2023数据采集与融合技术实践作业3
作业1
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn/(要求:指定--个网站,爬取这个网站中的所有的所有图片,例如中国气象网)
输出信息:将下载的url信息在控制台输出,并将下载的图片存储在images子文件夹中,并给出截图
spider代码
class QixiangSpider(scrapy.Spider):
name = "spider1"
start_url = "http://www.weather.com.cn/"
def start_requests(self):
url = QixiangSpider.start_url
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response, **kwargs):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
qixiangs = selector.xpath("//img")
for qixiang in qixiangs:
item = qixiangItem()
item["url"] = qixiang.xpath("./@src").extract_first()
print(item["url"])
yield item
except Exception as err:
print(err)
item代码
class qixiangItem(scrapy.Item):
url = scrapy.Field()
pass
pipeline代码
class MyspiderPipeline1:
count = 0
def process_item(self, item, spider):
img_url = item['url']
MyspiderPipeline1.count += 1
urllib.request.urlretrieve(img_url,filename=f"D:/myspider/myspider/spiders/images/{MyspiderPipeline1.count}.{img_url.split('.')[-1]}")
return item

运行run.py可查看下载结果
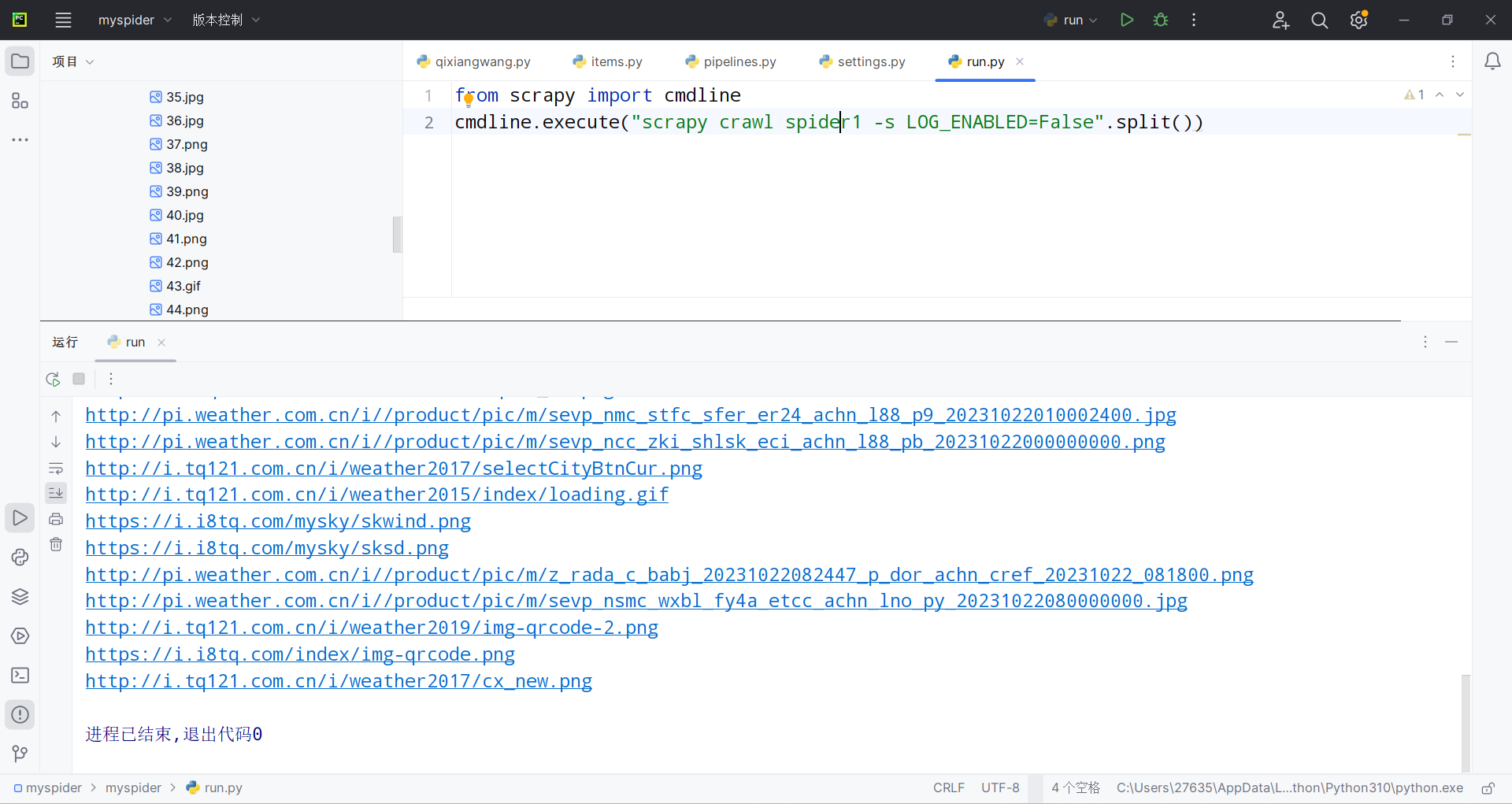
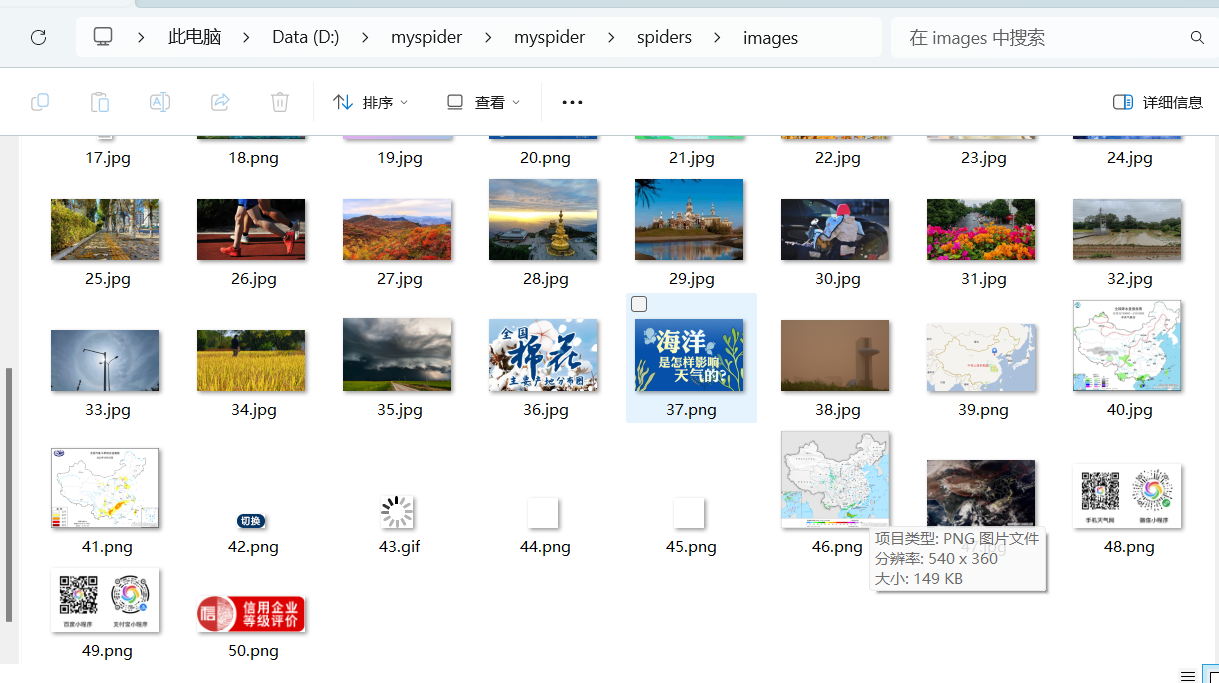
gitee链接:https://gitee.com/lxmlmx/crawl_project/tree/master/作业3
心得体会:学会运用scrapy多线程爬取网站数据
作业2
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网: https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计

pipeline代码
class MyspiderPipeline2:
def process_item(self, item, spider):
self.mydb = pymysql.connect(
host="192.168.149.1",
port=3306,
user='root',
password='123456',
database="stock",
charset='utf8'
)
self.cursor = self.mydb.cursor()
self.cursor.execute('''CREATE TABLE IF NOT EXISTS stocks(
stockname VARCHAR(256),
name VARCHAR(256),
newprice VARCHAR(256),
zhangdiefu VARCHAR(256),
zhangdieer VARCHAR(256),
chengjiaoliang VARCHAR(256),
chengjiaoer VARCHAR(256),
zhenfu VARCHAR(256),
zuigao VARCHAR(256),
zuidi VARCHAR(256),
jinkai VARCHAR(256),
zuoshou VARCHAR(256)
)''')
self.mydb.commit()
sql = "insert into stocks values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql,(item.get("stockname"),item.get("name"),item.get("newprice"), item.get("zhangdiefu"),item.get("zhangdieer"), item.get("chengjiaoliang"), item.get("chengjiaoer"), item.get("zhenfu"), item.get("zuigao"),item.get("zuidi"), item.get("jinkai"),item.get("zuoshou")))
print("succssfully conn1ctd!")
self.mydb.commit()
return item
def close_spider(self, spider):
self.mydb.close()
stock代码
import scrapy
import requests
import re
from myspider.items import StockItem
from bs4 import UnicodeDammit
class StockSpider(scrapy.Spider):
name = "spider2"
start_url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
def start_requests(self):
url = StockSpider.start_url
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response, **kwargs):
try:
stocks = []
url = "https://68.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124009413428787683675_1696660278138&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f12,f14,f2,f3,f4,f5,f6,f7,f15,f16,f17,f18&_=1696660278155"
r = requests.get(url=url)
data = re.compile("\"f2\":.*").findall(r.text)
data1 = data[0].split("},{")
data1[-1] = data1[-1].split("}")[0]
for i in range(len(data1)):
stock0 = data1[i].replace('"', "").split(",")
list = [6, 7, 0, 1, 2, 3, 4, 5, 8, 9, 10, 11]
stock = []
for j in list:
stock.append(stock0[j].split(":")[1])
stocks.append(stock)
print(stocks[0][0])
for i in range(len(stocks)):
item = StockItem()
item["stockname"] = stocks[i][0]
item["name"] = stocks[i][1]
item["newprice"] = stocks[i][2]
item["zhangdiefu"] = stocks[i][3]
item["zhangdieer"] = stocks[i][4]
item["chengjiaoliang"] = stocks[i][5]
item["chengjiaoer"] = stocks[i][6]
item["zhenfu"] = stocks[i][7]
item["zuigao"] = stocks[i][8]
item["zuidi"] = stocks[i][9]
item["jinkai"] =stocks[i][10]
item["zuoshou"] = stocks[i][11]
print(item)
yield item
except Exception as err:
print(err)
运行结果:
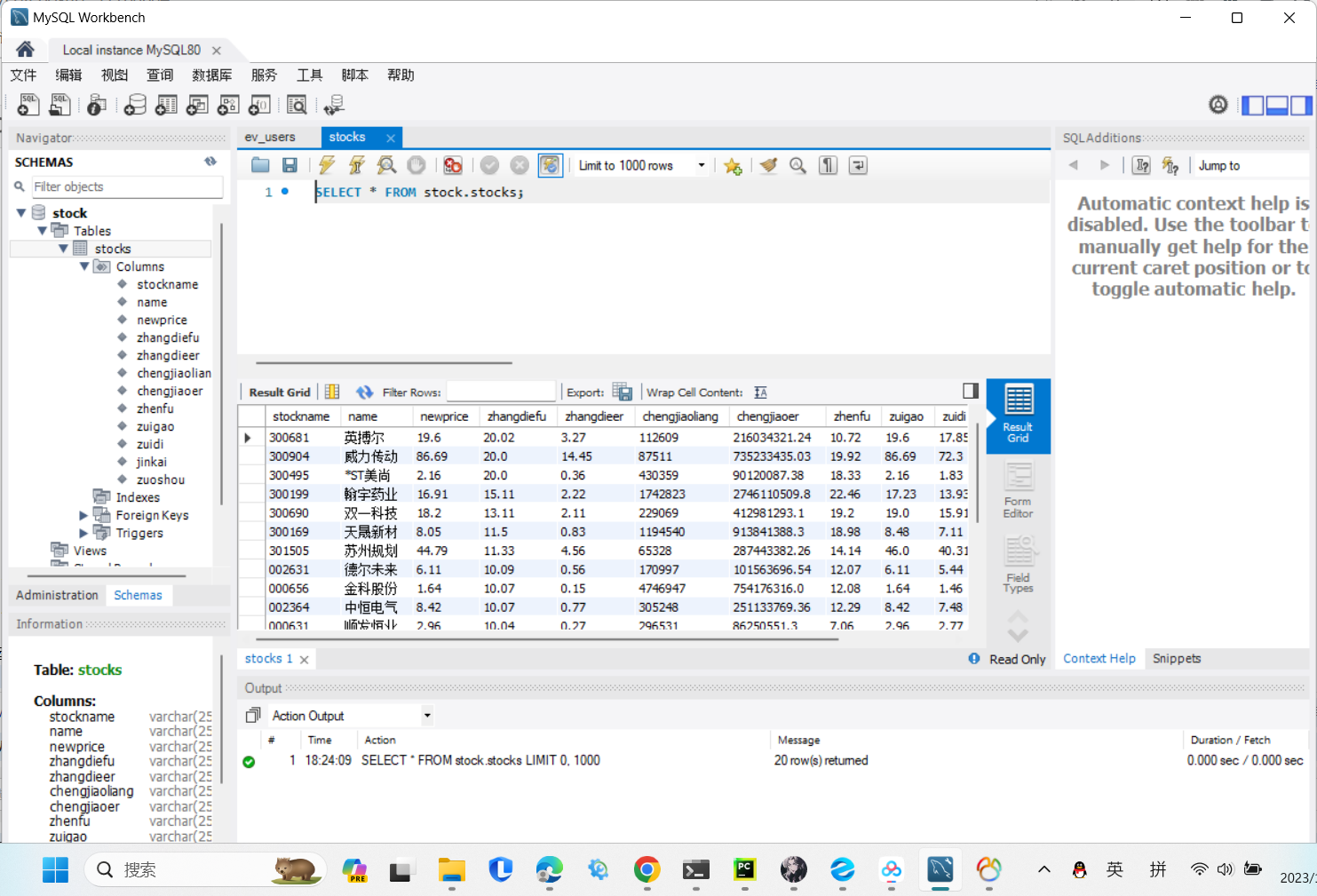
码云链接:https://gitee.com/lxmlmx/crawl_project/tree/master/作业3
心得体会:学会使用python连接mysql数据库保存数据。
作业3
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:招商银行网:https://www.boc.cn/sourcedb/whpj/
输出信息:(MySQL数据库存储和输出格式)

spider3代码
# _*_ coding : utf-8 _*_
# @Time : 2023/10/19 17:01
# @Author : lvmingxun
# @File : foreignexchange
# @Project : myspider
import scrapy
from myspider.items import foreignexchangeItem
from bs4 import UnicodeDammit
class foreignexchange(scrapy.Spider):
name = 'spider3'
start_url = "https://www.boc.cn/sourcedb/whpj/"
def start_requests(self):
url = foreignexchange.start_url
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response, **kwargs):
try:
ss = response.xpath("//tr")
ss = ss[2:len(ss)-2]
# print(ss)
for xx in ss:
# print(xx)
item = foreignexchangeItem()
item["Currency"] = xx.xpath("./td[1]/text()").extract()
print(xx.xpath("./td[1]/text()").extract())
item["TBP"] = xx.xpath("./td[2]/text()").extract()
item["CBP"] = xx.xpath("./td[3]/text()").extract()
item["TSP"] = xx.xpath("./td[4]/text()").extract()
item["CSP"] = xx.xpath("./td[5]/text()").extract()
item["Time"] = xx.xpath("./td[8]/text()").extract()
yield item
except Exception as err:
print(err)
pipeline代码
class MyspiderPipeline3:
def process_item(self, item, spider):
self.mydb = pymysql.connect(
host="192.168.149.1",
port=3306,
user='root',
password='123456',
database="fc",
charset='utf8'
)
print("succssfully conn1ctd!")
self.cursor = self.mydb.cursor()
self.cursor.execute('''CREATE TABLE IF NOT EXISTS fcs(
Currency VARCHAR(256),
TBP VARCHAR(256),
CBP VARCHAR(256),
TSP VARCHAR(256),
CSP VARCHAR(256),
Times VARCHAR(256)
)''')
self.mydb.commit()
sql = "insert into fcs values (%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql, (item.get("Currency"),item.get("TBP"),item.get("CBP"),item.get("TSP"),item.get("Times"),item.get("CSP")))
self.mydb.commit()
return item
def close_spider(self, spider):
self.mydb.close()
run运行结果:
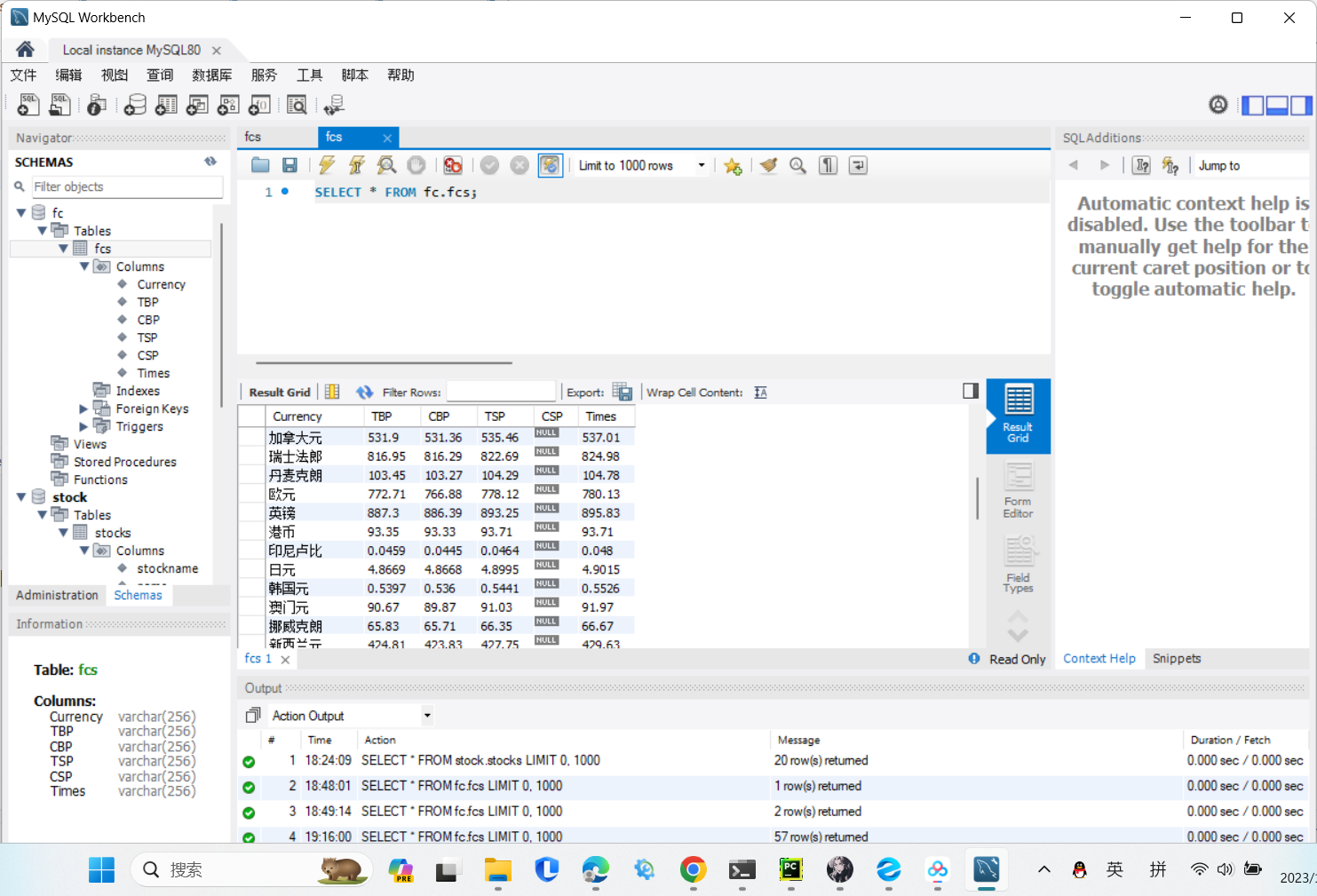
码云链接:https://gitee.com/lxmlmx/crawl_project/tree/master/作业3
心得体会:对使用xpath查找和数据库的使用更加熟练