一、作业内容
- 作业①:
- 要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
- 输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
- Gitee文件夹链接
- 要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
创建w.spider ,代码如下:
import scrapy from scrapy_weather.items import ScrapyWeatherItem class WSpider(scrapy.Spider): name = "w" allowed_domains = ["http://www.weather.com.cn"] start_urls = ["http://www.weather.com.cn"] def parse(self, response): # pipelines 下载数据 # items 定义数据结构 # 返回字符串 # content = response.text # 返回二进制 # content = response.body # print("====================================================") # print(content) # 直接使用response.xpath来解析response中的内容 img_list = response.xpath('//a[@target="_blank"]/img') # span_list = response.xpath('//div[@class="mainContent"]//a[@target="_blank"]/text()') print("====================================================") # span_list.extract()提取selector对象的data属性值 # span_list.extract_first()提取selector列表的第一个数据 # print(span_list.extract()) # print(span_list.extract_first()) for img in img_list: src = img.xpath('./@src').extract_first() book = ScrapyWeatherItem(src=src) # 获取一个就交给管道pipeline yield book
修改pipelis下载数据,代码如下:
from scrapy.pipelines.images import ImagesPipeline import scrapy # 想使用管道必须开启setting管道资源 class ScrapyWeatherPipeline(ImagesPipeline): def get_media_requests(self, item, info): # 根据图片地址对图片进行请求 yield scrapy.Request(item['src']) # 指定图片存储路径 def file_path(self, request, response=None, info=None, *, item=None): imgname = request.url.split('/')[-1] # 以图片url,通过/分割的最后一组数据为图片名 return imgname def item_completed(self, results, item, info): return item # 返回给下一个即将被执行的管道类
修改items定义数据结构,代码如下:
import scrapy class ScrapyWeatherItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 加载图片 src = scrapy.Field()
修改setting开放管道,代码如下:
ITEM_PIPELINES = { # 管道可以有很多个,1到1000, 数次越小优先级越高 "scrapy_weather.pipelines.ScrapyWeatherPipeline": 300, } IMAGES_STORE = './imags'
运行代码。
输出如下:
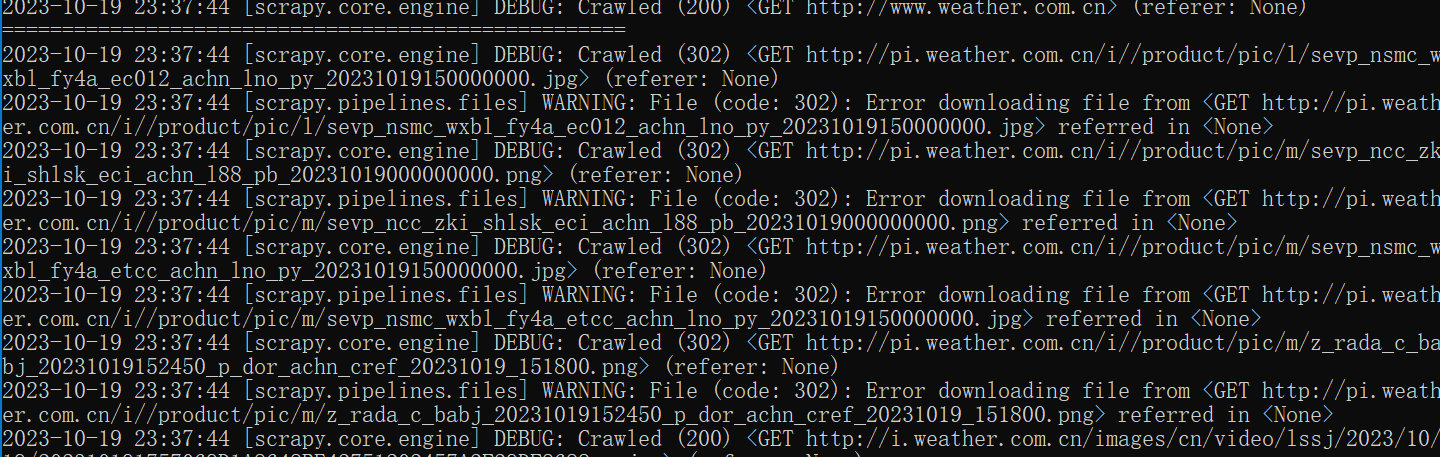
可以看到输出了图片:
随便打开一个图片:
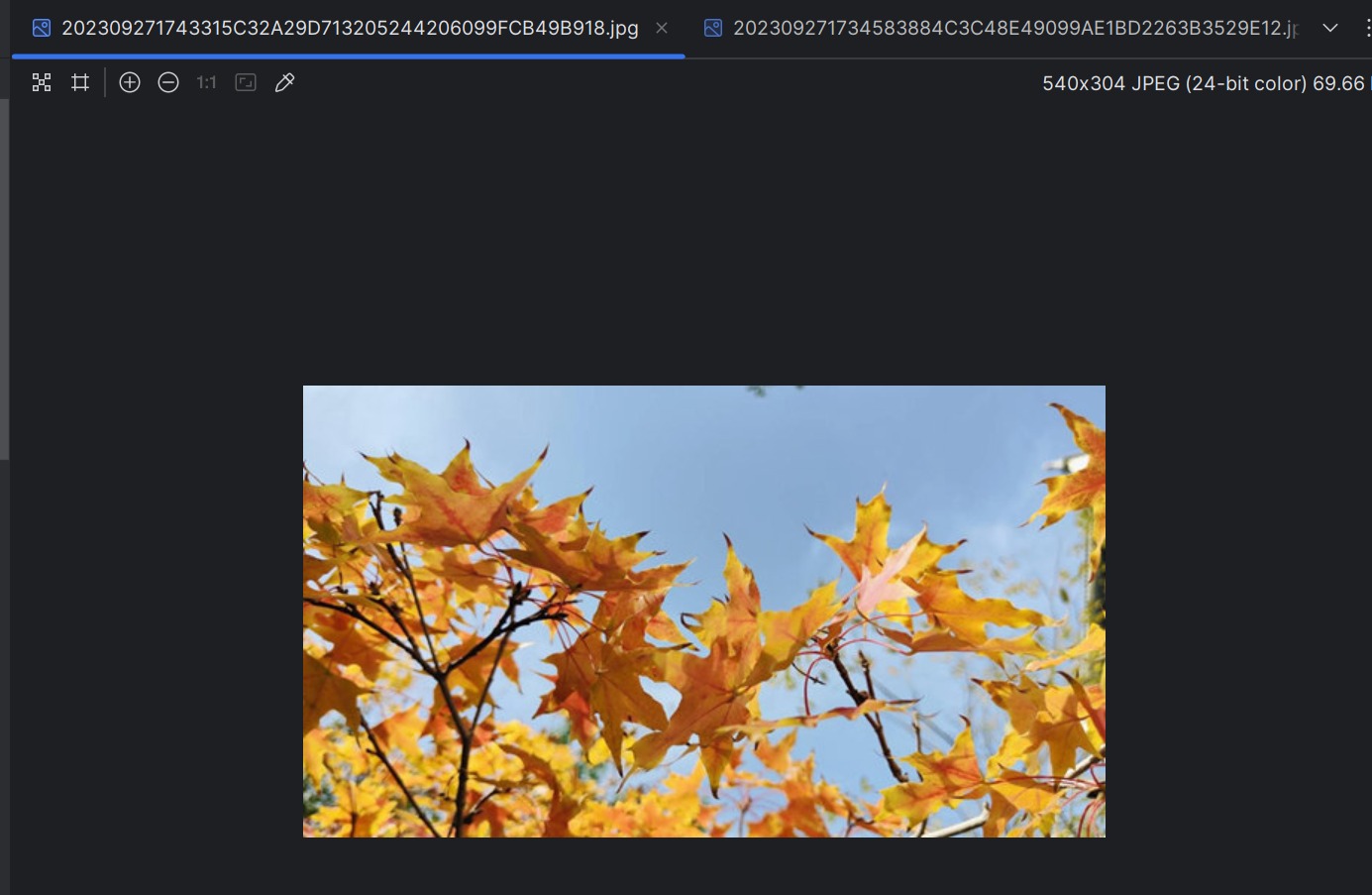
可以看到获取成功
- 作业②
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
- 候选网站:东方财富网:https://www.eastmoney.com/
- 输出信息:MySQL数据库存储和输出格式如下:
- 表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
-
序号
股票代码
股票名称
最新报价
涨跌幅
涨跌额
成交量
振幅
最高
最低
今开
昨收
1
688093
N世华
28.47
10.92
26.13万
7.6亿
22.34
32.0
28.08
30.20
17.55
2……
- Gitee文件夹链接
创建scraoy 过程就不展示了,展示核心代码,spider2.py代码为
import scrapy import requests import re from work2.items import Work2Item from bs4 import UnicodeDammit class StockSpider(scrapy.Spider): name = "w2" start_url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board" def start_requests(self): url = StockSpider.start_url yield scrapy.Request(url=url,callback=self.parse) def parse(self, response, **kwargs): try: stocks = [] url = "https://68.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124009413428787683675_1696660278138&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f12,f14,f2,f3,f4,f5,f6,f7,f15,f16,f17,f18&_=1696660278155" r = requests.get(url=url) data = re.compile("\"f2\":.*").findall(r.text) data1 = data[0].split("},{") data1[-1] = data1[-1].split("}")[0] for i in range(len(data1)): stock0 = data1[i].replace('"', "").split(",") list = [6, 7, 0, 1, 2, 3, 4, 5, 8, 9, 10, 11] stock = [] for j in list: stock.append(stock0[j].split(":")[1]) stocks.append(stock) print(stocks[0][0]) for i in range(len(stocks)): item = Work2Item() item["stockname"] = stocks[i][0] item["name"] = stocks[i][1] item["newprice"] = stocks[i][2] item["zhangdiefu"] = stocks[i][3] item["zhangdieer"] = stocks[i][4] item["chengjiaoliang"] = stocks[i][5] item["chengjiaoer"] = stocks[i][6] item["zhenfu"] = stocks[i][7] item["zuigao"] = stocks[i][8] item["zuidi"] = stocks[i][9] item["jinkai"] =stocks[i][10] item["zuoshou"] = stocks[i][11] print(item) yield item except Exception as err: print(err)
pipeline代码为:
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface from itemadapter import ItemAdapter class Work2Pipeline: def process_item(self, item, spider): self.mydb = pymysql.connect( host="192.168.149.1", port=3306, user='root', password='123456', database="stock", charset='utf8' ) self.cursor = self.mydb.cursor() self.cursor.execute('''CREATE TABLE IF NOT EXISTS stocks( stockname VARCHAR(256), name VARCHAR(256), newprice VARCHAR(256), zhangdiefu VARCHAR(256), zhangdieer VARCHAR(256), chengjiaoliang VARCHAR(256), chengjiaoer VARCHAR(256), zhenfu VARCHAR(256), zuigao VARCHAR(256), zuidi VARCHAR(256), jinkai VARCHAR(256), zuoshou VARCHAR(256) )''') self.mydb.commit() sql = "insert into stocks values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)" self.cursor.execute(sql,(item.get("stockname"),item.get("name"),item.get("newprice"), item.get("zhangdiefu"),item.get("zhangdieer"), item.get("chengjiaoliang"), item.get("chengjiaoer"), item.get("zhenfu"), item.get("zuigao"),item.get("zuidi"), item.get("jinkai"),item.get("zuoshou"))) print("succssfully conn1ctd!") self.mydb.commit() return item def close_spider(self, spider): self.mydb.close()
items.py代码为:
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class Work2Item(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() stockname = scrapy.Field() name = scrapy.Field() newprice = scrapy.Field() zhangdiefu = scrapy.Field() zhangdieer = scrapy.Field() chengjiaoliang = scrapy.Field() chengjiaoer = scrapy.Field() zhenfu = scrapy.Field() zuigao = scrapy.Field() zuidi = scrapy.Field() jinkai = scrapy.Field() zuoshou = scrapy.Field()
cmd输出部分截图如下:
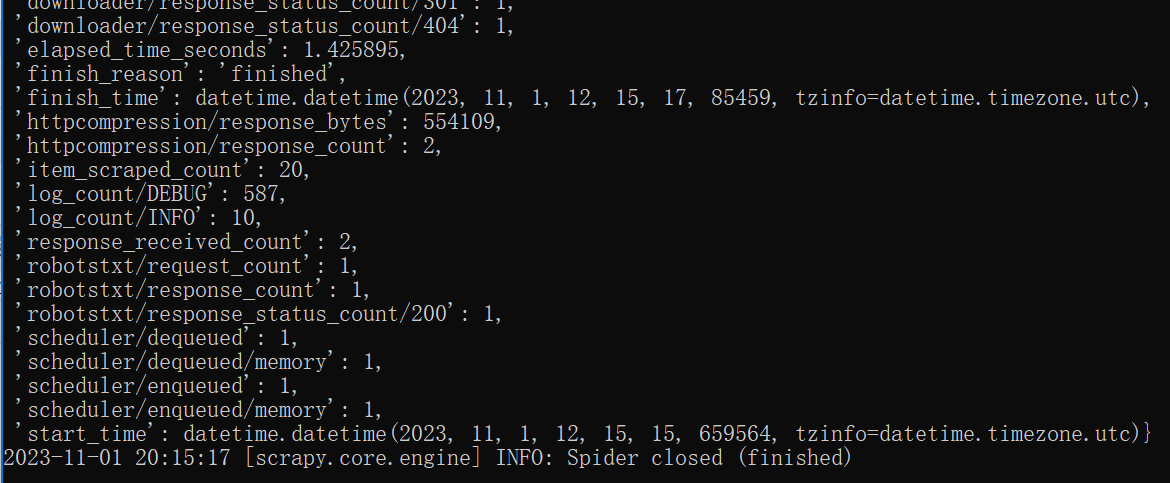
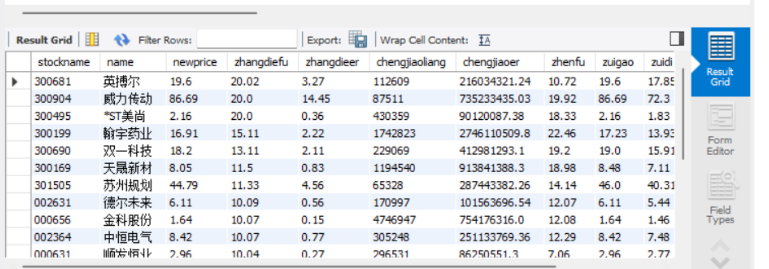
在MySQL中输入select* from stock.stock;
输出如下:
- 作业③:
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
- 候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
- 输出信息:
- Gitee文件夹链接
|
Currency |
TBP |
CBP |
TSP |
CSP |
Time |
|
阿联酋迪拉姆 |
198.58 |
192.31 |
199.98 |
206.59 |
11:27:14 |
同上一题一样,只展示核心代码,spider3.py代码如下:
import scrapy from myspider.items import foreignexchangeItem from bs4 import UnicodeDammit class foreignexchange(scrapy.Spider): name = 'spider3' start_url = "https://www.boc.cn/sourcedb/whpj/" def start_requests(self): url = foreignexchange.start_url yield scrapy.Request(url=url,callback=self.parse) def parse(self, response, **kwargs): try: ss = response.xpath("//tr") ss = ss[2:len(ss)-2] # print(ss) for xx in ss: # print(xx) item = foreignexchangeItem() item["Currency"] = xx.xpath("./td[1]/text()").extract() print(xx.xpath("./td[1]/text()").extract()) item["TBP"] = xx.xpath("./td[2]/text()").extract() item["CBP"] = xx.xpath("./td[3]/text()").extract() item["TSP"] = xx.xpath("./td[4]/text()").extract() item["CSP"] = xx.xpath("./td[5]/text()").extract() item["
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class Work2Item(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() Currency = scrapy.Field() TBP = scrapy.Field() CBP = scrapy.Field() TSP = scrapy.Field() CSP = scrapy.Field() Time = scrapy.Field()
"] = xx.xpath("./td[8]/text()").extract() yield item except Exception as err: print(err)
pipelines代码如下:
class MyspiderPipeline3: def process_item(self, item, spider): self.mydb = pymysql.connect( host="192.168.149.1", port=3306, user='root', password='123456', database="fc", charset='utf8' ) print("succssfully conn1ctd!") self.cursor = self.mydb.cursor() self.cursor.execute('''CREATE TABLE IF NOT EXISTS fcs( Currency VARCHAR(256), TBP VARCHAR(256), CBP VARCHAR(256), TSP VARCHAR(256), CSP VARCHAR(256), Times VARCHAR(256) )''') self.mydb.commit() sql = "insert into fcs values (%s,%s,%s,%s,%s,%s)" self.cursor.execute(sql, (item.get("Currency"),item.get("TBP"),item.get("CBP"),item.get("TSP"),item.get("Times"),item.get("CSP"))) self.mydb.commit() return item def close_spider(self, spider): self.mydb.close()
items.py代码如下:
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class Work2Item(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() Currency = scrapy.Field() TBP = scrapy.Field() CBP = scrapy.Field() TSP = scrapy.Field() CSP = scrapy.Field() Time = scrapy.Field()
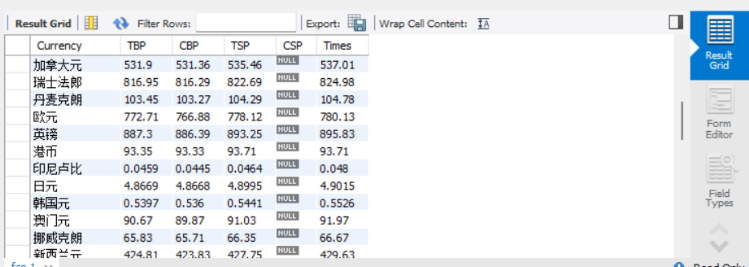
在MySQL中输入select* from fc.fcs;
输出结果如下: