要解决的问题
- 解决HUE操作大数据量Hive表时,执行报错的问题。
- 为开发人员或数据管理人员提供一个便捷的Flink SQL交互式查询工具,简化SQL验证的流程,进而提高工作效率。
功能介绍
- Flink SQL 读写Kafka
- Flink SQL 读写HDFS
- Flink SQL 关联
- Flink SQL 聚合
- Flink SQL 使用HiveCatalog读写Hive表
-- Flink SQL 读写Kafka CREATE TABLE `kafka_test_01`( `caseId` string, `sourceUrl` string ) with ( 'connector' = 'kafka', 'topic' = 'kafka_test_01', 'properties.group.id' = 'kafka_test_01', 'properties.bootstrap.servers' = '172.31.3.10:32058', 'format' = 'json', 'scan.startup.mode' = 'earliest-offset' ) insert into kafka_test_01 values('a', 'b') -- Flink SQL 读写HDFS drop table hdfs_pt_test CREATE TABLE hdfs_pt_test ( uniqid1 STRING, uniqid2 STRING, dt STRING ) PARTITIONED BY (dt) WITH ( 'connector'='filesystem', 'path'='hdfs://172.31.6.30:9000/dw/ods/hdfs_pt_test', 'format'='json', 'sink.partition-commit.delay'='1 h', 'sink.partition-commit.policy.kind'='success-file' ) insert into hdfs_pt_test values('a', 'b', 'c') select * from hdfs_pt_test where dt = 'c' -- Flink SQL JOIN验证 CREATE TABLE hdfs_join01_test ( uniqid STRING, name STRING ) WITH ( 'connector'='filesystem', 'path'='hdfs://172.31.6.30:9000/dw/ods/hdfs_pt_join01_test', 'format'='json', 'sink.partition-commit.delay'='1 h', 'sink.partition-commit.policy.kind'='success-file' ) insert into hdfs_join01_test values('1', 'aaa') insert into hdfs_join01_test values('2', 'bbb') insert into hdfs_join01_test values('3', 'ccc') select * from hdfs_join01_test CREATE TABLE hdfs_join02_test ( uniqid STRING, age STRING ) WITH ( 'connector'='filesystem', 'path'='hdfs://172.31.6.30:9000/dw/ods/hdfs_pt_join02_test', 'format'='json', 'sink.partition-commit.delay'='1 h', 'sink.partition-commit.policy.kind'='success-file' ) insert into hdfs_join02_test values('1', '18') insert into hdfs_join02_test values('2', '20') select * from hdfs_join02_test SELECT a.uniqid, a.name, b.age FROM hdfs_join01_test a INNER JOIN hdfs_join02_test b ON a.uniqid = b.uniqid -- Flink SQL GROUP验证 DROP TABLE hdfs_group01_test CREATE TABLE hdfs_group01_test ( name STRING, `value` INTEGER ) WITH ( 'connector'='filesystem', 'path'='hdfs://172.31.6.30:9000/dw/ods/hdfs_group01_test', 'format'='json', 'sink.partition-commit.delay'='1 h', 'sink.partition-commit.policy.kind'='success-file' ) insert into hdfs_group01_test values('aaa', 100) insert into hdfs_group01_test values('aaa', 100) insert into hdfs_group01_test values('bbb', 100) insert into hdfs_group01_test values('ccc', 600) SELECT name, SUM(`value`) as v FROM hdfs_group01_test GROUP BY name select count(*) from hdfs_group01_test -- Flink SQL 使用HiveCatalog读写Hive表 show catalogs use catalog myhive show databases use dw show tables select * from aquaticanimal insert into dwd_cpws_general_result01 select * from dwd_cpws_general where province='100000' limit 100 insert into dwd_pil_ps_test01 select * from dwd_pil_ps
功能列表
|
statement
|
comment
|
|---|---|
| SHOW CATALOGS | List all registered catalogs |
| SHOW DATABASES | List all databases in the current catalog |
| SHOW TABLES | List all tables and views in the current database of the current catalog |
| SHOW VIEWS | List all views in the current database of the current catalog |
| SHOW FUNCTIONS | List all functions |
| SHOW MODULES | List all modules |
| USE CATALOG catalog_name | Set a catalog with given name as the current catalog |
| USE database_name | Set a database with given name as the current database of the current catalog |
| CREATE TABLE table_name ... | Create a table with a DDL statement |
| DROP TABLE table_name | Drop a table with given name |
| ALTER TABLE table_name | Alter a table with given name |
| CREATE DATABASE database_name ... | Create a database in current catalog with given name |
| DROP DATABASE database_name ... | Drop a database with given name |
| ALTER DATABASE database_name ... | Alter a database with given name |
| CREATE VIEW view_name AS ... | Add a view in current session with SELECT statement |
| DROP VIEW view_name ... | Drop a table with given name |
| SET xx=yy | Set given key's session property to the specific value |
| SET | List all session's properties |
| RESET ALL | Reset all session's properties set by SET command |
| DESCRIBE table_name | Show the schema of a table |
| EXPLAIN PLAN FOR ... | Show string-based explanation about AST and execution plan of the given statement |
| SELECT ... | Submit a Flink SELECT SQL job |
| INSERT INTO ... | Submit a Flink INSERT INTO SQL job |
| INSERT OVERWRITE ... | Submit a Flink INSERT OVERWRITE SQL job |
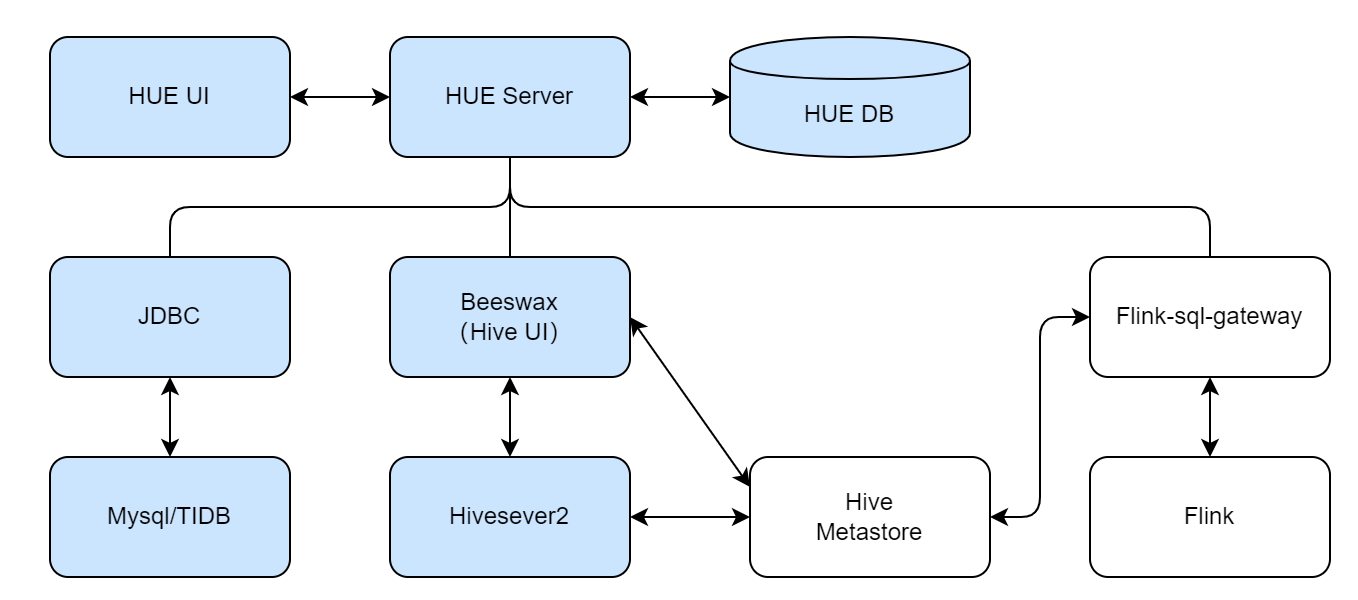
架构图
安装过程
注意事项
- Flink运行环境需要集成所需的第三方Jar包,包括Hadoop,Hive等相关Jar包,其中Hive需要源码重新编译,解决Guava版本冲突问题。
- 修改Flink-sql-gateway源码,限制使用Catalog方式读写Hive表的最大并行度。
- 目前HUE连接Flink SQL在聚合操作方面支持的不好,语法存在差异,需进一步探索。
其他尝试
HUE连接TIDB
执行环境
http://hue.dw.jcinfo.com/hue/editor/?type=flink
http://172.31.3.13:31741/#/overview
http://hdp0.dw.jcinfo.com:50070/dfshealth.html#tab-overview
http://metadata.jcinfo.com/#/login?redirect=%2Fredirect%2Fdatamodel%2Findex