task1_1.py
code:
with open('data1.txt','r',encoding='utf-8')as f: data=f.readlines() n=0 print(data) for line in data: if not line.strip()=='': n+=1 print(n)
output:

note:
if delet "not" in line 6, the output will be the spare line
task1_2.py
code:
with open('data1.txt','r',encoding='utf-8')as f: n_1=0 for line in f: if not line.strip()=='': n_1+=1 print(n_1)
output:

task1_3.py
code:
with open('data1.txt','r',encoding='utf-8')as f: n_1=0 for line in f: if not line.isspace(): n_1+=1 print(n_1)
output:
task2_1.py
code:
with open('data2.txt', 'r', encoding = 'utf-8') as f: data = f.read().split('\n') unique_line_lst = [] for line in data: if data.count(line) == 2: unique_line_lst.append(line) n = len(unique_line_lst) print(f'data2.txt共{n}行独特行') for line in unique_line_lst: print(line) unique_line_lst = [] for line in data: if data.count(line) == 1: unique_line_lst.append(line) n = len(unique_line_lst) print(f'data2.txt共{n}行独特行') for line in unique_line_lst: print(line)
output:

task3_1.py:
code:
title = ['城市', '人口(万)'] info = [['南京', '850'], ['纽约', '2300'], ['东京', '3800'], ['巴黎', '1000']] with open('city1.csv', 'w', encoding = 'gbk') as f: f.write(','.join(title) + '\n') # 写入标题行 for item in info: # 分行写入info f.write(','.join(item) + '\n')
output:
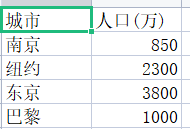
task3_2.py:
code:
with open('city1.csv', 'r', encoding = 'gbk') as f: data = f.read() print(data.rstrip('\n'))
output:
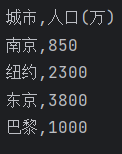
task3_3.py:
code:
with open('city1.csv', 'r', encoding = 'gbk') as f: data = f.readlines() print('data: ') print(data) info = [line.strip('\n').split(',') for line in data] print('info:') print(info)
output:

task3_4.py:
code:
import csv title = ['城市', '人口(万)'] info = [['南京', '850'], ['纽约', '2300'], ['东京', '3800'], ['巴黎', '1000']] with open('city2.csv', 'w', encoding = 'gbk', newline = '') as f: f_writer = csv.writer(f) # 为文件对象f创建一个writer对象(necessary) f_writer.writerow(title) # 通过writer对象的方法writerow()写入一行(标题行) f_writer.writerows(info) # 通过writer对象的方法writerows()写入多行(注意row和rows)
output:
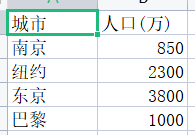
task3_5.py:
code:
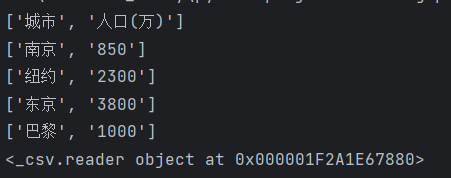
import csv with open('city2.csv', 'r', encoding = 'gbk') as f: f_reader = csv.reader(f) # 为文件对象f创建一个reader对象 for line in f_reader: print(line) print(f_reader)
output:
task4.py:
code:
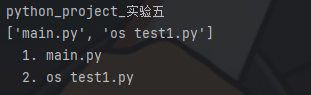
import os print(os.path.basename(os.getcwd())) # 将当前路径下所有.py文件名保存到py_file_lst中 py_file_lst = [file for file in os.listdir() if file.endswith('.py')] # 遍历输出 print(py_file_lst) for number, file in enumerate(py_file_lst, 1): print(f'{number:-3d}. {file}')
output:
task6.py
code:
with open('data6.csv','r',encoding = 'gbk') as f:
old_data = f.read().split('\n')
del old_data[0]
new_data = []
for i in range(len(old_data)-1):
if eval(old_data[i]) + float(0.5) >= int(eval(old_data[i])) + 1:
new_data.append(str(int(eval(old_data[i]))+1))
else:
new_data.append(str(int(eval(old_data[i]))))
title = ['原始数据','四舍五入后数据']
data = []
for i in range(len(old_data)-1):
data.append([old_data[i],new_data[i]])
with open('data6.csv','w',encoding = 'gbk') as f:
f.write(','.join(title) + '\n')
for i in data:
f.write(','.join(i) + '\n')
old_data = f.read().split('\n')
del old_data[0]
new_data = []
for i in range(len(old_data)-1):
if eval(old_data[i]) + float(0.5) >= int(eval(old_data[i])) + 1:
new_data.append(str(int(eval(old_data[i]))+1))
else:
new_data.append(str(int(eval(old_data[i]))))
title = ['原始数据','四舍五入后数据']
data = []
for i in range(len(old_data)-1):
data.append([old_data[i],new_data[i]])
with open('data6.csv','w',encoding = 'gbk') as f:
f.write(','.join(title) + '\n')
for i in data:
f.write(','.join(i) + '\n')
output:

task7.py
code:
with open('data7.csv','r',encoding = 'gbk') as f: info = f.read().split('\n') del info[0] major_dict = {} for i in info: person_list = i.split(',') major_dict[i] = person_list[2] items = [[k,v] for k,v in major_dict.items()] items.sort(key=lambda x:x[1]) majors_count = 1 majors_list = [] for i in range(len(items)-1): if items[i+1][1] == items[i][1] and items[i][1] not in majors_list: majors_list.append(items[i][1]) pass elif items[i+1][1] == items[i][1] and items[i][1] in majors_list: pass else: majors_list.append(items[i+1][1]) majors_count += 1 for i in range(majors_count): x = locals()[f'major{i+1}'] = [] for j in range(len(items)): if items[j][1] == majors_list[i]: x.append(items[j][0]) else: pass score_dict1 = {} for i in major1: person_list = i.split(',') score_dict1[i] = person_list[3] items1 = [[k,v] for k,v in score_dict1.items()] items1.sort(key=lambda x:x[1],reverse = True) score_dict2 = {} for i in major2: person_list = i.split(',') score_dict2[i] = person_list[3] items2 = [[k,v] for k,v in score_dict2.items()] items2.sort(key=lambda x:x[1],reverse = True) together = items1 + items2 final_data = [i[0] for i in together] final_list = [] for i in final_data: person_list = i.split(',') final_list.append(person_list) print(final_list) title = ['学号','姓名','专业','分数'] with open('data7.csv', 'w', encoding = 'gbk') as f: f.write(','.join(title) + '\n') for item in final_list: f.write(','.join(item) + '\n')
output:

[['1007', '小李子', 'Acting', '92'], ['1008', '甜茶', 'Acting', '91'], ['1006', '裘花', 'Acting', '89'], ['1009', '囧瑟夫', 'Acting', '88'], ['1005', '无脸男', 'Acting', '85'], ['1004', '大眼仔', 'Acting', '82'], ['1001', '抖森', 'Acting', '80'], ['1003', '毛怪', 'Acting', '75'], ['1002', '宝爷', 'Music', '97'], ['1010', '霉霉', 'Music', '96']]
task8.py
code:
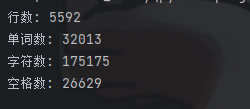
lines_count = 0 words_count = 0 chrs_count = 0 space_count = 0 with open('hamlet.txt','r',encoding = 'utf-8') as f: for line in f: words = line.split() lines_count += 1 words_count += len(words) chrs_count += len(line) for i in list(line): if i == ' ': space_count += 1 else: pass print('行数:',lines_count) print('单词数:',words_count) print('字符数:',chrs_count) print('空格数:',space_count)
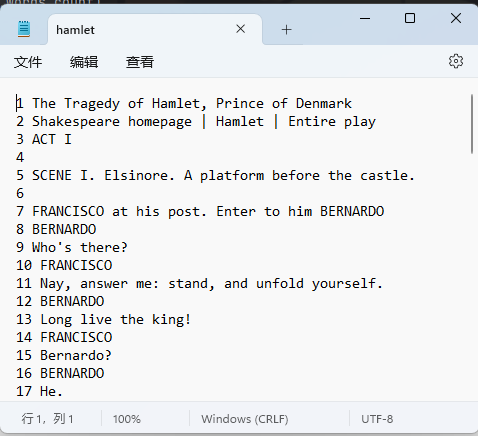
with open('hamlet.txt','r',encoding = 'utf-8') as f:
text = f.readlines()
for i in range(len(text)):
if text[i]:
text[i] = str(i+1) + ' ' + text[i]
with open('hamlet.txt','w',encoding = 'utf-8') as f:
f.writelines(text)
text = f.readlines()
for i in range(len(text)):
if text[i]:
text[i] = str(i+1) + ' ' + text[i]
with open('hamlet.txt','w',encoding = 'utf-8') as f:
f.writelines(text)
output:
task9.py
code:
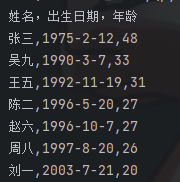
def is_valid(p_id): if len(p_id) != 18: return False else: a = p_id[-1] b = p_id[:-1] if b.isdigit() == True and a == 'X' or p_id.isdigit() == True: return True else: return False with open('data9_id.txt','r',encoding = 'utf-8') as f: info = f.read().split('\n') del info[0] id_list = [] for i in info: x = i.split(',') if x[0] not in id_list and is_valid(x[1]) == True: id_list.append([x[0],x[1]]) import datetime t = datetime.datetime.now() year_now = int(t.strftime('%Y%m%d')[0:4]) month_now = int(t.strftime('%Y%m%d')[4:6]) day_now = int(t.strftime('%Y%m%d')[6:8]) year_dict = {} for i in range(len(id_list)): p_id = id_list[i][1] year = int(p_id[6:10]) month = int(p_id[10:12]) day = int(p_id[12:14]) p_info = id_list[i][0] + ',' + str(year) + '-' + str(month) + '-' + str(day) + ',' if month <= month_now and day < day_now: year_dict[p_info] = year_now - year - 1 else: year_dict[p_info] = year_now - year print('姓名,出生日期,年龄') items = [[k,v] for k,v in year_dict.items()] items.sort(key=lambda x:x[1],reverse = True) for i in items: print(f'{i[0]}{i[1]}')
output:
task10_1.py
code:
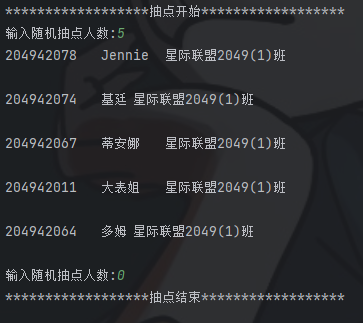
print(f"{'抽点开始':*^40}") import random as r with open('data10_stu.txt','r',encoding = 'utf-8') as f: stu = f.readlines() def the_lucky_dogs(n): stu_list = [] while True: if n != 0: i = r.randint(0,len(stu)-1) if stu[i] not in stu_list: stu_list.append(stu[i]) print(stu[i]) n -= 1 else: pass else: print(f"{'抽点结束':*^40}") break n = int(input('输入随机抽点人数:')) the_lucky_dogs(n)
output:
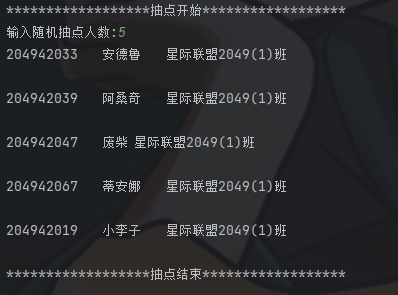
task10_2.py
code:
print(f"{'抽点开始':*^40}") import random as r with open('data10_stu.txt','r',encoding = 'utf-8') as f: stu = f.readlines() def the_lucky_dogs(n): stu_list = [] while True: if n != 0: i = r.randint(0,len(stu)-1) if stu[i] not in stu_list: stu_list.append(stu[i]) print(stu[i]) n -= 1 else: pass else: break for i in stu_list: stu.remove(i) while True: n = int(input('输入随机抽点人数:')) if n != 0: the_lucky_dogs(n) else: print(f"{'抽点结束':*^40}") break
output: