博客园首发,转载请注明地址:https://www.cnblogs.com/tzxxh/p/17792469.html
前言
Apache Kyuubi 是一个分布式和多租户网关,用于在数据仓库和湖仓上提供无服务器 SQL。Apache Celeborn 是一个Remote Shuffle Service的实现方案。本文参考 Kyuubi 和 Celeborn官网,在搭建之前需要大家事先准备好k8s、kyuubi和celeborn。
问题引入
根据 celeborn官网,spark调用celeborn时,需要把对应的jar包放到$SPARK_HOME/jars/ 目录下。大家都知道spark on k8s 需要打spark 镜像,那如果celeborn升级了,难道要重打镜像吗?
当然这是一种办法,但是作为有追求的(爱折腾)的程序员,肯定不喜欢这种不优雅的方式。
你可能会想到指定spark.jars不就完了,如果你这样试了,会得到如下的结果:
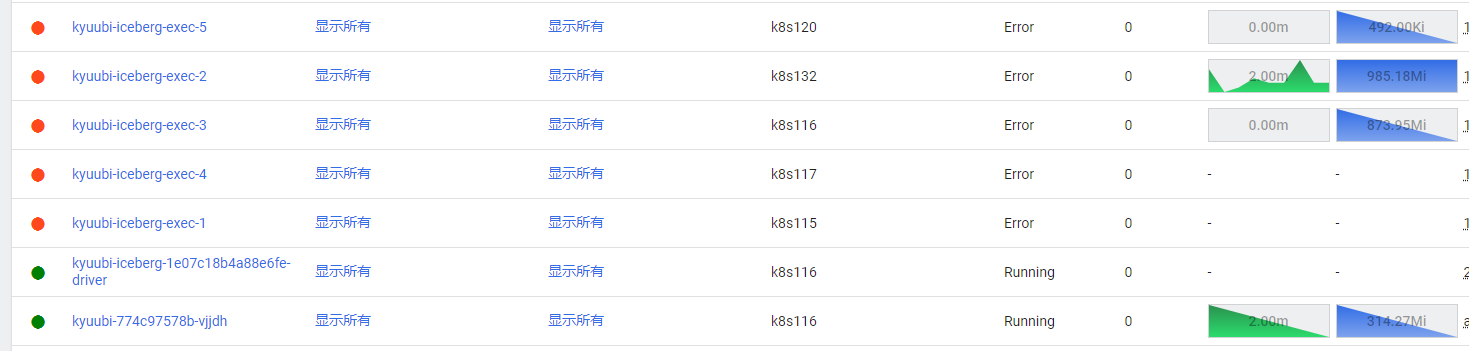
可以看到driver启动成功,但是executor启动却是失败的,点开一个executor查看日志如下:
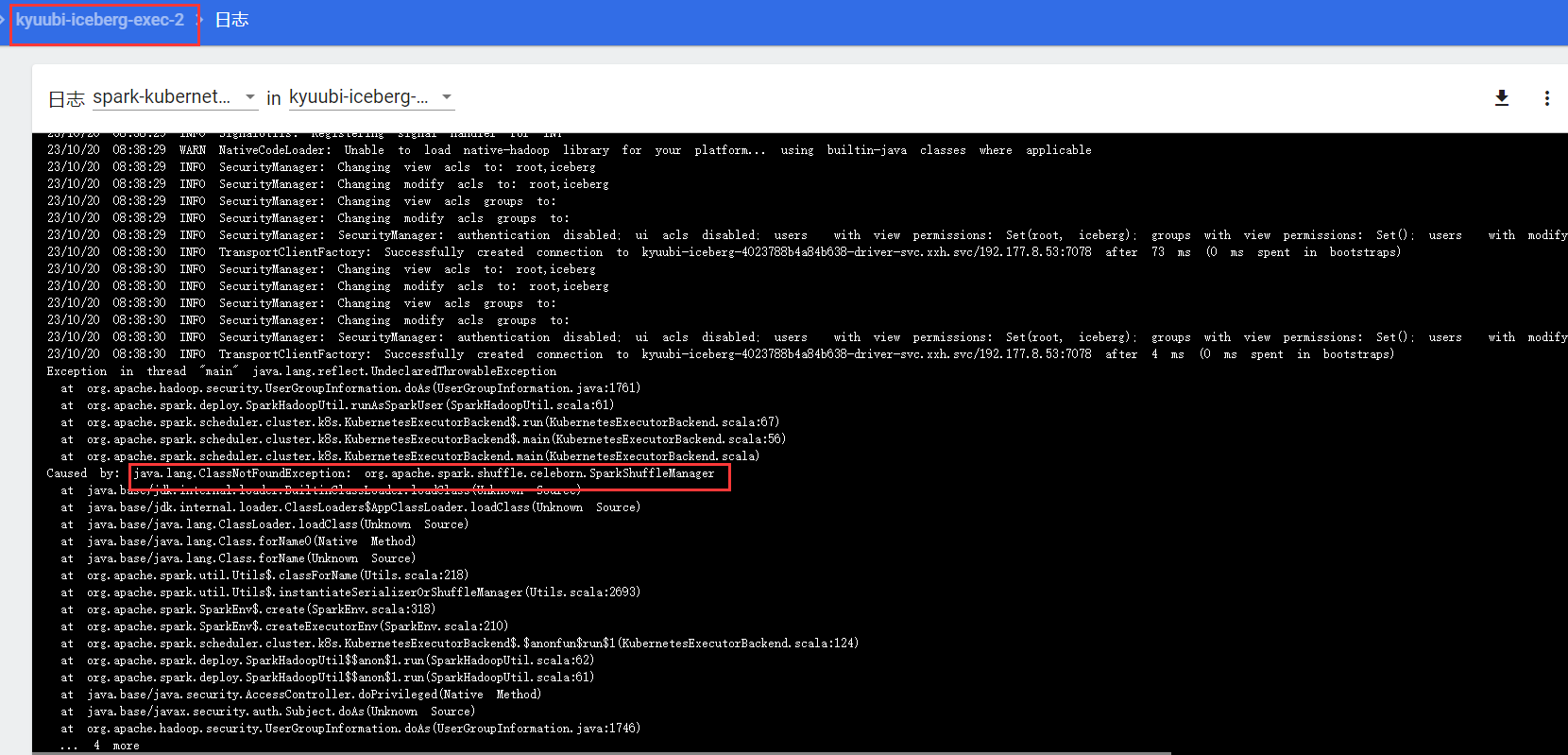
这是为什么呢?
问题探究
下面来看一张executor启动成功的截图
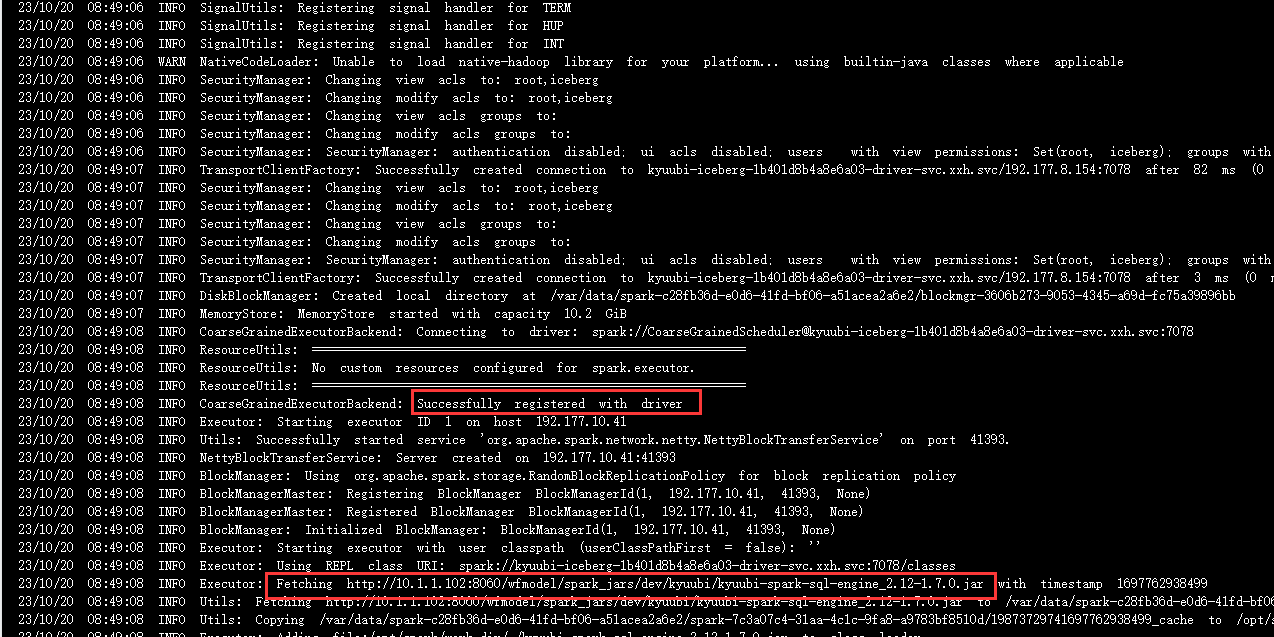
可以看到拉取spark.jars指定的jar包是在executor启动成功之后!
结合executor启动失败的那张图可以得出,启动失败的原因是:在executor启动过程中发现缺少celeborn相关jar包。(注:关于executor的启动流程细节,感兴趣的同学可以读源码或者搜索相关技术文章,本文不讨论executor启动的具体过程。)
那有什么办法可以在executor启动之前把jar包拉取下来呢?
问题解决
咱们用的是spark on k8s的方式,executor是以pod的方式启动的,既然是pod,结合spark.kubernetes.{driver,executor}.podTemplateFile 就可以指定 init containers 控制pod的创建过程,pod template文件如下:
apiversion: v1
kind: Pod
spec:
volumes:
- name: external-jars
emptyDir: {}
containers:
- volumeMounts:
- name: external-jars
mountPath: /opt/spark/external-jars
initContainers:
- name: download-external-jars
image: docker.wanfangdata.com.cn/wfk8s/busybox:1.28
command: ['sh', '-c', "wget -P /opt/spark/external-jars http://YOUR_URL/celeborn-client.jar"]
volumeMounts:
- name: external-jars
mountPath: /opt/spark/external-jars
hostAliases:
- ip: IP
hostnames:
- HOSTNAME
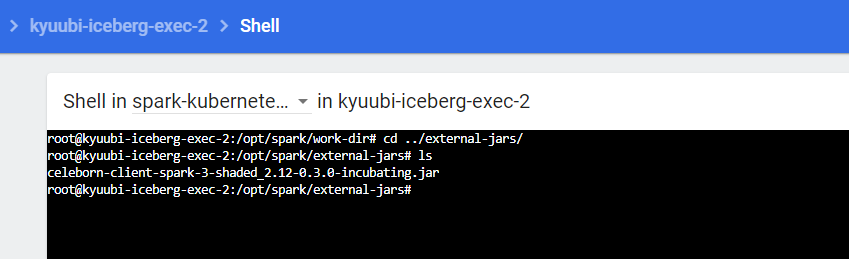
pod template 中指定的init containers 已经下载了celeborn jar包。
那如何把下载的这个jar包,加入到class path下呢?
查看spark镜像的entrypoint executor启动部分如下:
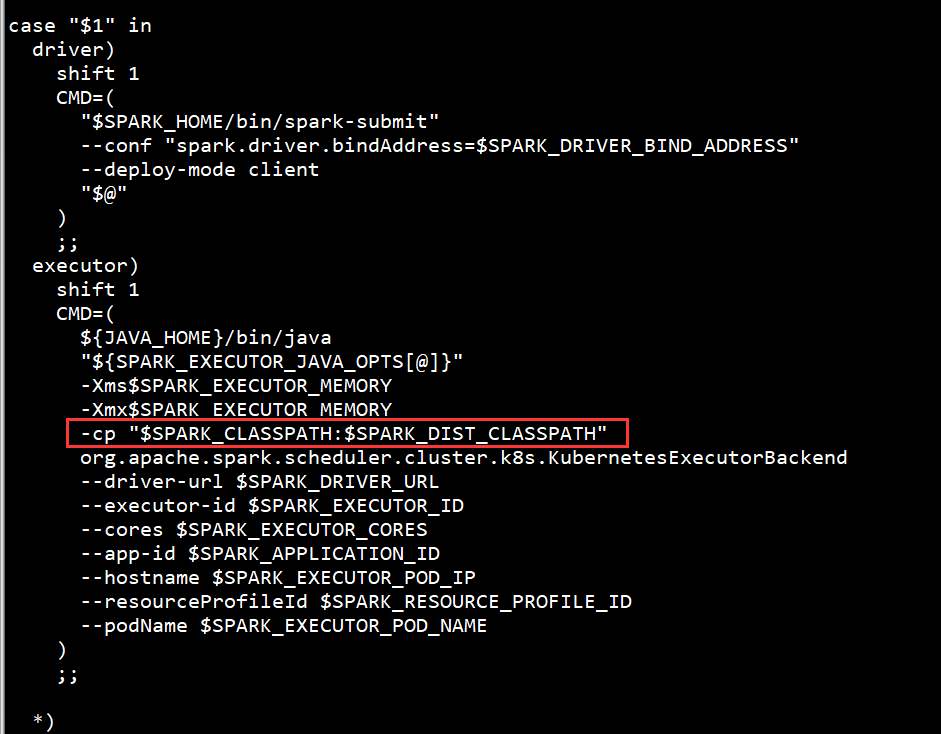
原来是用SPARK_CLASSPATH环境变量进行控制的。
那剩下的就简单了,只需要指定上如下参数就行了。
spark.executorEnv.[EnvironmentVariableName]
eg:
spark.executorEnv.SPARK_CLASSPATH=/opt/spark/external-jars/*
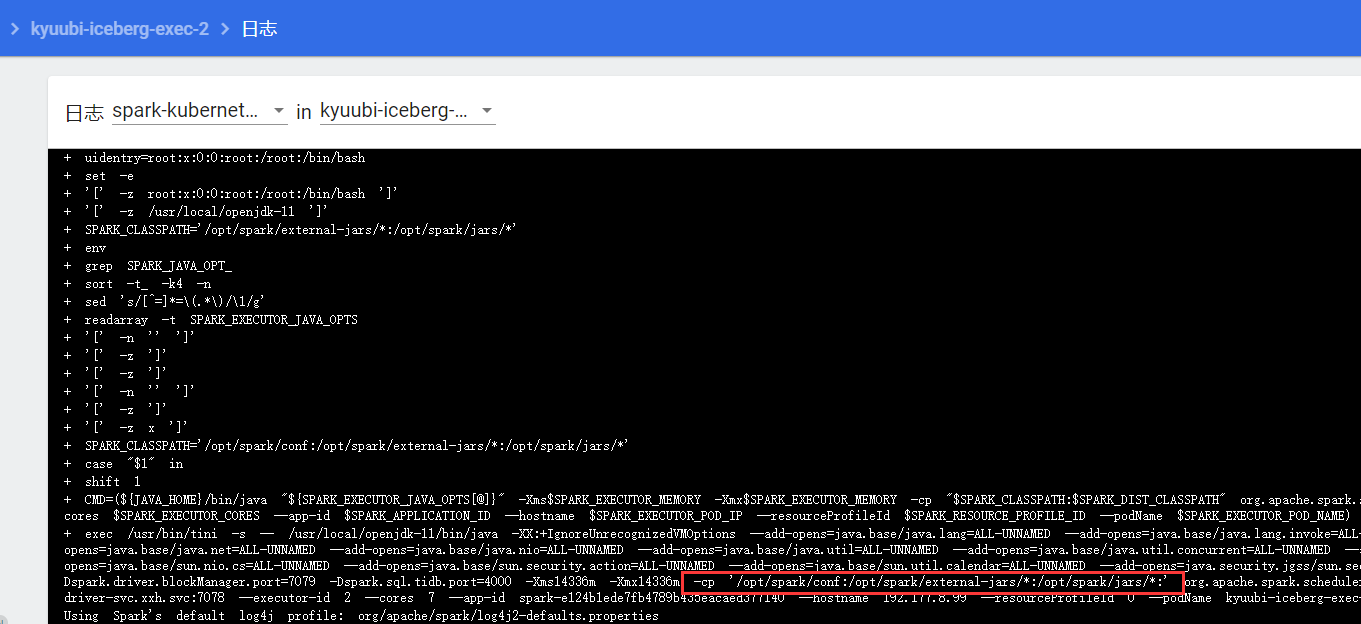
环境变量生效,executor pod启动成功。
如果celeborn版本升级,客户端只需要在init containers 时下载对应版本的jar包就行,不需要重打镜像。
附录
部分spark配置参考:
spark.kubernetes.executor.podTemplateFile=http://YOUR_URL/external-jars.yaml
spark.executorEnv.SPARK_CLASSPATH=/opt/spark/external-jars/*
spark.shuffle.service.enabled=false
spark.shuffle.manager=org.apache.spark.shuffle.celeborn.SparkShuffleManager
spark.celeborn.master.endpoints=YOUR_CELEBORNS_HOST
spark.celeborn.client.spark.shuffle.writer=hash
spark.celeborn.client.push.replicate.enabled=true
spark.sql.adaptive.localShuffleReader.enabled=false
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.shuffleTracking.enabled=false
spark.dynamicAllocation.initialExecutors=5
spark.dynamicAllocation.minExecutors=1
spark.dynamicAllocation.maxExecutors=13
spark.dynamicAllocation.executorAllocationRatio=0.5
spark.dynamicAllocation.executorIdleTimeout=60s
spark.dynamicAllocation.cachedExecutorIdleTimeout=30min
spark.dynamicAllocation.schedulerBacklogTimeout=1s
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=1s
spark.cleaner.periodicGC.interval=5min
spark.jars=http://YOUR_URL/jars