在图像实际的细分场景中,经常会遇到数据集不均衡以及数据集数量有限等问题,如何有效利用数据集,提升自己的算法效果,这里大刀基于自己的实际项目经验,分享在实际图像分类领域遇到问题,以及解决的方案,供参考。
前言
大家好,我是张大刀。之前有个智慧工地的项目,其中一个需求是监控工地上的起重机的使用合规性情况,说起来这个需求很常规,起重机有三种状态:

左(移动状态)、中间(伸展支腿)、右(开臂)
当起重机移动时,须关闭其吊臂并缩回支腿;在起重机开始承载重物之前,它须伸出支腿以增加起重机的稳定性;最后的开动臂状态是抬起吊杆。正确的顺序是:
移动到某一处→伸展支腿→开臂(完成起吊)→关臂→收回支腿→移动到其他处。
基上述需求,我们只需要识别出其中的三种状态,然后基于视频段的前后顺序即可将其串联起来。
数据侧: 工作现场的视频片段收集了4个月,之后进行处理找到带有起重机的视频,总共提取了34个视频剪辑,然后抽取视频帧,前三个月为训练集,最后一个月为测试集,总共为训练数据集标记了 2523 帧,并使用 2071 帧进行验证。

算法方案: 最开始的baseline算法方案为:
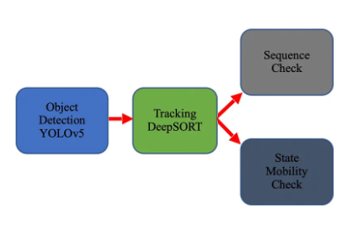
通过yolov5检测到起重机在图片中的位置,并识别出其中的状态类别,再通过DeepSORT完成目标追踪。这个方案最先被pass是因为开始时用yolov5直接对其分类的效果并不好。考虑到类别之间的差异性较小,以及边界信息特征与类别特征提取需要解耦,将算法方案更新如下:
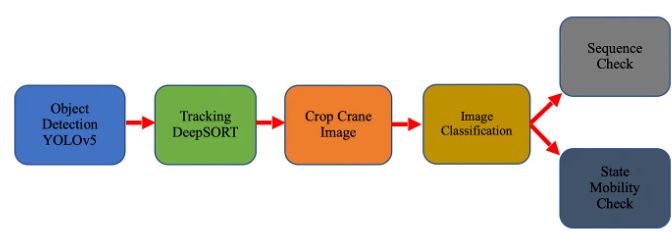
pipeline
在yolov5 检测到起重机的位置后,将图片裁剪下来做分类,最后做一个顺序的检查以及移动状态的检查。
顺序检查: 根据分类器的预测,将每一帧的预测结果存储在固定大小的FIFO缓冲区中,缓冲区内的存储状态可用于确定起重机的实际状态。这使得整体预测对噪声或单个帧的错误预测更加可靠,后期可通过逻辑进行过滤。
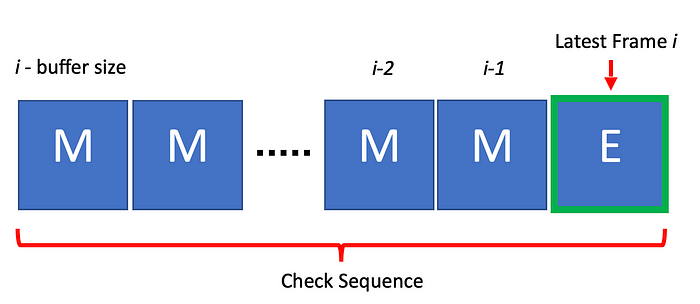
FIFO缓冲区,用于存储每个帧的预测起重机状态
运动状态检查: 一旦知道起重机状态,可通过检查上下帧起重机中边界框的 x、y以及卡尔曼速度矩阵预测的下帧边界框的差距来检查起重机是否静止。如果起重机处于伸展支腿或开臂状态是,则起重机应该是静止的。
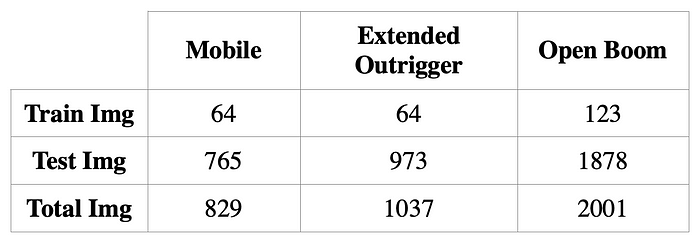
对于分类模型,起重机的分类算法,类别有三类:移动,伸展支腿和开臂。训练集+测试集总数如下:
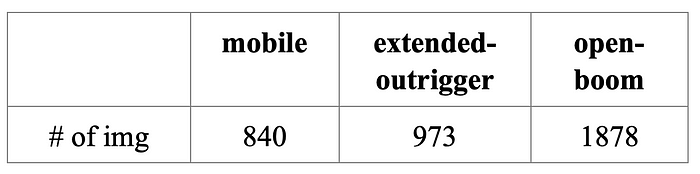
从数据分布中可以看出,数据分布不均衡,其中大部分都是开臂状态。这是因为起重机只有在使用时才会进入施工工地,只有起重机进入监控前往施工区域的短时间内,才用移动以及伸展支腿的状态。
01 迁移学习
第一步,对于任何图像分类任务,尝试的第一件事是使用常用的模型EfficientNet-B7进行迁移学习。在 ImageNet 上加载了带有预训练权重的模型后,同时冻结主干层,允许最后几层更新权重。训练的结果并不好,该模型似乎无法提取可以很好地区分 3 种起重机状态的特征,同时向模型添加更多层也无济于事,还可能存在过拟合的风险。

训练loss减少,但val的acc并没有提高
02 对比学习
想起之前人脸识别时,对数据规模以及数据类别比例的要求,于是开始考虑对比学习是否可能解决这个问题。对比学习主要由孪生网络+三元损失函数组成,其中选择一个锚点并与正(同一类)示例和负(不同类)示例进行比较,它的一个优点是不需要大量的训练数据,这刚好是当前场景遇到的问题。
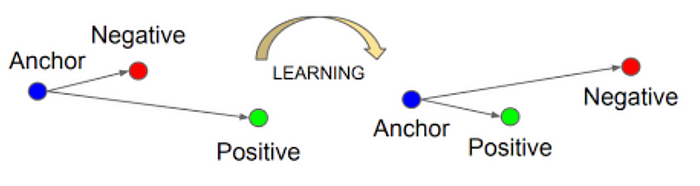
三元损失

使用三元损失训练编码器模型
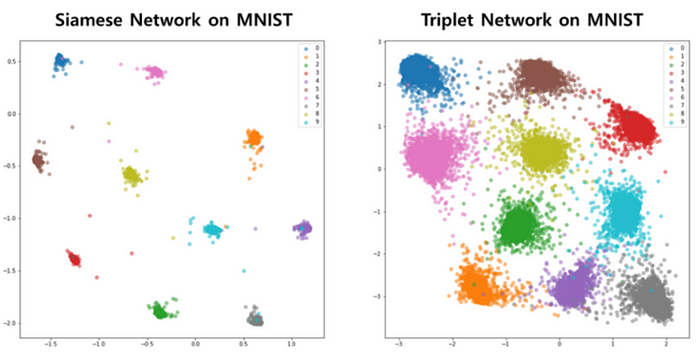
关键思想是模型学习从图像和同一类的集群成员中embedding特征,同时将不同类的成员尽可能分开。下面是如何使用这种模型来解决经典MNIST问题的示例。
批量三元组选择策略: 对于训练集的设置,使用的是在线三元组组合,对于每个batch,数据加载器会为每一类选择N个样本图像,然后选择一个锚点以及对应的正例和负例,做为一个三元组。下图为选择的三元组实例,并基于编码器计算正负例与锚点之间的L2距离(熟悉人脸识别的可能知道,这里的损失函数可以换成余弦距离以及arcface距离等)。

蓝框为锚点,属于A类,因此绿框内为A类的正例。其余的B&C类是负例图像(红框),每个图像下方是各图像与锚点图像之间的L2距离。数字越小,两个图像越相似。
正例和锚点之间的 L2 距离尽可能接近零,而负例和锚点之间的距离尽可能大。
损失函数定义如下:

对比学习中的损失函数(三元损失),其中 a是锚点,p 是正例,n 是负例。d为两者之间的 L2 距离,margin为中间的余量
下面是一个容易示例的三元组样本:

简单样本,因为正例和锚点之间的 L2 距离 (0.2) 远小于负例与锚点的距离(2.3)
下面是一个难例的三元组样本:
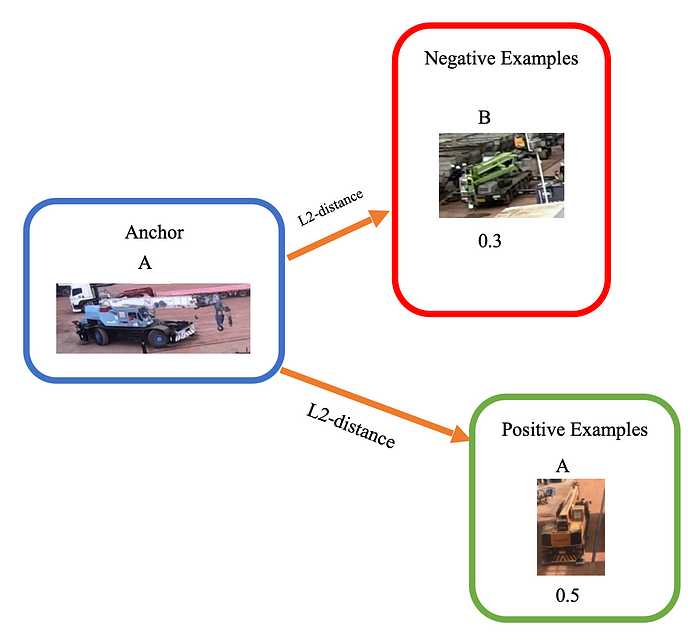
难例样本,因为正例和锚点之间的 L2 距离 (0.5) 大于负例与锚点之间的距离 (0.3)
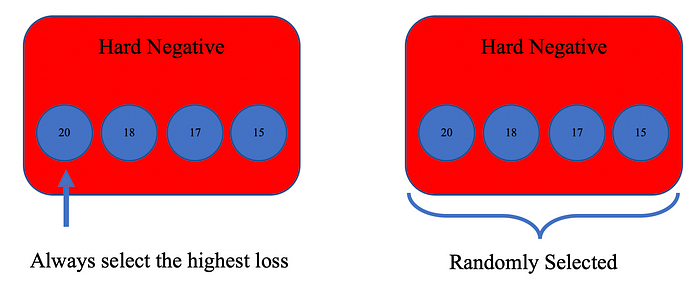
三元组的选择有几种选择策略:首先计算该批次中所有正负样本相对于锚点的三重损失(如果由N个正样本和N个负样本,则由N*N个三重损失),然后将损失从低到高排序,再将有序的损失分成 3 类:难例、半难例和容易例。根据选择策略,可以从难负例、半难负例和容易负例中随机选择负例做为三元组。下图中蓝色圆圈代表一个三元组(3 张图像:锚点、正和负),数字是它们的三元损失。

选择策略有两种方法,一是选择三元损失最大的三元组,第二从难例中随机选择三元组。实践发现,第一种方式,训练集中在小部分最难学习的图像样本上,缺乏泛化性。最终选择了第二种方式。
网络模型搭建: 对于网络选择,一开始选择resnet和densenet的效果并不好,后来自己搭建了网络模型,最后尝试下来发现inceptionv3的增加模型宽度的多卷积核的效果最成功,下面是最终搭建的网络模型结构。
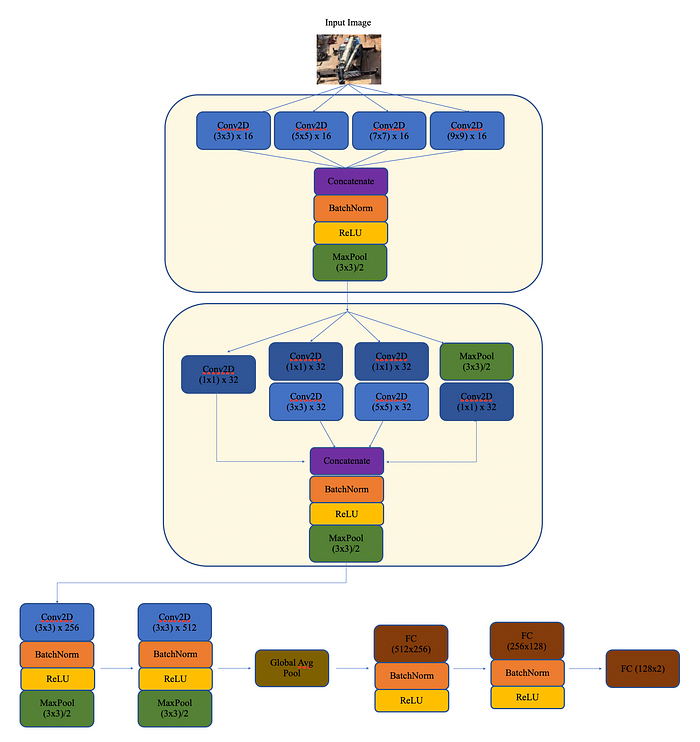
这里有两个关键模块:第一个模块由 4 个不同内核大小的 2D 卷积组成,用于提取不同大小的特征,然后将输出连接在一起。第二个模块的灵感来自 InceptionV3 模块,1x1 深度可分离卷积层旨在最大限度地减少模型中的参数数量。其余模块遵循传统的Conv,BatchNorm,ReLU和MaxPool堆叠,采用全局平均池化在全连接层之前将特征图在空间上简化为特征向量,模型的输出是一个二维向量,便于可视化嵌入空间。
训练方法: 将数据集分为训练集和测试集,按捕获帧的月份分开,训练集由在指定用于训练的月份中收集的一小部分图像样本组成,为确保涵盖所有可能的起重机方向以及所有起重机品牌类型,需手动选择。而后将剩余的图像与测试月份的图像组合在一起,以创建一个大型测试集。
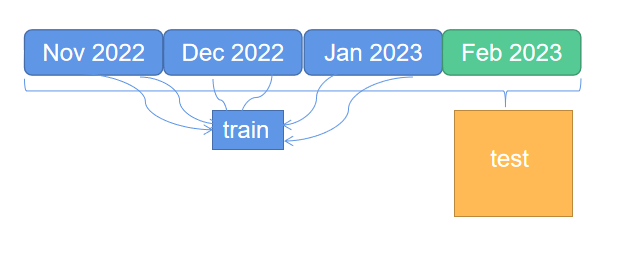
从 3 个月内收集小样本图像做训练集,而其余图像与测试集月份(绿色)合并做为测试集
下表汇总了数据集:
下表是训练集中每个类的示例图像:

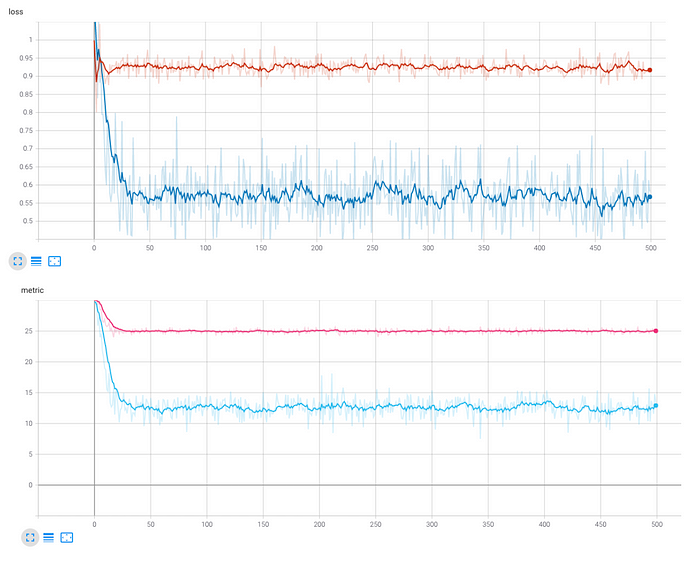
训练中选择Adam优化器训练模型,将边距设置为1,在每个batch中每个类的样本数量为5,并训练了500个epoch。对于评价指标,通过计算每个batch中非零三元组的平均数量。非零三元组的定义为设置一个正样本与锚点距离阈值以及一个margin值,在阈值以内,正样本与锚点的距离在阈值以内,负样本与锚点的距离在阈值+margin值以外,则为零三元组,否则为非零三元组,其中非零三元组的数量越少越好,这意味着模型正在的类内embedding比类间embedding更相似。
结果: 训练和测试集的损失和评估指标如下所示。
下面是整个训练数据集集的输出embedding。这里 A 是移动状态,BC 是支腿伸展状态,D 是开臂状态。
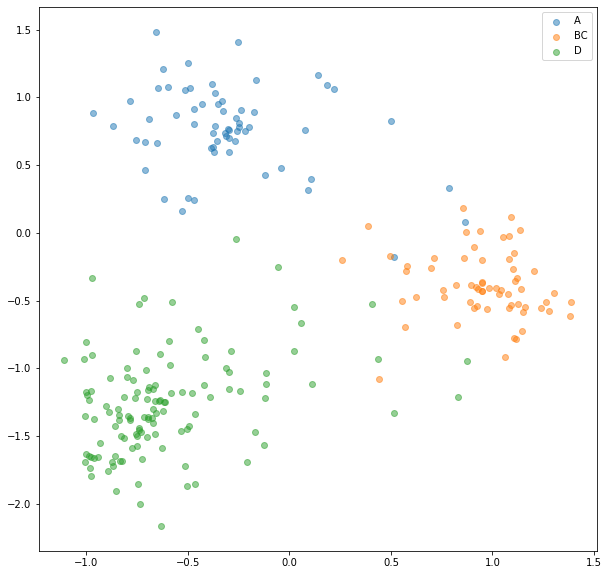
从图中结果表明,每个类似乎都有一个不同的聚类,为将其变成分类器,这里使用支持向量机 (SVM)(这里选择SVM的主要原因是样本少,也尝试有其他的方法,效果不理想) 来查找最佳超平面(在这种情况下只是平面),以按类分隔区域。
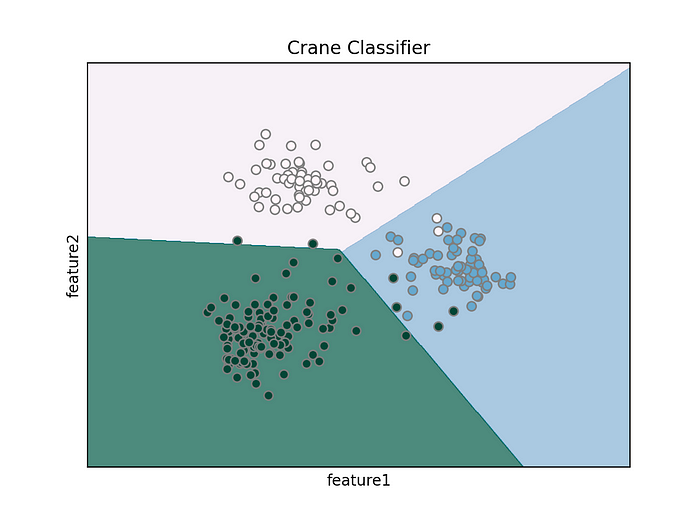
训练数据集上的 SVM 分离。
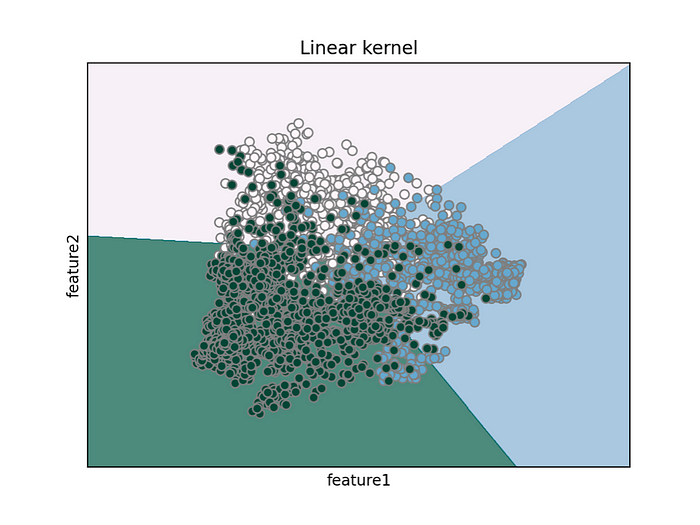
下面是从训练集计算的 SVM 在测试集上的表现:
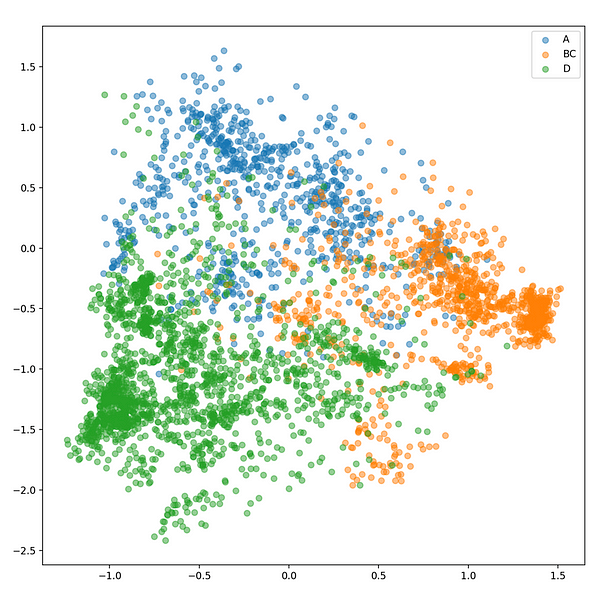
测试集的embedding
下表总结了测试集上的分类器性能以及混淆矩阵。

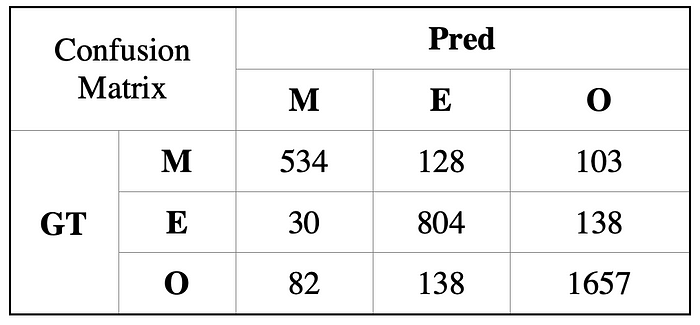
结果相对于之前好很多,分类器展示了提取embedding特征并将它们映射到可分离空间的能力。同时因为测试集为2月份场景与之前场景存在少许差距,从2月份的数据中每类抽取10张,放入训练集中,再拿剩下的测试集测试的话,模型性能就会显着提高。

错误分析: 仔细分析预测错误的图像,基本上是因为拍摄视角模糊、遮挡导致的,如下图中预测开臂状态,但实际是支腿伸展状态。吊臂似乎被部分抬起,以及起重机的不同视角,导致的错误分类。

gt=支腿伸展状态,pred=开臂状态

gt=移动状态,pred=支腿伸展状态

gt=开臂状态,pred=移动状态
总结
以上项目中的一个需求延申出来的一些实际解决方案,主要想分享的是在图像分类场景中,数据集很少、数据分布不均衡且数据类别间的差距较小时,可以用对比学习的方法来替代图像分类,同时越来越觉得算法的各个模型都是手段,适用于该场景的算法才是好算法,欢迎大家一起讨论学习。
来源丨所向披靡的张大刀