导包
from datetime import datetime
from colorama import Fore, Style
from autogpt.app import execute_command, get_command
from autogpt.config import Config
from autogpt.json_utils.json_fix_llm import fix_json_using_multiple_techniques
from autogpt.json_utils.utilities import LLM_DEFAULT_RESPONSE_FORMAT, validate_json
from autogpt.llm import chat_with_ai, create_chat_completion, create_chat_message
from autogpt.llm.token_counter import count_string_tokens
from autogpt.log_cycle.log_cycle import (
FULL_MESSAGE_HISTORY_FILE_NAME,
NEXT_ACTION_FILE_NAME,
USER_INPUT_FILE_NAME,
LogCycleHandler,
)
from autogpt.logs import logger, print_assistant_thoughts
from autogpt.speech import say_text
from autogpt.spinner import Spinner
from autogpt.utils import clean_input
from autogpt.workspace import Workspace
__init__初始化方法
class Agent:
"""Agent class for interacting with Auto-GPT.
用于和Auto-GPT交互的Agent类
Attributes:
ai_name: The name of the agent.
ai_name是用于指定agent的名称
memory: The memory object to use.
memory代表的是使用的内存对象。
full_message_history: The full message history.
完整的消息历史记录
next_action_count: The number of actions to execute.
执行操作的次数
system_prompt: The system prompt is the initial prompt that defines everything
the AI needs to know to achieve its task successfully.
Currently, the dynamic and customizable information in the system prompt are
ai_name, description and goals.
system_prompt是人工智能成功完成任务所需要的一切的初始提示,
目前,系统提示当中的动态和可以定制的信息有ai_name、description、goals。
triggering_prompt: The last sentence the AI will see before answering.
triggering_prompt:AI回答前看到的最后一句话
For Auto-GPT, this prompt is:
对于Auto-GPT来说,这个所谓的triggering prompt是:
Determine which next command to use, and respond using the format specified
above:
确定一下要使用哪一个下一个命令,并且使用上述指定的格式进行响应。
The triggering prompt is not part of the system prompt because between the
system prompt and the triggering
prompt we have contextual information that can distract the AI and make it
forget that its goal is to find the next task to achieve.
触发提示不是系统提示的一部分。因为在系统提示和触发提示之间,
我们有可能是有上下文信息,这些上下文信息是可能会干扰AI,
然后让AI忘掉,它的目标是去找到下一个要完成的任务。
SYSTEM PROMPT
系统提示
CONTEXTUAL INFORMATION (memory, previous conversations, anything relevant)
上下文信息(记忆,以前的对话,任何相关信息)
TRIGGERING PROMPT
触发提示
The triggering prompt reminds the AI about its short term meta task
(defining the next task)
触发提示提醒了AI,它的短期的元任务是什么鬼。
定义下一个任务。
"""
# 定义了一个名字叫做__init__的初始化函数
# 这个函数有9个参数
# 1、ai_name:这个是agent的名称
# 2、memory: 这个是记忆对象
# 3、full_message_history: 完整的消息历史
# 4、next_action_count: 执行操作的次数
# 5、command_registry: 命令注册?
# 6、config: 配置
# 7、system_prompt: 系统提示
# 8、triggering_prompt: 触发提示
# 9、workspace_directory: 工作空间目录
def __init__(
self,
ai_name,
memory,
full_message_history,
next_action_count,
command_registry,
config,
system_prompt,
triggering_prompt,
workspace_directory,
):
# 通过autogpt.config导入Config,创建了一个名字叫做cfg的配置对象
cfg = Config()
self.ai_name = ai_name
self.memory = memory
# summary_memory这个属性,暂时不明白是什么意思
# 初始化memory避免幻觉?
self.summary_memory = (
"I was created." # Initial memory necessary to avoid hallucination
)
self.last_memory_index = 0
self.full_message_history = full_message_history
self.next_action_count = next_action_count
self.command_registry = command_registry
self.config = config
self.system_prompt = system_prompt
self.triggering_prompt = triggering_prompt
# autogpt.workspace
# cfg.restrict_to_workspace是一个布尔值
# 这是通过读取RESTRICT_TO_WORKSPACE环境变量,表示是否限制在工作空间当中
self.workspace = Workspace(workspace_directory, cfg.restrict_to_workspace)
# 将当前时间格式化为字符串,赋值给created_at属性
self.created_at = datetime.now().strftime("%Y%m%d_%H%M%S")
# 这个属性cycle_count
self.cycle_count = 0
# 这个属性log_cycle_handler
self.log_cycle_handler = LogCycleHandler()
start_interaction_loop方法
def start_interaction_loop(self):
# Interaction Loop
# 交互循环
cfg = Config()
self.cycle_count = 0
command_name = None
arguments = None
user_input = ""
start_interaction_loop,看英文意思应该是开始交互的循环。
- 这里面是创建了一个cfg配置对象。
cycle_count应该是对话次数的计数。command_name字面意思是命令名称。auguments是参数的意思。user_input是用户输入的意思。
1、初始化一些参数
while True:
# Discontinue if continuous limit is reached
# 如果达到了连续对话的极限,那么就停止了
# cycle_count表示对话次数
self.cycle_count += 1
# 将当前cycle对话当中的日志计数器设置为0。
self.log_cycle_handler.log_count_within_cycle = 0
# 将当前cycle对话的历史记录,写入到日志文件当中
self.log_cycle_handler.log_cycle(
self.config.ai_name,
self.created_at,
self.cycle_count,
self.full_message_history,
FULL_MESSAGE_HISTORY_FILE_NAME,
)
2、判断跳出循环的时机
# 对于连续对话模式cfg.continuous_mode
# 如果对话次数cycle_count达到了设定的极限cfg.continuous_limit
# 就输出一条日志信息(logger.typewriter_log)
# 并且跳出循环
if (
cfg.continuous_mode
and cfg.continuous_limit > 0
and self.cycle_count > cfg.continuous_limit
):
logger.typewriter_log(
"Continuous Limit Reached: ", Fore.YELLOW, f"{cfg.continuous_limit}"
)
break
3、核心LLM调用函数
# Send message to AI, get response
# 向AI发送消息,并且获得响应
# AI思考的时候,显示一个旋转的加载按钮
with Spinner("Thinking... "):
assistant_reply = chat_with_ai(
self,
self.system_prompt, # 系统提示
self.triggering_prompt, # 触发提示
self.full_message_history, # 完整消息的历史记录
self.memory, # 记忆
cfg.fast_token_limit, # 快速令牌限制
) # TODO: This hardcodes the model to use GPT3.5. Make this an argument
当前代码将硬编码使用chatgpt 3.5来进行聊天,建议将其作为一个参数传递给chat_with_ai函数,以便于在需要的时候更改模型
chat_with_ai这个函数是最最核心的函数。
4、将LLM response格式化为JSON
# 将机器人的回复格式化为json格式
assistant_reply_json = fix_json_using_multiple_techniques(assistant_reply)
将机器人回复的格式转换成为json格式。
这个是格式化输出。
这个也挺核心的。
5、遍历plugin进行LLM response的后处理
for plugin in cfg.plugins:
if not plugin.can_handle_post_planning():
continue
assistant_reply_json = plugin.post_planning(assistant_reply_json)
这段代码是一个 Python 的 for 循环语句,
它遍历了一个名为 cfg.plugins 的列表中的每一个元素,
并对每个元素执行一些操作。
具体来说,我们可以将这段代码拆解为以下几个部分:
- 1、
for plugin in cfg.plugins::- 这是一个 for 循环语句,
- 它会遍历
cfg.plugins列表中的每一个元素, - 并将当前元素赋值给变量
plugin。
- 2、
if not plugin.can_handle_post_planning()::- 这是一个条件语句,
- 它会判断当前遍历到的
plugin是否具有can_handle_post_planning方法。 - 如果该方法返回 False,
- 那么跳过当前循环,
- 执行下一个循环。
这个can_handle_post_planning到底是个什么方法?在什么位置呢?
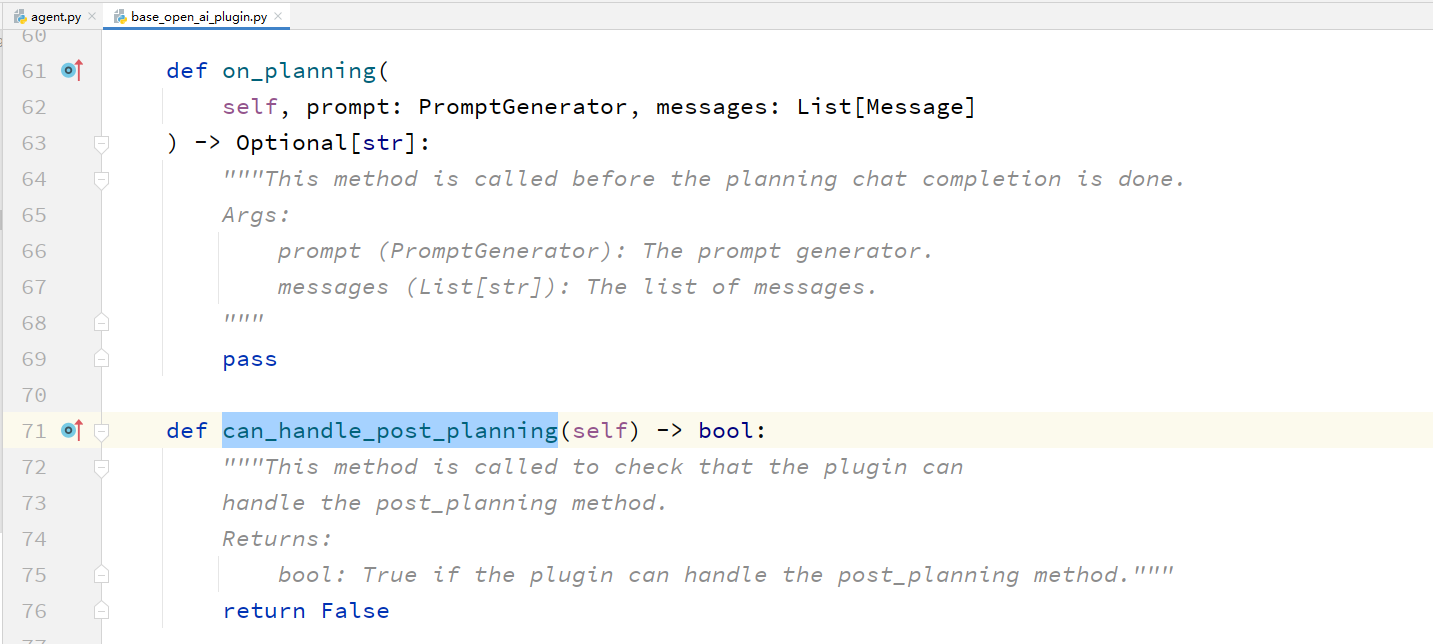
这个方法的意思,就是判断一下,插件是否可以处理post_planning。
那么这个post_planning的理解就很重要了。
post_planning的字面意思是
规划后。大致应该是
后处理的意思。
- 3、
assistant_reply_json = plugin.post_planning(assistant_reply_json):- 这是一个函数调用语句,
- 它会调用当前遍历到的
plugin的post_planning方法, - 并将变量
assistant_reply_json作为参数传递给该方法。 - 该方法的返回值会被赋值给变量
assistant_reply_json。
这里就需要注意了,为什么plugin会有post_planning方法呢?
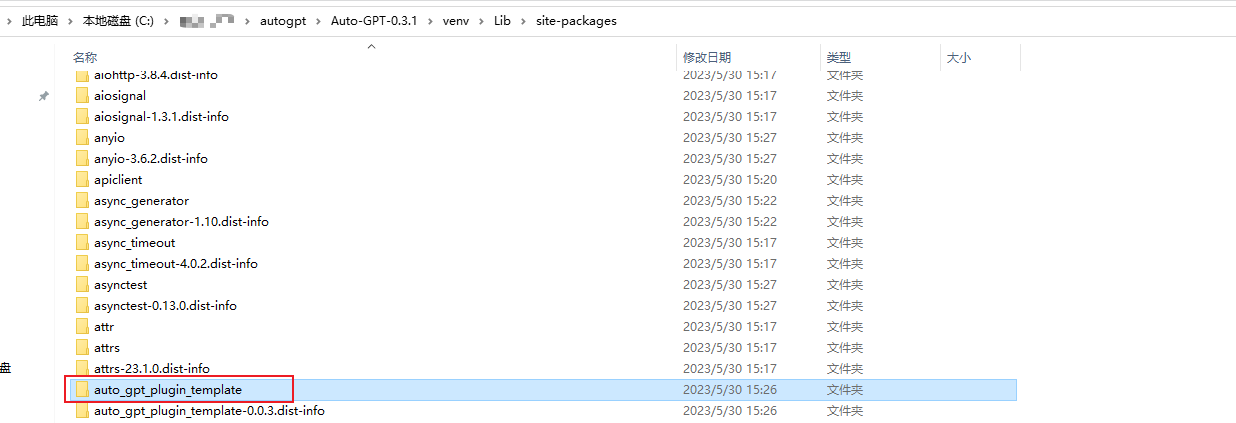
通过查看这个post_planning是一个抽象方法。
这个方法是在包中:
auto_gpt_plugin_template中。这个包就是
插件模板。
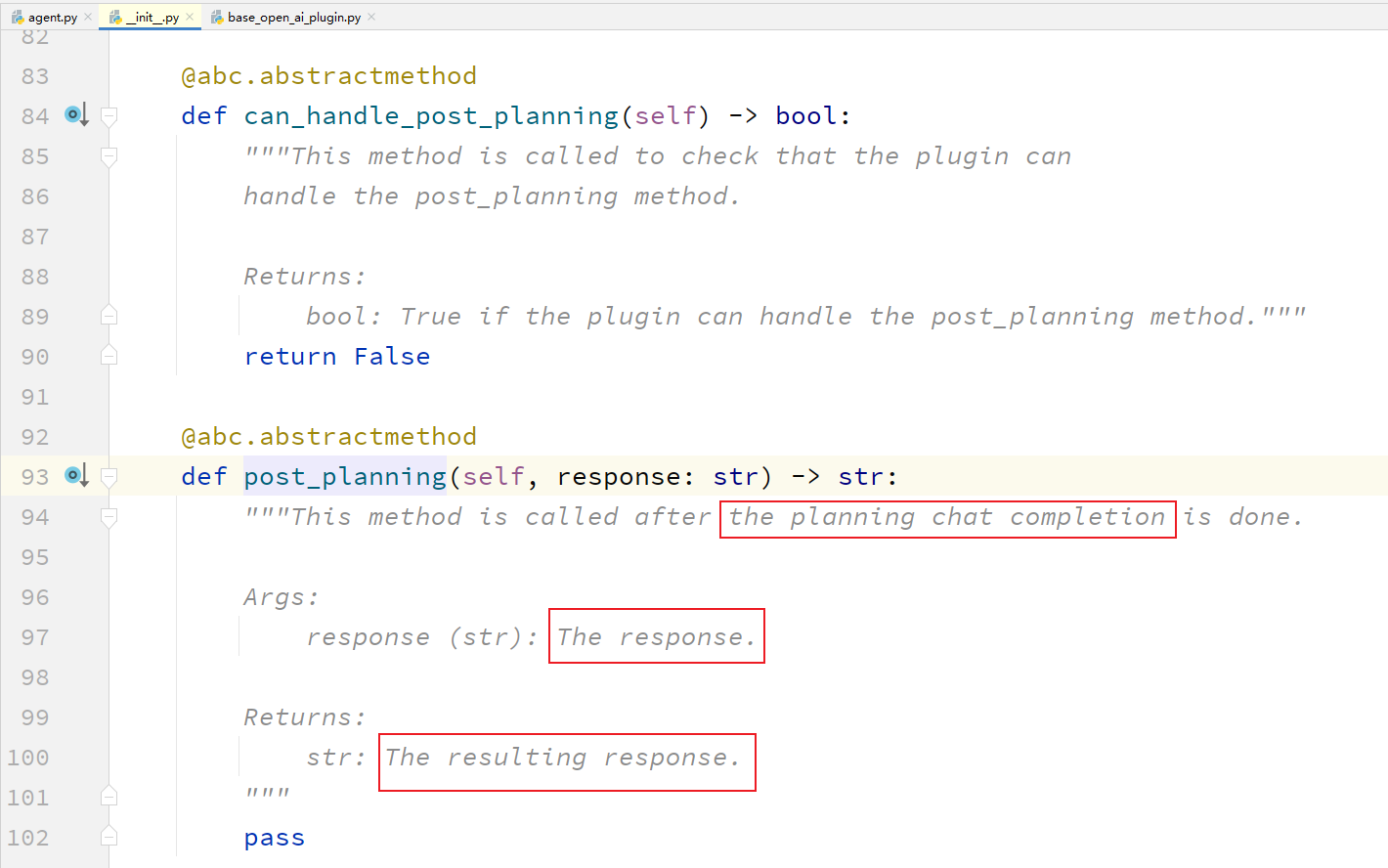
可以看到这个方法什么时候被调用呢?
the planning chat completion:计划中的聊天端点完成。
机器人的response,转变成为了,resulting response。
- 综合来看,
- 这段代码的作用是:
- 遍历
cfg.plugins列表中的每一个元素, - 对于具有
can_handle_post_planning方法的元素, - 调用其
post_planning方法, - 并将变量
assistant_reply_json作为参数传递给该方法。 - 该方法的返回值会更新变量
assistant_reply_json。
- 遍历
6、打印assistant的thoughts
# Print Assistant thoughts
if assistant_reply_json != {}:
validate_json(assistant_reply_json, LLM_DEFAULT_RESPONSE_FORMAT)
# Get command name and arguments
try:
print_assistant_thoughts(
self.ai_name, assistant_reply_json, cfg.speak_mode
)
command_name, arguments = get_command(assistant_reply_json)
if cfg.speak_mode:
say_text(f"I want to execute {command_name}")
arguments = self._resolve_pathlike_command_args(arguments)
except Exception as e:
logger.error("Error: \n", str(e))
这段代码是一个 Python 中的条件语句,
它用于打印 Assistant 的回复内容、并获取其中的命令名称和参数。
具体来说,我们可以将这段代码拆解为以下几个部分:
-
1、
# Print Assistant thoughts:- 这是一个注释,用于描述下面的代码块的作用。
-
2、
if assistant_reply_json != {}::- 这是一个条件语句,
- 它会判断变量
assistant_reply_json是否为空字典。 - 如果不是
空字典, - 那么执行下面的代码块。
-
3、
validate_json(assistant_reply_json, LLM_DEFAULT_RESPONSE_FORMAT):- 这是一个函数调用语句,
- 它会调用名为
validate_json的函数, - 对变量
assistant_reply_json进行格式验证。
要对插件处理过的json进行格式校验。
这个validate_json函数,点进去之后,有个报错。
解决报错
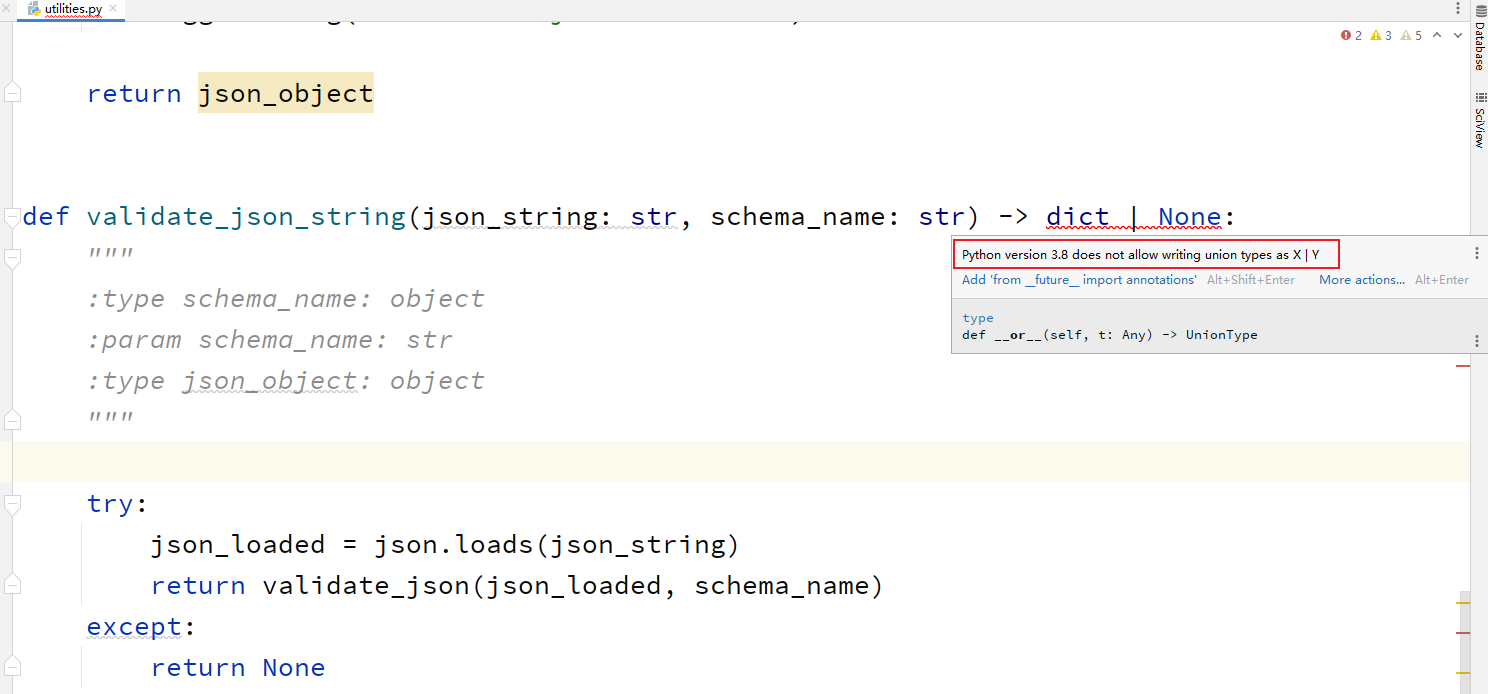
通过上面的注释,可以知道这么一个问题:
在 Python 3.8 及之前的版本中,确实不支持使用
X | Y的方式来表示类型的联合(Union)。在 Python 3.10 中,引入了一项新特性,即使用
X | Y的方式来表示类型的联合。在 Python 3.10 及之后的版本中,可以使用这种方式来表示类型的联合。在 Python 3.8 及之前的版本中,如果需要表示类型的联合,可以使用
typing.Union类型注释。例如,可以使用Union[int, float]来表示一个整数或浮点数类型的联合。
那我就没有必要再用这个python 3.8了。
我直接下载最新的吧。

- pip的默认安装位置,我就不修改了。
- 改一下阿里源。
- 然后就是pycharm当中配置工程的环境。
6、打印assistant的thoughts
# Print Assistant thoughts
if assistant_reply_json != {}:
validate_json(assistant_reply_json, LLM_DEFAULT_RESPONSE_FORMAT)
# Get command name and arguments
try:
print_assistant_thoughts(
self.ai_name, assistant_reply_json, cfg.speak_mode
)
command_name, arguments = get_command(assistant_reply_json)
if cfg.speak_mode:
say_text(f"I want to execute {command_name}")
arguments = self._resolve_pathlike_command_args(arguments)
except Exception as e:
logger.error("Error: \n", str(e))
-
4、
try::- 这是一个try语句,用于尝试执行下面的代码块。
- 如果下面的代码块出现了异常,
- 那么跳转到 except 语句中执行相应的代码块。
-
5、
print_assistant_thoughts(self.ai_name, assistant_reply_json, cfg.speak_mode):- 这是一个函数调用语句,
- 它会调用名为
print_assistant_thoughts的函数, - 用于打印 Assistant 的回复内容。
print_assistant_thoughts:打印assistant的thoughts。
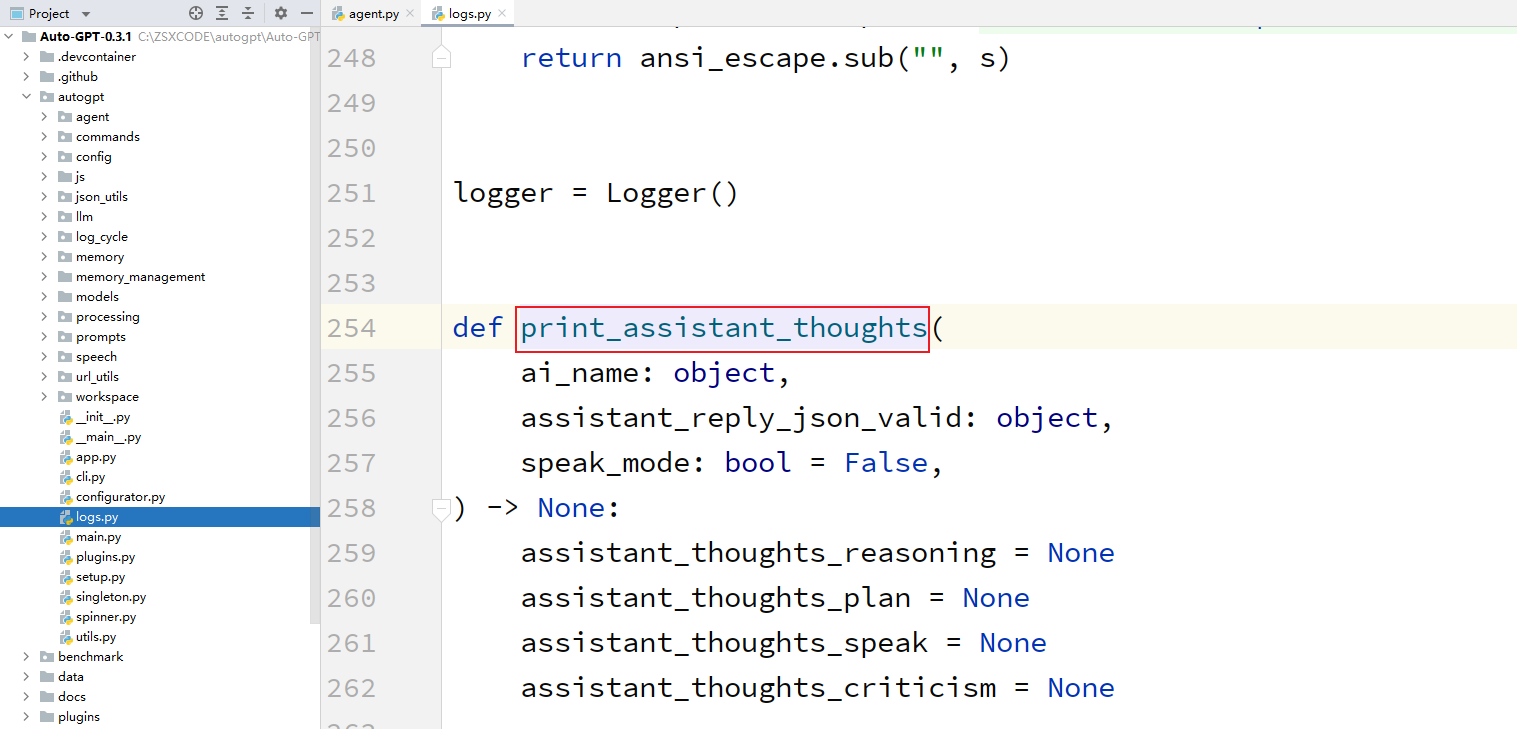
传入的参数有:agent的名字name,有经过插件处理之后的json,还有speak_mode。
这个speak_mode是啥东西。
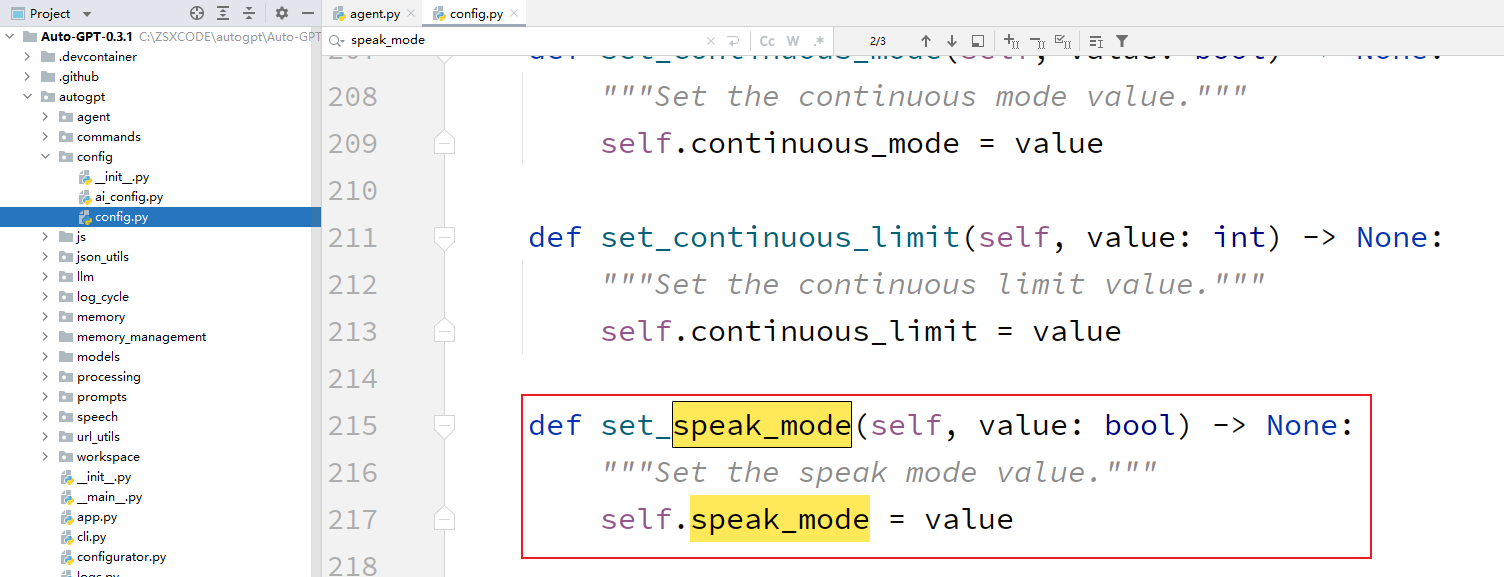
看上面的图,应该可以分析出来,这个speak_mode只是一个布尔值。
- 6、
command_name, arguments = get_command(assistant_reply_json):- 这是一个函数调用语句,
- 它会调用名为
get_command的函数, - 用于从 Assistant 的回复内容中获取命令名称和参数。
- 该函数的返回值会分别赋值给变量
command_name和arguments。
这是一个挺重要的函数:get_command。
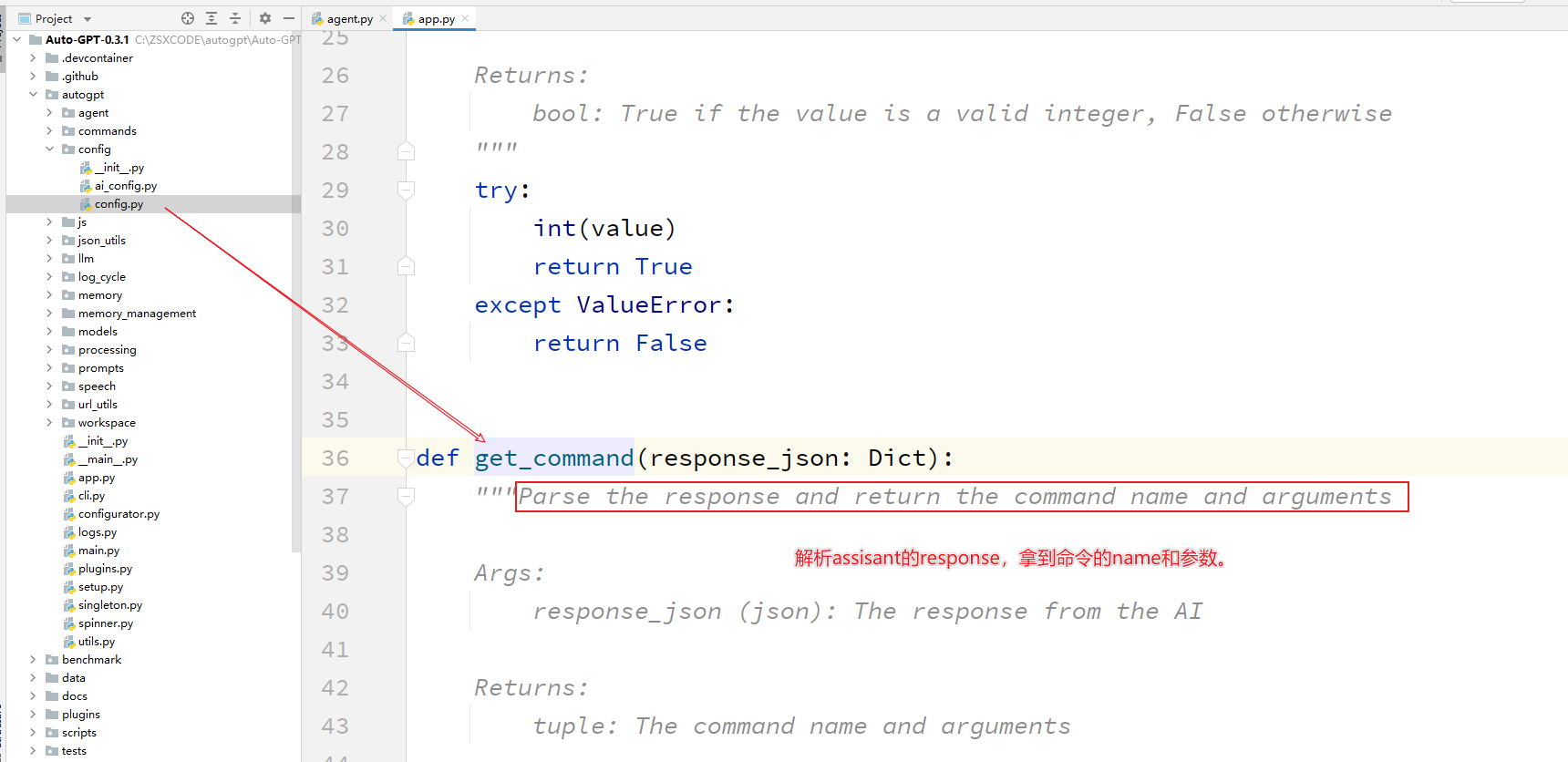
这个函数具体是什么样子呢?
def get_command(response_json: Dict):
"""Parse the response and return the command name and arguments
Args:
response_json (json): The response from the AI
Returns:
tuple: The command name and arguments
Raises:
json.decoder.JSONDecodeError: If the response is not valid JSON
Exception: If any other error occurs
"""
try:
if "command" not in response_json:
return "Error:", "Missing 'command' object in JSON"
if not isinstance(response_json, dict):
return "Error:", f"'response_json' object is not dictionary {response_json}"
command = response_json["command"]
if not isinstance(command, dict):
return "Error:", "'command' object is not a dictionary"
if "name" not in command:
return "Error:", "Missing 'name' field in 'command' object"
command_name = command["name"]
# Use an empty dictionary if 'args' field is not present in 'command' object
arguments = command.get("args", {})
return command_name, arguments
except json.decoder.JSONDecodeError:
return "Error:", "Invalid JSON"
# All other errors, return "Error: + error message"
except Exception as e:
return "Error:", str(e)
- 首先判断 JSON 对象中是否存在
command属性,如果不存在,则返回一个包含错误信息的元组。 - 然后判断
response_json是否为字典类型,如果不是,则返回一个包含错误信息的元组。 - 接着获取
command属性,并判断其是否为字典类型,如果不是,则返回一个包含错误信息的元组。 - 然后获取
name属性的值,作为命令名称。 - 如果
args属性不存在,则将参数设置为空字典。 - 最后返回命令名称和参数。
- 如果解析出错,则返回一个包含错误信息的元组。
这说明了一个问题,response_json当中是肯定包含command属性的。
那么他们是怎么设计prompt,让chatgpt能够吐出来command属性的呢?
这个要好好研究一下。
- 7、
if cfg.speak_mode: say_text(f"I want to execute {command_name}"):- 这是一个条件语句,
- 它会判断变量
cfg.speak_mode是否为 True。 - 如果是 True,
- 那么调用
say_text函数, - 用于将 Assistant 想要执行的命令名称通过语音输出出来。
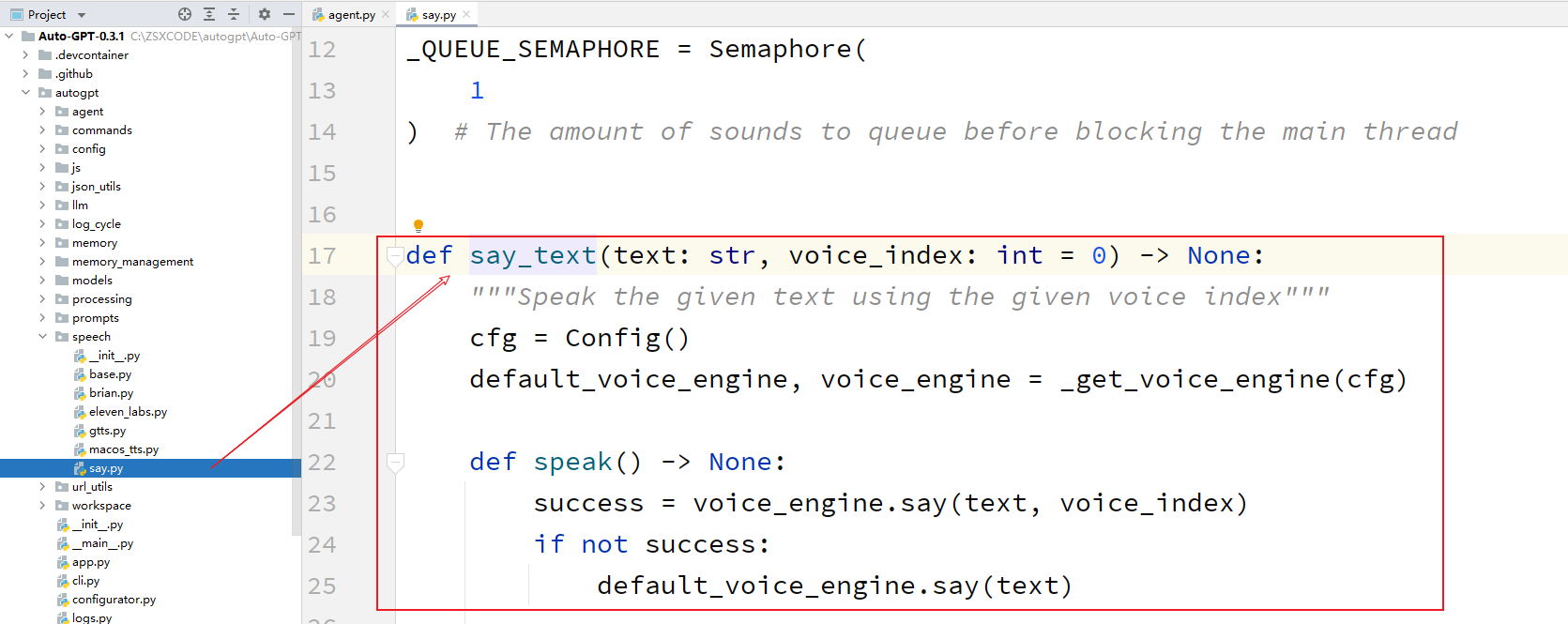
牛逼了,还能够进行语音播报。
这个是要研究一下,到底是怎么连接TTS的。
- 8、
arguments = self._resolve_pathlike_command_args(arguments):- 这是一个函数调用语句,
- 它会调用名为
_resolve_pathlike_command_args的方法, - 用于解析路径参数。
_resolve_pathlike_command_args是在agent这个类当中的方法。这个方法的目的,前面我们从json当中解析出来的command_name和arguments。
将argument当中的路径都转换成为绝对路径。
- 9、
except Exception as e: logger.error("Error: \n", str(e)):- 这是一个 except 语句,用于捕获 try 语句中的异常。
- 如果 try 语句中的代码块出现了异常,那么执行相应的代码块,将异常信息记录在日志文件中。
综合来看,这段代码的作用是:
判断变量
assistant_reply_json是否为空字典,如果不是空字典,则进行格式验证、打印 Assistant 的回复内容、获取命令名称和参数、解析路径参数等操作,并将异常信息记录在日志文件中。如果出现异常,那么记录异常信息。
7、记录对话周期信息和下一步操作的信息
self.log_cycle_handler.log_cycle(
self.config.ai_name,
self.created_at,
self.cycle_count,
assistant_reply_json,
NEXT_ACTION_FILE_NAME,
)
logger.typewriter_log(
"NEXT ACTION: ",
Fore.CYAN,
f"COMMAND = {Fore.CYAN}{command_name}{Style.RESET_ALL} "
f"ARGUMENTS = {Fore.CYAN}{arguments}{Style.RESET_ALL}",
)
这段代码包含两个调用函数的语句,用于记录日志。以下是每一行代码的具体意思:
self.log_cycle_handler.log_cycle(self.config.ai_name, self.created_at, self.cycle_count, assistant_reply_json, NEXT_ACTION_FILE_NAME):- 调用
log_cycle方法记录日志,该方法记录了与 AI 对话的一个周期的信息,- 包括 AI 名称、
- 周期开始时间、
- 周期计数、
- AI 的回复信息
- 以及下一步要执行的操作文件名。
- 调用
self.log_cycle_handler:记录日志的处理程序对象。self.config.ai_name:AI 的名称。self.created_at:周期开始的时间。self.cycle_count:周期计数。assistant_reply_json:AI 的回复信息。NEXT_ACTION_FILE_NAME:下一步要执行的操作文件名。
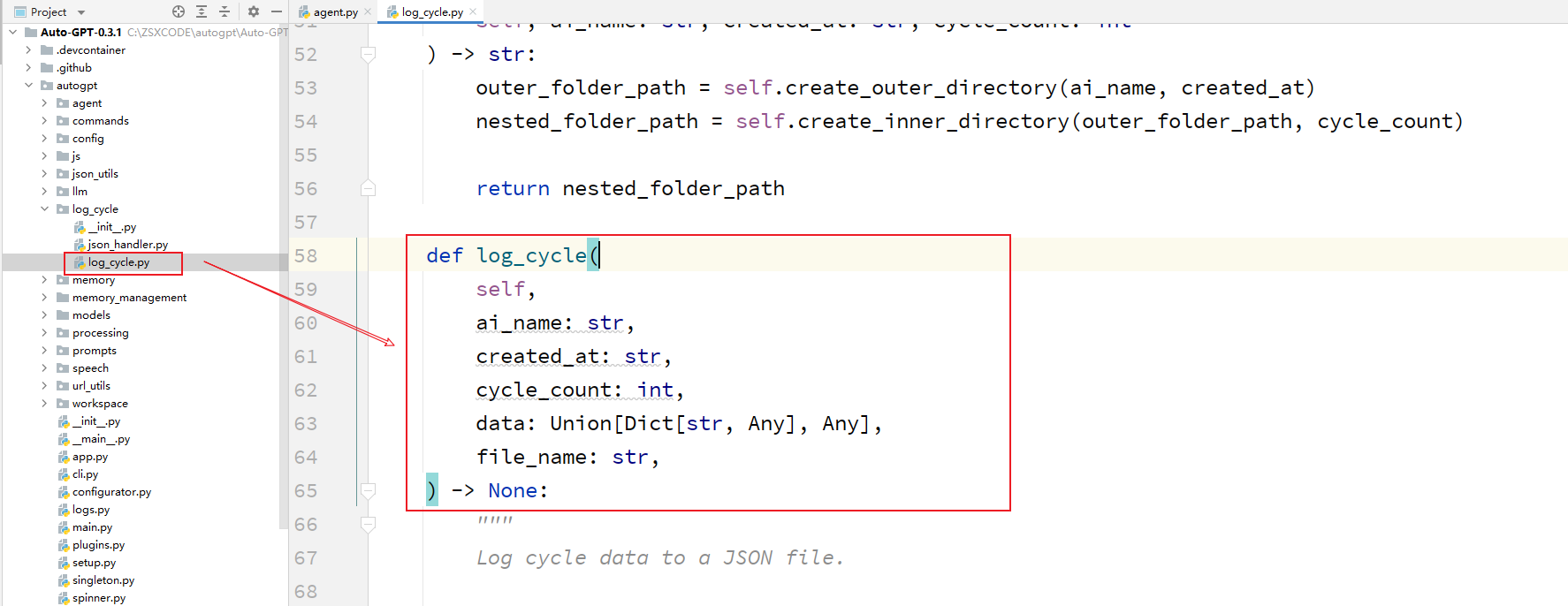
logger.typewriter_log("NEXT ACTION: ", Fore.CYAN, f"COMMAND = {Fore.CYAN}{command_name}{Style.RESET_ALL} "f"ARGUMENTS = {Fore.CYAN}{arguments}{Style.RESET_ALL}"):- 调用
typewriter_log方法记录日志,- 该方法记录了下一步要执行的操作,包括命令名称和参数。
logger:日志记录器对象。logger.typewriter_log:记录日志的方法。"NEXT ACTION: ":日志记录的前缀。Fore.CYAN:颜色代码,表示将后面的文本显示为青色。f"COMMAND = {Fore.CYAN}{command_name}{Style.RESET_ALL} "f"ARGUMENTS = {Fore.CYAN}{arguments}{Style.RESET_ALL}":- 待记录的文本字符串,包括命令名称和参数。
- 其中,
{Fore.CYAN}表示将后面的文本显示为青色,{Style.RESET_ALL}表示恢复默认文本样式。
- 调用
8、用户输入命令的状态判断
这里有两个比较重要的变量:console_input和user_input
if not cfg.continuous_mode and self.next_action_count == 0:
# ### GET USER AUTHORIZATION TO EXECUTE COMMAND ###
# Get key press: Prompt the user to press enter to continue or escape
# to exit
self.user_input = ""
logger.info(
"Enter 'y' to authorise command, 'y -N' to run N continuous commands, 's' to run self-feedback commands, "
"'n' to exit program, or enter feedback for "
f"{self.ai_name}..."
)
while True:
if cfg.chat_messages_enabled:
console_input = clean_input("Waiting for your response...")
else:
console_input = clean_input(
Fore.MAGENTA + "Input:" + Style.RESET_ALL
)
if console_input.lower().strip() == cfg.authorise_key:
user_input = "GENERATE NEXT COMMAND JSON"
break
elif console_input.lower().strip() == "s":
logger.typewriter_log(
"-=-=-=-=-=-=-= THOUGHTS, REASONING, PLAN AND CRITICISM WILL NOW BE VERIFIED BY AGENT -=-=-=-=-=-=-=",
Fore.GREEN,
"",
)
thoughts = assistant_reply_json.get("thoughts", {})
self_feedback_resp = self.get_self_feedback(
thoughts, cfg.fast_llm_model
)
logger.typewriter_log(
f"SELF FEEDBACK: {self_feedback_resp}",
Fore.YELLOW,
"",
)
user_input = self_feedback_resp
command_name = "self_feedback"
break
elif console_input.lower().strip() == "":
logger.warn("Invalid input format.")
continue
elif console_input.lower().startswith(f"{cfg.authorise_key} -"):
try:
self.next_action_count = abs(
int(console_input.split(" ")[1])
)
user_input = "GENERATE NEXT COMMAND JSON"
except ValueError:
logger.warn(
"Invalid input format. Please enter 'y -n' where n is"
" the number of continuous tasks."
)
continue
break
elif console_input.lower() == cfg.exit_key:
user_input = "EXIT"
break
else:
user_input = console_input
command_name = "human_feedback"
self.log_cycle_handler.log_cycle(
self.config.ai_name,
self.created_at,
self.cycle_count,
user_input,
USER_INPUT_FILE_NAME,
)
break
if user_input == "GENERATE NEXT COMMAND JSON":
logger.typewriter_log(
"-=-=-=-=-=-=-= COMMAND AUTHORISED BY USER -=-=-=-=-=-=-=",
Fore.MAGENTA,
"",
)
elif user_input == "EXIT":
logger.info("Exiting...")
break
else:
# Print authorized commands left value
logger.typewriter_log(
f"{Fore.CYAN}AUTHORISED COMMANDS LEFT: {Style.RESET_ALL}{self.next_action_count}"
)
这段代码包含了一个 if 和一个 else 分支语句,用于获取用户的授权来执行命令,并记录用户的输入。
以下是每一行代码的具体意思:
-
if not cfg.continuous_mode and self.next_action_count == 0::- 如果当前不是连续模式,并且没有剩余的授权命令次数,
- 则需要获取用户的授权来执行命令。
-
self.user_input = "":- 清空
self.user_input变量, - 该变量用于记录用户的输入。
- 清空
-
logger.info("Enter 'y' to authorise command, 'y -N' to run N continuous commands, 's' to run self-feedback commands, " 'n' to exit program, or enter feedback for " f"{self.ai_name}..."):- 记录提示信息,提示用户输入
- 1、授权命令
- 2、连续命令次数
- 3、自我反馈命令
- 4、退出程序或输入反馈信息等选项。
- 记录提示信息,提示用户输入
-
while True::- 进入一个死循环,
- 直到用户输入
有效的授权命令或者其他选项。
-
其中
cfg.chat_messages_enabled是一个配置变量,用于控制是否将输入提示信息显示在聊天界面上。- 如果该变量为
True,则调用clean_input函数显示 "Waiting for your response..." 的提示信息,并等待用户的输入。clean_input函数用于获取用户的输入,会清空输入字符串中的空格和换行符。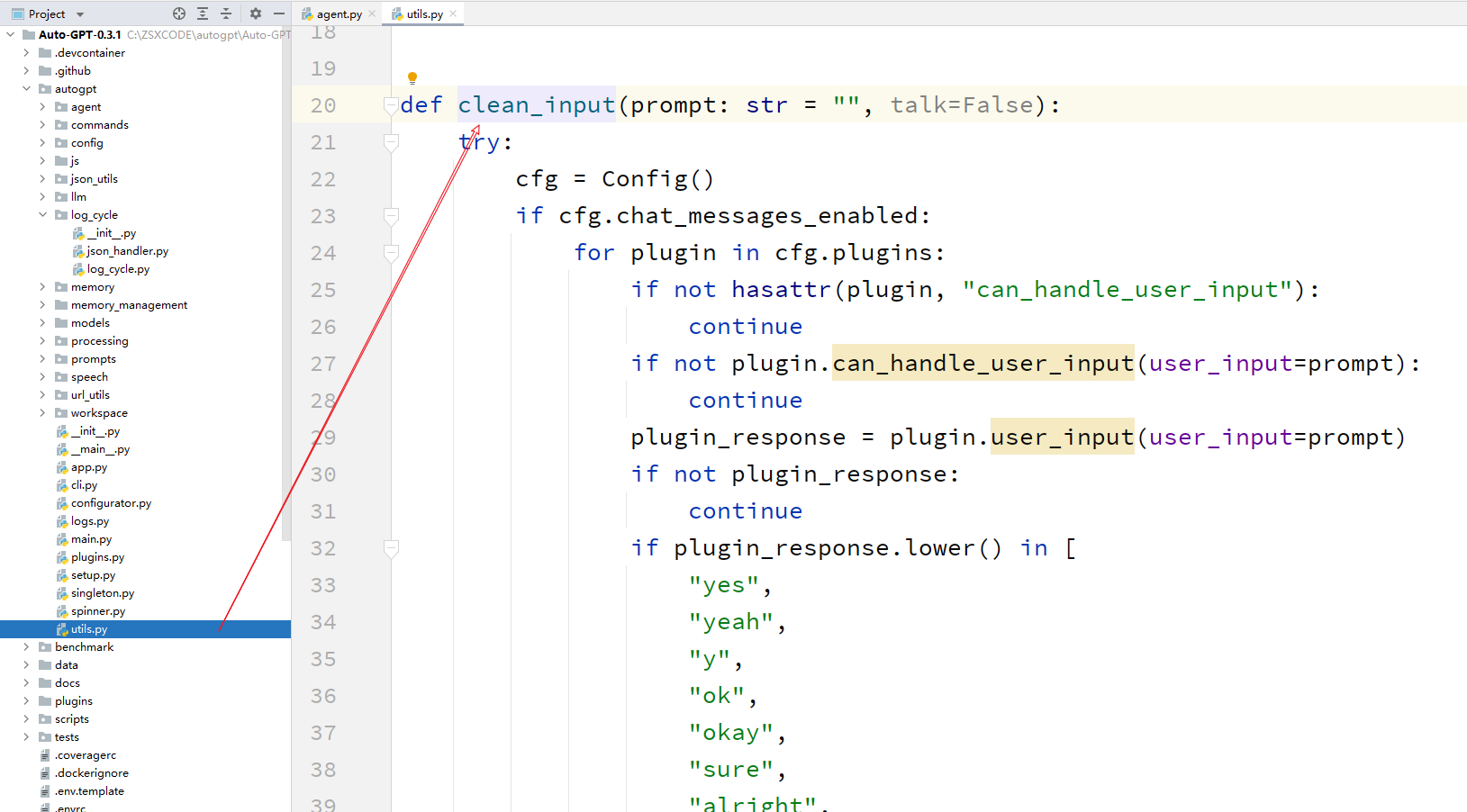
- 如果该变量为
False,则将输入提示信息以紫色文本的形式显示在控制台上,而不是在聊天界面上。- 具体来说,使用了 Python 包
colorama中的Fore和Style类来显示颜色和样式。- 其中
Fore.MAGENTA表示将后面的文本显示为紫色, Style.RESET_ALL表示恢复默认文本样式。
- 其中
- 调用
clean_input函数等待用户输入后,将用户的输入赋值给变量console_input。
- 具体来说,使用了 Python 包
- 如果该变量为
-
if console_input.lower().strip() == cfg.authorise_key::- 如果用户输入的命令是
授权命令, - 则将
user_input变量设置为字符串"GENERATE NEXT COMMAND JSON", - 表示
需要生成下一步的命令 JSON。
- 如果用户输入的命令是
-
elif console_input.lower().strip() == "s"::- 如果用户输入的命令是
自我反馈命令, - 则调用
get_self_feedback方法获取自我反馈结果, - 并将
user_input变量设置为自我反馈结果。
- 如果用户输入的命令是
-
elif console_input.lower().strip() == ""::- 如果用户输入为空,则记录警告信息,提示用户输入格式无效。
-
elif console_input.lower().startswith(f"{cfg.authorise_key} -")::- 如果用户输入的是连续授权命令,
- 则解析出连续命令次数,
- 并将
user_input变量设置为字符串"GENERATE NEXT COMMAND JSON", - 表示需要生成下一步的命令 JSON。
-
elif console_input.lower() == cfg.exit_key::- 如果用户输入的是退出程序命令,
- 则将
user_input变量设置为字符串"EXIT", - 表示需要退出程序。
-
else::- 如果用户输入的是反馈信息,
- 则将
user_input变量设置为用户输入的字符串, - 并将
command_name变量设置为字符串"human_feedback", - 表示是用户的反馈信息。
-
self.log_cycle_handler.log_cycle(self.config.ai_name, self.created_at, self.cycle_count, user_input, USER_INPUT_FILE_NAME):- 记录用户的输入到日志文件中。
-
logger.typewriter_log(f"{Fore.CYAN}AUTHORISED COMMANDS LEFT: {Style.RESET_ALL}{self.next_action_count}"):- 如果当前是连续模式或者还有剩余的授权命令次数,
- 则记录剩余的授权命令次数到日志文件中。
9、命令执行 - execute command
# Execute command
if command_name is not None and command_name.lower().startswith("error"):
result = (
f"Command {command_name} threw the following error: {arguments}"
)
elif command_name == "human_feedback":
result = f"Human feedback: {user_input}"
elif command_name == "self_feedback":
result = f"Self feedback: {user_input}"
else:
for plugin in cfg.plugins:
if not plugin.can_handle_pre_command():
continue
command_name, arguments = plugin.pre_command(
command_name, arguments
)
command_result = execute_command(
self.command_registry,
command_name,
arguments,
self.config.prompt_generator,
)
result = f"Command {command_name} returned: " f"{command_result}"
result_tlength = count_string_tokens(
str(command_result), cfg.fast_llm_model
)
memory_tlength = count_string_tokens(
str(self.summary_memory), cfg.fast_llm_model
)
if result_tlength + memory_tlength + 600 > cfg.fast_token_limit:
result = f"Failure: command {command_name} returned too much output. \
Do not execute this command again with the same arguments."
for plugin in cfg.plugins:
if not plugin.can_handle_post_command():
continue
result = plugin.post_command(command_name, result)
if self.next_action_count > 0:
self.next_action_count -= 1
这段代码包含了一个 if 分支语句,用于根据不同的命令类型执行不同的操作,并记录执行结果。
以下是每一行代码的具体意思:
if command_name is not None and command_name.lower().startswith("error")::- 如果命令名称不为空,并且以 "error" 开头,
- 则
将执行结果设置为一个字符串,包含了命令名称和错误信息。
elif command_name == "human_feedback"::- 如果命令名称是 "human_feedback",
- 则将执行结果设置为一个字符串,
- 包含了 "Human feedback" 和用户输入的字符串。
elif command_name == "self_feedback"::- 如果命令名称是 "self_feedback",
- 则将执行结果设置为一个字符串,
- 包含了 "Self feedback" 和自我反馈得到的结果。
else::- 如果命令名称不是上述两种情况,说明是其他类型的命令,
- 则依次遍历配置变量
cfg.plugins中的插件, - 检查每个插件是否能够处理该命令。
- 如果插件不能够处理该命令,则跳过该插件,继续遍历下一个插件。
- 如果插件能够处理该命令,则调用插件中的
pre_command方法进行处理, - 并将处理后的命令名称和参数赋值给
command_name和arguments变量。 - 接着调用
execute_command函数执行命令, - 将执行结果赋值给
command_result变量。 - 最后将执行结果设置为一个字符串,
- 包含了命令名称和执行结果。
result_tlength = count_string_tokens(str(command_result), cfg.fast_llm_model):- 计算命令执行结果中的字符串单词数,
- 将结果赋值给
result_tlength变量。
memory_tlength = count_string_tokens(str(self.summary_memory), cfg.fast_llm_model):- 计算自我反馈的结果中的字符串单词数,
- 将结果赋值给
memory_tlength变量。
if result_tlength + memory_tlength + 600 > cfg.fast_token_limit::- 如果命令执行结果和自我反馈的结果的单词数之和加上一个常量
600大于配置变量cfg.fast_token_limit, - 则将执行结果设置为一个字符串,
- 包含了命令名称和错误信息,
- 提示用户不要再次执行该命令。
- 如果命令执行结果和自我反馈的结果的单词数之和加上一个常量
for plugin in cfg.plugins::- 依次遍历配置变量
cfg.plugins中的插件, - 检查每个插件是否能够处理命令执行结果。
- 如果插件不能够处理命令执行结果,则跳过该插件,继续遍历下一个插件。
- 如果插件能够处理命令执行结果,则调用插件中的
post_command方法进行处理,并将处理后的结果赋值给result变量。
- 依次遍历配置变量
if self.next_action_count > 0::- 如果当前是连续模式,
- 并且还有剩余的授权命令次数,
- 则将剩余的授权命令次数减 1。
if result is not None::- 如果命令执行后的结果不为空,则执行下面的代码块。
self.full_message_history.append(create_chat_message("system", result)):- 将命令执行后的结果添加到聊天记录中。
- 具体来说,调用了
create_chat_message函数- 创建了一个包含 "system" 和命令执行结果的聊天消息对象,
- 并将该对象添加到
self.full_message_history列表中。
logger.typewriter_log("SYSTEM: ", Fore.YELLOW, result):- 将命令执行后的结果记录到日志文件中。
- 具体来说,调用了
logger模块中的typewriter_log函数, - 将日志记录的前缀设置为 "SYSTEM: ",日志记录的前景色设置为黄色,
- 将命令执行后的结果作为日志记录的内容。
else::如果命令执行后的结果为空,则执行下面的代码块。self.full_message_history.append(create_chat_message("system", "Unable to execute command")):- 将一条包含 "system" 和 "Unable to execute command" 的聊天消息添加到聊天记录中。
logger.typewriter_log("SYSTEM: ", Fore.YELLOW, "Unable to execute command"):- 将 "Unable to execute command" 记录到日志文件中。具体来说,
- 调用了
logger模块中的typewriter_log函数, - 将日志记录的前缀设置为 "SYSTEM: ",日志记录的前景色设置为黄色,
- 将 "Unable to execute command" 作为日志记录的内容。
_resolve_pathlike_command_args方法
代码
def _resolve_pathlike_command_args(self, command_args):
if "directory" in command_args and command_args["directory"] in {"", "/"}:
command_args["directory"] = str(self.workspace.root)
else:
for pathlike in ["filename", "directory", "clone_path"]:
if pathlike in command_args:
command_args[pathlike] = str(
self.workspace.get_path(command_args[pathlike])
)
return command_args
这段代码实现了一个名为 _resolve_pathlike_command_args 的方法,用于解析命令参数中的路径参数。
该方法接受一个名为 command_args 的参数,应该是一个包含命令参数的字典对象。
方法的作用是将命令参数中的路径参数转换为绝对路径。
具体来说,该方法的实现如下:
- 方法签名:
def _resolve_pathlike_command_args(self, command_args) - 方法参数:
command_args:待解析的命令参数,类型为dict。
- 方法返回值:一个字典对象,包含解析后的命令参数。
- 方法实现:
- 首先判断
命令参数中是否包含directory属性,并且其值为""或/。- 如果是,则将其替换为
工作区根目录的绝对路径。
- 如果是,则将其替换为
- 否则,对于命令参数中的每个路径属性(
"filename","directory","clone_path"),- 将其值转换为绝对路径,
- 并
更新、命令参数中对应的属性。
- 最后返回更新后的命令参数字典。
- 首先判断
get_self_feedback方法
def get_self_feedback(self, thoughts: dict, llm_model: str) -> str:
"""Generates a feedback response based on the provided thoughts dictionary.
This method takes in a dictionary of thoughts containing keys such as 'reasoning',
'plan', 'thoughts', and 'criticism'. It combines these elements into a single
feedback message and uses the create_chat_completion() function to generate a
response based on the input message.
Args:
thoughts (dict): A dictionary containing thought elements like reasoning,
plan, thoughts, and criticism.
Returns:
str: A feedback response generated using the provided thoughts dictionary.
"""
ai_role = self.config.ai_role
feedback_prompt = f"Below is a message from me, an AI Agent, assuming the role of {ai_role}. whilst keeping knowledge of my slight limitations as an AI Agent Please evaluate my thought process, reasoning, and plan, and provide a concise paragraph outlining potential improvements. Consider adding or removing ideas that do not align with my role and explaining why, prioritizing thoughts based on their significance, or simply refining my overall thought process."
reasoning = thoughts.get("reasoning", "")
plan = thoughts.get("plan", "")
thought = thoughts.get("thoughts", "")
feedback_thoughts = thought + reasoning + plan
return create_chat_completion(
[{"role": "user", "content": feedback_prompt + feedback_thoughts}],
llm_model,
)
这段代码定义了一个名为 get_self_feedback 的方法,用于生成一个反馈响应,基于提供的思考字典。
以下是每一行代码的具体意思:
def get_self_feedback(self, thoughts: dict, llm_model: str) -> str::- 定义了一个名为
get_self_feedback的方法, - 该方法需要三个参数:
self,thoughts,和llm_model。 - 其中,
self表示当前对象,thoughts是一个包含思考元素的字典,llm_model是一个字符串, - 表示要使用的语言模型。
- 定义了一个名为
"""Generates a feedback response based on the provided thoughts dictionary.:- 该行代码是一个文档字符串,用于描述该方法的功能。
ai_role = self.config.ai_role:- 获取配置变量
self.config.ai_role的值, - 并将其赋值给变量
ai_role。 - 该变量表示 AI 代理的角色。
- 获取配置变量
feedback_prompt = f"Below is a message from me, an AI Agent, assuming the role of {ai_role}. whilst keeping knowledge of my slight limitations as an AI Agent Please evaluate my thought process, reasoning, and plan, and provide a concise paragraph outlining potential improvements. Consider adding or removing ideas that do not align with my role and explaining why, prioritizing thoughts based on their significance, or simply refining my overall thought process.":- 设置一个反馈提示变量
feedback_prompt, - 用于提示提示用户评估 AI 代理的思考过程和计划,
- 并提供改进意见。
- 设置一个反馈提示变量
reasoning = thoughts.get("reasoning", ""):- 从思考字典
thoughts中获取键为 "reasoning" 的值, - 并将其赋值给变量
reasoning。 - 如果该键不存在,则将
reasoning的值设置为空字符串。
- 从思考字典
plan = thoughts.get("plan", ""):- 从思考字典
thoughts中获取键为 "plan" 的值, - 并将其赋值给变量
plan。 - 如果该键不存在,则将
plan的值设置为空字符串。
- 从思考字典
thought = thoughts.get("thoughts", ""):- 从思考字典
thoughts中获取键为 "thoughts" 的值, - 并将其赋值给变量
thought。 - 如果该键不存在,则将
thought的值设置为空字符串。
- 从思考字典
feedback_thoughts = thought + reasoning + plan:- 将
thought、reasoning和plan三个字符串拼接起来, - 并将结果赋值给变量
feedback_thoughts。
- 将
return create_chat_completion([{"role": "user", "content": feedback_prompt + feedback_thoughts}], llm_model):- 调用
create_chat_completion函数生成一个反馈响应,并将该响应作为方法的返回值。 - 具体来说,将反馈提示
feedback_prompt和思考内容feedback_thoughts组合成一个包含 "user" 角色和内容的字典, - 并作为参数传递给
create_chat_completion函数, - 同时将语言模型
llm_model作为另一个参数传递给函数。 - 函数将使用语言模型生成一个响应,并将其作为字符串返回。
- 调用