2023数据采集与融合技术实践作业3
gitee仓库链接:https://gitee.com/zhoujingyang0509/crawl_project/tree/master/作业3
作业1
要求:
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。
使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位 08页)、总下载的图片数量(尾数后3位108张)等限制爬取的措施。
输出信息:
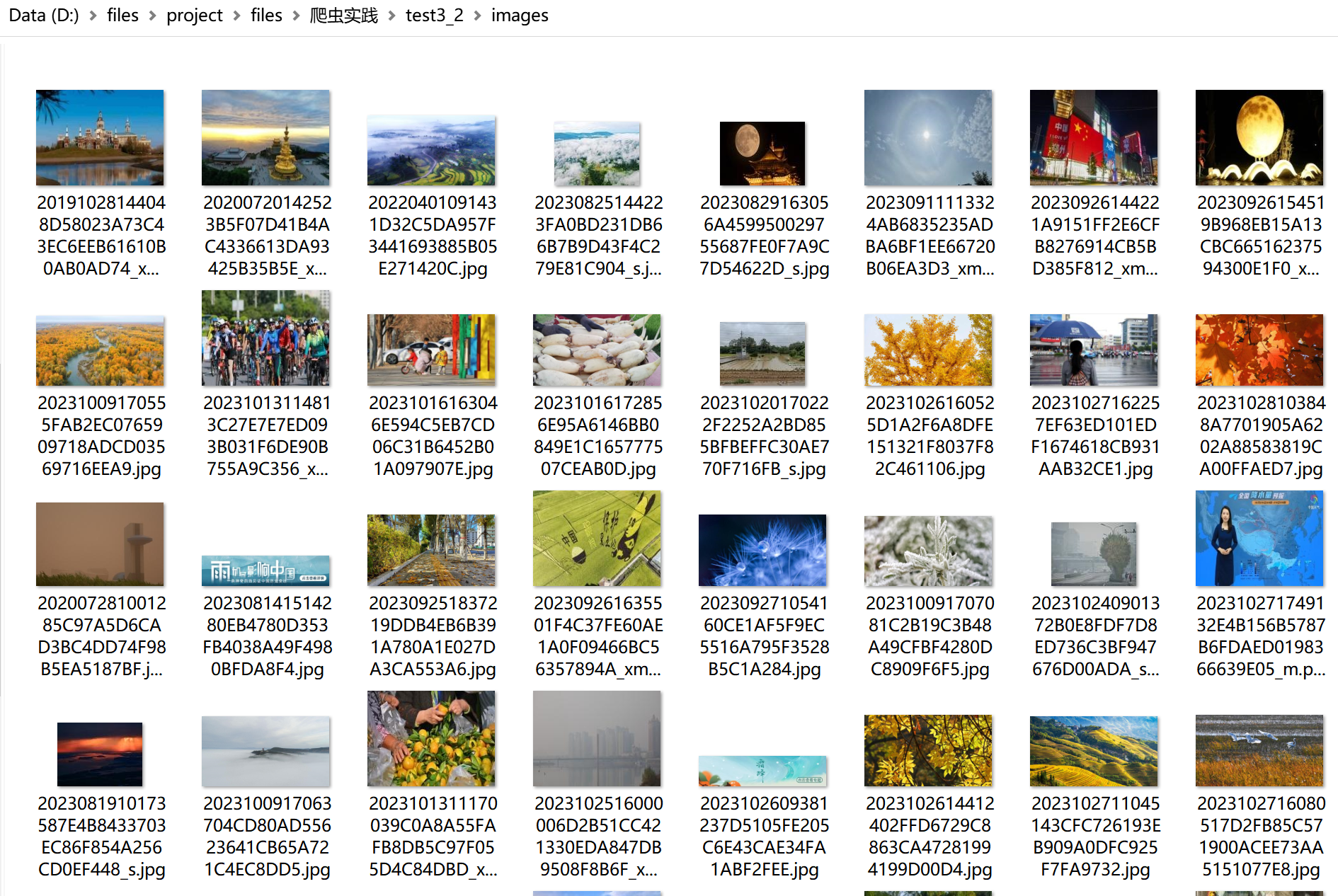
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
test.py
解析数据
class WeatherSpider(scrapy.Spider):
name = 'test'
# allowed_domains = ['www.xxx.com.cn']
start_urls = ['http://www.weather.com.cn/']
page = 0
pic_num = 0
#解析图片链接
def parsePic(self, response):
#获取图片链接列表
images = response.xpath("//img")
for image in images:
self.pic_num+=1
img = image.xpath('@src').extract_first()
#爬取108张图片
if self.pic_num<=108:
item = ImgItem()
item["src"] = img
item["pic_num"]=self.pic_num
print("第",self.pic_num,"张:",img)
yield item
#解析页面url
def parse(self, response):
urls = response.xpath("//a/@href").extract()
for url in urls:
self.page += 1
#爬取8页
if self.page <= 8:
time.sleep(2)
yield scrapy.Request(url=url, callback=self.parsePic)
items.py
定义数据对象
class Test32Item(scrapy.Item):
# define the fields for your item here like:
src = scrapy.Field()
pipelines.py
存储数据
from scrapy.pipelines.images import ImagesPipeline
class imgsPileLine(ImagesPipeline):
# count=1
#根据图片地址进行数据请求
def get_media_requests(self, item, info):
yield scrapy.Request(item['src'])
#指定图片存储路径
def file_path(self, request, response=None, info=None, *, item=None):
# imgName=str(self.count)+".jpg"
# self.count+=1
url=request.url
imgName=url.split('/')[-1]
return imgName
#返回给下一个即将被执行的管道类
def item_completed(self, results, item, info):
return item
settings.py
单线程设置
USER_AGENT ='...'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'test3_2.pipelines.imgsPileLine': 300,
#换成自定义的管道类
}
#图片存储目录
IMAGES_STORE='./images'
多线程设置:在settings.py中开启多线程,可自动设置线程数

终端输出图片url
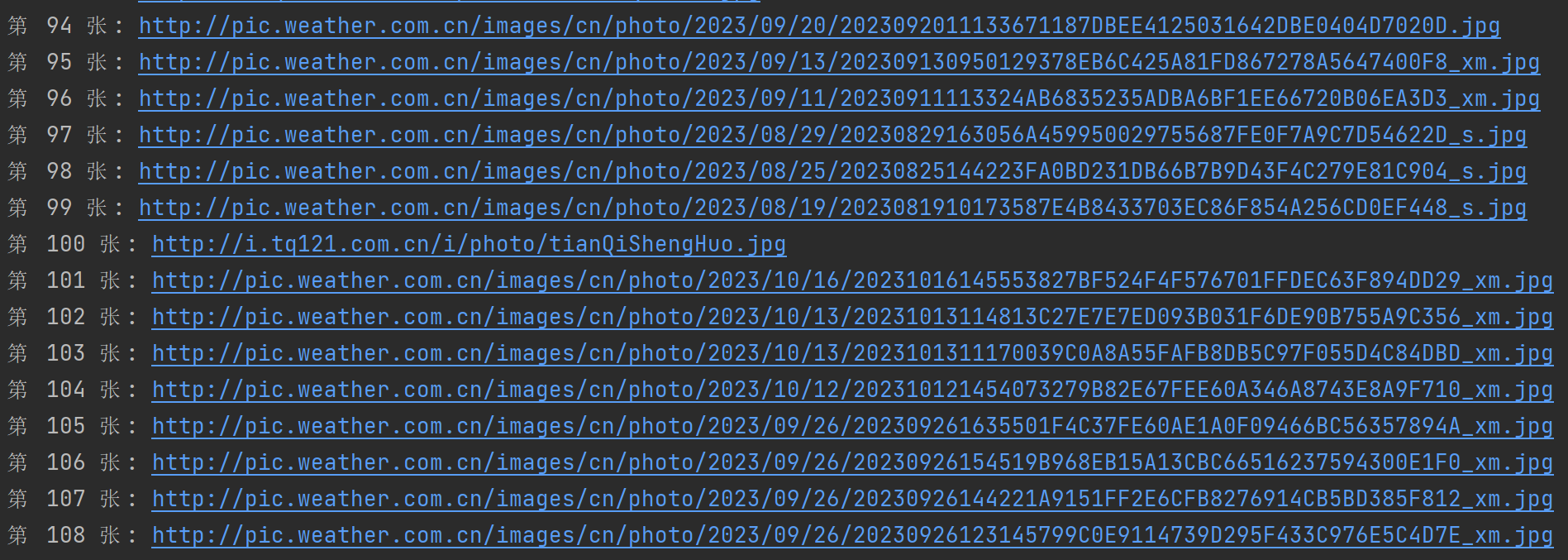
查看图片
心得
1、多线程可以不使用threading,只需要设置CONCURRENT_REQUESTS值就行,而且scrapy框架是异步的,所以在下载图片时并不是按顺序下载的。
2、一开始有点疑惑,没有像之前商城或其它网页明显的翻页,如何实现爬取特定页数,再想想就可以知道爬取全部链接,限定爬取链接的数量即可
3、存取图片需要自定义一个类继承ImagesPipeline,在自定义类中实现根据图片地址进行图片数据请求并存储图片,和文本数据类型存储不一样
作业2
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
网站:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:
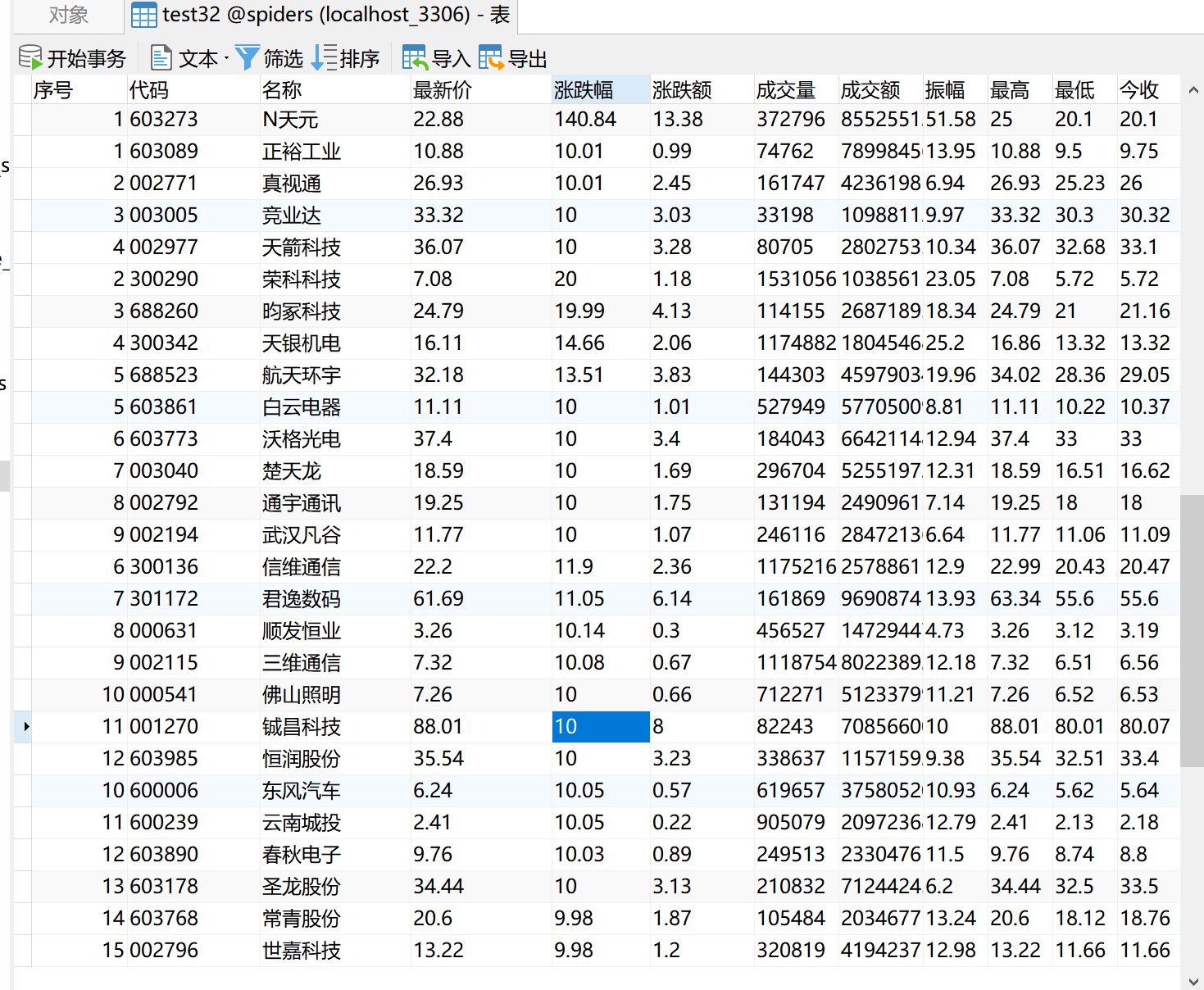
MySQL数据库存储和输出格式如下:表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 振幅 最高 最低 今开 昨收
1 688093 N世华 28.47 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.20 17.55
2……
test.py
主要代码:
#解析数据并将数据传入管道
def parse(self, response):
data = response.text
json_data = json.loads(data[data.find('{'):data.rfind('}') + 1])
stock_list = json_data['data']['diff']
count=0
for stock in stock_list:
item = Test32Item()
count+=1
item['id']=count
item['code'] = stock['f12']
item['name'] = stock['f14']
item['latest_price'] = stock['f2']
item['change_degree'] = stock['f3']
item['change_amount'] = stock['f4']
item['count'] = stock['f5']
item['money'] = stock['f6']
item['zfcount'] = stock['f7']
item['highest'] = stock['f15']
item['lowest'] = stock['f16']
item['today'] = stock['f17']
item['yestoday'] = stock['f18']
yield item
实现翻页操作
#爬取3页数据
if self.page_num <= 3:
self.page_num += 1
url = f'https://69.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112404359196896638151_1697701391202&pn={self.page+1}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1697701391203'
yield scrapy.Request(url=url, callback=self.parse)
items.py
class Test32Item(scrapy.Item):
id = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
latest_price = scrapy.Field()
change_degree = scrapy.Field()
change_amount=scrapy.Field()
count = scrapy.Field()
money = scrapy.Field()
zfcount = scrapy.Field()
highest = scrapy.Field()
lowest = scrapy.Field()
today = scrapy.Field()
yestoday = scrapy.Field()
pipelines.py
import pymysql
#将数据存取到mysql中
class mysqlPipeline:
conn=None
cursor=None
#连接数据库
def open_spider(self,spider):
self.conn=pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='123456',db='spiders',charset='utf8')
#插入数据
def process_item(self, item, spider):
self.cursor=self.conn.cursor()
sql = "INSERT INTO test32(序号,代码,名称,最新价,涨跌幅,涨跌额,成交量,成交额,振幅,最高,最低,今收,昨收)" \
" VALUES (%s,%s, %s, %s,%s, %s, %s, %s, %s, %s, %s, %s, %s)"
try:
self.cursor.execute(sql, [item["id"],item["code"],item["name"],item["latest_price"],item["change_degree"],item["change_amount"],item["count"],item["money"],item["zfcount"],item["highest"],item["lowest"],item["today"],item["yestoday"]])
self.conn.commit()
print("插入成功")
except Exception as err:
print("插入失败", err)
return item
#关闭数据库
def close_spider(self,spider):
if self.cursor:
self.cursor.close()
if self.conn:
self.conn.close()
settings.py
USER_AGENT ='...'
ROBOTSTXT_OBEY = False
#开启管道
ITEM_PIPELINES = {
'test32.pipelines.mysqlPipeline': 300,
}
终端查看是否插入数据成功
查看数据库
心得
1、这个是动态网页,在抓包时查看预览信息没看到数据,找了很久很久,然后我在抓包页面按ctrl+f搜索页面数据,找到对应数据的包,发现数据在预览信息中是很长一行,数据在很后面,而之前我恰好忽略了它导致找了很久。
2、知道了在scrap中爬取动态网站数据有好几种方法,可以手动抓包解析数据包获得数据,也可以结合selenium获取动态页面数据,如果直接对页面发送请求获取不到所需数据。
作业3
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
输出信息:
Currency TBP CBP TSP CSP Time
阿联酋迪拉姆 198.58 192.31 199.98 206.59 11:27:14
...
test.py
#解析数据
def parse(self, response):
count=0
#获得tr列表
# trs=response.xpath('/html/body/div[1]/div[5]/div[1]/div[2]/table/tbody/tr/td')
trs=response.xpath('//html/body/div/div[@class="BOC_main"]/div[1]/div[2]/table//tr')
print(trs)
print("-----------------------------")
for tr in trs:
currency = tr.xpath("./td[1]/text()").extract_first()
tsp = tr.xpath("./td[2]/text()").extract_first()
csp = tr.xpath("./td[3]/text()").extract_first()
tbp = tr.xpath("./td[4]/text()").extract_first()
cbp = tr.xpath("./td[5]/text()").extract_first()
time = tr.xpath("./td[8]/text()").extract_first()
count+=1
#忽略第一行标题
if count ==1 :
continue
item = Test33Item(currency=currency, tsp=tsp, csp=csp, tbp=tbp, cbp=cbp, time=time)
print(currency,tsp,csp,tbp,cbp,time+"-------------------")
yield item
items.py
class Test33Item(scrapy.Item):
currency = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
time = scrapy.Field()
pipelines.py
import pymysql
import scrapy
class mysqlPipeline:
conn = None
cursor = None
def __init__(self):
self.conn = None
self.cursor = None
def open_spider(self, spider):
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='123456', db='spiders',
charset='utf8')
def process_item(self, item, spider):
self.cursor = self.conn.cursor()
sql = "INSERT INTO test33(Currency,TBP,CBP,TSP,CSP,Time)" \
" VALUES (%s,%s, %s, %s,%s, %s)"
try:
self.cursor.execute(sql,[item["currency"], item["tbp"], item["cbp"], item["tsp"], item["csp"], item["time"]])
self.conn.commit()
print("插入成功")
except Exception as err:
print("插入失败", err)
return item
def close_spider(self, spider):
if self.cursor:
self.cursor.close()
if self.conn:
self.conn.close()
stetings.py
USER_AGENT ='...'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'test32.pipelines.mysqlPipeline': 300,
}
查看输出:
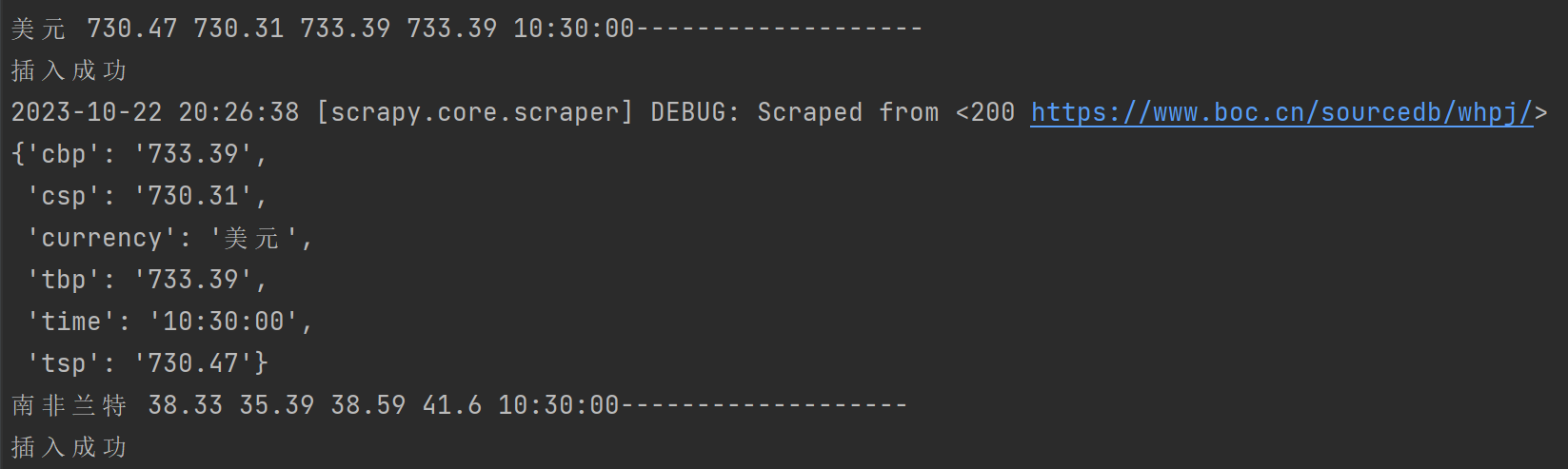
查看数据库内容:
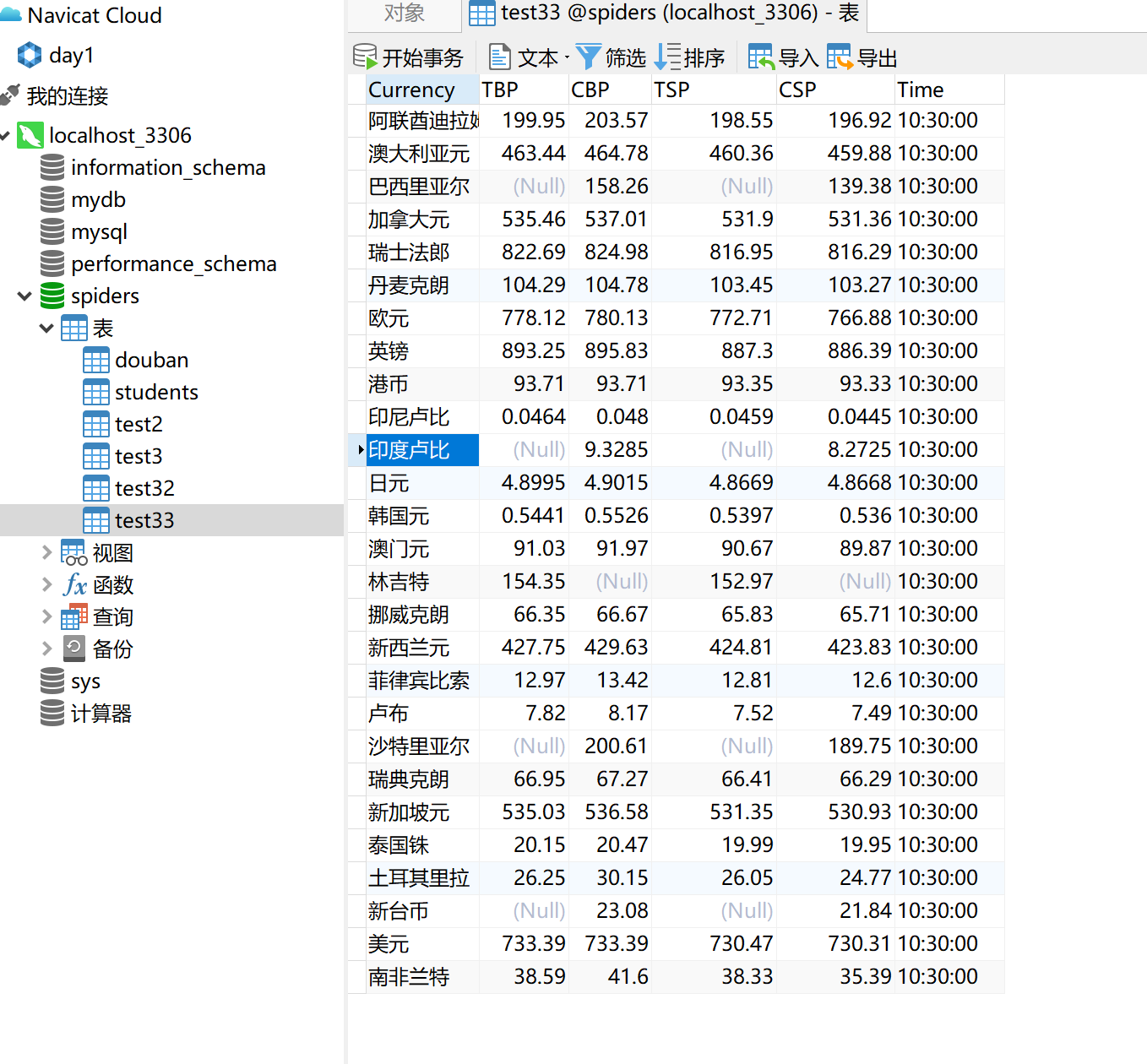
心得
1、还是和往常一样右键打开检查,复制xpath路径,获取tr列表,解析数据,但是tr列表打印出来却一直是空的,而response是有内容的,在页面上xpath表达式也能定位到元素。
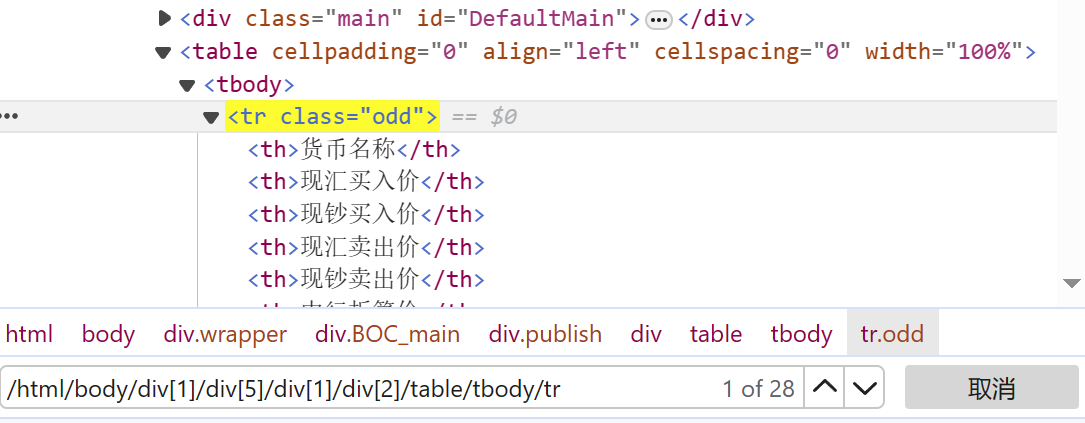
卡了很久依旧不知道咋回事,然后问助教才知道浏览器在对table进行处理时,自动添加了tbody元素,并且自动对div进行了排序,导致复制的xpath路径出错。我打开检查看到的代码是动态调试了的,而response返回的是网页源码,在源码上没有tbody,所以xpath解析不到数据,然后把tbody删了就能定位到元素了!!!又学到了一个解决bug的方法~

2、解析页面数据时要小心,如果得不到所需数据就多打印信息,查看哪步出错并找到解决方法。