RISCV基础原理介绍
初识RISC-V
https://www.cnblogs.com/wahahahehehe/p/15574316.html
1.1 什么是RISC-V
了解RISC-V之前,先熟悉一个概念,指令集架构(Instruction Set Architecture,ISA)。
还记得用C语言的编写的hello world程序吗?
该程序在PC、8位MCU、32位MCU这些不同的平台上都能正常运行,这是为什么呢?
答案就是有一套标准规范,正因为编译器和芯片设计时都遵循这套规范,使得高级语言编写的程序经指定编译器编译后能直接运行在对应的芯片上。
这套标准规范就是指令集架构(Instruction Set Architecture,ISA)。
ISA主要分为复杂指令集(Complex Instruction Set Computer,CISC)和精简指令集(Reduced Instruction Set Computer,RISC),典型代表如下:
ISA是底层硬件电路面向上层软件程序提供的一层接口规范,即机器语言程序所运行的计算机硬件和软件之间的“桥梁”。ISA主要定义了如下内容:
· 基本数据类型及格式(byte、int、word……)
ISA规定了机器级程序的格式和行为,即ISA具有软件看得见(能感觉到)的特性,因此用机器指令或汇编指令编写机器级程序时,必须熟悉对应平台的ISA。不过程序员大多使用高级语言(C/C++、Java)编写程序,由工具链编译转换为对应的机器语言,不需要了解ISA和底层硬件的执行机理。
RISC由美国加州大学伯克利分校教授David Patterson发明。
RISC-V(读作”risk-five“),表示第五代精简指令集,起源于2010年伯克利大学并行计算实验室(Par Lab) 的1位教授和2个研究生的一个项目(该项目也由David Patterson指导),希望选择一款指令集用于科研和教学,该项目在x86、ARM等指令集架构中徘徊,最终决定自己设计一个全新的指令集,RISC-V由此诞生。RISC-V的最初目标是实用、开源、可在学术上使用,并且在任何硬件或软件设计中部署时无需版税。
2015年,为了更好的推动RISC-V在技术和商业上的发展,3位创始人做了如下安排:
· 成立RISC-V基金会,维护指令集架构的完整性和非碎片化
2019年,RISC-V基金会宣布将总部迁往瑞士,改名RISC-V国际基金会。作为全球性非营利组织,已在全球70多个国家拥有2000+成员。包括华为、中兴、阿里巴巴、、乐鑫等众多国内企业。
通过十多年的发展,RISC-V这一星星之火已有燎原之势。倪光南院士表示,未来RISC-V很可能发展成为世界主流CPU之一,从而在CPU领域形成Intel (x86)、ARM、RISC-V三分天下的格局。
RISC-V指令集采用模块化的方式进行组织设计,由基本指令集和扩展指令集组成,每个模块用一个英文字母表示。
其中,整数(Integer)指令集用字母“I”表示,这是RISC-V处理器最基本也是唯一强制要求实现的指令集。其他指令集均为可选模块,可自行选择是否支持。
通常把模块“I”、“M”、“A”、“F”和“D”的特定组合“IMAFD”称为通用组合(General),用字母“G”表示。如用RV32G表示RV32IMAFD。
RV32I支持32个通用寄存器x0~x31,每个寄存器长度均为32位,其中寄存器x0恒为0,剩余31个为任意读/写的通用寄存器。
为了增加汇编程序的阅读性,汇编编程时通常采用应用程序二进制接口协议(Application Binary Interface,ABI)定义的寄存器名称。
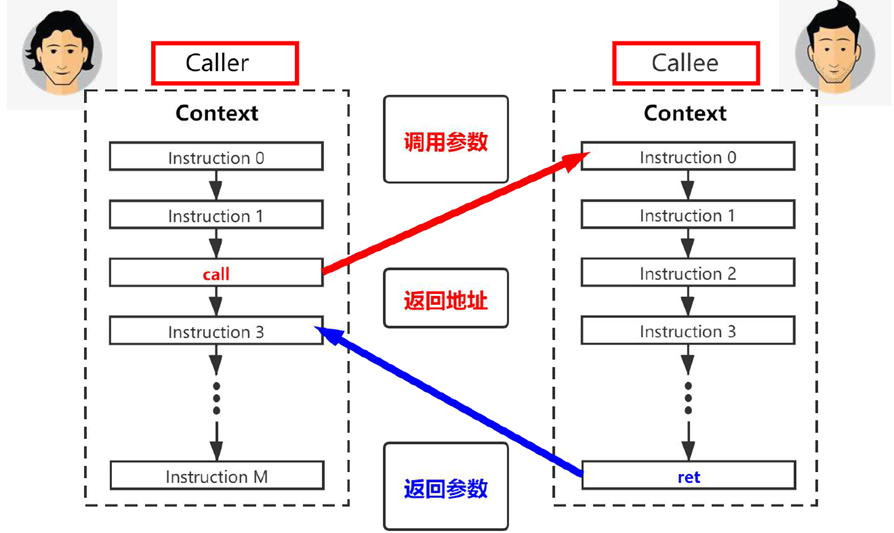
· Caller:来访者,简单来说就是打电话的,即调用函数的函数,
· Callee:被访者,简单来说就是接电话的,即被调用函数
· 寄存器的宽度由ISA指定,如RV32的通用寄存器宽度为32位,RV64的通用寄存器宽度为64位。
· 如果支持浮点指令,则需额外支持32个浮点(Float Point)寄存器
· 不同于ARM,RISC-V中PC指针不占用通过寄存器,而是独立的,程序执行中自动变化,无法通过通用寄存器访问和修改PC值。
RISC-V规定如下四个特权级别(privilege level):
· 机器模式(M),RISC-V处理器在复位后自动进入机器模式(M),因此,机器模式是所有RISC-V处理器唯一必须要实现的特权模式。此模式下运行的程序权限最高,支持处理器的所有指令,可以访问处理器的全部资源。
· 用户模式(U),该模式是可选的,权限最低。此模型下仅可访问限定的资源。
· 管理员模式(S),该模式也是可选的,旨在支持Linux、Windows等操作系统。管理员模式可访问的资源比用户模式多,但比机器模式少。
通过不同特权模式的组合,可设计面向不同应用场景的处理器,如:
从2017年开始关注并研究RISC-V开源指令集的32位MCU架构,针对快速中断响应、高带宽数据DMA进行优化,自定义压缩指令,研发设计硬件压栈(HPE,Hardware Prologue/Epilogue),并创新性提出免表中断(VTF,Vector Table Free)技术,即免查表方式中断寻址技术,同时引入两线仿真调试接口。
目前已形成了侧重于低功耗或高性能等多个版本的RISC-V处理器。特点如下:
结合多年USB、低功耗蓝牙、以太网等接口的设计经验,基于多款自研RISC-V处理器,并基于32位通用MCU架构外加USB高速PHY、蓝牙收发器、以太网PHY等专业接口模块推出增强版MCU+系列产品。
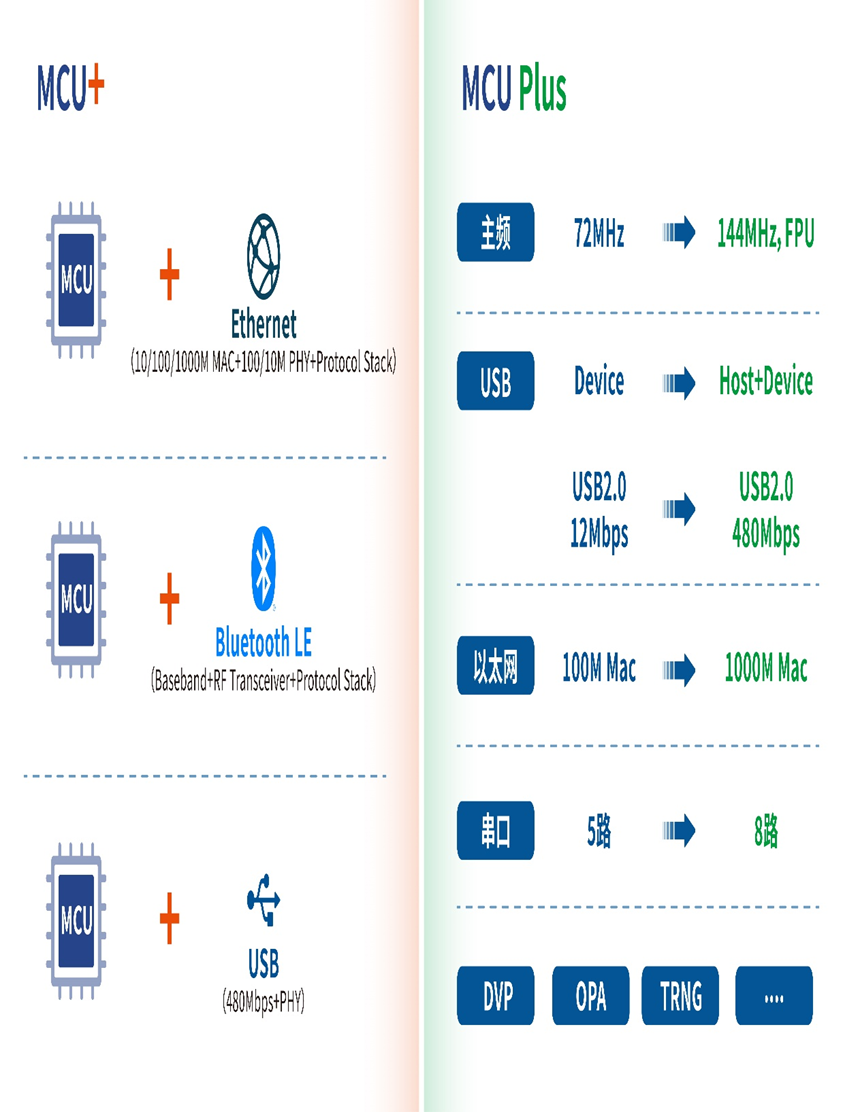
RISC-V系列MCU Roadmap如下:

1.3 工业级互联型MCU CH32V307
基于工业级互联型RISC-V MCU CH32V307,通过讲解RISC-V常用汇编指令,分析CH32V307的每个外设功能及使用方法,配合详细的示例代码,帮助大家熟悉RISC-V平台的嵌入式开发。
CH32V307配备了硬件堆栈区、快速中断入口,在标准RISC-V基础上大大提高了中断响应速度。加入单精度浮点指令集,扩充堆栈区,具有更高的运算性能。扩展串口U(S)ART数量到8组,电机定时器到4组。提供USB2.0高速接口(480Mbps)并内置了PHY收发器,以太网MAC升级到千兆并集成了10M-PHY模块。
详细参数如下:

目录
从技术的角度来看,以RISC为架构体系的ARM指令集的指令格式统一、种类少、寻址方式少,简单的指令意味着相应硬件线路可以尽量做到最佳化,从而提高执行速率。而RISC-V指令集,也是基于RISC原理建立的开放指令集架构(ISA)。两者区别可能在于,ARM标准授权方式只能根据自身需求,调整产品频率和功耗,不可以更改原有设计,以至于ARM架构文档冗长,指令数目复杂;RISC-V规避了这个缺点,架构文档页数仅有200多页,指令数目少,自由定制,操作方便。
一旦成为行业标准,垄断态势便会出现。ARM的技术授权模式会要求客户选择一种特定的芯片设计方案,并且支付许可费,这笔费用可能会达到上百万美金,芯片投产以后,再按照芯片量缴纳授权费。对于大型公司来说,一次性支付大笔许可费在实力允许范围内;对于小型公司而言,许可费便会牵制住其前进的脚步。ARM新的收费模式,允许芯片厂商能够支付一笔适量的预付款,便可以获得需要的所有芯片技术组合,这个组合会包括SOC设计所需的基本知识产权和工具,芯片生产是再支付授权费和专利费即可。有人说,ARM推出新的授权方式是迫于RISC-V开源架构带来的市场压力,其实有一定道理。
2010年,加州大学伯克利分校的一个研究团队准备设计CPU是,在选择指令集是遇到了困难,英特尔严防死守、ARM授权费太贵。无奈之下,花费了四年时间完成了RISC-V的指令集开发,并且该指令集彻底开放。正是因为RISC-V选择了对商业公司非常友好的BSD开源协议,以及RISC-V兼具精简和灵活等优点,众多商业公司纷纷关注RISC-V。
2010年,加州大学伯克利分校的一个研究团队正在准备启动一个新项目。在为新项目选择指令集的时候,他们发现,x86指令集被Intel控制得死死的,ARM指令集的授权费又非常贵,MIPS、SPARC、PowerPC也存在知识产权问题。在这种情况下,研究团队毅然决定,从零开始,设计一套全新的指令集。在外人看来,这是一件令人望而却步的工作。但事实上,伯克利的研究团队只召集了一个4人小组,用了3个月的时间,就完成了RISC-V的指令集开发。虽然看似非常轻松,但其实是有前提的。RISC-V之所以是个V(Five),就是因为它之前已经有过I、II、III、IV。负责带队研制这些RISC指令集的,不是别人,正是伯克利分校的David Patterson教授,就是RISC指令集的真正创始人。当年那篇正式提出精简指令集设计思想的开创性论文——《精简指令集计算机概述》,就是他和另一位名叫Ditzel的学者共同发表的。正是因为有相关的技术沉淀,伯克利分校的团队才能在短期内做出了RISC-V。
RISC-V指令集非常精简和灵活。它的第一个版本只包含了不到50条指令,可以用于实现一个具备定点运算和特权模式等基本功能的处理器。如果用户需要的话,也可以根据自己的需求自定义新指令。
高校毕竟是高校,功利心没有那么重。再加上研究团队本身确实也没钱没人去维护它。所以,在做出RISC-V指令集之后,研究团队决定,将它彻底开放,使用BSD License开源协议。BSD(Berkeley Software Distribution)开源协议是一个自由度非常大的协议,几乎可以说是“为所欲为”。它允许使用者修改和重新发布开源代码,也允许基于开源代码开发商业软件发布和销售。这就意味着,任何人都可以基于RISC-V指令集进行芯片设计和开发,然后拿去卖钱,而不需要支付授权费用。这就很好了,大批公司开始加入对RISC-V的研究和二次开发之中。
短短几年的时间里,包括谷歌、华为、IBM、镁光、英伟达、高通、三星、西部数据等商业公司,以及加州大学伯克利分校、麻省理工学院、普林斯顿大学、ETH Zurich、印度理工学院、洛伦兹国家实验室、新加坡南洋理工大学以及中科院计算所等学术机构,都纷纷加入RISC-V基金会。目前,RISC-V基金会共有包括18家白金会员在内的235家会员单位(数据截止2019年7月10日)。这些会员单位中包含了半导体设计制造公司、系统集成商、设备制造商、军工企业、科研机构、高校等各式各样的组织,足以说明RISC-V的影响力在不断扩大。因此,包括中科院计算所、华为公司、阿里巴巴集团等在内的20多个国内企事业单位,选择加入了RISC-V基金会。阿里还是其中的白金会员。2018年7月,上海经信委出台了国内首个支持RISC-V的政策。10月,中国RISC-V产业联盟成立。产品方面,中天微和华米科技先后发布了基于RISC-V指令集的处理器。
随着高通入股 sifive,清华伯克利联合成立国际 Risc-V 实验室,以及华米发布采用自研 Risc-V 的小米手环4,Risc-V 势头越发凶猛,大有追赶 ARM 之势。在技术上,Linux 5.1 官方内核默认支持了 Risc-V,Qemu 4.0.0 对 Risc-V 也提供了全面支持,而 Qemu Risc-V Hypervisor / Xvisor 模拟也在紧锣密鼓开展,系统层面,Buildroot, Openembedded,Debian,Fedora 的开发也如火如荼。
ARM公司就专门建了一个域名为riscv-basics.com的网站,里面的内容主题为“设计系统芯片之前需要考虑的五件事”,从成本、生态系统、碎片化风险、安全性和设计保证上对RISC-V进行攻击。
尽管RISC-V在这场短暂的竞争中获胜,但ARM提出的那五个方面的质疑,也不是完全没有道理。尤其是碎片化问题,作为开源技术,RISC-V的确很难规避。
所谓碎片化:由于RISC-V允许用户自己任意添加新的指令,但照此趋势发展下去,可能以后很多芯片厂商开发出的RISC-V架构处理器尽管都归属于同一RISC-V体系,但在实际应用搭配时,却不能够适配同样版本的软件。
RISC-V是一个典型三操作数、加载-存储形式的RISC架构,包括三个基本指令集和6个扩展指令集,如表1.1所示,其中RV32E是RV32I的子集,不单独计算。
表1.1 RISC-V的指令集组成。
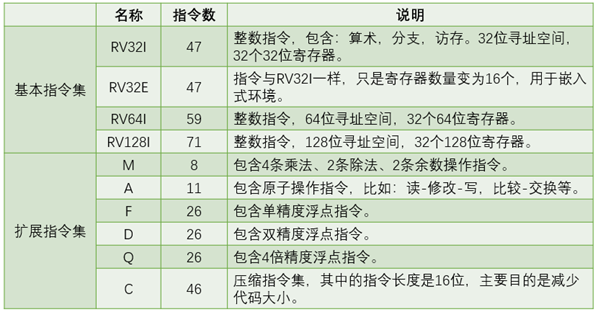
基本指令集的名称后缀都是I,表示Integer,任何一款采用RISC-V架构的处理器都要实现一个基本指令集,根据需要,可以实现多种扩展指令集,例如:如果实现了RV32IM,表示实现了32位基本指令集和乘法除法扩展指令集。如果实现了RV32IMAFD,那么可以使用RV32G来表示,表示实现了通用标量处理器指令集。这里只介绍RV32I的基本情况。
RV32I 指令集有47条指令,能够满足现代操作系统运行的基本要求,47条指令按照功能可以分为如下几类。 1)整数运算指令:实现算术、逻辑、比较等运算。 2)分支转移指令:实现条件转移、无条件转移等运算,并且没有延迟槽。 3)加载存储指令:实现字节、半字、字的加载、存储操作,采用的都是寄存器相对寻址方式。 4)控制与状态寄存器访问指令:实现对系统控制与状态寄存器的原子读-写、原子读-修改、原子读-清零等操作。 5)系统调用指令:实现系统调用、调试等功能。
模块化的RISC-V架构,能够使得用户能够灵活选择不同的模块组合,以满足不同的应用场景。譬如针对于小面积低功耗嵌入式场景,用户可以选择RV32IC组合的指令集,仅使用Machine Mode(机器模式);而高性能应用操作系统场景,则可以选择譬如RV32IMFDC的指令集,使用Machine Mode(机器模式)与User Mode(用户模式)两种模式。而他们共同的部分则可以相互兼容。
ARM的架构分为A、R和M三个系列,分别针对于Application(应用操作系统)、Real-Time(实时)和Embedded(嵌入式)三个领域,彼此之间并不兼容。
RISC-V架构支持32位或者64位的架构,32位架构由RV32表示,其每个通用寄存器的宽度为32比特;64位架构由RV64表示,其每个通用寄存器的宽度为64比特。
RISC-V架构的整数通用寄存器组,包含32个(I架构)或者16个(E架构)通用整数寄存器,其中整数寄存器0被预留为常数0,其他的31个(I架构)或者15个(E架构)为普通的通用整数寄存器。
如果使用了浮点模块(F或者D),则需要另外一个独立的浮点寄存器组,包含32个通用浮点寄存器。如果仅使用F模块的浮点指令子集,则每个通用浮点寄存器的宽度为32比特;如果使用了D模块的浮点指令子集,则每个通用浮点寄存器的宽度为64比特。
在流水线中能够尽早尽快的读取通用寄存器组,往往是处理器流水线设计的期望之一,这样可以提高处理器性能和优化时序。这个看似简单的道理,在很多现存的商用RISC架构中都难以实现,因为经过多年反复修改,不断添加新指令后,其指令编码中的寄存器索引位置变得非常的凌乱,给译码器造成了负担。
得益于后发优势,同时总结了多年来处理器发展的教训,RISC-V的指令集编码非常的规整,指令所需的通用寄存器的索引(Index)都被放在固定的位置,如图1.2所示。因此指令译码器(Instruction Decoder)可以非常便捷的译码出寄存器索引,然后读取通用寄存器组(Register File,Regfile)。

与所有的RISC处理器架构一样,RISC-V架构使用专用的存储器读(Load)指令和存储器写(Store)指令访问存储器(Memory),其他的普通指令无法访问存储器,这种架构是RISC架构的常用的一个基本策略,这种策略使得处理器核的硬件设计变得简单。
存储器访问的基本单位是字节(Byte)。RISC-V的存储器读和存储器写指令支持一个字节(8位),半字(16位),单字(32位)为单位的存储器读写操作,如果是64位架构还可以支持一个双字(64位)为单位的存储器读写操作。
RISC-V架构的存储器访问指令还有如下显著特点:
1)为了提高存储器读写的性能,RISC-V架构推荐使用地址对齐的存储器读写操作,但是地址非对齐的存储器操作RISC-V架构也支持,处理器可以选择用硬件来支持,也可以选择用软件来支持。
2)由于现在的主流应用是小端格式(Little-Endian),RISC-V架构仅支持小端格式。有关小端格式和大端格式的定义和区别,本文在此不做过多介绍,若对此不甚了解的初学者可以自行查阅学习。
3)很多的RISC处理器都支持地址自增或者自减模式,这种自增或者自减的模式虽然能够提高处理器访问连续存储器地址区间的性能,但是也增加了设计处理器的难度。RISC-V架构的存储器读和存储器写指令不支持地址自增自减的模式。
4)RISC-V架构采用松散存储器模型(Relaxed Memory Model),松散存储器模型对于访问不同地址的存储器读写指令的执行顺序不作要求,除非使用明确的存储器屏障(Fence)指令加以屏蔽。
这些选择都清楚地反映了RISC-V架构,力图简化基本指令集,从而简化硬件设计的哲学。RISC-V架构如此定义非常合理,能够达到能屈能伸的效果。譬如:对于低功耗的简单CPU,可以使用非常简单的硬件电路,即可完成设计;而对于追求高性能的超标量处理器,则可以通过复杂设计的动态硬件调度能力来提高性能。
1)RISC-V架构有两条无条件跳转指令(Unconditional Jump),jal与jalr指令。跳转链接(Jump and Link)指令jal可用于进行子程序调用,同时将子程序返回地址存在链接寄存器(Link Register:由某一个通用整数寄存器担任)中。跳转链接寄存器(Jump and Link-Register)指令jalr指令能够用于子程序返回指令,通过将jal指令(跳转进入子程序)保存的链接寄存器用于jalr指令的基地址寄存器,则可以从子程序返回。
2)RISC-V架构有6条带条件跳转指令(Conditional Branch),这种带条件的跳转指令跟普通的运算指令一样直接使用2个整数操作数,然后对其进行比较,如果比较的条件满足时,则进行跳转。因此,此类指令将比较与跳转两个操作放到了一条指令里完成。
作为比较,很多的其他RISC架构的处理器需要使用两条独立的指令。第一条指令先使用比较指令,比较的结果被保存到状态寄存器之中;第二条指令使用跳转指令,判断前一条指令保存在状态寄存器当中的比较结果为真时则进行跳转。相比而言RISC-V的这种带条件跳转指令不仅减少了指令的条数,同时硬件设计上更加简单。
3)对于没有配备硬件分支预测器的低端CPU,为了保证其性能,RISC-V的架构明确要求其采用默认的静态分支预测机制,即:如果是向后跳转的条件跳转指令,则预测为“跳”;如果是向前跳转的条件跳转指令,则预测为“不跳”,并且RISC-V架构要求编译器也按照这种默认的静态分支预测机制来编译生成汇编代码,从而让低端的CPU也能得到不错的性能。
为了使硬件设计尽量简单,RISC-V架构特地定义了所有的带条件跳转指令跳转目标的偏移量(相对于当前指令的地址)都是有符号数,并且其符号位被编码在固定的位置。因此,这种静态预测机制在硬件上非常容易实现,硬件译码器可以轻松的找到这个固定的位置,并判断其是0还是1来判断其是正数还是负数,如果是负数则表示跳转的目标地址为当前地址减去偏移量,也就是向后跳转,则预测为“跳”。当然对于配备有硬件分支预测器的高端CPU,则可以采用高级的动态分支预测机制来保证性能。
为了理解此节,需先对一般RISC架构中程序调用子函数的过程予以介绍,其过程如下:
1)进入子函数之后需要用存储器写(Store)指令来将当前的上下文(通用寄存器等的值)保存到系统存储器的堆栈区内,这个过程通常称为“保存现场”。
2)在退出子程序之时,需要用存储器读(Load)指令来将之前保存的上下文(通用寄存器等的值)从系统存储器的堆栈区读出来,这个过程通常称为“恢复现场”。
“保存现场”和“恢复现场”的过程,通常由编译器编译生成的指令来完成,使用高层语言(譬如C或者C++)开发的开发者,对此可以不用太关心。高层语言的程序中,直接写上一个子函数调用即可,但是这个底层发生的“保存现场”和“恢复现场”的过程,却是实实在在地发生着(可以从编译出的汇编语言里面,看到那些“保存现场”和“恢复现场”的汇编指令),并且还需要消耗若干的CPU执行时间。
为了加速这个“保存现场”和“恢复现场”的过程,有的RISC架构发明了一次写多个寄存器到存储器中(Store Multiple),或者一次从存储器中读多个寄存器出来(Load Multiple)的指令,此类指令的好处是,一条指令就可以完成很多事情,从而减少汇编指令的代码量,节省代码的空间大小。但是此种“Load Multiple”和“Store Multiple”的弊端是,会让CPU的硬件设计变得复杂,增加硬件的开销,也可能损伤时序使得CPU的主频无法提高,在设计此类处理器时,一般需要克服不少困难。
RISC-V架构则放弃使用这种“Load Multiple”和“Store Multiple”指令。并解释,如果有的场合比较介意这种“保存现场”和“恢复现场”的指令条数,那么可以使用公用的程序库(专门用于保存和恢复现场)来进行,这样就可以省掉,在每个子函数调用的过程中,都放置数目不等的“保存现场”和“恢复现场”的指令。
此选择再次印证了RISC-V追求硬件简单的哲学,因为放弃“Load Multiple”和“Store Multiple”指令,可以大幅简化CPU的硬件设计,对于低功耗小面积的CPU,可以选择非常简单的电路进行实现,而高性能超标量处理器,由于硬件动态调度能力很强,可以有强大的分支预测电路,保证CPU能够快速的跳转执行,从而可以选择使用公用的程序库(专门用于保存和恢复现场)的方式,减少代码量,但是同时达到高性能。
很多早期的RISC架构发明了带条件码的指令,譬如在指令编码的头几位表示的是条件码(Conditional Code),只有该条件码对应的条件为真时,该指令才被真正执行。
这种将条件码编码到指令中的形式,可以使得编译器将短小的循环,编译成带条件码的指令,而不用编译成分支跳转指令。这样便减少了分支跳转的出现,一方面减少了指令的数目;另一方面也避免了分支跳转带来的性能损失。然而,这种“条件码”指令的弊端,同样会使得CPU的硬件设计变得复杂,增加硬件的开销,也可能损伤时序使得CPU的主频无法提高,笔者在曾经设计此类处理器时便深受其苦。
RISC-V架构则放弃使用这种带“条件码”指令的方式,对于任何的条件判断,都使用普通的带条件分支跳转指令。此选择再次印证了RISC-V追求硬件简单的哲学,因为放弃带“条件码”指令的方式,可以大幅简化CPU的硬件设计,对于低功耗小面积的CPU,可以选择非常简单的电路进行实现,而高性能超标量处理器,由于硬件动态调度能力很强,可以有强大的分支预测电路,保证CPU能够快速的跳转执行达到高性能。
很多早期的RISC架构均使用了“分支延迟槽(Delay Slot)”,最具有代表性的便是MIPS架构,在很多经典的计算机体系结构教材中,均使用MIPS对分支延迟槽进行过介绍。分支延迟槽就是指,在每一条分支指令后面,紧跟的一条或者若干条指令,不受分支跳转的影响,不管分支是否跳转,这后面的几条指令都一定会被执行。
早期的RISC架构,很多采用了分支延迟槽诞生的原因,主要是因为当时的处理器流水线比较简单,没有使用高级的硬件动态分支预测器,所以使用分支延迟槽,能够取得可观的性能效果。然而,这种分支延迟槽,使得CPU的硬件设计变得极为的别扭,CPU设计人员对此往往苦不堪言。
RISC-V架构则放弃了分支延迟槽,再次印证了RISC-V力图简化硬件的哲学,因为现代的高性能处理器的分支预测算法精度已经非常高,可以有强大的分支预测电路,保证CPU能够准确的预测跳转执行达到高性能。而对于低功耗小面积的CPU,由于无需支持分支延迟槽,硬件得到极大简化,也能进一步减少功耗和提高时序。
很多RISC架构还支持零开销硬件循环(Zero Overhead Hardware Loop)指令,其思想是通过硬件的直接参与,通过设置某些循环次数寄存器(Loop Count),然后可以让程序自动地进行循环,每一次循环则Loop Count自动减1,这样持续循环直到Loop Count的值变成0,则退出循环。
之所以提出发明这种硬件协助的零开销循环,是因为在软件代码中的for 循环(for i=0; i<N; i++)极为常见,而这种软件代码通过编译器编译之后,往往会编译成若干条加法指令和条件分支跳转指令,从而达到循环的效果。一方面这些加法和条件跳转指令占据了指令的条数;另外一方面条件分支跳转,如存在着分支预测的性能问题。而硬件协助的零开销循环,则将这些工作由硬件直接完成,省掉了这些加法和条件跳转指令,减少了指令条数且提高了性能。
然而有得必有失,此类零开销硬件循环指令,大幅地增加了硬件设计的复杂度。因此,零开销循环指令与RISC-V架构简化硬件的哲学是完全相反的,在RISC-V架构中,自然没有使用此类零开销硬件循环指令。
在RISC-V架构使用模块化的方式组织不同的指令子集,最基本的整数指令子集(I字母表示)支持的运算,包括加法、减法、移位、按位逻辑操作和比较操作。这些基本的运算操作,能够通过组合或者函数库的方式,完成更多的复杂操作(譬如乘除法和浮点操作),从而能够完成大多数的软件操作。
整数乘除法指令子集(M字母表示)支持的运算包括,有符号或者无符号的乘法和除法操作。乘法操作能够支持两个32位的整数相乘,得到一个64位的结果;除法操作能够支持两个32位的整数相除,得到一个32位的商与32位的余数。
单精度浮点指令子集(F字母表示)与双精度浮点指令子集(D字母表示)支持的运算,包括浮点加减法,乘除法,乘累加,开平方根和比较等操作,同时提供整数与浮点,单精度与双精度浮点彼此之间的格式转换操作。
很多RISC架构的处理器在运算指令产生错误之时,譬如上溢(Overflow)、下溢(Underflow)、非规格化浮点数(Subnormal)和除零(Divide by Zero),都会产生软件异常。RISC-V架构的一个特殊之处是,对任何的运算指令错误(包括整数与浮点指令)均不产生异常,而是产生某个特殊的默认值,同时,设置某些状态寄存器的状态位。RISC-V架构推荐软件通过其他方法来找到这些错误。再次清楚地反映了RISC-V架构力图简化基本的指令集,从而简化硬件设计的哲学。
基本的RISC-V基本整数指令子集(字母I表示 )规定的指令长度,均为等长的32位,这种等长指令定义,使得仅支持整数指令子集的基本RISC-V CPU,非常容易设计。但是等长的32位编码指令,也会造成代码体积(Code Size)相对较大的问题。
为了满足某些对于代码体积要求较高的场景(譬如嵌入式领域),RISC-V定义了一种可选的压缩(Compressed)指令子集,由字母C表示,也可以由RVC表示。RISC-V具有后发优势,从一开始便规划了压缩指令,预留了足够的编码空间,16位长指令与普通的32位长指令,可以无缝自由地交织在一起,处理器也没有定义额外的状态。
RISC-V压缩指令的另外一个特别之处是,16位指令的压缩策略是,将一部分普通最常用的的32位指令中的信息,进行压缩重排得到(譬如假设一条指令使用了两个同样的操作数索引,则可以省去其中一个索引的编码空间),因此每一条16位长的指令,都能一一找到其对应的原始32位指令。因此,程序编译成为压缩指令,仅在汇编器阶段就可以完成,极大的简化了编译器工具链的负担。
RISC-V架构的研究者进行了详细的代码体积分析,如图3所示,通过分析结果可以看出,RV32C的代码体积相比RV32的代码,体积减少了百分之四十,并且与ARM,MIPS和x86等架构相比,都有不错的表现。
RISC-V架构定义了三种工作模式,又称特权模式(Privileged Mode):
1)Machine Mode:机器模式,简称M Mode。
2)Supervisor Mode:监督模式,简称S Mode。
3)User Mode:用户模式,简称U Mode。
RISC-V架构定义M Mode为必选模式,另外两种为可选模式。通过不同的模式组合,可以实现不同的系统。
RISC-V架构也支持几种不同的存储器地址管理机制,包括对于物理地址和虚拟地址的管理机制,使得RISC-V架构能够支持,从简单的嵌入式系统(直接操作物理地址),到复杂的操作系统(直接操作虚拟地址)的各种系统。
RISC-V架构定义了一些控制和状态寄存器(Control and Status Register,CSR),用于配置或记录一些运行的状态。CSR寄存器是处理器核内部的寄存器,使用其自己的地址编码空间和存储器寻址的地址区间完全无关系。
CSR寄存器的访问采用专用的CSR指令,包括CSRRW、CSRRS、CSRRC、CSRRWI、CSRRSI以及CSRRCI指令。
中断和异常机制往往是处理器指令集架构中,最为复杂而关键的部分。RISC-V架构定义了一套相对简单基本的中断和异常机制,但是也允许用户对其进行定制和扩展。
RISC-V架构目前虽然还没有定型矢量(Vector)指令子集,但是从目前的草案中已经可以看出,RISC-V矢量指令子集的设计理念非常的先进,由于后发优势及借助矢量架构多年发展成熟的结论,RISC-V架构将使用可变长度的矢量,而不是矢量定长的SIMD指令集(譬如ARM的NEON和Intel的MMX),从而能够灵活的支持不同的实现。追求低功耗小面积的CPU,可以选择使用长度较短的硬件矢量进行实现,而高性能的CPU,则可以选择较长的硬件矢量进行实现,并且同样的软件代码能够彼此兼容。
除了上述阐述的模块化指令子集的可扩展、可选择,RISC-V架构还有一个非常重要的特性,那就是支持第三方的扩展。用户可以扩展自己的指令子集,RISC-V预留了大量的指令编码空间,用于用户的自定义扩展,同时,还定义了四条Custom指令,可供用户直接使用,每条Custom指令,都有几个比特位的子编码空间预留,因此,用户可以直接使用四条Custom指令,扩展出几十条自定义的指令。
处理器设计技术经过几十年的衍进,随着大规模集成电路设计技术的发展直至今天,呈现出如下特点:
1)由于高性能处理器的硬件调度能力已经非常强劲且主频很高,因此,硬件设计希望指令集尽可能的规整、简单,从而,使得处理器可以设计出更高的主频与更低的面积。
2)以IoT应用为主的极低功耗处理器更加苛求低功耗与低面积。
3)存储器的资源也比早期的RISC处理器更加丰富。
如上种种这些因素,使得很多早期的RISC架构设计理念(依据当时技术背景而诞生),时至今日不仅不能帮助现代处理器设计,反而成了负担桎梏。某些早期RISC架构定义的特性,一方面使得高性能处理器的硬件设计束手束脚;另一方面又使得极低功耗的处理器硬件设计,背负不必要的复杂度。
得益于后发优势,全新的RISC-V架构,能够规避所有这些已知的负担,同时,利用其先进的设计哲学,设计出一套“现代”的指令集。这里再次将其特点总结如表1.2所示。表1.3表示RISC-V指令实现流程与性能参数特性。
表1.2 RISC-V指令集架构特点总结
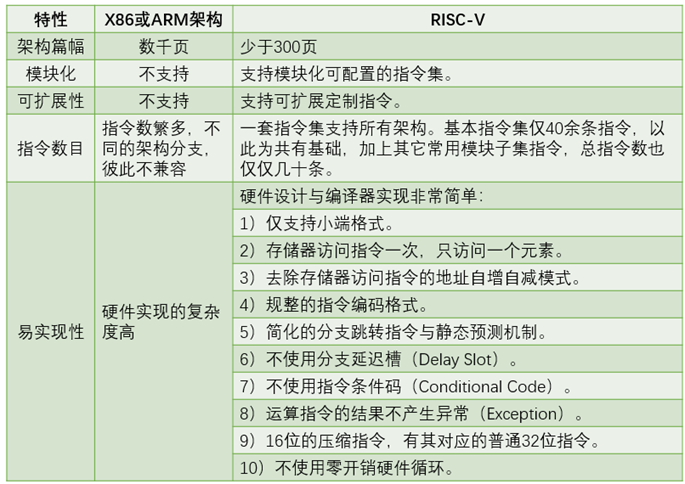
表1.3 RISC-V指令实现流程与性能参数特性

一言以蔽之,RISC-V的特点在于极简、模块化以及可定制扩展,通过这些指令集的组合或者扩展,几乎可以构建适用于任何一个领域的微处理器,比如云计算、存储、并行计算、虚拟化/容器、MCU、应用处理器和DSP处理器等。
目前基于RISC-V架构的开源处理器有很多,既有标量处理器Rocket,也有超标量处理器BOOM,还有面向嵌入式领域的Z-scale、PicoRV32等。
Rocket是UCB设计的一款64位、5级流水线、单发射顺序执行处理器,主要特点有:
1)支持MMU,支持分页虚拟内存,所以可以移植Linux操作系统。
2)具有兼容IEEE 754-2008标准的FPU。
3)具有分支预测功能,具有BTB(Branch Prediction Buff)、BHT(Branch History Table)、RAS(Return Address Stack)。
表1.3表示ARM Cortex-A5与采用RISC-V指令集架构的Rocket比较
表1.3 ARM Cortex-A5与采用RISC-V指令集架构的Rocket比较
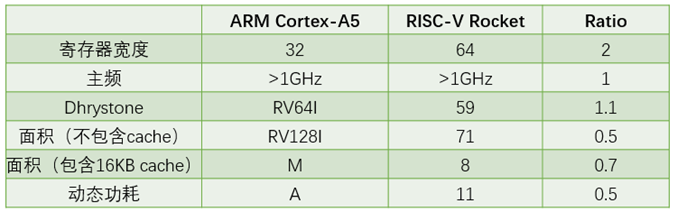
UCB的研究人员设计的一款采用RISC-V指令集架构的开源处理器Rocket,并且已经成功流片了11次,其中采用台积电40nm工艺时的性能与采用同样工艺的,都是标量处理器的ARM Cortex-A5的性能对比如表3所示。可见Rocket占用更小的面积,使用更小的功耗,但是性能却更优。
Rocket是采用Chisel(Constructing Hardware in an Scala Embedded Language)编写的,这也是UCB设计的一种开源的硬件编程语言,是Scala语言的领域特定应用,可以充分利用Scala的优势,将面向对象(object orientation)、函数式编程(functional programming)、类型参数化(parameterized types)、类型推断(type inference)等概念引入硬件编程语言,从而提供更加强大的硬件开发能力。Chisel除了开源之外,还有一个优势就是使用Chisel编写的硬件电路,可以通过编译得到对应的Verilog设计,还可以得到对应的C++模拟器。Rocket使用Chisel编写,就可以很容易得到对应的软件模拟器。同时,因为Chisel是面向对象的,所以Rocket的很多类可以被其他开源处理器、开源SoC直接使用。
BOOM(Berkeley Out-of-Order Machine)是UCB设计的一款64位超标量、乱序执行处理器,支持RV64G,也是采用Chisel编写,利用Chisel的优势,只使用了9000行代码,流水线可以划分为六个阶段:取指、译码/重命名/指令分配、发射/读寄存器、执行、访存、回写。
借助于Chisel,BOOM是可参数化配置的超标量处理器,可配置的参数包括:
· 重排序缓存ROB(Re-Order Buffer)、物理寄存器的大小
· 取指令缓存、RAS、BTB、加载、存储队列的深度
· MSHRs(Miss Status Handling Registers)的大小
· 是否使能L2 Cache
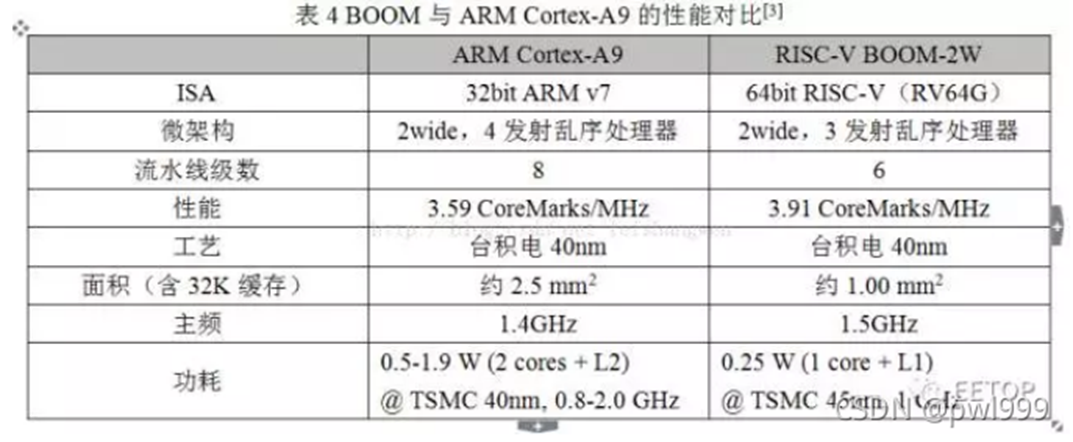
UCB已经在40nm工艺上对BOOM进行了流片,测试结果如表4所示。可见BOOM与商业产品ARM Cortex-A9的性能要略优,体现在面积小、功耗低。
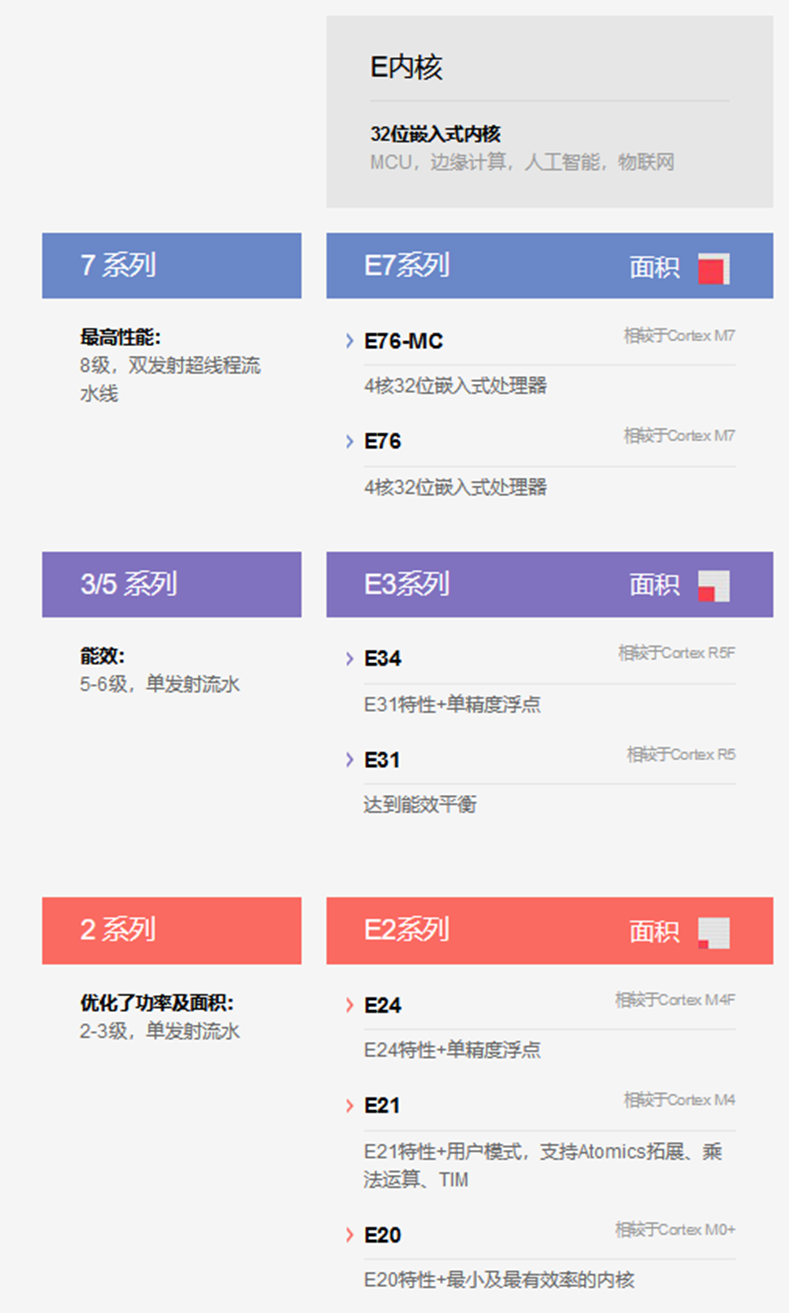
SiFive总部位于旧金山,专注于实现定制硅芯片设计的民主化。该公司的创始人发明了RISC-V,这是一种适用于现代微处理器的自由开放的指令集架构。SiFive正在采用该体系结构,并轻松设计公司所需的自定义变体。sifive ip 系列:
4.2 平头哥
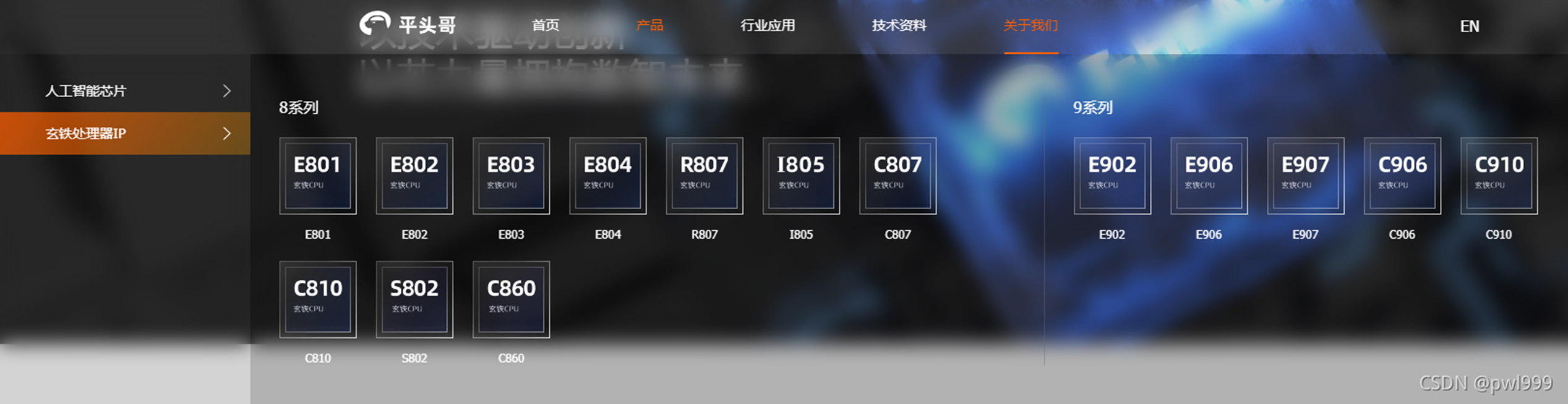
平头哥半导体有限公司成立于2018年9月19日,是阿里巴巴集团的全资半导体芯片业务主体。平头哥拥有端云一体全栈产品系列,涵盖数据中心人工智能芯片、处理器IP授权等,实现芯片端到端设计链路全覆盖。t-head ip 系列:
4.3 Andes
晶心科技为台湾原创性32位元嵌入式微处理器核心智财与系统晶片设计平台公司,在嵌入式微处理器领域,晶心从零开始,经过十余年之深耕,目前已经在全球矽智财厂中,处于领先之地位。andes ip 系列:
4.4 芯来科技
芯来科技是一家具有代表性的RISC-V处理器内核IP和解决方案公司,该公司创造了我国第一颗开源RISC-V处理器项目——蜂鸟E203。据编者了解,蜂鸟E203支持协处理器接口进行指令扩展,并提供内嵌的ITCM与DTCM。同时,核心功耗面积和性能届不逊色于ARM的Cortex-M0+处理器核(M0+ 是ARM最小面积的处理器核)。得益于芯来的“一分钱计划”,蜂鸟E203目前也被国内多数公司所采用。
芯来科技(Nuclei System Technology)成立于2018年6月,是中国大陆首家专业RISC-V处理器IP和芯片解决方案公司。芯来 ip 系列:

· N100系列处理器内核主要面向极低功耗与极小面积的场景而设计,非常适合传统的8位内核或16位内核升级需求,可广泛应用于模混合、IoT或其他超低功耗场景。
· N200系列32位超低功耗RISC-V处理器为物联网IoT终端设备的感知,连接,控制以及轻量级智能应用而设计。
· N300系列32位超低功耗RISC-V处理器面向机制能效比且需要DSP,FPU特性的场景而设计,应用于IoT和工业控制等场景。
· N600系列32位RISC-V处理器面向实时控制或高性能嵌入式应用场景,应用于AIoT边缘计算,存储或其他实时控制应用。
· N900系列是面向高性能领域的32位RISC-V应用处理器,应用于AIoT边缘计算,数据中心,网络设备和基带通信等领域。
黄山1/2号。华米科技发布了全球可穿戴领域第一颗人工智能芯片“黄山1号“。这颗芯片基于RISC-V指令集架构开发,240MHz主频、55nm制程,并且集成了AON(Always On)模块控制器和神经网络加速模块。
黄山1号不仅功耗低,还可以自动将传感器数据搬运到内部 SRAM之中,让数据存储性能更快、更稳定。而更为值得称道的是,它集成了神经网络加速模块,能够本地化处理AI任务 —— 通过Heart Rate、ECG Engine、ECG Engine Pro、Arrhythmias四大驱动引擎,对心率、心电、心律失常等进行实时监测与分析,可广泛应用在各类智能可穿戴设备中。
https://www.cnblogs.com/wahahahehehe/p/15574316.html
https://www.cnblogs.com/pwl999/p/15534963.html