产品官网:https://www.huaweicloud.com/product/hecs-light.html

今天我们采用可靠更安全、智能不卡顿、价优随心用、上手更简单、管理特省心的华为云耀云服务器L实例为例,介绍配置使用 Scikit-learn 进行鸢尾花分类的识别,作为使用云服务器进行深度学习环境配置的入门基础
Scikit-learn(sklearn)是一个用于机器学习的Python库,它提供了简单而有效的工具,用于数据挖掘和数据分析。鸢尾花分类是一个经典的机器学习问题,而Scikit-learn提供了许多工具和算法来解决这类问题。
1. **安装 Python:**
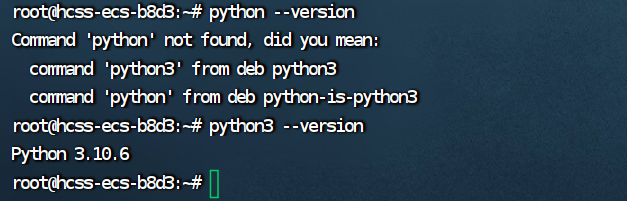
- 大多数 Ubuntu 系统预装了 Python。你可以通过以下命令检查 Python 版本:
```bash
python3 --version
```
- 如果需要安装 Python,可以使用以下命令:
```bash
sudo apt update
sudo apt install python3
```
2. **安装 pip(Python 包管理工具):**
- 使用以下命令安装 pip:
```bash
sudo apt install python3-pip
```
3. **创建虚拟环境(可选但建议):**
- 为了隔离项目的依赖,建议使用虚拟环境。使用以下命令创建虚拟环境:
```bash
sudo apt install python3-venv
python3 -m venv myenv
source myenv/bin/activate
```

4. **安装 Scikit-learn:**
- 在激活的虚拟环境中,使用以下命令安装 Scikit-learn:
```bash
pip install scikit-learn
```

5. **编写 Python 代码:**
首先,让我们在myenv环境下创建项目结构目录:
project_root/
│
├── src/
│ ├── iris_classifier/
│ │ ├── iris_classifier.py
│ │ └── 其他源代码文件(如果有)
│
├── 其他项目文件和目录

使用vim创建一个 Python 脚本来编写使用 Scikit-learn 进行鸢尾花分类的代码。
vim iris_classifier.py
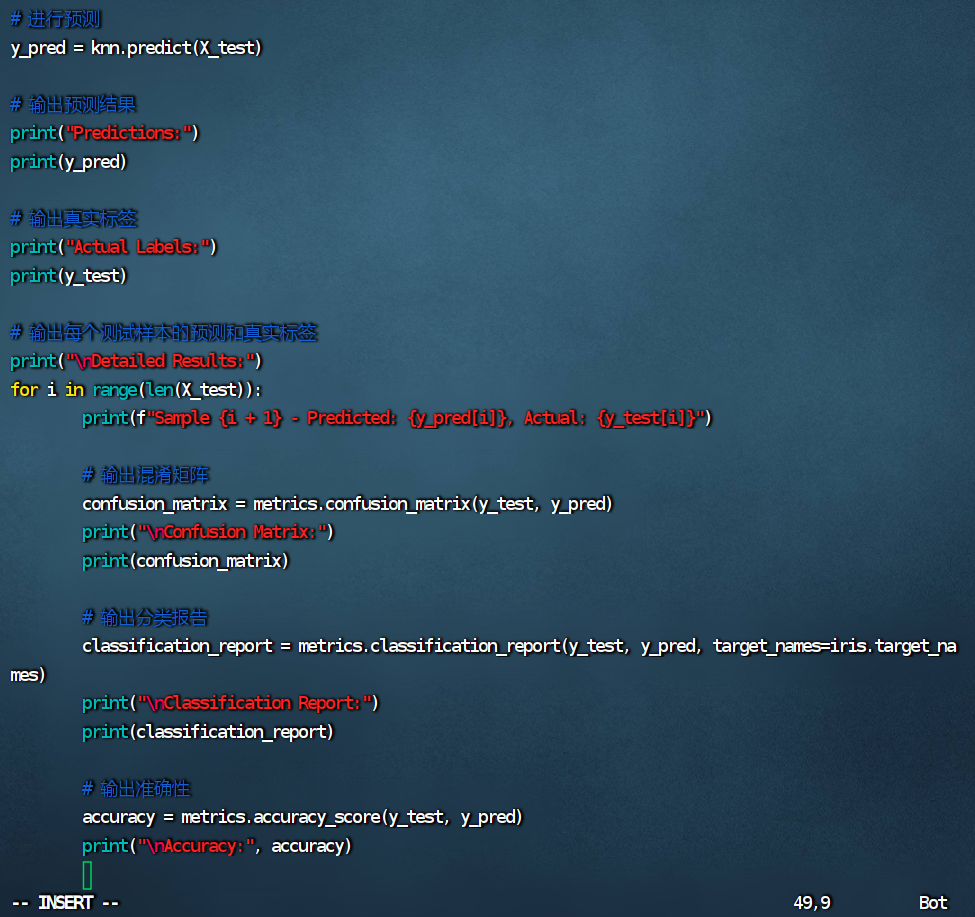
```python
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建 KNN 分类器
knn = KNeighborsClassifier(n_neighbors=3)
# 训练模型
knn.fit(X_train, y_train)
# 进行预测
y_pred = knn.predict(X_test)
# 输出预测结果
print("Predictions:")
print(y_pred)
# 输出真实标签
print("Actual Labels:")
print(y_test)
# 输出每个测试样本的预测和真实标签
print("\nDetailed Results:")
for i in range(len(X_test)):
print(f"Sample {i + 1} - Predicted: {y_pred[i]}, Actual: {y_test[i]}")
# 输出混淆矩阵
confusion_matrix = metrics.confusion_matrix(y_test, y_pred)
print("\nConfusion Matrix:")
print(confusion_matrix)
# 输出分类报告
classification_report = metrics.classification_report(y_test, y_pred, target_names=iris.target_names)
print("\nClassification Report:")
print(classification_report)
# 输出准确性
accuracy = metrics.accuracy_score(y_test, y_pred)
print("\nAccuracy:", accuracy)
```

6. **运行 Python 代码:**
- 使用以下命令运行 Python 代码:
```bash
python iris_classifier.py
```

由图可以得到完整的输出结果,包括各混淆矩阵、预测与真实样本、分类报告、准确性等。
通过这些步骤,我们成功在 华为云耀云服务器L实例上成功配置并运行使用 Scikit-learn 进行鸢尾花分类的识别。