1. 一阶段和二阶段目标检测
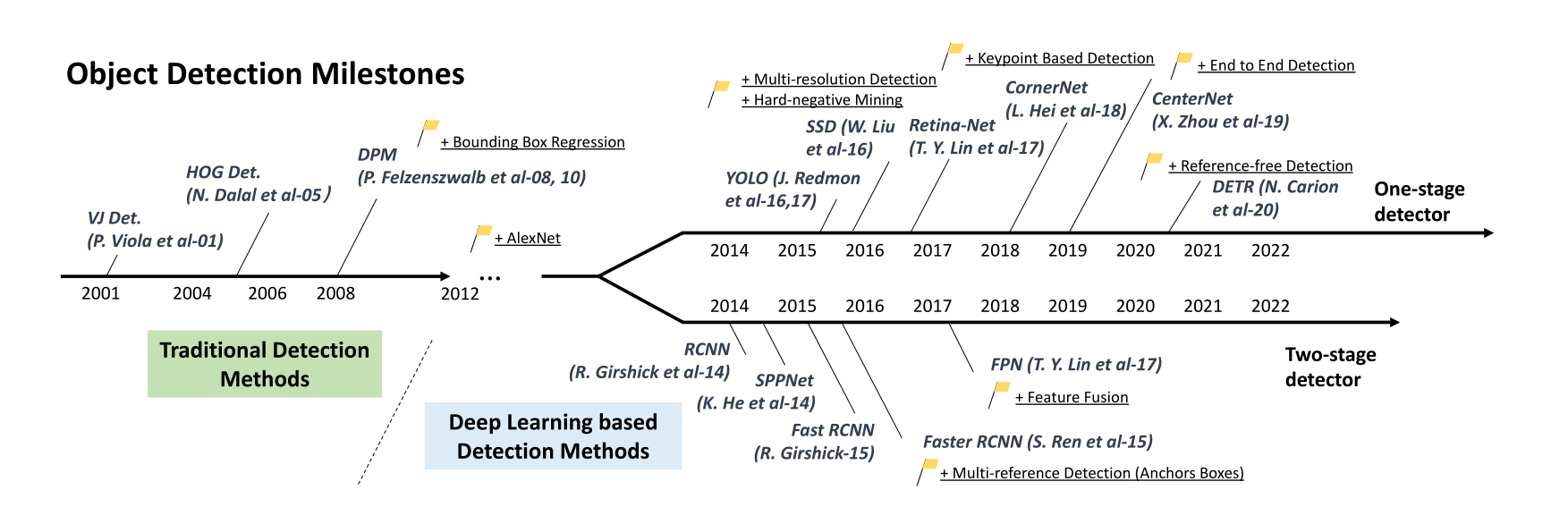
一阶段:直接输出,端到端
二阶段:先提取候选框,再分析甄别
histogram of oriented gradient,HOG
scale invariant feature transform,SIFT
单发多框检测与区域卷积神经网络(R-CNN)也存在以下主要区别:
1. 检测方式不同:- 单发多框检测:先生成大量anchor box,然后判断每个anchor box中的前景物体,并调整框位置。
- R-CNN:先使用选择性搜索等方法生成大量区域提议,然后判断每个提议框中的前景物体。
2. 训练过程不同:- 单发多框检测:anchor box是手动设定的,直接用于训练。训练时同时进行分类和边界框回归。
- R-CNN:区域提议来自于独立的方法。首先使用CNN提取每个提议的特征,然后进行SVM分类和边界框回归。训练分两步进行。
3. 预测速度不同:- 单发多框检测:在特征提取之后直接进行预测,速度较快。
- R-CNN:需要先生成大量区域提议,然后再进行CNN特征提取和SVM判断,速度较慢。
4. 框回归方式不同:- 单发多框检测:直接调整anchor box的位置,回归方式较简单。
- R-CNN:通过SVM分类得到正样本提议框,然后执行ConvNet框回归,得到更加准确的框坐标。
总体来说,单发多框检测的思路更加简单高效,利用固定的anchor box直接进行训练和预测,较易于实时化。而R-CNN采用较为复杂的两步训练方式,预测速度较慢,但是通过更为精确的框回归可以得到更高的检测精度
2. 计算机视觉能解决哪些问题:
分类,classification
检测,object Detection 能够区分出来不同类别
分割,更细粒度的抠图
语义分割 (像素分类,不区分同一类)与实例分割(同一个实例的不同类别区分出来,区分)
自动驾驶,全景分割,看到的所有像素都做实例分割
Object Detection in 20 Years: A survey
DPM:HOG 模板滑动(人工设计)窗口,符合模板特征
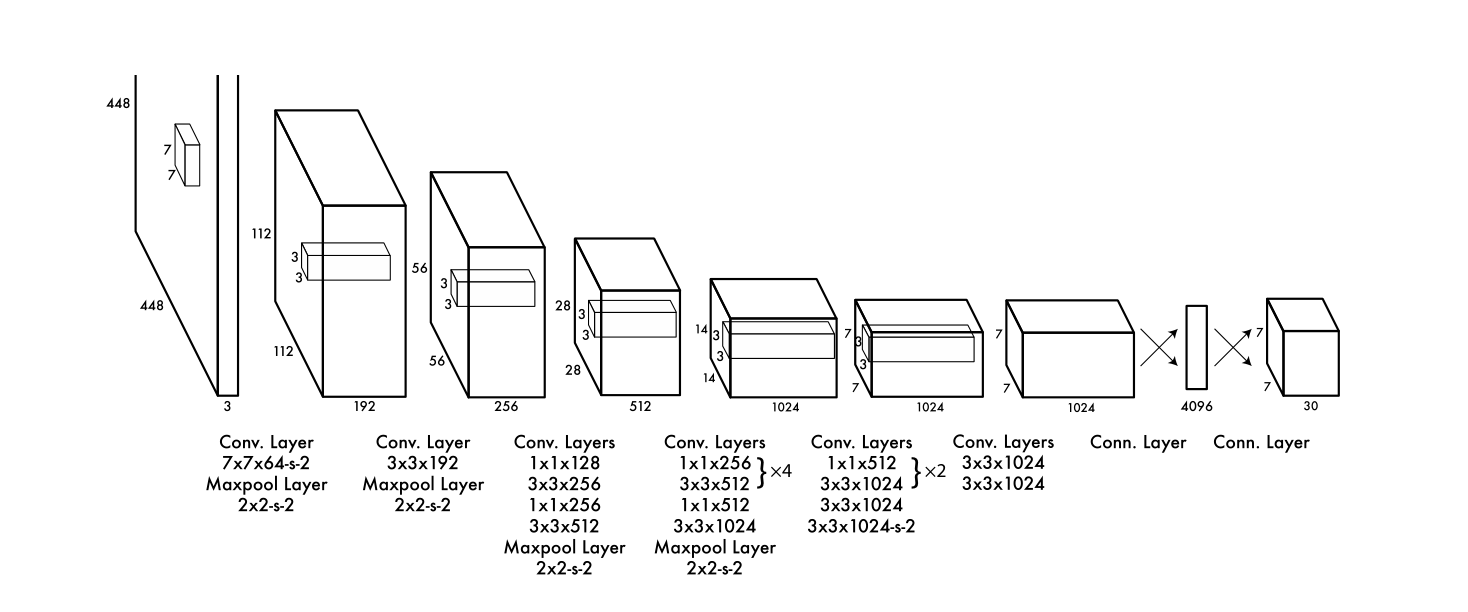
3. YOLO V1
框架: 1. 缩放图片 2. 卷积网络 3. Non-max supperession 后处理,conf过滤-> 非极大值抑制
预测阶段