计数器法:https://gitee.com/lymgoforIT/golang-trick/tree/master/08-count-limit-rate
令牌桶算法:https://gitee.com/lymgoforIT/golang-trick/tree/master/09-token-bucket-limiter
漏桶算法:https://gitee.com/lymgoforIT/golang-trick/tree/master/10-leaky-bucket-limiter
计数器、滑动窗口、漏斗算法、令牌桶算法是常见的几个限流算法,虽然已经有现成的包可以直接使用,但理解各算法的原理以及代码实现还是很有帮助的。
1. 计数器法
计数器是一种最简单限流算法,其原理就是:在一段时间间隔内,对请求进行计数,与阀值进行比较判断是否需要限流,一旦到了时间临界点,将计数器清零。
可以在程序中设置一个变量 count,当过来一个请求我就将这个数 +1,同时记录请求时间。
当下一个请求来的时候判断count的计数值是否超过设定的频次,以及当前请求的时间和第一次请求时间是否在 1 分钟内。
如果在 1 分钟内并且超过设定的频次则证明请求过多,后面的请求就拒绝掉。
如果该请求与第一个请求的间隔时间大于计数周期,且 count 值还在限流范围内,就重置 count。
常见使用redis的string类型 incr(),能保障原子性操作,比如对每秒限流,可以每秒设置一个key(limit-2023-12-25-22:11:11)。首先获取当前时间拼接一个如上的key(即拼上自定义的前缀limit-)。如果key存在且未超过某个阈值就自增,超过阈值就拒绝;如果key不存在就代表这新的一秒没有请求则重置计数。
代码实现:
type CountLimiter struct {
rate int64 // 计数周期内运行的最大请求数
begin time.Time // 当前轮计数开始时间
count int64 // 当前计数周期累计的请求数
cycle time.Duration // 计数周期,如统计1秒内的总请求数,那么计数周期就是1秒
lock sync.Mutex // 判断能否放行时需要加锁操作
}
func NewCountLimiter(rate int64, cycle time.Duration) *CountLimiter {
return &CountLimiter{
rate: rate,
begin: time.Now(),
count: 0,
cycle: cycle,
lock: sync.Mutex{},
}
}
func (c *CountLimiter) Allow() bool {
c.lock.Lock()
defer c.lock.Unlock()
if c.count == c.rate { // 达到最大限流时,判断时间是否也超过统计周期了,超了可以重置限流器了,没有超说明还在当前统计周期内,应该拦截
if time.Now().Sub(c.begin) > c.cycle {
c.Reset()
return true
} else {
return false
}
} else { // 还没有达到最大限流数,那么不管时间周期是否超出统计计数周期,都可以放行
c.count++
return true
}
}
func (c *CountLimiter) Reset() {
c.begin = time.Now()
c.count = 0
}
func main() {
countLimiter := NewCountLimiter(3, time.Second) // 1s内不可超过3个请求
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func(i int) {
defer wg.Done()
if countLimiter.Allow() {
fmt.Println(fmt.Sprintf("当前时间%s,请求%d通过了", time.Now().String(), i))
} else {
fmt.Println(fmt.Sprintf("当前时间%s,请求%d被限流了", time.Now().String(), i))
}
}(i)
time.Sleep(200 * time.Millisecond)
}
wg.Wait()
}
结果:(截图)
缺点【临界值】
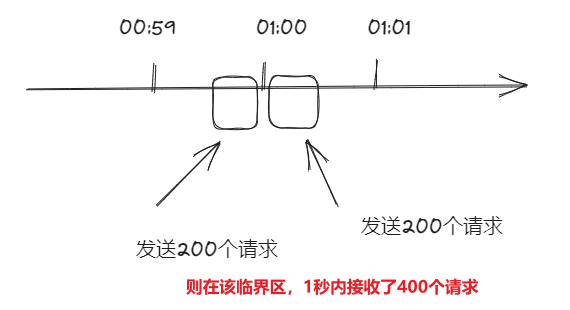
如果有个需求对于某个接口 /query 每分钟最多允许访问 200 次,假设有个用户在第 59 秒的最后几毫秒瞬间发送 200 个请求,当 59 秒结束后 Counter 清零了,在下一秒的时候又发送 200 个请求。那么在 1 秒钟内这个用户发送了 2 倍的请求,这个是符合设计逻辑的,这也是计数器方法的设计缺陷,系统可能会承受恶意用户的大量请求,甚至击穿系统。
2. 令牌桶算法
令牌桶算法(Token Bucket)是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。想象有一个木桶,以固定的速度往木桶里加入令牌,木桶满了则不再加入令牌。服务收到请求时尝试从木桶中取出一个令牌,如果能够得到令牌则继续执行后续的业务逻辑;如果没有得到令牌,直接返回访问频率超限的错误码或页面等,不继续执行后续的业务逻辑。
由于木桶内只要有令牌,请求就可以被处理,所以令牌桶算法可以支持突发流量。同时由于往木桶添加令牌的速度是固定的,且木桶的容量有上限,所以单位时间内处理的请求数目也能够得到控制,起到限流的目的。假设加入令牌的速度为 1token/10ms(则1s内最多放置100个令牌,因此QPS期望是100左右),另一方面,桶的容量为500,在请求比较的少的时候(小于每10毫秒1个请求)时,木桶可以先"攒"一些令牌(最多500个)。当有突发流量时,一下把木桶内的令牌取空,也就是有500个在并发执行的业务逻辑,之后要等每10ms补充一个新的令牌才能接收一个新的请求。
木桶的容量设置:需要考虑业务逻辑的资源消耗和机器能承载并发处理多少业务逻辑。
生成令牌的速度设置 :太慢的话起不到“攒”令牌应对突发流量的效果,可根据预估或压测的QPS进行设置。
令牌按固定的速率被放入令牌桶中
桶中最多存放 B 个令牌,当桶满时,新添加的令牌被丢弃或拒绝
如果桶中的令牌不足 1个,则不会删除令牌,且请求将被限流(丢弃或阻塞等待)
令牌桶限制的是平均流入速率(允许突发请求,只要有令牌就可以处理,支持一次拿多个令牌),并允许一定程度突发流量。
适用场景
适合电商抢购或者微博出现热点事件的场景,因为在限流的同时可以应对一定的突发流量。如果采用均匀速度处理请求的算法,在发生热点时间的时候,会造成大量的用户无法访问,对用户体验的损害比较大。
假设设置每100ms生产一个令牌,记录最近一次访问的时间戳 lastTime 和令牌数,每次请求时如果 now - lastTime > 100ms, 增加 (now - lastTime) / 100ms个令牌。然后,如果令牌数 > 0,令牌数 -1 继续执行后续的业务逻辑,否则返回请求频率超限的错误码或页面。
上面的算法是对整体的请求进行的限流,如果是要对用户或IP进行限流,则可以使用map[string]Limiter控制,key为userId或IP,value为对应的限流器。
代码实现:
package main
import (
"fmt"
"sync"
"time"
)
type TokenBucketLimiter struct {
lock sync.Mutex
rate time.Duration // 多长时间放入一个令牌,即放入令牌的速率
capacity int64 // 令牌桶的容量,控制最多放入多少令牌,也即突发最大并发量
tokens int64 // 当前桶中已有的令牌数量
lastTime time.Time // 上次放入令牌的时间,避免开启协程定时去放入令牌,而是请求到来时懒加载的方式(now - lastTime) / rate放入令牌
}
func NewTokenBucketLimiter(rate time.Duration, capacity int64) *TokenBucketLimiter {
if capacity < 1 {
panic("token bucket capacity must be large 1")
}
return &TokenBucketLimiter{
lock: sync.Mutex{},
rate: rate,
capacity: capacity,
tokens: 0,
lastTime: time.Time{},
}
}
func (tbl *TokenBucketLimiter) Allow() bool {
tbl.lock.Lock() // 加锁避免并发错误
defer tbl.lock.Unlock()
// 如果 now 与上次请求的间隔超过了 token rate
// 则增加令牌,更新lastTime
now := time.Now()
if now.Sub(tbl.lastTime) > tbl.rate {
tbl.tokens += int64((now.Sub(tbl.lastTime)) / tbl.rate) // 放入令牌
if tbl.tokens > tbl.capacity {
tbl.tokens = tbl.capacity // 总令牌数不能大于桶的容量
}
tbl.lastTime = now // 更新上次往桶中放入令牌的时间
}
if tbl.tokens > 0 { // 令牌数是否充足
tbl.tokens -= 1
return true
}
return false // 令牌不足,拒绝请求
}
func main() {
tbl := NewTokenBucketLimiter(10, 5) // 每10ms放一个令牌,1s放100个,桶容量(最大突发流量)为5
for i := 0; i < 10; i++ {
fmt.Println(tbl.Allow()) // 模拟突发流量10个请求,超过桶容量5
}
time.Sleep(100 * time.Millisecond)
fmt.Println(tbl.Allow())
}
结果:(截图)
漏桶算法
与令牌桶是“反向”的算法,当有请求到来时先放到木桶中,worker以固定的速度从木桶中取出请求进行相应。如果木桶已经满了,直接返回请求频率超限的错误码或者页面。
漏桶算法有以下特点:
漏桶具有固定容量,出水速率是固定常量(流出请求)
如果桶是空的,则不需流出水滴
可以以任意速率流入水滴到漏桶(流入请求)
如果流入水滴超出了桶的容量,则流入的水滴溢出(新请求被拒绝)
漏桶限制的是常量流出速率(即流出速率是一个固定常量值),所以最大的速率就是出水的速率,不能出现突发流量。
适用场景
流量最均匀的限流方式,一般用于流量“整形”,例如保护数据库的限流。先把对数据库的访问加入到木桶中,worker再以db能够承受的qps从木桶中取出请求,去访问数据库。不太适合电商抢购和微博出现热点事件等场景的限流,一是应对突发流量不是很灵活,二是如果需要对用户或者IP限流,则用map为每个user_id/ip维护一个队列(木桶),workder从这些队列中拉取任务,资源的消耗会比较大。
通常使用队列来实现,在go语言中可以通过带缓冲的通道buffered channel来快速实现,任务加入channel,开启一定数量的 worker 从 channel 中获取任务执行,这一定数量的worker表示的就是限流,如开启5个worker,便表示限流速度为5,即同一时刻最多处理5个请求。
package main
import (
"context"
"fmt"
"sync"
"time"
)
type Result struct {
Msg string // 根据实际情况定义返回结果需要哪些字段
}
type Handler func() Result // 处理函数的形式也应该根据具体需要而定
type Task struct {
id int64 // 任务id
result chan Result // 任务的执行结果,即请求的响应结果
handler Handler // 请求的执行函数
}
func NewTask(id int, handler Handler) Task {
return Task{
handler: handler,
result: make(chan Result),
id: int64(id),
}
}
type LeakyBucketLimiter struct {
bucketSize int64 // 桶的大小
workerNum int64 // 工作者数量,即最大并发数
taskChan chan Task // 用于存放请求
}
func NewLeakyBucketLimiter(bucketSize, workerNum int64) *LeakyBucketLimiter {
if capacity < 1 {
panic("capacity must be large 1")
}
if workerNum < 1 {
panic("workerNum must be large 1")
}
return &LeakyBucketLimiter{
bucketSize: bucketSize,
workerNum: workerNum,
taskChan: make(chan Task, bucketSize),
}
}
func (lbl *LeakyBucketLimiter) AddTask(task Task) bool { // 类似其他限流算法的Allow方法
// 如果木桶已经满了,或者任务执行失败或超时了,返回false
select {
case lbl.taskChan <- task: // 利用了select的特性判断是否能往通道中添加任务
default:
fmt.Printf("请求%d被拒绝了\n", task.id)
return false
}
// 如果成功入桶,调用者会等待Task的Handler执行结果
// 由于Task的result是无缓冲的通道,不应该让其无限等待阻塞,否则出现问题时,不往该chan写,就会一直阻塞在这里了,泄漏
// 因此设置一个超时时间
//resp := <-task.result
//fmt.Printf("请求%d运行成功,结果为:%v\n", task.id, resp)
select {
case resp := <-task.result:
fmt.Printf("请求%d运行成功,结果为:%v\n", task.id, resp)
case <-time.After(5 * time.Second): // 超时时间可以稍微设置长一点点,因为任务放入桶中后,可能需要排队一点时间才被拉取出来执行
return false // 这里超时当被限流处理
}
return true
}
func (lbl *LeakyBucketLimiter) Start(ctx context.Context) {
// 开启workerNum个协程从木桶拉取任务执行
for i := 0; int64(i) < lbl.workerNum; i++ {
go func(ctx context.Context) {
defer func() { // 铁则:开启的子协程一定要捕获异常,否则一旦出现异常会依次上抛,上抛也一直不捕获,会导致程序退出
if err := recover(); err != any(nil) {
fmt.Println("捕获到异常")
}
}()
for { // 持续监听,拉取任务执行
select {
case <-ctx.Done():
fmt.Println("退出工作")
return
default:
task := <-lbl.taskChan
result := task.handler()
task.result <- result // 处理结果写入对应Task的结果通道
}
}
}(ctx)
}
}
func main() {
bucket := NewLeakyBucketLimiter(10, 4)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
bucket.Start(ctx) // 开启消费者
// 模拟20个并发请求
var wg sync.WaitGroup
wg.Add(20)
for i := 0; i < 20; i++ {
go func(id int) {
defer wg.Done()
task := NewTask(id, func() Result { // 这里的func应该根据实际需要定义为handler,写具体的业务逻辑和返回的result
time.Sleep(300 * time.Millisecond) // 模拟业务逻辑消耗的时间
return Result{}
})
bucket.AddTask(task) // 请求入桶
}(i)
}
wg.Wait()
time.Sleep(10 * time.Second)
}
结果:(截图)
上面的代码其实已经有点类似生产者消费者模型了,添加任务即往队列中放任务(生产消息),然后安排一定数量的协程(消费者)拉取任务执行(消费消息)。