向量检索
这篇文章主要介绍一些向量检索的常用方法
向量检索主要分为两种情况,分别为NN和ANN
首先是最近邻NN,时间复杂度为\(O(ND)\)
其中N为向量的个数,D为向量的维度,运算速度较慢
ANN通过牺牲一部分的内存和内存占用等,换来更快的检索速度(不一定是最近似的,比较近似的即可)
NN和ANN可应用在CV向量检索等多个方面
根据向量个数的规模,解决办法小结如下所示:
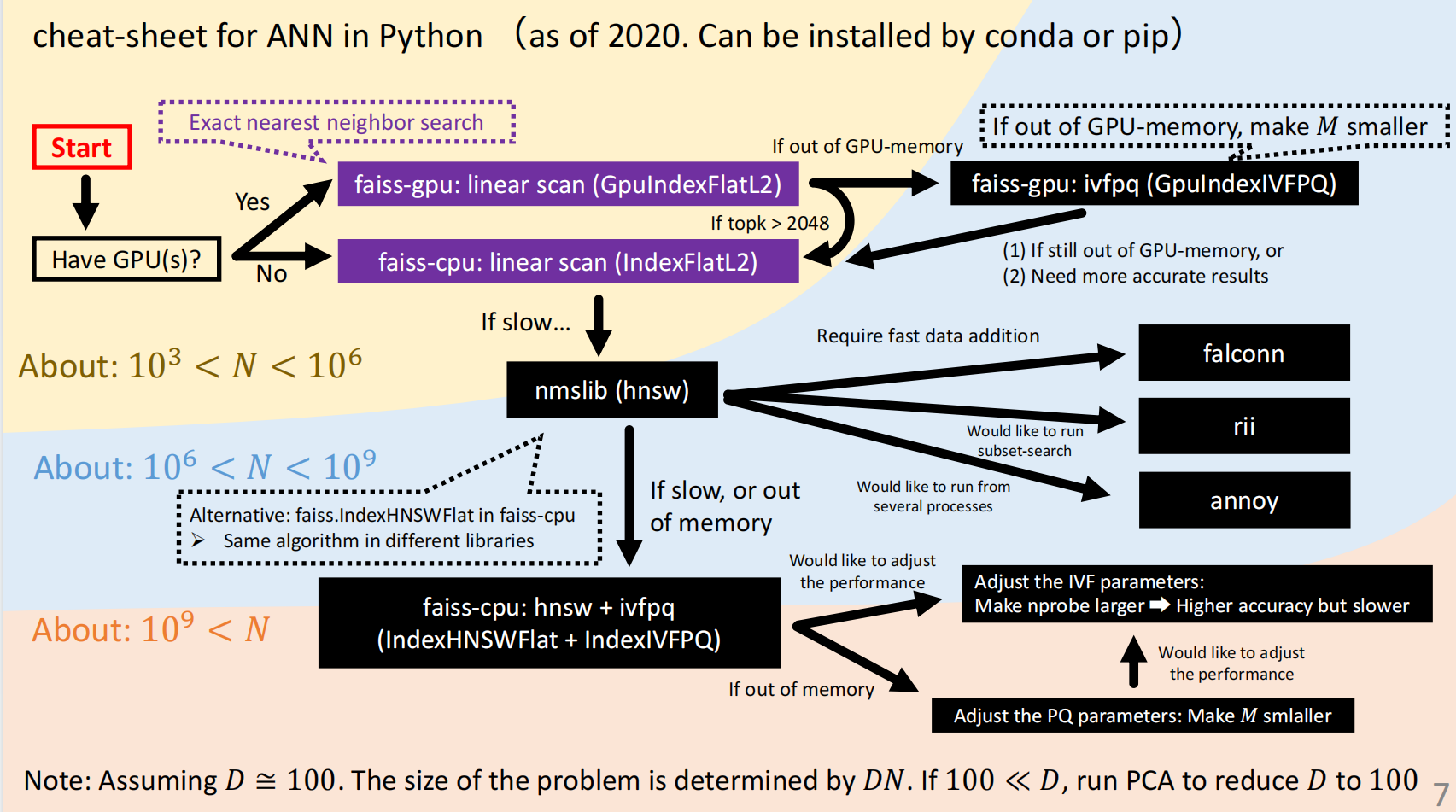
注意向量的维度限制
接下来介绍向量检索的两种思路
Part 1: Nearest Neighbor Search
介绍一下需要解决的问题和基本思路:

faiss为facebook为了向量检索做的包,不同规模问题用不同方法去解决,并充分发挥了GPU等方面的优势
当\({M<20}\)的时候,采用SIMD(单指令流多数据流),基本过程如下所示:
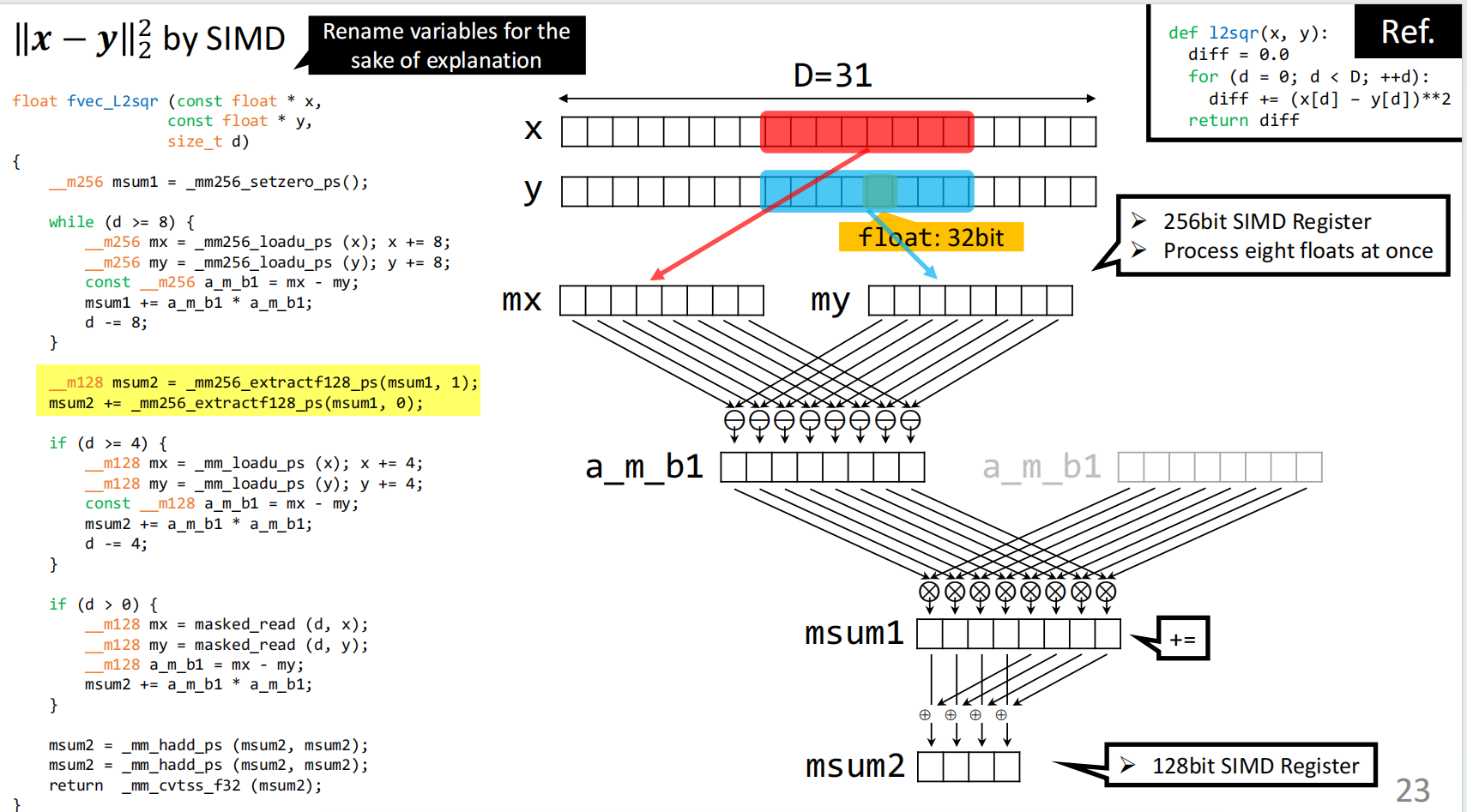
充分提升了并行性,在计算距离的过程中提升了差不多8倍的效率。
当\({M\geq 20}\),采用矩阵乘法的方式,并且将其部署在GPU上加速运算效率
如下图所示:

将该算法部署在GPU上差不多可以提升10倍。
Part 2: Approximate Nearest Neighbor Search
整体思路如下所示:
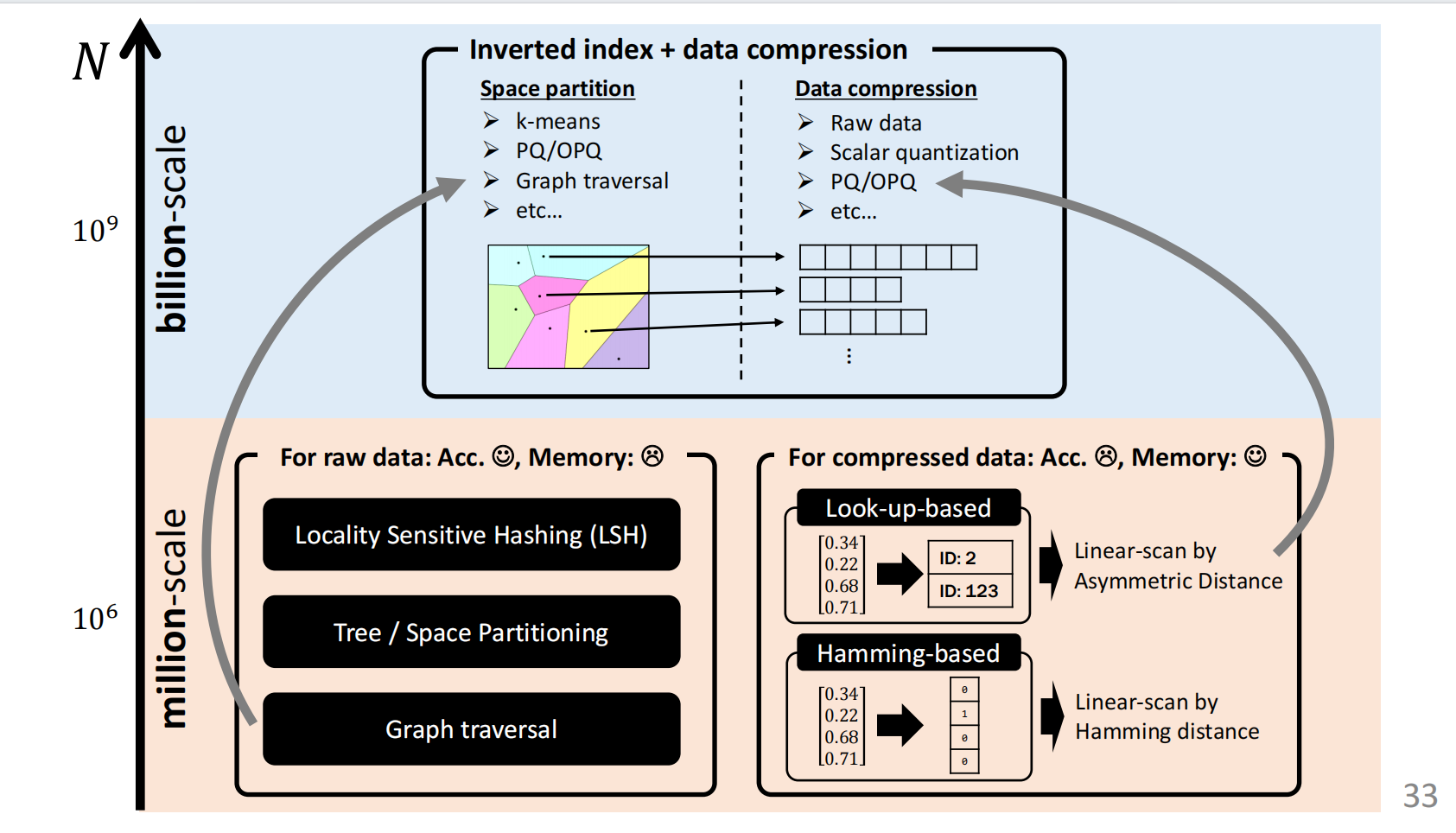
主要划分为millon和billon两个数量级,整体思路也分为空间分割识别和数据压缩两种思路。
哈希的基本思路,也比较简单,如下所示:
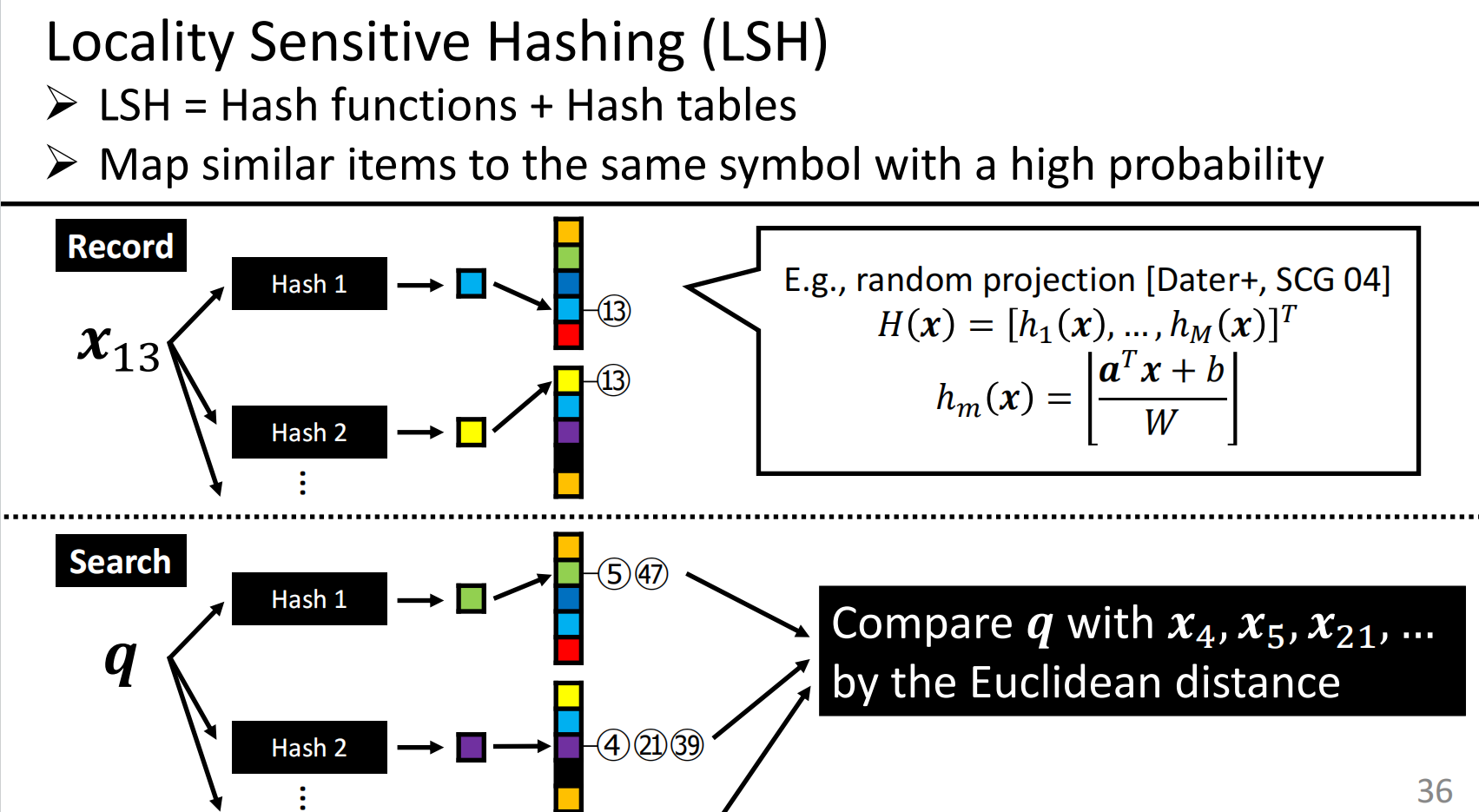
原始数据的存储也需要额外的内存,也需要一些哈希表来提升精度,
效果并不是很理想。Falconn在此基础上提出了改进,在此不再赘述。
FLANN(Fast Library for ANN)
基于KD树的思想,检索速度快,但是原始数据的存储占用内存大。
Annoy和KD树类似,但是通过随机取点划分空间再检索,需要的参数很少
但是也是需要大规模的内存消耗,速度也比NSW和HNSW更慢。
接下来介绍重量级的方法