探索性因子分析的步骤:
接下来,通过一个案例演示因子分析(探索性因子分析)的各个步骤应该如何进行。
案例:欲探究我国不同省份铁路运输能力情况,收集到部分相关数据如下:

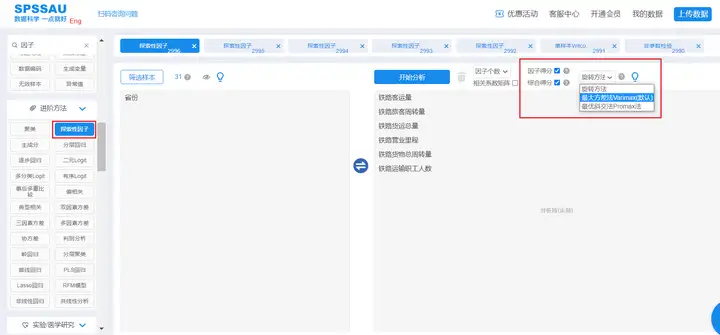
上传数据至SPSSAU系统,在【进阶方法】模块,选择【探索性因子分析】,将变量拖拽到右侧分析框,勾选“因子得分”与“综合得分”,旋转方法选择默认的“最大方差法”,操作如下图:
一、指标数据标准化处理
由于指标数据性质不同,具有不同的数量级和量纲,会导致分析结果不准确或产生误差。因此,先对原始数据进行标准化处理。SPSSAU因子分析将自动进行标准化处理,因此不需要再对数据进行处理。
标准化计算公式:(X-Mean)/ Std
二、因子分析适用性检验
进行因子分析的前提是数据适合使用该方法,通常采取KMO检验和Bartlett球形检验。KMO检验用于检查变量间的相关性,取值为0~1。KMO值越接近于1,变量间的相关性越强,一般该值大于0.6即可进行因子分析。Bartlett球形检验用于检验变量是否各自独立,通常显著性小于0.05时,说明符合标准,适合做因子分析。
本案例SPSSAU输出KMO和Bartlett球形检验结果如下:

从结果来看,KMO值为0.722大于0.6,所以可以进行因子分析。同时Bartlett球形检验结果显示p值小于0.05,可以进行因子分析。
三、提取公因子
以特征根大于1为标准提取公因子,SPSSAU得到各因子的特征根以及方差解释率见下表:

分析上表可知,特征根大于1的因子共有两个,这2个公因子的累计方差解释率为78.808%,第一个因子的方差解释率为41.346%,第二个因子的方差解释率为37.462%,说明提取的两个公因子能够代表原来6个铁路运输能力指标78.808%的信息,整体来看信息变量丢失较少,因子分析效果比较理想。
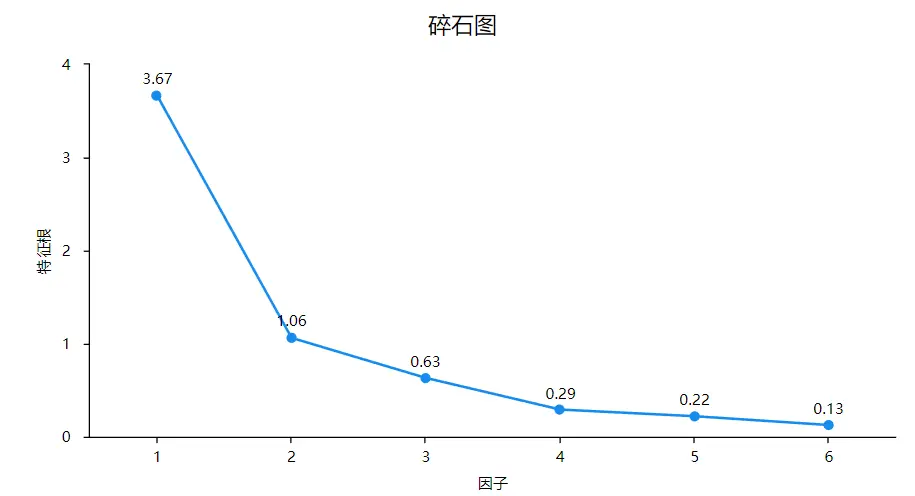
另外,从特征根的碎石图可以更为直观的看出拟提取的公因子。如上图,前两个因子的让特征根值均大于1,且曲线比价陡峭,剩下4个特征根值均小于1且特征根值曲线逐渐变得比较平缓,即提取前2个因子可以代表所有原始铁路运输指标的绝大部分信息,与方差解释率得到结果一致。
四、公因子命名与解释
找到公因子后,为了理解公因子的实际意义以及方便对问题进行分析,需要继续进行因子旋转。旋转常用方法为最大方差法。旋转后的因子载荷矩阵可以直观反映各个变量对主成分的贡献程度,一个变量在某个公因子上的载荷系数的绝对值越大,说明变量与该公因子越具有相关性。
下表为使用最大方差法进行旋转后得到的因子载荷系数表格:
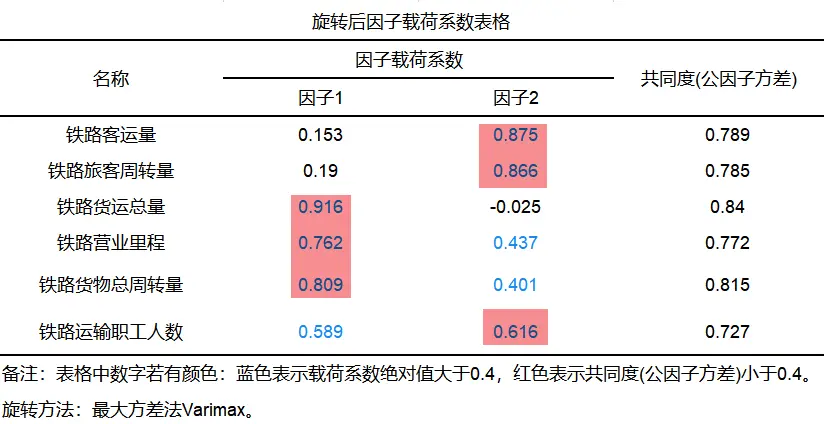
分析上表可知,因子1在铁路货运总量、铁路营业里程、铁路货物总周转量上具有较大的载荷,因此这3个变量归为一类命名为货运因子(记作F1)。因子2在铁路客运量、铁路旅客周转量、铁路运输职工人数上具有较大的载荷,因此这3个变量归为另一类命名为客运因子(记作F2)。
五、计算因子得分
确定因子后,进一步计算各因子得分,SPSSAU输出成份得分系数矩阵如下:
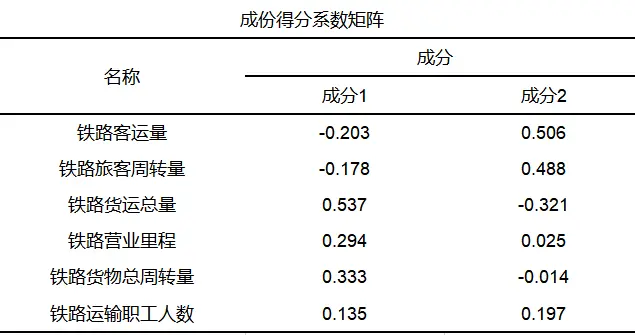
根据成份得分系数矩阵,得到公因子F由变量X表示线性组合的因子得分函数:
F1=-0.203*铁路客运量-0.178*铁路旅客周转量+0.537*铁路货运总量+0.294*铁路营业里程+0.333*铁路货物总周转量+0.135*铁路运输职工人数
F2=0.506*铁路客运量+0.488*铁路旅客周转量-0.321*铁路货运总量+0.025*铁路营业里程-0.014*铁路货物总周转量+0.197*铁路运输职工人数
这一过程可通过手算完成,但要注意使用的是标准化后的数据代入公式。
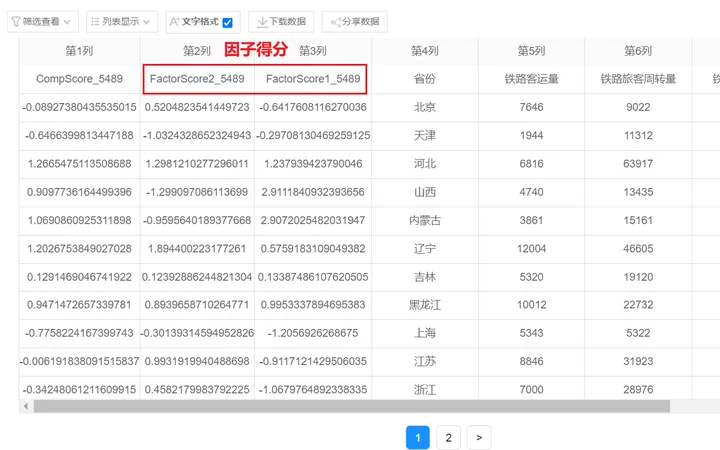
在我们进行分析前,勾选【因子得分】,SPSSAU自动保存公因子得分,如下图:
六、计算综合得分
进行综合评价将指标数据代入因子表达式,计算综合得分,分析结果并进行综合评价。即以2个公因子得分为基础,再以每个因子的方差解释率为权数进行线性加权平均,最后得到一个综合得分模型:
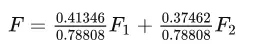
注:分子为两个公因子旋转后方差解释率,分母为旋转后累计方差解释率。
勾选【综合得分】后,SPSSAU将自动保存综合得分,结果见下图:
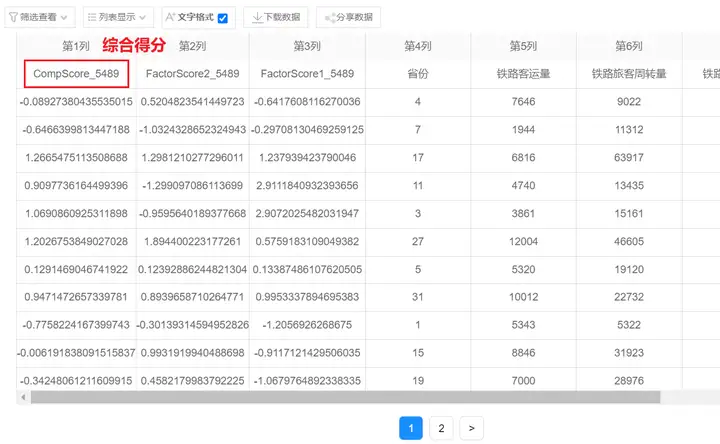
得到综合得分后,可将数据下载至本地,使用excel对综合得分进行排序,该排名就代表了31个省份的铁路运输能力。最后整理成下面这个一个表格:
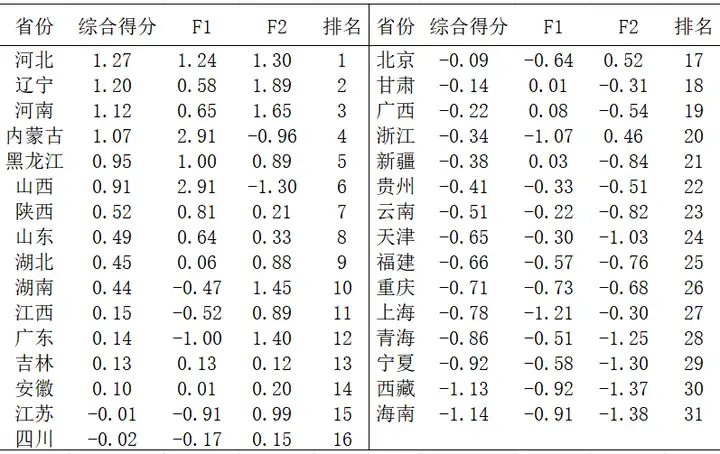
分析31个省份铁路运输能力综合得分表可知,河北省的铁路运输能力最强,海南省铁路运输能力最弱......
至此,因子分析结束。