1.KNN算法的定位
KNN算法属于分类算法,所以它是有监督学习里面的一部分,且属于有监督学习里的分类问题
- KNN的计算量很大
-
KNN理论上比较成熟且算法简单易懂,易实现
2.KNN算法的核心
-
简单地说---“近朱者赤,近墨者黑”
- 进行分类的时候,即将被分类的这个样本的附近(特征空间中最邻近)离它最近的K个节点数量中,K个中哪个类的节点数量最多,它就是属于那一类
- K就是离样本最近的所有节点数量
- K是超参数,需要通过验证集不断更新完善
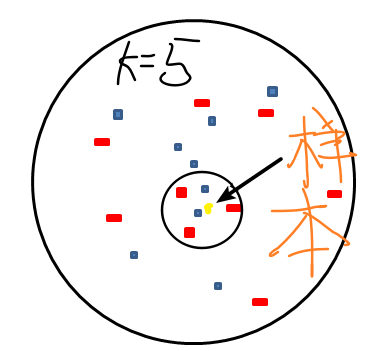
如上图:此时K=5,黄色的点是样本,即将对它进行预测,所以此时找到它最近的5个点分别是图中小圆圈圈起来的部分,五个里面红色居多,所以就把它归为红色这一类。
3.KNN的操作方法:
- 分类预测:多数表决,就是刚刚说的
- 回归预测:平均值法,就是取点数量的平均值作为判断基准
4.K值对KNN分类的影响
过拟合和欠拟合
很显然的K值不是越大越好
- K越大,可以想象当他无穷大,要找到很多个点,而这很多个点里面可能一个类只有一个点,很多类别,极端的情况是一个类仅有一个点,进来的每一个自成一类,所以会导致分类分出来很粗糙,类的区分度不大,就会产生欠拟合
- K越小,最小取为1,类似的,分类分的很细,以至于最后分的类别很多,容易过拟合,当一个新的噪声点来的时候会严重偏离原来的类别,就是泛化能力很弱,过拟合产生
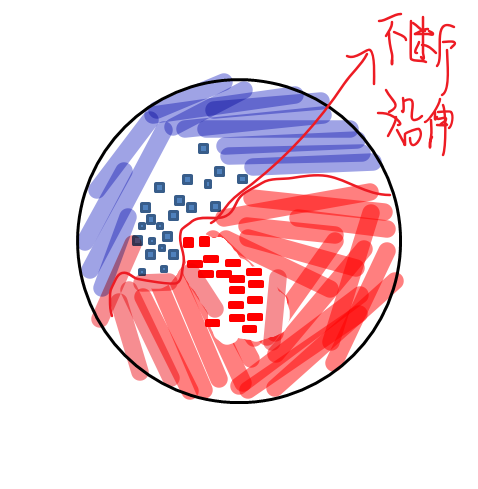
如上:当K很小,分得很细致,来一个新的点就会往中间突出的那个地方延申,当一个噪声点来时,就会导致分类误差很大。而当K不断变大,最后会变成全蓝或全红。
5.最后,总结
-
KNN:“近朱者赤,近墨者黑”;
-
KNN核心:找到最近的K个点,再在K个点里面找同类别点数最多的点,此类就是要归过去的类;
-
K为超参数需要不断更新完善;
-
分类预测:多数表决;回归预测:平均值法;
-
K越大,欠拟合(因为分的类别很多,类与类的区分度太小,极端情况一类一个,进来的每一个自成一类);K越小欠拟合(分类分的很细,以至于最后分的类别很多);