一、Spark读取DM数据库问题描述
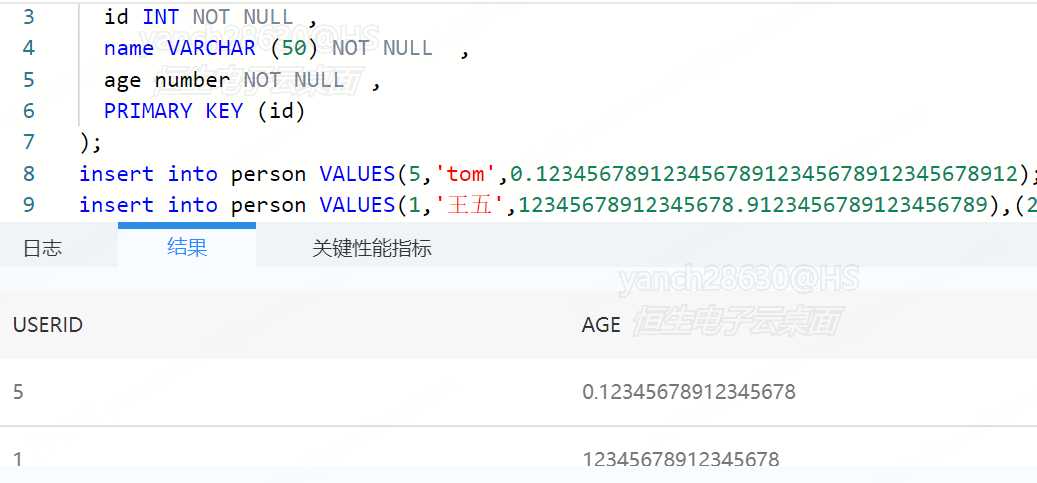
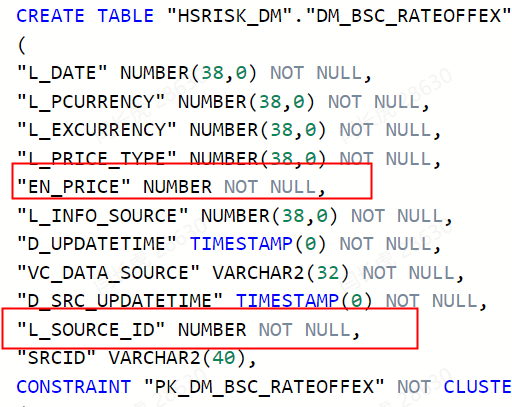
当达梦的表格设计使用number数据类型时,如果没有指定精确,使用默认值,如下图所示
则在读取该表格数据时,报错如下:
24/01/12 10:43:48 ERROR Node: [47db01a8b6ff47e7840cb0a777033721]:component[sink] cause error,error:Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 4) (10.20.192.76 executor 0): org.apache.spark.SparkException: [INTERNAL_ERROR] Negative scale is not allowed: -1. Set the config "spark.sql.legacy.allowNegativeScaleOfDecimal" to "true" to allow it.
at org.apache.spark.SparkException$.internalError(SparkException.scala:77)
at org.apache.spark.SparkException$.internalError(SparkException.scala:81)
at org.apache.spark.sql.errors.QueryCompilationErrors$.negativeScaleNotAllowedError(QueryCompilationErrors.scala:2274)
at org.apache.spark.sql.types.DecimalType$.checkNegativeScale(DecimalType.scala:173)
at org.apache.spark.sql.types.Decimal.set(Decimal.scala:120)
at org.apache.spark.sql.types.Decimal$.apply(Decimal.scala:571)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.$anonfun$makeGetter$4(JdbcUtils.scala:412)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.nullSafeConvert(JdbcUtils.scala:549)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.$anonfun$makeGetter$3(JdbcUtils.scala:412)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.$anonfun$makeGetter$3$adapted(JdbcUtils.scala:410)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anon$1.getNext(JdbcUtils.scala:361)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anon$1.getNext(JdbcUtils.scala:343)
at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at org.apache.spark.util.CompletionIterator.hasNext(CompletionIterator.scala:31)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:760)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:140)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:101)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:161)
at org.apache.spark.scheduler.Task.run(Task.scala:139)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:554)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1529)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:557)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
二、解决spark读写DM数据库报错解决方案
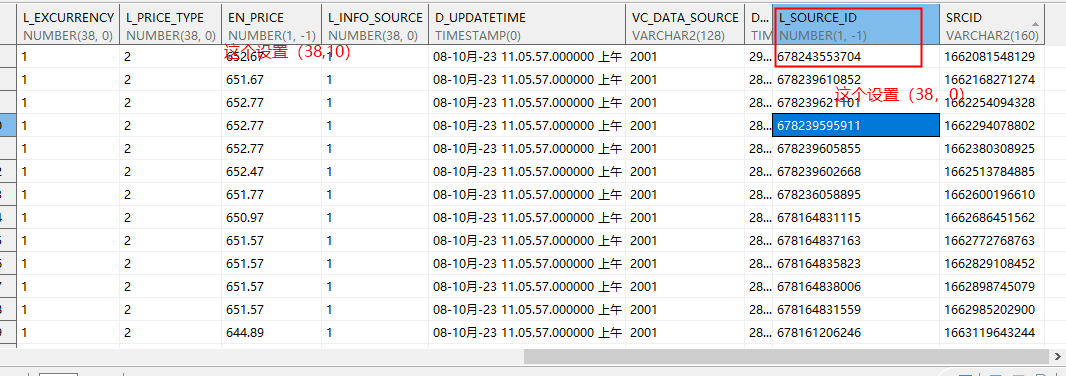
通过debug代码发现,如果没有指定number,则读取过来的精度为(1,-1),而实际上通过DM工具查询其元数据信息显示的确实(0,0)

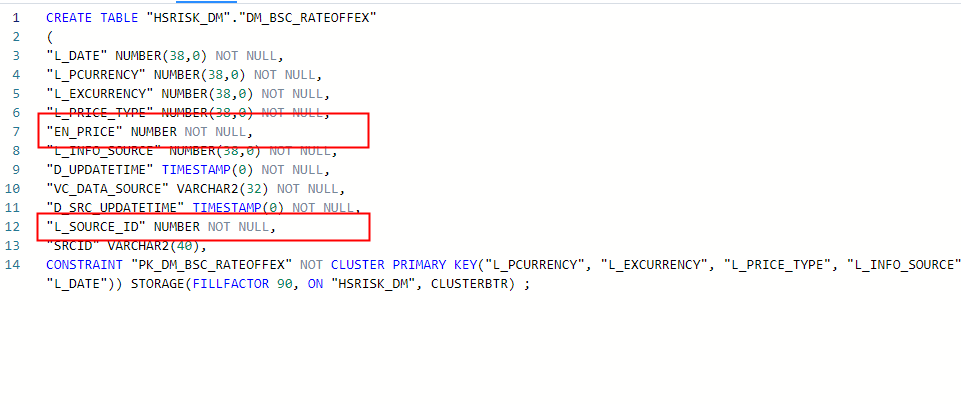
2.1 解决方案1,按照提示修改Spark的源代码
2.1.1 按照提示修改参数
先按照提示设置spark.sql.legacy.allowNegativeScaleOfDecimal=true,但是,Dirver端生效,而Worker端执行任务时却不生效,该值在true和false之间来回切换,设置无效
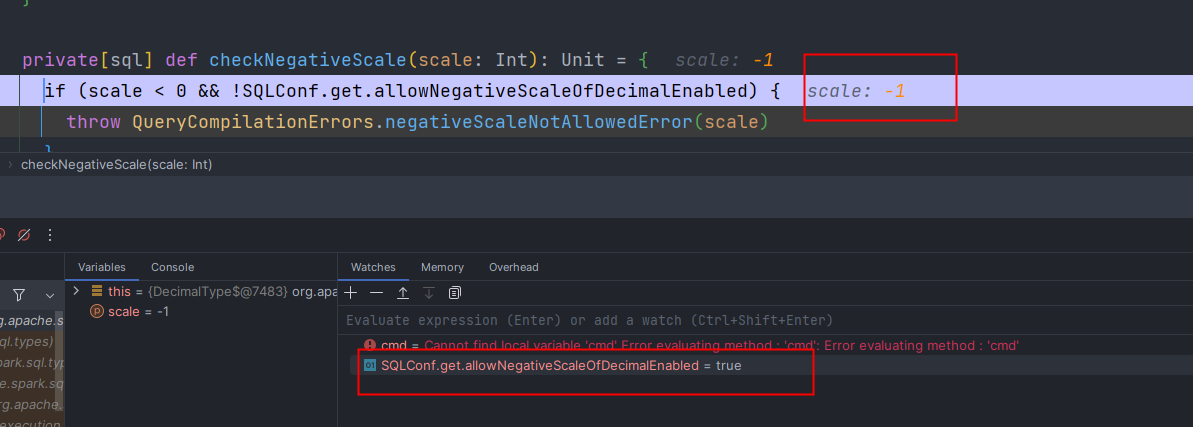
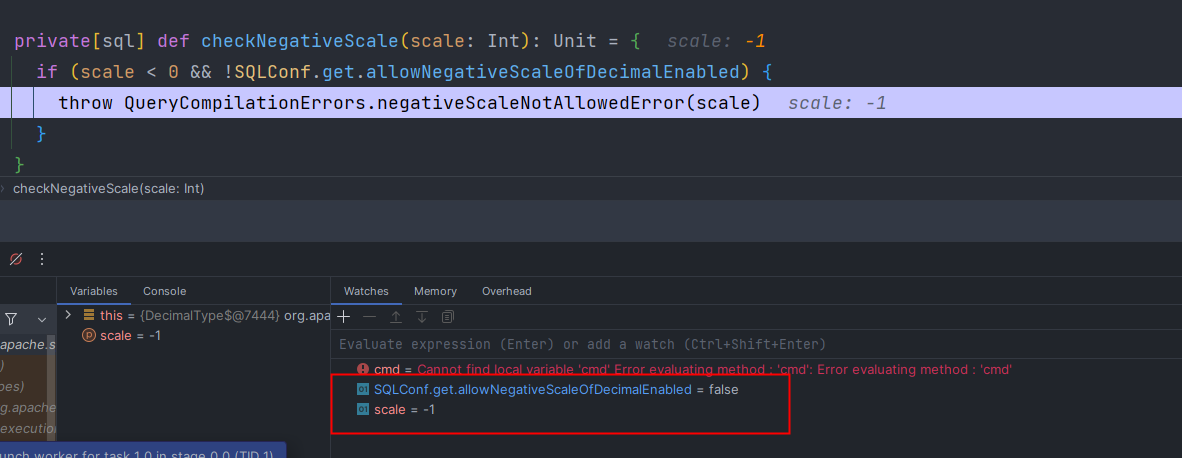
2.1.2 修改Spark的源码强制设置为true
为了不影响版本发布,强制修改Spark代码,将该值从默认值false改为true,发现有报错:
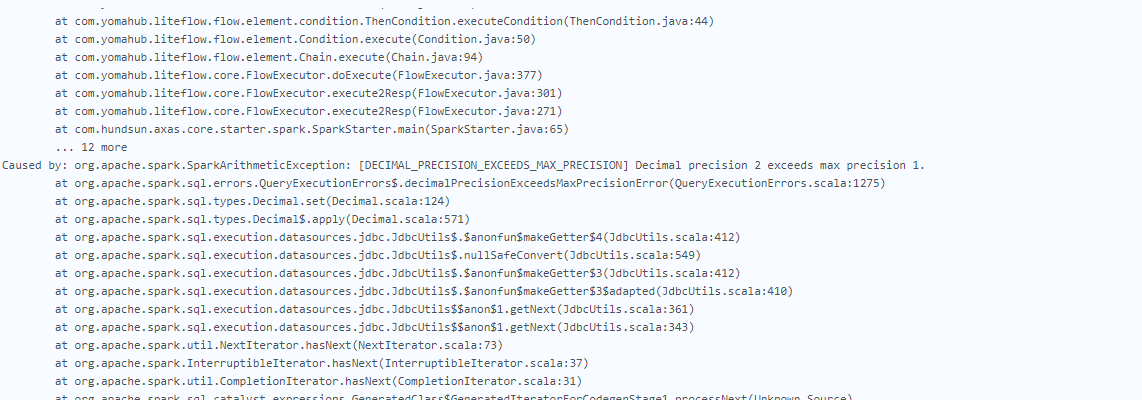
2.1.3 产看oracle和dm的元数据差异
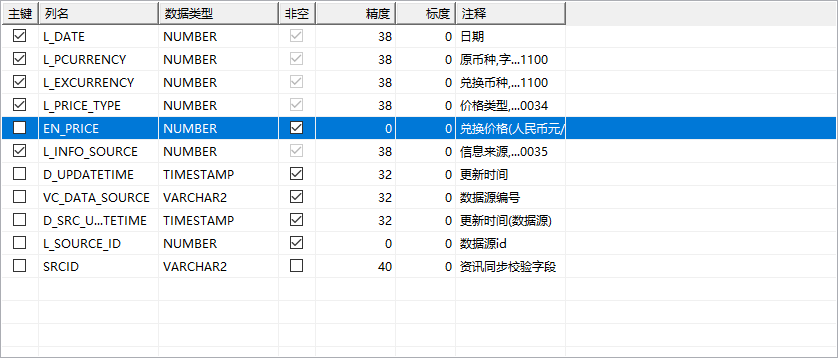
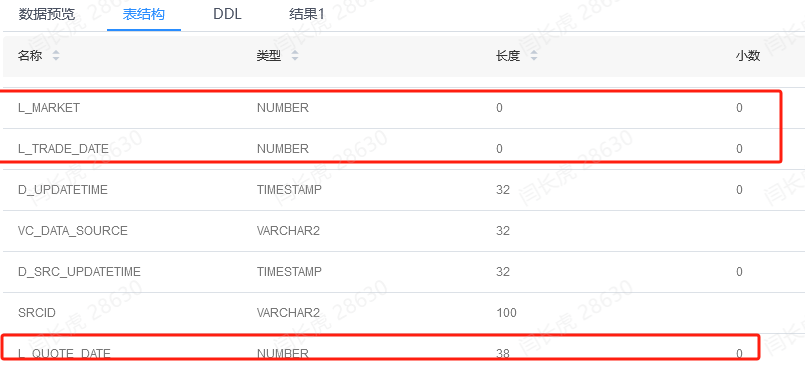
因此,总结这个错误应该是DM的数据库的问题,毕竟同样的表格格式,在oracle和DM中显示的元数据精确度都不一样,二者显示的精确度也不一样,Oracle的可以正常读取,而DaMeng的不可以。如下图所示
Oracle的表结构
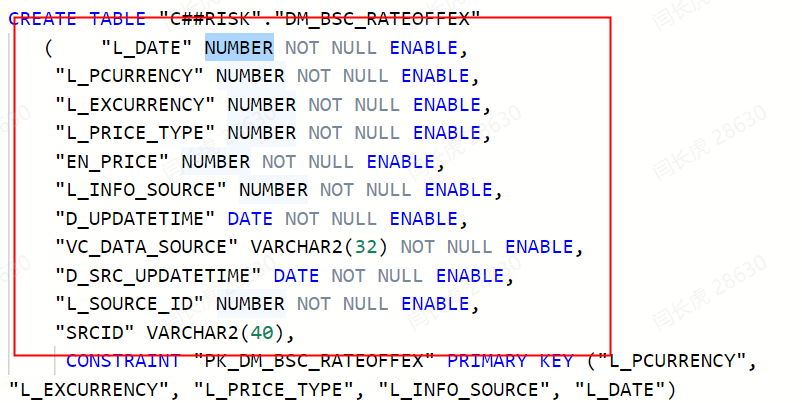
DaMeng表结构
Oracle显示元数据信息
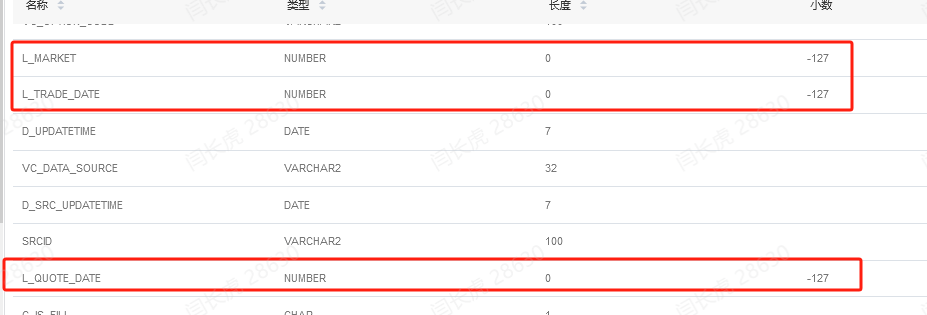
DaMeng的元数据信息
2.2 解决方案1,编写DM的连接器,将默认的改为(17,17)
2.2.1 产看DM的默认缺省度
查了一下DM的官方文档,当精度缺失时,默认为16,标度省略时,则默认为0;

2.2.2 验证DM的number缺省时的精度和标度
经过验证,都缺省的情况经过验证为(17,17),编写DM的对应Spark的连接器,问题解决。