01 什么是 Disruptor
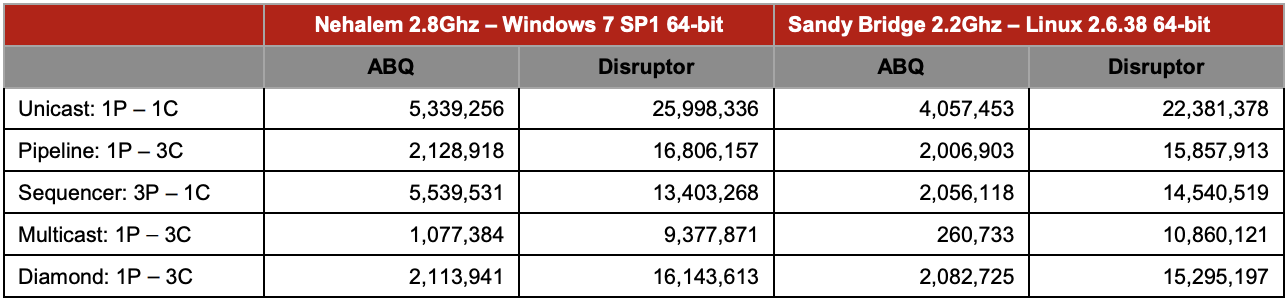
disruptor 是 lmax 开源的一个高性能并发内存队列,和日常使用的 ArrayBlockingQueue 的性能对比如下图
02 高性能的原因
2.1 避免伪共享内存
什么是 CPU 高速缓存?
首先介绍一下 CPU 缓存的定义:
在计算机系统中,CPU高速缓存(英语:CPU Cache,在本文中简称缓存)是用于减少处理器访问内存所需平均时间的部件。
当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。
— 维基百科
CPU 缓存图如下:
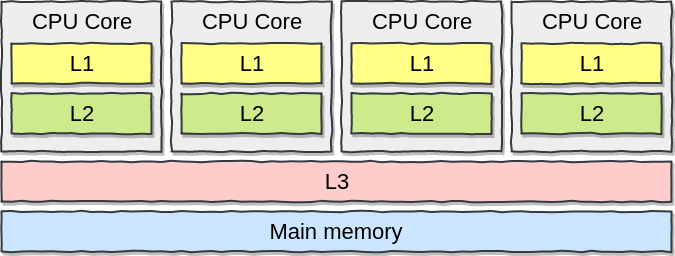
当 CPU 想要从 Main memory 读取数据的时候,会先看一下 L1 缓存中是否存在,若不存在则查看 L2 缓存是否存在,若 L2 和 L3 缓存都不存在时,才从 Main memory 读取数据,从 Main memory 读取数据后,CPU 会将数据缓存至 L1、L2、L3 中。离 CPU 越近,读取速度越快,其中 L1 缓存的效率是 Main memory 的 60 倍。
什么是缓存行 (Cache Line)
Cache Line 是 cache 和 Main memory 之间转换的最小单位,目前大部分 CPU 的 Cache Line 的 64 byte,这代表 CPU 读取内存数据的时候,不是一个个读取,而是一次性读取整个 Cache Line
一个 Java 的 long 类型是 8 字节,因此在一个缓存行中可以存 8 个 long 类型的变量。
试想一下你正在遍历一个长度为 16 的 long 数组 data[16],原始数据自然存在于主内存中,访问过程描述如下
- 访问 data[0],CPU core 尝试访问 CPU Cache,未命中
- 尝试访问主内存,操作系统一次访问的单位是一个 Cache Line 的大小 — 64 字节,这意味着:既从主内存中获取到了 data[0] 的值,同时将 data[0] ~ data[7] 加入到了 CPU Cache 之中,for free~
- 访问 data[1]~data[7],CPU core 尝试访问 CPU Cache,命中直接返回。
- 访问 data[8],CPU core 尝试访问 CPU Cache,未命中。
- 尝试访问主内存。重复步骤 2
伪共享内存
伪共享指的是多个线程同时读写同一个缓存行的不同变量时导致的 CPU 缓存失效。
假如有两个变量 x 和 y 被两个不同 CPU 调度的线程访问,x 和 y 刚好在同一个 Cache Line 中,第一个线程修改了变量 X,然后第二个线程修改变量 y 的时候,发现 Cache line 被标记无效了,第二个线程需要再次从 Main memory 中读取数据。也就意味着,频繁的多线程操作,CPU 缓存将会彻底失效,降级为 CPU core 和主内存的直接交互
Disruptor 如何解决伪共享内存
通过字节填充解决伪共享内存,即一个变量只存在于一个 Cache line 中
具体如下:
在 Disruptor 中定义了一个用于填充 Cache Line 的抽象类 RingBufferPad
/*
* 填充辅助类,为解决缓存的伪共享问题,需要对每个缓存行(64B)进行填充
*/
abstract class RingBufferPad
{ // https://github.com/LMAX-Exchange/disruptor/issues/167
/*
RingBufferFields中的属性被频繁读取,这里的属性是为了避免RingBufferFields遇到伪共享问题
*/
protected long p1, p2, p3, p4, p5, p6, p7;
}
abstract class RingBufferFields<E> extends RingBufferPad {
private static final int BUFFER_PAD; // 用于在数组中进行缓存行填充的空元素个数
private static final long REF_ARRAY_BASE; // 内存中引用数组的开始元素基地址,是数组开始的地址+BUFFER_PAD个元素的偏移量之和,后续元素的内存地址需要在此基础计算地址
private static final int REF_ELEMENT_SHIFT; // 引用元素的位移量,用于计算BUFFER_PAD偏移量,基于位移计算比乘法运算更高效
private static final Unsafe UNSAFE = Util.getUnsafe(); // 上面的变量都是为了UNSAFE的操作
static {
final int scale = UNSAFE.arrayIndexScale(Object[].class); // arrayIndexScale获取数组中一个元素占用的字节数,不同JVM实现可能有不同的大小
if (4 == scale) {
REF_ELEMENT_SHIFT = 2;
} else if (8 == scale) {
REF_ELEMENT_SHIFT = 3;
} else {
throw new IllegalStateException("Unknown pointer size");
}
BUFFER_PAD = 128 / scale; // BUFFER_PAD=32 or 16,为什么是128呢?是为了满足处理器的缓存行预取功能(Adjacent Cache-Line Prefetch)
// https://github.com/LMAX-Exchange/disruptor/issues/158
// https://software.intel.com/en-us/articles/optimizing-application-performance-on-intel-coret-microarchitecture-using-hardware-implemented-prefetchers
// Including the buffer pad in the array base offset
// BUFFER_PAD << REF_ELEMENT_SHIFT 实际上是BUFFER_PAD * scale的等价高效计算方式
REF_ARRAY_BASE = UNSAFE.arrayBaseOffset(Object[].class) + (BUFFER_PAD << REF_ELEMENT_SHIFT);
}
private final long indexMask; // 用于进行 & 位与操作,实现高效的模操作
private final Object[] entries;
protected final int bufferSize;
protected final Sequencer sequencer; // 生产者序列号
// 省略...
}
public final class RingBuffer<E> extends RingBufferFields<E> implements Cursored, EventSequencer<E>, EventSink<E>
{
public static final long INITIAL_CURSOR_VALUE = Sequence.INITIAL_VALUE; // 游标初始值 -1
protected long p1, p2, p3, p4, p5, p6, p7;
}
RingBufferFields 继承了 RingBufferPad 类,RingBuffer 继承了 RingBufferFields 类,并且 RingBuffer 中也有 7 个没有任何作用和读写请求的 long 类型的变量, RingBuffer 里面的 indexMask 这些字段前后,各定义了 7 个没有任何作用和读写请求的 long 类型的变量。
这样,无论在内存的什么位置上,这些变量所在的 Cache Line 都不会有任何写更新的请求。我们就可以始终在 Cache Line 里面读到它的值,而不需要从内存里面去读取数据,也就大大加速了 Disruptor 的性能。
| 属性类型 | 属性名 | 字节数 |
|---|---|---|
| long | p7 | 8 |
| long | p6 | 8 |
| long | p5 | 8 |
| long | p4 | 8 |
| long | p3 | 8 |
| long | p2 | 8 |
| long | p1 | 8 |
| ref | sequencer | 4/8 |
| int | entries | 4 |
| ref | entries | 4/8 |
| long | indexMask | 8 |
| long | p7 | 8 |
| long | p6 | 8 |
| long | p5 | 8 |
| long | p4 | 8 |
| long | p3 | 8 |
| long | p2 | 8 |
| long | p1 | 8 |
2.2 无锁
加锁的影响
在线程修改数据的时候的操作步骤如下:
- 将数据从主内存缓存在 CPU 高速缓存中
- 在 CPU进行计算时,直接从高速缓存中读取数据并且在计算完成之后写入到缓存中。在整个运算过程完成后,再把缓存中的数据同步到主内存。
由于步骤 1 和 步骤 2 不是原子性操作,假如有两个线程同时将变量 X 的值加 1,线程 A 和 线程 B 同时读到变量 X 的值后,在工作内存中进行数据计算后将数据写入内存中,最终主内存中的值是原有的值 + 1,而不是 + 2,相当有一个线程的操作被覆盖了。
为了避免这种情况发生,一般采取的方法是加修改数据的地方加锁(比如 ArrayBlockingQueue),一次只允许一个线程进行修改。
这种方式的缺点也明显,加锁是一个很消耗性能的操作
一个 64 位的变量循环执行 500 次的结果如下图

CAS
另外一种处理变量被覆盖更新的方式是 CAS,只有预期值和当前值匹配时,才将修改后的新值保持到内存中,否则进行循环重试操作,直到预期值和当前值匹配为止
使用 CAS 对一个 64 位的变量循环执行 500 次的结果如下图

Disruptor 每个生产者或者消费者线程,通过 CAS 申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。
2.3 ring buffer
圆形缓冲区(circular buffer),也称作圆形队列(circular queue),循环缓冲区(cyclic buffer),环形缓冲区(ring buffer),是一种用于表示一个固定尺寸、头尾相连的缓冲区的数据结构,适合缓存数据流。
— 维基百科
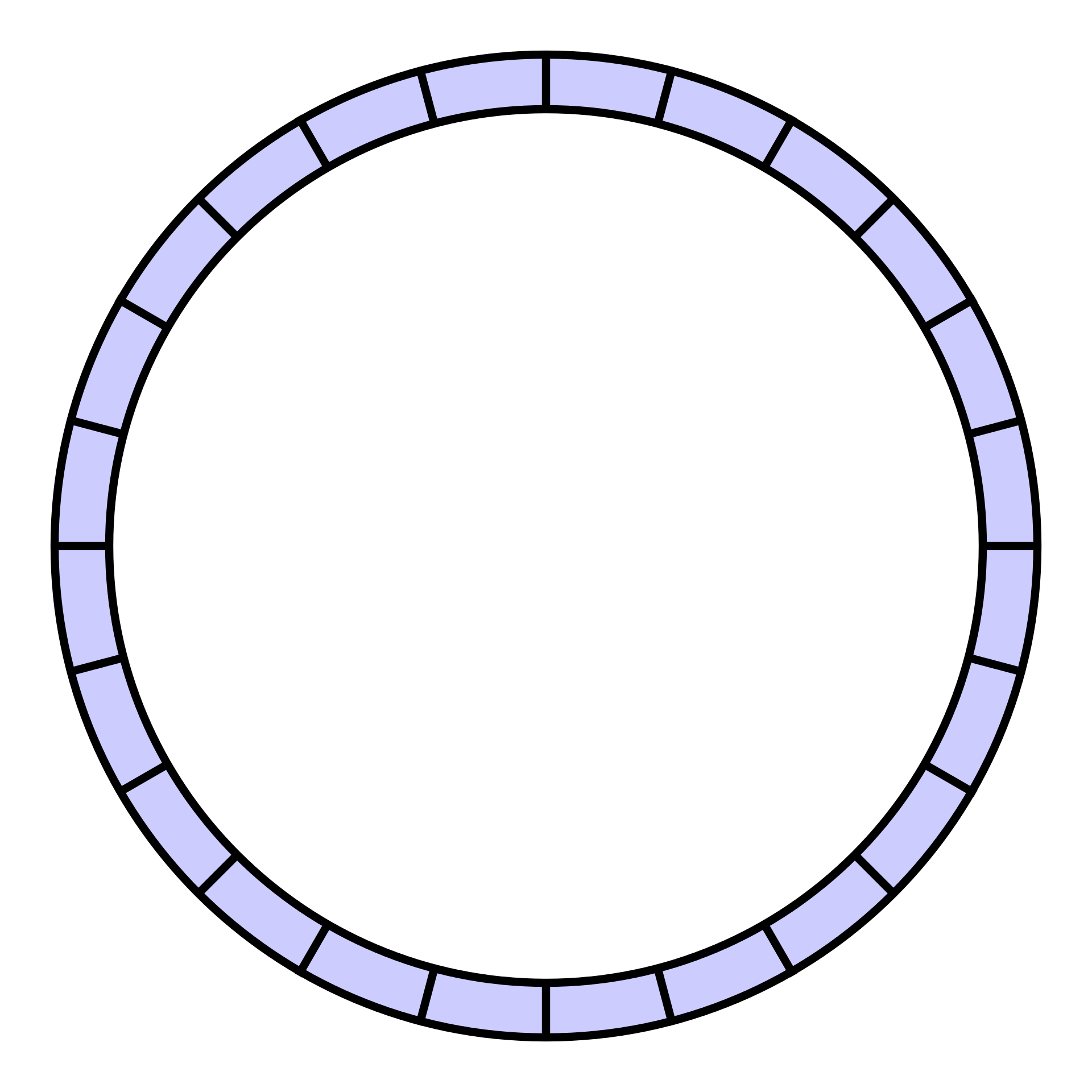
ring buffer 是一种先进先出的队列,在初始化的时候确定了队列的大小,当队列满的时候,新的元素进行入队操作时,ringbuffer 会覆盖最久未使用的元素。可以理解为一个固定大小并循环使用的数组
ring buffer 的优点:
- 由于 ring buffer 初始化大小后不再更新,之后的入队和出队操作只会进行更新,没有进行插入和删除,这对于 GC 是很友好的
- ring buffer 底层实现还是数组,连续多个元素会一并加载到 CPU Cache 里面来,所以访问遍历的速度会更快
在 Disruptor 中,生产者线程通过 publishEvent() 发布 Event 的时候,并不是创建一个新的 Event,而是通过 event.set() 方法修改 Event, 也就是说 RingBuffer 创建的 Event 是可以循环利用的,这样还能避免频繁创建、删除 Event 导致的频繁 GC 问题
2.4 消费者批量读取
在写入/读取数据之前,先加锁申请批量的空闲/可读取的存储单元,之后往队列中写入/读取数据的操作不需要加锁,写入/读取的性能因此提高
已读取为例:
available Buffer: 当某个位置写入成功的时候,便把availble Buffer相应的位置置位,标记为写入成功。读取的时候,会遍历available Buffer,来判断元素是否已经就绪。
private void processEvents()
{
T event = null;
// 写线程被分配到的最大元素下标,ring buffer 最大的写入位置
long nextSequence = sequence.get() + 1L;
while (true)
{
try
{
// 从reader cursor开始读取 available Buffer,一直查到第一个不可用的元素,然后返回最大连续可读元素的位置;
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
if (batchStartAware != null)
{
batchStartAware.onBatchStart(availableSequence - nextSequence + 1);
}
// 批量消费,由于没有其它事件处理器和我竞争序号,这些序号我都是可以消费的
while (nextSequence <= availableSequence)
{
event = dataProvider.get(nextSequence);
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}
sequence.set(availableSequence);
}
catch (final TimeoutException e)
{
notifyTimeout(sequence.get());
}
catch (final AlertException ex)
{
if (running.get() != RUNNING)
{
break;
}
}
catch (final Throwable ex)
{
handleEventException(ex, nextSequence, event);
sequence.set(nextSequence);
nextSequence++;
}
}
}
03 Disruptor 队列使用
以 maven 项目为例
首先添加 pom 依赖
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.4.4</version>
</dependency>
- 定义一个存储数据的事件
public class LongEvent
{
private long value;
public void set(long value)
{
this.value = value;
}
@Override
public String toString()
{
return "LongEvent{" + "value=" + value + '}';
}
}
- 定义消费事件的处理器
public class LongEventHandler implements EventHandler<LongEvent>
{
@Override
public void onEvent(LongEvent event, long sequence, boolean endOfBatch)
{
System.out.println("Event: " + event);
}
}
- 发布事件
public class LongEventMain {
public static void main(String[] args) throws Exception
{
int bufferSize = 1024;
Disruptor<LongEvent> disruptor =
new Disruptor<>(LongEvent::new, bufferSize, DaemonThreadFactory.INSTANCE);
disruptor.handleEventsWith(new LongEventHandler());
disruptor.start();
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++)
{
bb.putLong(0, l);
ringBuffer.publishEvent((event, sequence, buffer) -> event.set(buffer.getLong(0)), bb);
Thread.sleep(1000);
}
}
}
运用 main 方法,该程序每秒生产一个事件,消费者收到事件后输出如下
04 参考资料
https://zh.wikipedia.org/wiki/CPU%E7%BC%93%E5%AD%98
解读Disruptor系列--解读源码(4)之RingBuffer
JAVA 拾遗 — CPU Cache 与缓存行
Understanding the LMAX Disruptor
Disruptor-1.0.pdf