产品官网:https://www.huaweicloud.com/product/hecs-light.html

今天我们采用可靠更安全、智能不卡顿、价优随心用、上手更简单、管理特省心的华为云耀云服务器L实例为例,演示单台服务器配置伪分布式模式hadoop集群的基础:完成 JDK 环境的部署
Hadoop 是一个开源的分布式存储和计算框架,旨在处理大规模数据集。它是 Apache 软件基金会的一个顶级项目,为用户提供了一种可靠、可扩展且高效处理大数据的方式。
1. Hadoop Distributed File System(HDFS): HDFS 是 Hadoop 的分布式文件系统,设计用于存储大规模数据集。它将数据划分为块(block)并分布存储在多台机器上,提供了高容错性和可靠性。
2. MapReduce: MapReduce 是 Hadoop 的计算模型,用于并行处理大规模数据集。它将计算任务分解为 Map 和 Reduce 阶段,通过在分布式环境中执行这些任务来实现数据处理。
3. YARN(Yet Another Resource Negotiator): YARN 是 Hadoop 的资源管理器,负责集群资源的管理和调度。它允许多个应用程序共享同一集群,从而更有效地利用集群资源。
4. Hadoop生态系统: Hadoop 生态系统包含许多其他工具和框架,如 Hive、Pig、HBase、Spark 等,用于支持不同类型的数据处理和分析需求。
5. 扩展性: Hadoop 具有良好的可扩展性,可以轻松地在集群中添加新的节点以处理不断增长的数据量。它支持在普通硬件上搭建集群,使得大规模数据处理变得更加经济高效。
6. 开源和社区支持: Hadoop 是开源软件,由全球的开发者社区维护和支持。它拥有庞大的用户社群和活跃的开发者社区,不断推动框架的发展和改进。
Hadoop 被广泛应用于处理大规模数据,包括数据存储、数据分析、机器学习等各种场景。它的设计理念使得它适用于在常规硬件上搭建的大规模集群,并为用户提供了一种可靠、高效、可扩展的大数据处理解决方案。
JDK : Java Development Kit ,是用于 Java 语言开发的环境。大数据的很多软件的运行都需要有 Java 运行环境的支持,所以我们需要预先部署好 JDK 环境。
### 步骤1 :下载 JDK 软件: https://www.oracle.com/java/technologies/downloads
下载 jdk-8u361-linux-x64.tar.gz


将下载好的文件用finalshell上传至云服务器

### 步骤2 :配置 JDK 环境
1. 创建文件夹,用来部署 JDK ,将 JDK 和 Tomcat 都安装部署到: /export/server 内
```bash
mkdir -p /export/
```

2. 解压缩 JDK 安装文件
```bash
tar -zxvf jdk-8u361-linux-x64.tar.gz -C /export/server
```

3. 配置 JDK 的软链接
```bash
ln -s /export/server/jdk1.8.0_351 /export/server/jdk
```

4. 配置 JAVA_HOME 环境变量,以及将 $JAVA_HOME/bin 文件夹加入 PATH 环境变量中
```bash
vim ~/.bashrc
```
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin

5. 生效环境变量
```bash
source /etc/profile
```

6. 配置 java 执行程序的软链接
```bash
rm -f /usr/bin/java
ln -s /export/server/jdk/bin/java /usr/bin/java/
```

7. 执行验证
```bash
java -version
javac -version
```
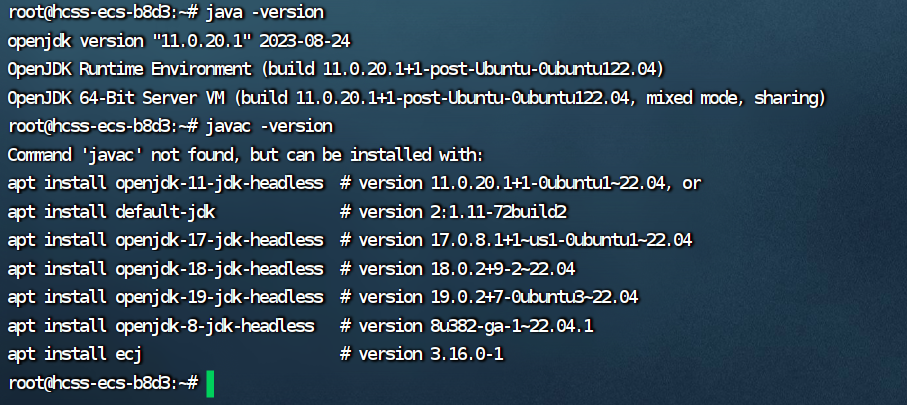
至此,我们成功完成了JAVA环境配置的准备