概述
本节主要讨论数据在内存和硬盘之间的移动的管理,可以分为两个部分,空间控制(Spatial Control)和时间控制(Temporal Control)。
- spatial control 决定将 pages 写到磁盘的哪个位置,使得常常在一起使用的 pages 能离得比较近,从而提高 I/O 效率。
- temporal control 决定何时将 pages 读入内存,写回磁盘,使得读写次数最小,从而提高 I/O 效率。
buffer pool manager
DBMS 启动时会从 OS 申请一块内存区域,即 buffer pool,将这块区域划分为大小相同的 pages,为了与 disk pages 区分,通常称为 frames。如下图所示:
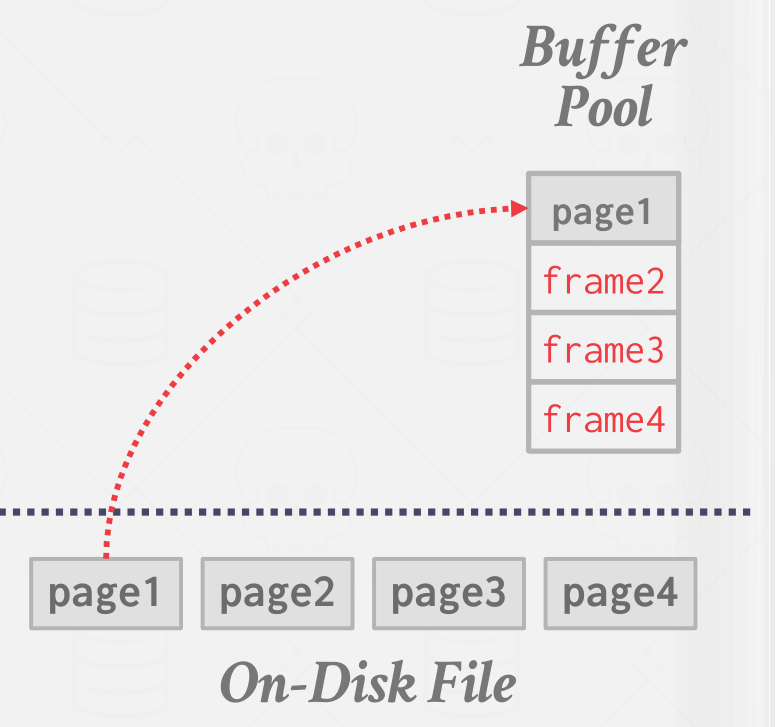
同时 DBMS 会维护一个 page table,负责记录每个 page 在内存中的位置、是否被写过(dirty flag)、引用计数(reference counter)等元信息,如下图所示:
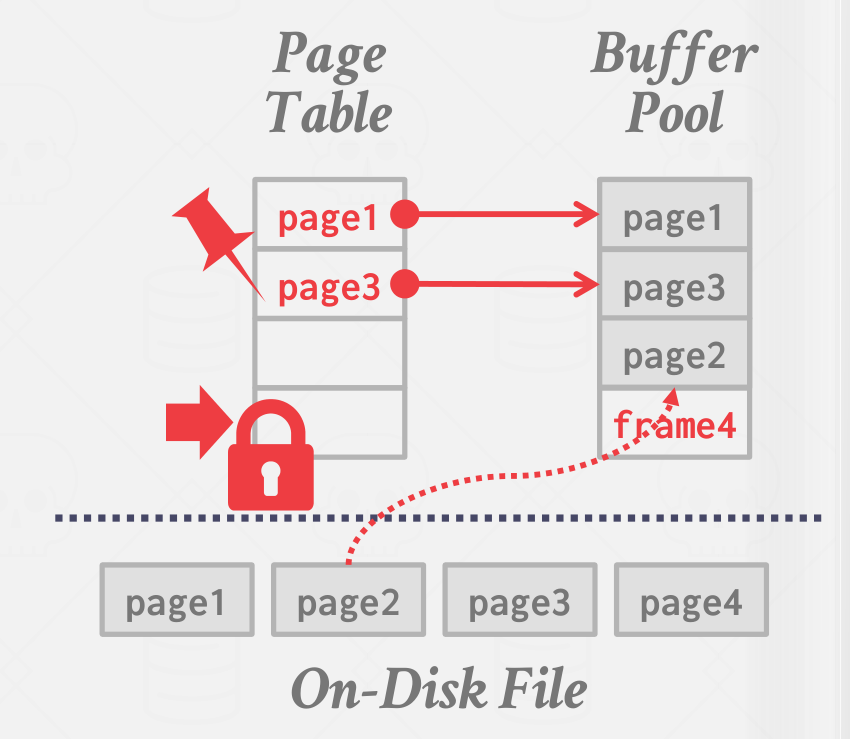
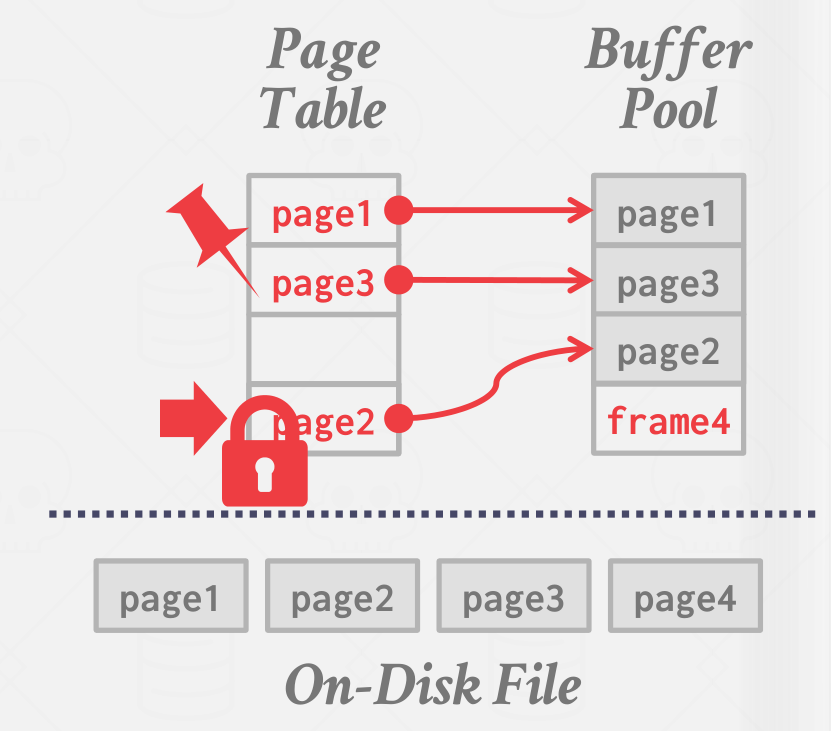
当 page table 的某 page 被引用时,会记录引用计数(pin reference),表示该 page 正在被使用,占用的内存不能被释放;当请求的 page 不在 page table 中时,DBMS 会先申请一个 latch(应该是 spin lock),表示该 entry 被占用,然后从 disk 中读取相关 page 到 buffer pool,释放 latch。如下图所示:
buffer pool 与数据库的 disk page 的关系有点像磁盘页与虚拟内存之间的关系(联想一下 mmap,但是不建议在数据库中利用 mmap 来实现)。
buffer pool 位于内存,它的组织形式是固定大小的 pages 的数组,每个数组元素称为 frame(为了在命名上与 page 做出区分)。
An array entry is called a frame.
Locks vs. Latches
在 database 中,latch 更像操作系统中所说的 mutex(互斥锁),一般是用于锁定细粒度的 page 等,一般在写入 page 等操作期间被持有。
而 locks 则是用于保证线程之间的同步,一般在 transaction 的持续期间被持有。
注意 latch 和 cpp 中的 latch 不是同一个概念!
page table vs. page directory
page directory 是 disk page id 和它在 database files 之间的位置的映射关系,page directory 是存在于磁盘,持久化的。
page directory 可以说是 disk page id 与它在磁盘上的位置之间的映射关系。
page table 则是 disk page id 与它在 buuffer pool 的 frame 的缓存之间的映射关系,一个 page id 映射到一个 frame?page table 存在于内存中,非持久化的(当然也可以写入到磁盘中)。
multiple buffer pool
为了减少并发控制的开销以及利用数据的 locality 性质,DBMS 可能在不同维度上维护多个 buffer pools:
- 多个 buffer pools 实例,相同 page 会 hash 到相同的实例上;
- 每个 database 分配一个 buffer pool;
- 每种 page 类型一个 buffer pool;
prefetchig
scan sharig
scan sharing 技术主要用在多个查询存在数据共用的情况。当两个查询 A, B 先后发生,B 发现自己有一部分数据与 A 共用,于是先共用 A 的 cursor,等 A 扫完后,再扫描自己还需要的其它数据。
buffer pool bypass
当碰到大数据量的 sequential scan 时,如果将所需要的 pages 顺序存入 buffer pool,将会污染 buffer pool,大量可能之后马上会用到的 frame 被驱逐,而这些 pages 可能只会使用一次就没用了,因此一些 DBMS 做了相应优化,出现这种查询时,为它单独分配一块局部内存,将其对 buffer pool 的影响隔离。
os page cache
大部分的 disk operation 都是通过系统调用完成的,通常系统会维护自身的数据缓存,这会导致一份数据在操作系统和 DBMS 中被缓存两次,大多数 DBMS 会使用(O_DIRECT)来告诉 OS 不要缓存这些数据,postgresql 除外。
buffer replacement policy
当 buffer pool 空间不足时,假设要读入新的 pages,就必须选择 buffer pool 的一部分 pages 移除,选择要移除的 pages 则是基于 buffer replacement policy 完成,该策略有以下几个目标:
- correcness:脏数据必须同步到 disk;
- accuracy:尽量选择不常用的 pages 移除;
- speed:选择 victim page 移除要迅速;
- meta-data overhead:决策所需的元信息不能太大;
LRU
LRU 就是维护每个 page 上一次被访问的时间戳,每次都移除时间戳最小的 page。
实现方法很多,例如遍历一遍找到时间戳最小的 page,又或者使用升序链表,又或者小顶堆等;
比较常用的实现方案是利用 clock,它为每个 page 保存一个 accessed bit,每当 page 被访问时,将 reference bit 设置为 $1$;每隔一段时间,轮询每个 page 的 reference bit,若该 bit 为 $1$,将其置为 $0$;若该 bit 为 $0$,移除该 page。它其实是 LRU 的一种近似。
简单的 LRU 策略会被 sequential flooding 现象影响,导致最近访问的 page 实际上是最不可能需要的 page,为了解决这一问题,研究人员提出了 LRU-K 策略。
考虑只有 $2$ 个 frame 的 buffer pool,有 $3$ 个 page 的 file,顺序扫描这个 file 两遍,就能理解 sequential flooding 的负面作用了。
LRU-K
简单来说,就是比较最近的第 k 此访问的时间戳,而不是最近一次。
对某些 DBMS 来说,它会通过保存查询执行过程中的上下文信息,判断 page 的优先级。