以下代码导致内存溢出:
是一段连表查询导致查询不到的问题
var onelst = await dbpTasks.Where(Epr).Join(Context.DbpTaskMetadata.AsNoTracking().GroupBy(meta => meta.Taskid).Select(g => new { Key = g.Key, Value = g }), src => src.Taskid, meta => meta.Key, (src, meta) => new { src, meta }).Select(taskinfo => new TaskDbFullInfo
{
Dbptask = taskinfo.src,
CaptureMeta = taskinfo.meta.Value.Where(x => x.Metadatatype == (int)MetaDataType.emCapatureMetaData).FirstOrDefault(),
ContentMeta = taskinfo.meta.Value.Where(x => x.Metadatatype == (int)MetaDataType.emContentMetaData).FirstOrDefault(),
MaterialMeta = taskinfo.meta.Value.Where(x => x.Metadatatype == (int)MetaDataType.emStoreMetaData).FirstOrDefault(),
PlanningMeta = taskinfo.meta.Value.Where(x => x.Metadatatype == (int)MetaDataType.emPlanMetaData).FirstOrDefault(),
SplitMeta = taskinfo.meta.Value.Where(x => x.Metadatatype == (int)MetaDataType.emSplitData).FirstOrDefault()
}
).ToListAsync();
DbpTaskMetadata全部查询分组了 ,耗时长内存也飙升,主要使用Group
sfenxiFenixql语句如下:
EXPLAIN
SELECT
dbptask.*,
capture_meta.metadata AS capture_metadata,
content_meta.metadata AS content_metadata,
material_meta.metadata AS material_metadata,
planning_meta.metadata AS planning_metadata,
split_meta.metadata AS split_metadata
FROM dbp_task dbptask
LEFT JOIN
(
SELECT taskid, metadata
FROM dbp_task_metadata
WHERE metadatatype = 1
) capture_meta
ON dbptask.taskid = capture_meta.taskid
LEFT JOIN
(
SELECT taskid, metadata
FROM dbp_task_metadata
WHERE metadatatype = 2
) content_meta
ON dbptask.taskid = content_meta.taskid
LEFT JOIN
(
SELECT taskid, metadata
FROM dbp_task_metadata
WHERE metadatatype = 3
) material_meta
ON dbptask.taskid = material_meta.taskid
LEFT JOIN
(
SELECT taskid, metadata
FROM dbp_task_metadata
WHERE metadatatype = 4
) planning_meta
ON dbptask.taskid = planning_meta.taskid
LEFT JOIN
(
SELECT taskid, metadata
FROM dbp_task_metadata
WHERE metadatatype = 5
) split_meta
ON dbptask.taskid = split_meta.taskid
WHERE dbptask.taskid<10;
mysql分析:
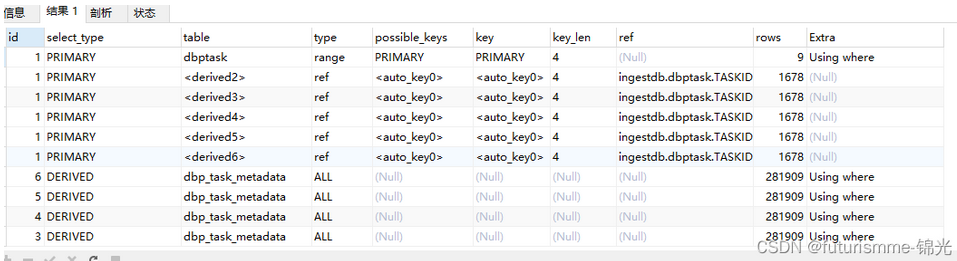
可以看到时全表查询
本地调试运行现象内存飙升不止
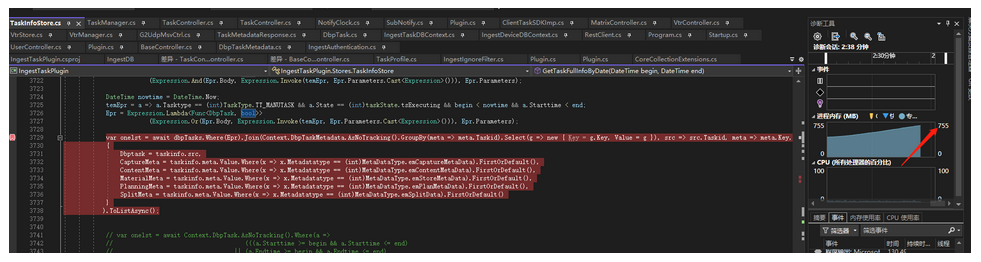
内存飙升分析
使用方式:
.Net Core在Linux环境dump分析_.net core dump_iamfrankjie的博客-CSDN博客
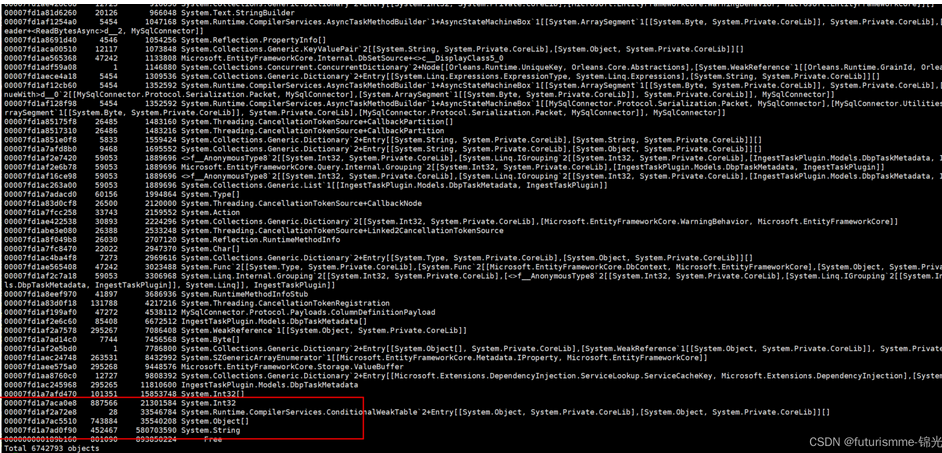
如何修改:
如何不是后台服务添加请求接口日志,查找所有请求的接口记录.
定位那个请求连接 然后本地调试观察内存使用情况
然后结合内存情况分析
实现的原理梳理:
表1为任务表
表2为任务元数据表
表1的taskid对应表二taskid有多条记录
如何查询表1的一个taskid和类型对应记录为一个字段加表2对应的多条记录分别为一个字段
如果您需要在查询中添加任务元数据的类型条件,可以这样修改SQL语句:
sql
SELECT
t1.taskid AS taskid,
(SELECT metadata FROM task_metadata WHERE taskid = t1.taskid AND type = 'type1' LIMIT 1) AS metadata1,
(SELECT metadata FROM task_metadata WHERE taskid = t1.taskid AND type = 'type2' LIMIT 1 OFFSET 1) AS metadata2,
(SELECT metadata FROM task_metadata WHERE taskid = t1.taskid AND type = 'type3' LIMIT 1 OFFSET 2) AS metadata3
FROM tasks t1
msyql分析:

可以看到不存在全表查询
或者在LINQ查询中这样修改:
csharp
var result = from t in dbContext.Tasks
select new
{
t.TaskId,
Metadata1 = (from tm in dbContext.TaskMetadata
where tm.TaskId == t.TaskId && tm.Type == "type1"
select tm.Metadata).FirstOrDefault(),
Metadata2 = (from tm in dbContext.TaskMetadata
where tm.TaskId == t.TaskId && tm.Type == "type2"
select tm.Metadata).Skip(1).FirstOrDefault(),
Metadata3 = (from tm in dbContext.TaskMetadata
where tm.TaskId == t.TaskId && tm.Type == "type3"
select tm.Metadata).Skip(2).FirstOrDefault()
};
只需要在查询TaskMetadata的条件中添加元数据类型的条件即可。如果某个类型的元数据不存在,相应的Metadata字段将为NULL。例如,如果task_metadata表还有一个Type列,数据如下:| taskid | metadata | Type |
|:-:|:-:|:-:|
| 1 | metadata1 | type1 |
| 1 | metadata2 | type2 |
| 2 | metadata3 | type2 |
| 2 | metadata4 | type3 |那么查询结果为:| taskid | metadata1 | metadata2 | metadata3 |
|:-:|:-:|:-:|:-:|
| 1 | metadata1 | metadata2 | NULL |
| 2 | NULL | metadata3| metadata4 | Metadata1字段包含type1元数据,Metadata2包含type2元数据,Metadata3包含type3元数据。请根据实际业务逻辑选择元数据的类型条件,我这里只作为一个示例。
优化
使用EF Core执行全表查询时,由于需要将整个表的数据加载到内存中,如果表过大 existed内存限制,很容易出现内存溢出的问题。有几种方法可以避免或减少此问题:1. 设置DbContext的MaxResultSetSize限制您可以在DbContext选项中设置MaxResultSetSize来限制返回行数,例如:
csharp optionsBuilder.UseSqlServer(connectionString, o => o.MaxResultsSize(100));
这将限制查询返回不超过100行记录,可以避免返回过多数据导致的内存溢出。2. 使用延迟加载和懒加载在EF Core中,默认启用延迟加载,这意味着关联数据只在真正访问时从数据库加载。您也可以通过设置属性的Load方法手动标记启用延迟加载,例如:
csharp
public class Blog
{
public int Id { get; set; }
public string Title { get; set; }
public virtual List<Post> Posts { get; set; }
}
modelBuilder.Entity<Blog>()
.HasMany(b => b.Posts)
.WithOne(p => p.Blog)
.HasForeignKey(p => p.BlogId)
.IsRequired()
.Load(); // 使用延迟加载
这可以避免在查询博客时立即加载所有的文章数据,减少内存使用。3. 设置查询的PageSize并使用分页您可以在查询中设置PageSize来限制单次返回行数,然后使用分页逐步加载更多数据,而不是立即加载所有行。例如:
csharp int pageSize = 100; var blogs = await dbContext.Blogs.Take(pageSize).ToListAsync(); var nextPage = await dbContext.Blogs.Skip(pageSize).Take(pageSize).ToListAsync(); // ...
这种分页查询方式可以充分控制每次加载的数据量,有效降低内存溢出的风险。4. 避免ToListAsync方法ToListAsync方法会将查询结果缓存到内存列表中,这会占用更多内存。您可以使用其他像Single、SingleOrDefault这样的查询方法,或者用foreach直接枚举查询的每个结果,而不调用ToListAsync。这些是使用EF Core时避免或减少全表查询导致内存溢出的几个常用方法。适当运用可以提高系统的性能和健壮性。