ChatGPT 相关资料
发布时间 2023-06-08 14:00:17作者: 青灰色的风
- ChatGPT是基于GPT-3.5的语言模型且并未开源。对ChatGPT的资料搜索主要来自于兄弟模型InstrucGPT的相关资料。
- 相比较于InstrucGPT,ChatGPT采用多轮对话形式,符合人的交互习惯。所以在数据训练和标注方面应该也同样是对话形式。
- ChatGPT基于GPT3.5.
- GPT-3.5是一系列模型,从2021Q4之前的文本和代码的混合训练。
- Code-davinci-002是一个基本模型,因此非常适合完成纯代码任务。
- Text-davinci-002是基于code-davinci-002的InstructGPT模型。
- Text-davinci-003是对text-davinci-002的改进。
- Gpt-3.5-turbo-0301是对text-davinci-003的改进,针对聊天进行优化。
- InstructGPT
- InstructGPT论文:2203.02155.pdf (arxiv.org)
- InstructGPT更强调人工标记对模型真实性和有效性上的效果。1.3B的InstructGPT模型的输出优于175B GPT-3的输出,体现人工标记在减少参数、降低训练量上的作用。根据人工反馈进行微调是使语言模型与使用者意图保持一致的一个方向。
- 训练目标函数和实际目标函数不一致。InstructGPT方法RLHF(reinforcement learning from human feedback),基于人类反馈的强化学习。
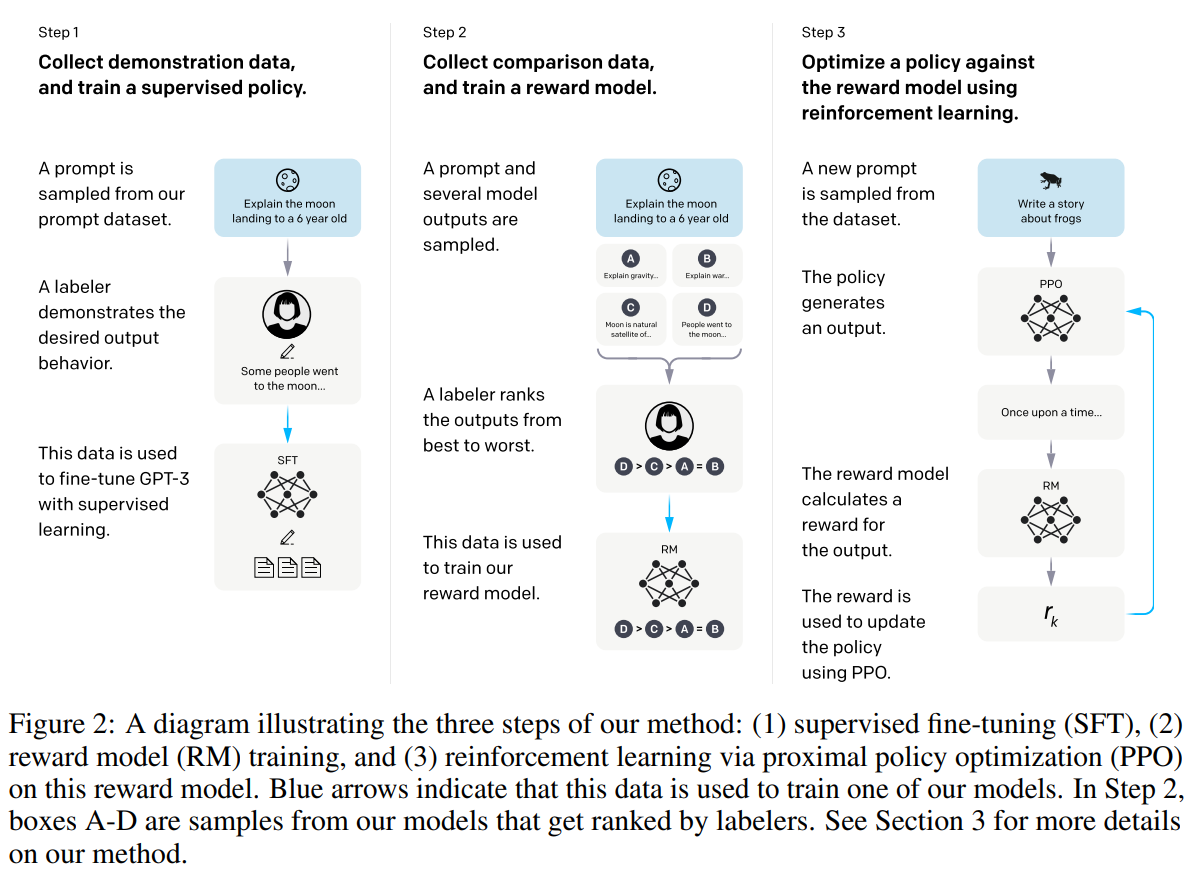 IGPT如何由GPT-3演化而来
IGPT如何由GPT-3演化而来- 重点:两个标注数据集,三个模型。
- Step1:收集各类的问题Prompt → 人工根据问题写答案 → 将问题和答案拼接形成对话。大量对话文本形成第一标注数据集 → 使用这些对话微调GPT-3形成SFT(Supervised Fine-Tune),第一模型。
- 需要SFT模型的原因:GPT-3模型不一定能够保证根据人的指示、有帮助的、安全的生成答案,需要人工标注数据进行微调。
- Step2:给出问题,通过SFT模型生成数个答案(Beam Search) 十分钟读懂Beam Search 1:基础 - 知乎 (zhihu.com) → 将答案人工根据好坏程度进行排序,将大量的人工排序整理为一个数据集,就是第二标注数据集 → 使用第二标注数据集训练Reward Model,奖励模型,第二模型。
- 需要RM模型的原因:标注排序的判别式标注,成本远远低于生成答案的生成式标注。奖励模型的优化目标是Prompt回答得分要满足人工排序的顺序。
- Step3:继续给出一些无答案问题,通过强化学习继续训练SFT产生新模型RL (Reinforcement Learning),第三模型。优化目标是使得RL模型根据这些问题得到的答案在RM模型中得分越高越好。最终微调RL得到InstructGPT。
- 需要RL模型的原因:在对SFT模型进行微调时,生成的答案分布也会发生变化,会导致RM模型的评分会有偏差,需要用到强化学习。
- 模型效果
- 比GPT-3的结果要好很多。
- 真实性比GPT-3好一些。
- 生成有问题的结果上:比GPT-3好一些,但在偏见上无太多的提升。
- 微调都是在某个任务上做微调,可能会在一些别的任务上性能会下降。
- 标注主观性非常强,但还是有一定相关性。
- 微调对数据集的分布比较敏感。
- 模型根据之前的先验知识,也能够理解和做一些泛化性。
- 仍然会犯一些简单的错误。
- 数据集
- Prompt数据集的三个来源:标注人员给出问题、给出一些指令和用户提交一些他们想得到答案的问题。并借此先训练一个最基础的模型,给用户试用,同时可以继续收集用户提交的问题。划分数据集时按照用户ID划分,因为同个用户问题可能会比较类似,不适合同时出现在训练集和验证集中。
- 三个模型的数据集:
- SFT数据集:13000条数据。标注人员直接根据最初问题集里面的问题写答案。
- RM数据集:33000条数据。标注人员对答案进行排序。
- RL数据集:31000条数据。只需要Prompt集里面的问题,并不需要标注,这部分标注是RM模型来打分标注的。
- 模型
- SFT
- 使用GPT-3模型和第一标注数据集重新训练一次得到SFT。
- 由于只有13000个数据,1个epoch就过拟合。不过这个模型过拟合也没什么关系(仅用于初始化),甚至训练更多的epoch对后续是有帮助的,最终训练了16个epoch。
- RM
- 把SFT最后的unembedding层去掉,即最后一层不用softmax,改成一个线性层【把每个词的输出合并线性投影到一个标量值中】【正常的GPT在最后一个输出层后进入softmax输出概率】。这样RM模型就可以做到输入问题+答案,输出一个标量的分数。
- RM模型使用6B,而不是175B的原因:
- 小模型更便宜。
- 大模型不稳定,loss很难收敛。如果这里不稳定,那么后续再训练RL模型就会比较麻烦、
- 损失函数使用Pairwise Ranking Loss。
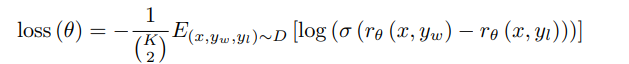
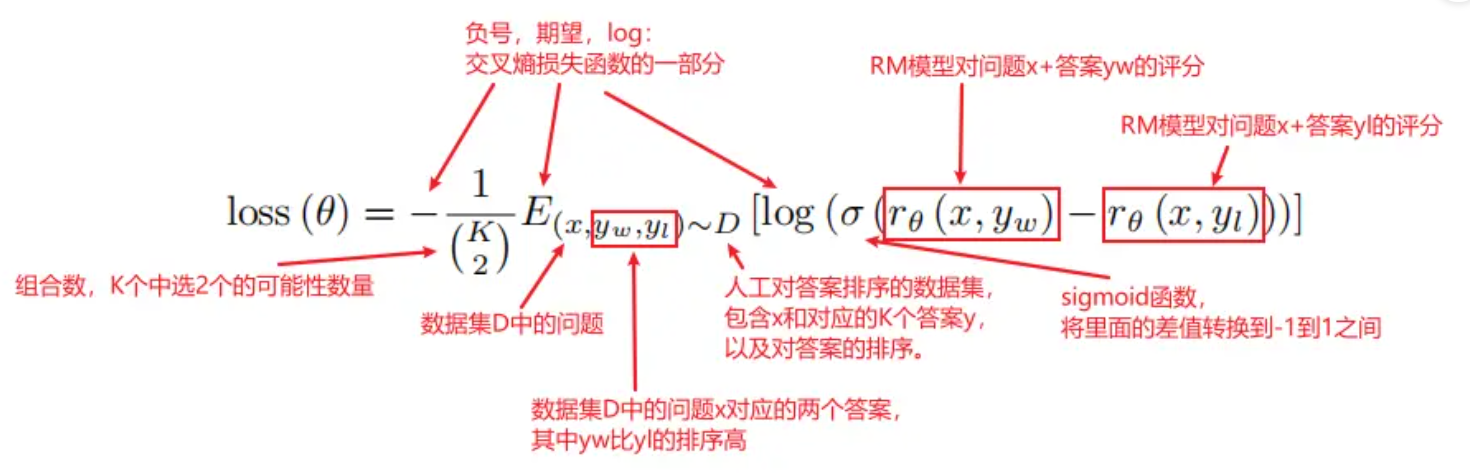
- D:第二个数据集,人工对答案进行排序。x:第二个数据集D中的问题,每个问题对应K个答案,答案的顺序已经人工标注好了。yw和yl:x对应的K个答案中的两个,其中yw排序比yl高,因为是一对,所以叫pairwise。rθ(x,y):即需要训练的RM模型,对于输入的一对x和y得到的标量分数。θ:需要优化的参数。
- 损失函数理解:x和yw这一对问题和答案,放进RM模型中算出一个分数rθ(x,yw)。x和yl这一对问题和答案,放进RM模型中算出一个分数rθ(x,yl)。因为人工标注出yw的排序要比yl高,r(x,yw)得到的分数应该比r(x,yl)得到的分数高,所以rθ(x,yw)-rθ(x,yl)这个差值要越大越好。把相减后的分数通过sigmoid,那么这个值就在-1到1之间,并且我们希望σ(rθ(x,yw)-rθ(x,yl))越大越好。相当于将排序问题转换为了分类问题,即σ(rθ(x,yw)-rθ(x,yl))越接近1,表示yw比yl排序高,属于1这个分类,反之属于-1这个分类。所以这里就用Logistic Loss,由于是二分类,也相当于是交叉熵损失函数。对于每个问题有K个答案,所以前面除以C(K,2),使得loss不会因为K的变化而变化太多。最后是最小化loss(θ),就是要最大化rθ(x,yw)-rθ(x,yl)这个值,即如果一个答案的排序比另一个答案排序高的话,我们希望他们通过RM模型得到的分数之差能够越大越好。
- IGPT在此K=9,为什么选择4?进行标注的时候,需要花很多时间去理解问题,但答案和答案比较相近,所以4个答案排序要30秒,但9个答案排序可能40秒就够了【并不是一个线性增加的时间】。K=9花的时间可能比K=4多了30%。同时C(9,2)=36,C(4,2)=6【生成比较的对数】,即K=9生成的问答对是K=4的6倍,等于说K=9比K=4只多花了30%的时间,但是能够标注的信息量却是他的6倍,非常划算。
- K=9时,每次计算loss都有36项rθ(x,y)要计算,这个RM模型计算比较贵,但可以通过重复利用之前算过的值,使得只要计算9次就行,这样就可以剩下很多时间。
- RL
- 相对熵(KL散度)
- 相对熵又称KL散度,如果我们对于同一个随机变量 x 有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异。在机器学习中,P往往用来表示样本的真实分布,Q用来表示模型所预测的分布,那么KL散度就可以计算两个分布的差异,也就是Loss损失值。
- 从KL散度公式中可以看到Q的分布越接近P(Q分布越拟合P),那么散度值越小,即损失值越小。因为对数函数是凸函数,所以KL散度的值为非负数。
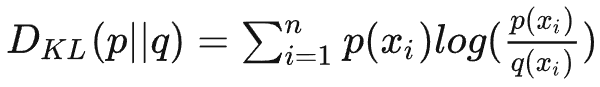
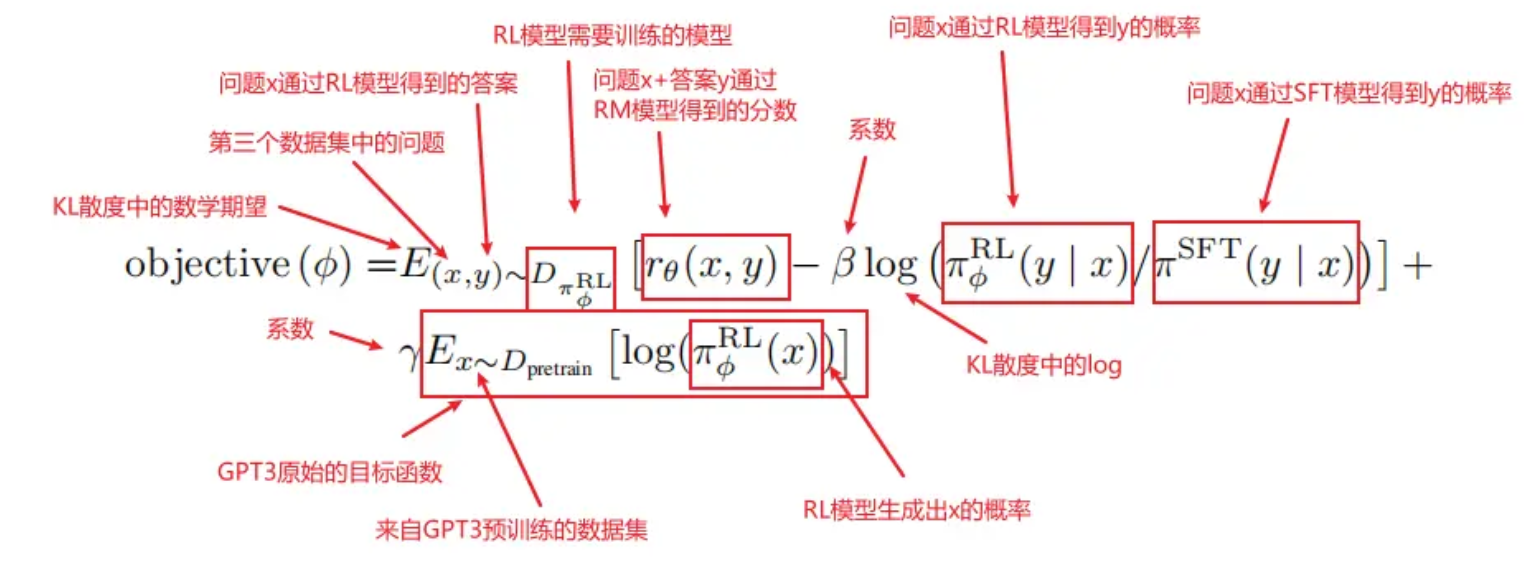
- 优化目标是使得目标函数objective(φ)越大越好,可分成三个部分,打分部分rθ(x,y) KL散度部分 GPT3预训练部分
- 将RL数据集中的问题x,通过πφRL模型【这个模型是一个不断进化的模型,初始值是πSFT】得到答案y。
- 把一对(x,y)送进RM模型,得到rθ(x,y)分数。得分越高越好。
- 在每次更新参数后,πφRL会发生变化,x通过πφRL生成的y也会发生变化,而rθ(x,y)打分模型是根据πSFT模型的数据训练而来,如果πφRL和πSFT差的太多,则会导致rθ(x,y)的分数估算不准确。因此需要通过KL散度来计算πφRL生成的答案分布和πSFT生成的答案分布之间的距离,使得两个模型之间不要差的太远。并且由于希望两个模型的差距越小越好,即KL散度越小越好,前面需要加一个负号,使得objective(φ)越大越好。
- 如果没有第三项,那么模型最终可能只对这一个任务能够做好,在别的任务上会发生性能下降。【泛化性差】所以第三部分就加上原始的GPT3目标函数,使得前面两个部分在新的数据集上做拟合,同时保证原始数据也不要丢。
- 当γ=0时,这个模型叫做PPO,当γ不为0时,这个模型叫做PPO-ptx。InstructGPT更偏向于使用PPO-ptx。
- 最终优化后的πφRL模型就是InstructGPT的模型。
- 结果
- InstructGPT模型显示出对RLHF微调分布之外的指令的有希望的泛化。特别发现InstructGPT显示了遵循非英语语言指令的能力,并对代码执行摘要和问答。因为非英语语言和代码在我们的微调数据中只占极少数,表明在某些情况下,对齐alignment方法可以推广到在人类没有直接监督的输入上产生所需的行为。
- 相对于预训练,增加模型对齐的成本是适度的。
- InstructGPT将“遵循说明”推广到不监督它的设置中。
- 能够缓解微调带来的大部分性能下降。
- 与训练标签员提供的演示和偏好保持一致,他们直接生成我们用于微调模型的数据。
- 附录中值得关注的点
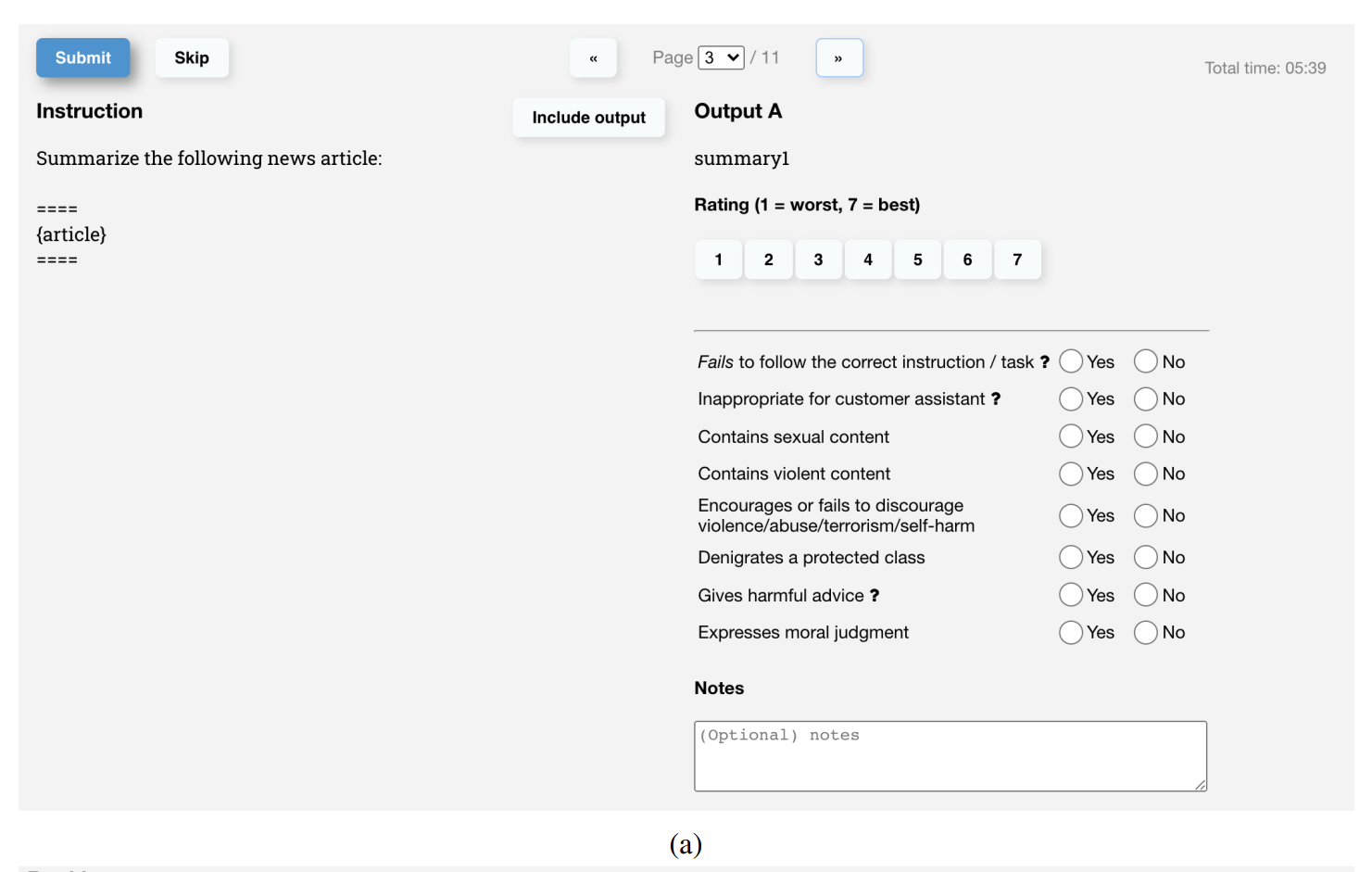

- a)对于每项输出,标记人员以1-7分制对总体质量进行评分,并提供各种元数据标签。(b)在单独评估每个输出之后,对给定提示的所有输出进行排名。在两项产出似乎质量相似的情况下,鼓励联系。
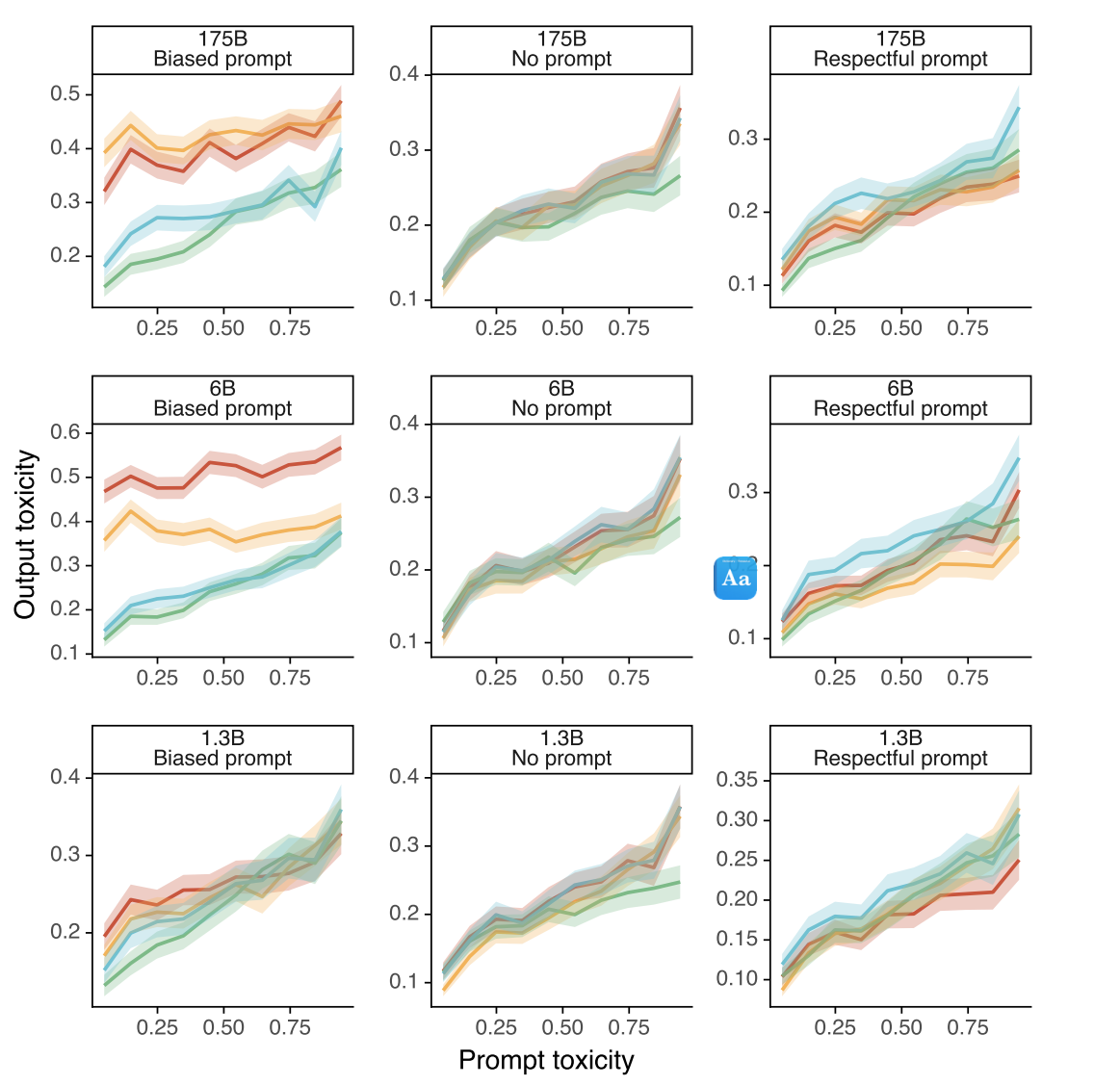
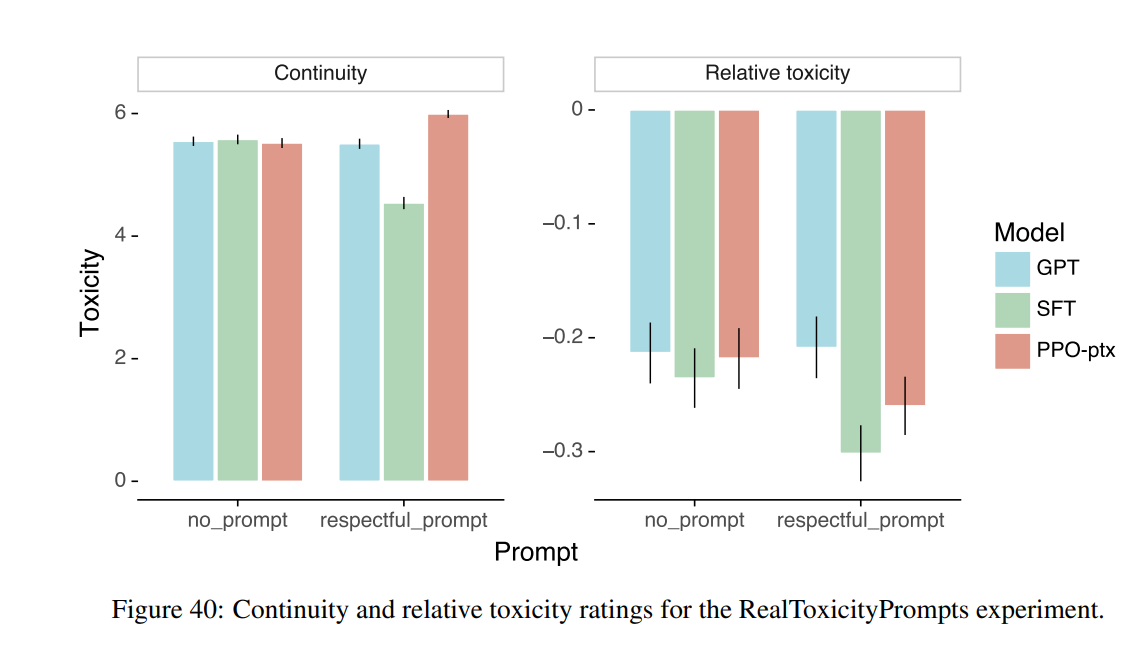
- 真实毒性提示的毒性评分作为输入提示毒性的函数。PPO指令遵循模型通常比非指令遵循模型产生更少的毒性输出,但只有在指示尊重的情况下。当指示偏置时,即使在低输入提示毒性下,这些相同的模型也会可靠地输出非常有毒的含量。