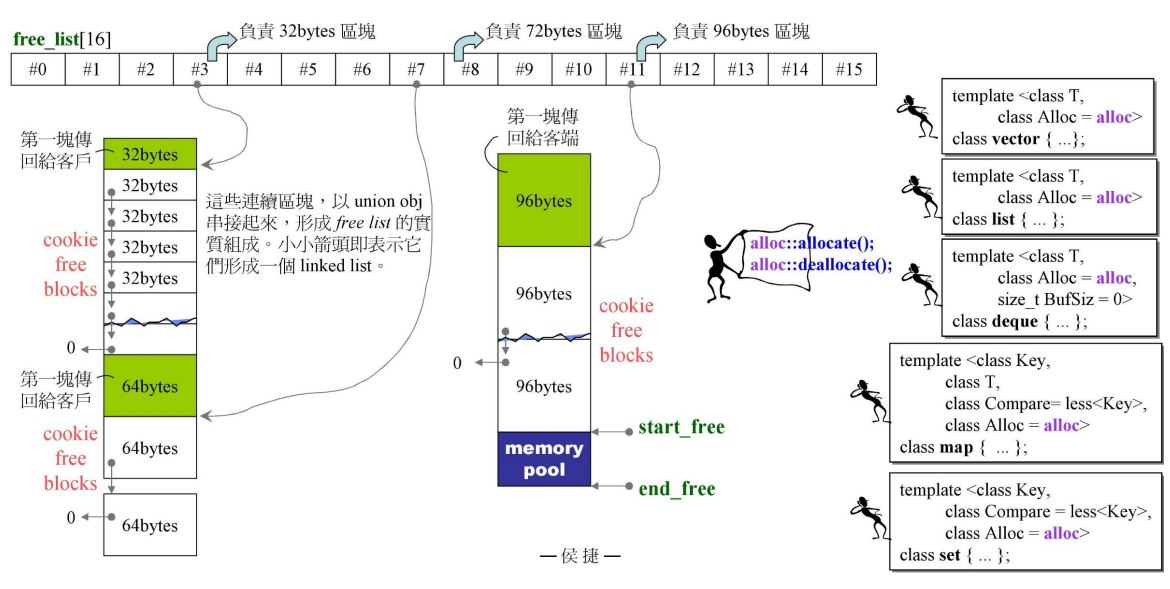
容器使用该分配器分配内存,而不是直接用malloc向操作系统索要,这样会节省很多存放cookie的内存空间。
处理内存申请时,如果申请的内存块小于128bytes, alloc将从以下几方面递进式地申请内存
- 首先看看对应freelist有无空闲空间
- alloc的内存池的备用内存是否有空余块(end_free - start_free)
- 如果没有,则使用malloc向系统申请内存
- 如果malloc还失败了,那么再看看其他freelist是否还有没有划分出去的内存块
- 最后,已然山穷水尽,调用malloc_alloc(第一个配置器)的allocate()看看它的 handler 处理程序能否空出一些内存
有几个问题值得探讨
- sgi版本的stl管理内存的方式乍一看和linux内核的伙伴系统很像,但是stl内存池根本不涉及连续内存块合并的操作,也就是说没有伙伴的概念
- 内存池管理的内存在程序运行期间,并没有被调用free()库函数,因为如果要free,则必须要传回紧挨着cookie之后的那根指针,但是这根指针在分配过程中早已丢失。所以也更谈不上这些内存会归还给操作系统了。