在linux源码中经常遇到__asm__函数。它其实是函数asm的宏定义
#define __asm__ asm,asm函数让系统执行汇编语句。
__asm__常常与__volatile__一起出现。__volatile__限制编译器不能对下面的汇编语句进行优化处理。
现代cpu通常具有多级缓存,寄存器、一级、二级、三级缓存。当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。距离寄存器越远、速度越慢、容量也越大。如下所示:
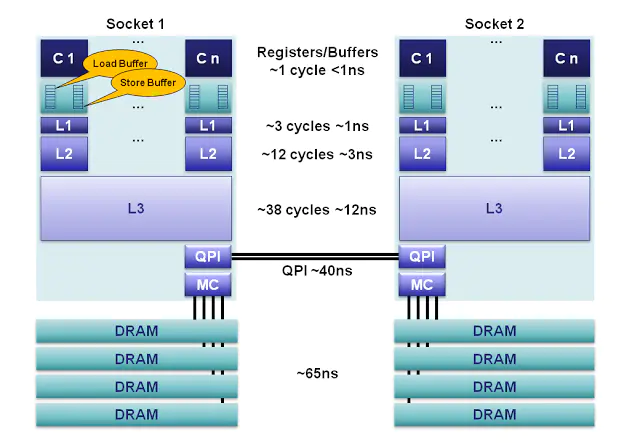
缓存之所以有效,主要是因为程序运行时对内存的访问呈现局部性(Locality)特征。这种局部性既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality)。有效利用这种局部性,缓存可以达到极高的命中率。
但是这带来一个问题,因为cpu和编译器的优化,编写的代码并不总是按照编写的顺序进行执行,可能被优化掉或合并掉,从而导致程序结果并不符合预期。为了解决这种重排序导致的不正确性,程序中通常采用volatile修饰变量以避免被寄存器缓存。
从本质上来说,volatile变量(不管是java还是c)都是通过内存屏障机制来实现的,只不过汇编指令("lock; addl $0,0(%%rsp)" : : : "memory", "cc")能够保证本进程中之前的所有非volatile变量值都会从寄存器刷到L3缓存或内存,取决于是一个socket核内的不同core访问还是跨socket核访问。所以c/c++中如下显示的内存屏障用法是需要一刀切刷干净的原因。
#define pg_memory_barrier_impl() \ __asm__ __volatile__ ("lock; addl $0,0(%%rsp)" : : : "memory", "cc") /* * The memory barrier has to be placed here to ensure that any flag * variables possibly changed by this process have been flushed to main * memory, before we check/set is_set. */ pg_memory_barrier(); /* Quick exit if already set */ if (latch->is_set) return; latch->is_set = true;
查看内存屏障的汇编实现
gcc -c -O2可以生成目标文件(默认是O0,看不出编译器优化后的差异,走O2就很清晰的看出差异了),通过objdump将以十六进制和汇编代码的形式显示.o文件的内容。如下:
#include <iostream> int foo = 10; int main(int argc, const char * argv[]) { // insert code here... volatile int a = foo + 10; // __asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory"); volatile int b = foo + 20; printf("%d %d\n",a,b); return 0; }
[lightdb@lightdb-dev ~]$ gcc -O2 -c test_as.cpp [lightdb@lightdb-dev ~]$ objdump -D test_as.o 0000000000000000 <main>: 0: 48 83 ec 18 sub $0x18,%rsp 4: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # a <main+0xa> a: bf 00 00 00 00 mov $0x0,%edi f: 8d 50 0a lea 0xa(%rax),%edx 12: 83 c0 14 add $0x14,%eax 15: 89 54 24 08 mov %edx,0x8(%rsp) 19: 89 44 24 0c mov %eax,0xc(%rsp) 1d: 8b 54 24 0c mov 0xc(%rsp),%edx 21: 31 c0 xor %eax,%eax 23: 8b 74 24 08 mov 0x8(%rsp),%esi 27: e8 00 00 00 00 callq 2c <main+0x2c> 2c: 31 c0 xor %eax,%eax 2e: 48 83 c4 18 add $0x18,%rsp 32: c3 retq 33: 66 66 2e 0f 1f 84 00 data16 nopw %cs:0x0(%rax,%rax,1) 3a: 00 00 00 00 3e: 66 90 xchg %ax,%ax
然后包含了memory_barrier的差别。如下:
0000000000000000 <main>: 0: 48 83 ec 18 sub $0x18,%rsp 4: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # a <main+0xa> a: 83 c0 0a add $0xa,%eax d: 89 44 24 08 mov %eax,0x8(%rsp) 11: f0 83 04 24 00 lock addl $0x0,(%rsp) # 内存屏障 16: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 1c <main+0x1c> 1c: bf 00 00 00 00 mov $0x0,%edi 21: 83 c0 14 add $0x14,%eax 24: 89 44 24 0c mov %eax,0xc(%rsp) 28: 8b 54 24 0c mov 0xc(%rsp),%edx 2c: 31 c0 xor %eax,%eax 2e: 8b 74 24 08 mov 0x8(%rsp),%esi 32: e8 00 00 00 00 callq 37 <main+0x37> 37: 31 c0 xor %eax,%eax 39: 48 83 c4 18 add $0x18,%rsp 3d: c3 retq 3e: 66 90 xchg %ax,%ax
如果a和b不是volatile,会进一步重排序,如下:
0000000000000000 <main>: 0: 48 83 ec 08 sub $0x8,%rsp 4: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # a <main+0xa> a: 8d 70 0a lea 0xa(%rax),%esi d: f0 83 04 24 00 lock addl $0x0,(%rsp) 12: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 18 <main+0x18> 18: bf 00 00 00 00 mov $0x0,%edi 1d: 8d 50 14 lea 0x14(%rax),%edx 20: 31 c0 xor %eax,%eax 22: e8 00 00 00 00 callq 27 <main+0x27> 27: 31 c0 xor %eax,%eax 29: 48 83 c4 08 add $0x8,%rsp 2d: c3 retq 2e: 66 90 xchg %ax,%ax
java可通过hsdis将字节码文件.class生成汇编码,这是sun官方提供的工具。如下:
public class Bar { volatile int a = 1; volatile static int b = 2; public int sum(int c) { return a + b + c; } public static void main(String[] args) { new Bar().sum(3); } }
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -Xcomp -XX:CompileCommand=dontinline,*Bar.sum -XX:CompileCommand=compileonly,*Bar.sum Bar
===
https://blog.csdn.net/qq_39312683/article/details/96908239 里面的例子中汇编码和gcc生成的有些大
https://zhuanlan.zhihu.com/p/476210914 以jctools演示重排序的优化,主要靠padding
https://blog.csdn.net/yexiangCSDN/article/details/100773963 asm函数汇编解释
https://www.cnblogs.com/yfii/p/14661346.html 生成汇编
https://blog.csdn.net/jackgo73/article/details/126031027
https://blog.csdn.net/wohu1104/article/details/110730799 预处理、编译、汇编、链接的过程和选项