puck因为省选保龄所以要求我们写的玩意儿。
图的基础知识
基本定义:
- 图:一张图 \(G\) 由若干个点和连接这些点的边构成。称点的集合为点集 \(V\),边的集合为边集 \(E\),记 \(G=(V,E)\)。
- 阶:图 \(G\) 的点数 \(|V|\) 称为阶,记作 \(|G|\)。
- 无向图:若 \(e\in E\) 没有方向,则称 \(G\) 为无向图。无向图的边记作 \(e = (u, v)\),\(u, v\) 之间无序。
- 有向图:若 \(e\in E\) 有方向,则称 \(G\) 为有向图。有向图的边记作 \(e = u\to v\) 或 \(e = (u, v)\),\(u, v\) 之间有序。无向边 \((u, v)\) 可以视为两条有向边 \(u\to v\) 和 \(v\to u\)。
- 重边:端点和方向(有向图)完全相同的边称为重边。
- 自环:连接相同点的边称为自环。
相邻相关:
- 相邻:在无向图中,称 \(u,v\) 相邻当且仅当存在 \(e=(u, v)\)。
- 邻域:在无向图中,点 \(u\) 的邻域为所有与之相邻的点的集合,记作 \(N(u)\)。
- 邻边:在无向图中,与 \(u\) 相连的边 \((u,v)\) 称为 \(u\) 的邻边。
- 出边 / 入边:在有向图中,从 \(u\) 出发的边 \(u\to v\) 称为 \(u\) 的出边,到达 \(u\) 的边 \(v\to u\) 称为 \(u\) 的入边。
- 度数:一个点的度数为与之关联的边的数量,记作 \(d(u)\),\(d(u)=\sum_{e\in E}([u=e_u]+[u=e_v])\)。每个点的自环对其度数产生 \(2\) 的贡献。
- 出度/入度:在有向图中,从 \(u\) 出发的边的数量称为 \(u\) 的出度,记作 \(d ^ +(u)\);到达 \(u\) 的边的数量称为 \(u\) 的入度,记作 \(d ^ -(u)\)。
路径相关:
- 途径:连接一串结点的序列称为途径,用点序列 \(v_{0..k}\) 和边序列 \(e_{1..k}\) 描述,其中 \(e_i=(v_{i-1},v_i)\)。通常写为 \(v_0\to v_1\to \cdots\to v_k\)。
- 迹:不经过重复边的途径称为迹。
- 回路:\(v_0=v_k\) 的迹称为回路。
- 路径:不经过重复点的迹称为路径,也称简单路径。不经过重复点比不经过重复边强,所以不经过重复点的途径也是路径。注意题目中的简单路径可能指迹。
- 环:除 \(v_0=v_k\) 外所有点互不相同的途径称为环,也称圈或简单环。
连通性相关:
- 连通:对于无向图的两点 \(u,v\),若存在途径使得 \(v_0=u\) 且 \(v_k=v\),则称 \(u,v\) 连通。
- 弱连通:对于有向图的两点 \(u,v\),若将有向边改为无向边后 \(u,v\) 连通,则称 \(u,v\) 弱连通。
- 连通图:任意两点连通的无向图称为连通图。
- 弱连通图:任意两点弱连通的有向图称为弱连通图。
- 可达:对于有向图的两点 \(u,v\),若存在途径使得 \(v_0=u\) 且 \(v_k=v\),则称 \(u\) 可达 \(v\),记作 \(u\rightsquigarrow v\)。
- 关于点双连通/边双连通/强连通。
特殊图:
- 简单图:不含重边和自环的图称为简单图。
- 有向无环图:不含环的有向图称为有向无环图,简称DAG(directed Acyclic Graph)。
- 完全图:任意不同的两点之间恰有一条边的无向简单图称为完全图。\(n\) 阶完全图记作 \(K_n\)。
- 树:不含环的无向连通图称为树。树是简单图,满足 \(|V|=|E|+1\)。若干棵(包括一棵)树组成的连通块称为森林。
- 稀疏图/稠密图:\(|E|\) 远小于 \(|V|^2\) 的图称为稀疏图,\(|E|\) 接近 \(|V|^2\) 的图称为稠密图。这两个概念没有严格定义,用于讨论时间复杂度为 \(\mathcal{O}(|E|)\) 和 \(\mathcal{O}(|V|^2)\) 的算法。
子图相关:
- 子图:满足 \(V'\subseteq V\) 且 \(E'\subseteq E\) 的图 \(G'=(V',E')\) 称为 \(G=(V,E)\) 的子图,记作 \(G'\subseteq G\)。
- 导出子图:选择若干个点以及两端都在该点集的所有边构成的子图称为该图的导出子图。导出子图的形态仅由选择的点集 \(V'\) 决定,称点集为 \(V'\) 的导出子图为 \(V'\) 导出的子图,记作 \(G[V']\)。
- 生成子图:\(|V'| = |V|\) 的子图称为生成子图。
- 极大子图(分量):在子图满足某性质的前提下,称子图 \(G'\) 是 极大 的,当且仅当不存在同样满足该性质的子图 \(G''\) 且 \(G'\subsetneq G''\subseteq G\)。称 \(G'\) 为满足该性质的分量,如连通分量,点双连通分量。极大子图不能再扩张。例如,极大的连通的子图称为原图的连通分量,也就是我们熟知的连通块。
约定:
- 一般记 \(n\) 表示点集大小 \(|V|\),\(m\) 表示边集大小 \(|E|\)。
图的储存
邻接矩阵存图:
我们可以用邻接矩阵存储一张图:
- 用 \(v_{i,j}\) 表示从 \(i\) 到 \(j\) 的边权,若不通则为 0。
我们能得到:无向图的邻接矩阵是对称的,有向图的邻接矩阵是不对称的。
邻接矩阵类似于网格图,所以更适合于图论入门者学。一般只在Floyd上用。
放个图示吧:
邻接表存图:
类似于这种东西:

邻接表核心结构:
-
顶点用一维数组存储
-
每个顶点的所有邻接边构成一个长度不定的线性表
由于邻接边的动态特性,一般都使用结构体+链式前向星(单链表)的方式来实现邻接表。但如果对链表知识没有掌握的话,也可以采用其它方法实现动态线性表,例如 vector,甚至数组等。
vector实现:
vector 可变大小的特性用来实现邻接表非常合适。
声明:
vector<int> g[N];//存储n个顶点对应的边,每个是一个vector
如果加权图,可用一个结构体,例如:
struct Node {int v,/*边连接的顶点*/w;/*权*/};
vector<Node> g[N];
建立:
cin>>x>>y; //输入一条边
g[x].push_back(y); //新增一条边
//加权图增加结构体:g[x].push_back({y, w});
//无向图一条边加两次:g[y].push_back(x);
遍历:
for(auto x:g[u])
//此时x可以是g[u]里的任何元素,访问x代替访问g[u]里的元素即可
- 链式前向星实现:
这是用静态数组实现单链表的一种技巧,将每个边用结构体的形态存储成一个边集(数组),每个边的 next 指向同一起点的下一条边在边集里的的序号,事实上就是一个链表。g[N] 为邻接表,存储每个顶点连接的第一条边(在边集里的序号)。
声明:
struct Edge {int to;int next;} g[N];
建边:
int head[N];
int cnt = 1;
inline void add(int from, int t) {
g[cnt].to = t;
g[cnt].next = head[from];
head[from] = cnt++;
}
遍历 :
for(int i=head[x];i!=0;i=edge[i].next)
图的遍历
与在网格图里一样,图同样拥有广度优先遍历(bfs)和深度优先遍历(dfs)。
- 深度优先遍历(dfs):
可以用一张图来描绘:

给出深度优先遍历的主要文字(口胡)过程:
假设初始状态是图中所有顶点均未被访问
-
从某个顶点出发,然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和 \(v\) 有路径相通的顶点都被访问到
-
若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止
-
实现深度优先遍历的关键在于回溯。所谓“回溯”,就是自后往前,追溯曾经走过的路径
-
走到的顶点需要打上标记,以防再次访问
因为图上的每个点最多被访问 \(1\) 次,所以单次dfs的时间复杂度是 \(\mathcal{O}(n)\) 的。
下面给出图上dfs的代码:
inline void dfs(int x) {//这里的x指在点x进行深度优先遍历
vis[x]=true;
for(auto u:g[x])
if(!vis[u]) dfs(u);
}
- 广度优先遍历(bfs):
给出广度优先遍历的主要文字(口胡)过程:
-
先入队一个节点
-
然后入队与该节点相邻的且未被访问过的节点,然后出队该节点
-
重复上一条过程直到所有的节点均被访问
ps:实现方法是用一个标记数组加队列完成的,标记数组的作用是标记节点是否被访问过。
下面给出图上bfs的代码:
inline void bfs(int x) {
q.push(x);
vis[x]=true;
while(!q.empty()) {
int u=q.front();
q.pop();
for(auto v:g[u])
if(!vis[v]) q.push(v),vis[v]=true;
}
}
特殊的树
本来不想写的,但是怕被打。
基本概念/术语:
-
树:一个长得像真实生活中倒置(即根在上、叶子在下)的树的图,任意两点之间的简单路径有且只有一条。树是一棵连通且无环的图,边数 \(=n?1\)。
-
根节点:树最上层的节点,一棵树有且只有一个。
-
深度:到根结点的路径上的边数。
-
高度:所有结点的深度的最大值。
-
叶节点:没有子结点的结点。
-
父亲:对于除根以外的每个结点,从该结点到根路径上的第二个结点。根结点没有父结点。
-
祖先:一个结点到根结点的路径上,除了它本身外的结点。根结点的祖先集合为空。
-
子节点:如果 \(u\) 是 \(v\) 的父亲,那么 \(v\) 是 \(u\) 的子结点。子结点的顺序一般不加以区分,二叉树是一个例外,有左儿子/右儿子之分。
-
兄弟:同一个父亲的多个子结点互为兄弟。
-
后代:如果 \(u\) 是 \(v\) 的祖先,那么 \(v\) 是 \(u\) 的后代。
-
子树:删掉与父亲相连的边后,该结点所在的子图。


-
二叉树
-
前/先序遍历:根 \(\rightarrow\) 左子树/儿子 \(\rightarrow\) 右子树/儿子。
-
中序遍历:左子树/儿子 \(\rightarrow\) 根 \(\rightarrow\) 右子树/儿子。
-
后序遍历:左子树/儿子 \(\rightarrow\) 右子树/儿子 \(\rightarrow\) 根。
-
遍历的特殊结论
-
前/先序遍历 + 中序遍历 = 确定二叉树。
-
后序遍历 + 中序遍历 = 确定二叉树。
-
特殊的二叉树及其性质
-
满二叉树/完美二叉树:所有叶结点的深度均相同的二叉树称为满二叉树/完美二叉树。
满二叉树的第 \(k\) 层有 \(2^{k-1}\) 个节点,任意 \(k\) 层二叉树最多有 \(2^{k-1}\) 个节点。
若在任意一棵满二叉树中,有 \(n_0\) 个叶子节点,有 \(n_2\) 个度为 \(2\) 的节点,则有 \(n_0=n_2+1\)。
\(n\) 个节点的满二叉树深为 \(\log n+1\)
- 完全二叉树:只有最下面两层结点的度数可以小于 \(2\),且最下面一层的结点都集中在该层的最左侧。


-
对于一棵满二叉树/完美二叉树,其深度为 \(k\),则其节点总数为 \(2^k-1\),此结论可逆。
-
对于一棵满二叉树/完美二叉树/完全二叉树,若任意节点(除叶节点外)的编号为 \(i\),其左儿子的编号为 \(2i\),右儿子的编号为 \(2i + 1\)。此结论可逆,证明显然。
二叉树的第 \(k\) 层至多有 \(2^{i-1}(i\ge 1)\) 个节点。
声明:
一般使用父亲儿子表示法。
struct Node {int fa,ls,rs;} t[N];
遍历:
inline void f1(int x) {
if(x==叶子节点) return;
f1(t[x].ls);
f1(t[x].rs);
}//前序遍历
inline void f2(int x) {
f1(t[x].ls);
if(x==叶子节点) return;
f1(t[x].rs);
}//中序遍历
inline void f3(int x) {
f1(t[x].ls);
f1(t[x].rs);
if(x==叶子节点) return;
}//后序遍历
- 堆:
没听,只会 priority_queue。
- 并查集
并查集用于处理一些动态不相交集合(disjoint Sets)的合并及查询问题。
并查集是用森林实现的多个不相交集合,每个集合的元素构成一棵树,树的根是
集合代表元素。
树的形态、代表元素是哪一个无关紧要。
这里给出并查集的查询和合并操作:
inline int find(int x) {
if(x==f[x]) return x;
else return find(f[x]);
}
inline void merge(int a,int b) {
int x=find(a),y=find(b);
if(x!=y) f[y]=x;
}
但是我们发现每一次查询操作是 \(\mathcal{O}(n)\) 的,我们需要想办法优化。
- 按秩合并:
人话:按照树的深度合并。
运用这一种优化可以让每一次查询操作变成 \(\mathcal{O}(\log n)\)。
代码:没听课不会。
- 路径压缩:
既然是要找你的祖先,那为什么不直接将自己与祖先相连呢?运用这一种优化可以让每一次查询操作变成 \(\mathcal{O}(\alpha(n))\)。
代码:
inline int find(int x) {
if(x!=f[x]) f[x]=find(f[x]);
return f[x];
}
最短路
对于最短路问题,我们一般是分两种情况讨论:
-
单源最短路问题(一个点到其他所有点的最短路)
-
全源最短路问题(任意两个点的最短路)
接下来讨论几种常用的最短路算法。
- Floyd:
Floyd是个典型的全源最短路算法。
Floyd的基础是一个邻接矩阵:\(dis_{x,y}\),代表着 \(x\) 到 \(y\) 点的最短路径。
初始的时候,若 \(x\) 和 \(y\) 间有一条边 \((x,y,z)\),则我们令 \(f_{x,y}=z\),如果没有边,我们可以令 \(f_{x,y}=+\infty\)。
也就是说,我们先使用 memset,将 \(dis\) 数组先全体赋正无穷。然后我们输入边,修改有边的两个点对应的 \(dis\) 数组值。特殊地,所有 \(dis_{x,x}=0\)。
本质上该算法的核心思想是去依次枚举 \([1,n]\) 作为两个点的间的断点,尝试把两条路径拼接在一起从而获得更优的两点间的最短路径。
即假设 \(y\) 作为中转点的时候,有 \(dis_{x,z}>f_{x,y}+dis_{y,z}\),则更新 \(dis_{x,z}\)为更小的 \(dis_{x,y}+dis_{y,z}\)
所以我们不难发现Floyd是个动态规划算法。
ps:其实最初的定义是 \(dis_{k,i,j}\) 表示从 \(i\) 点出发,只经过 \([1,k]\) 这些中间点,最后到达 \(j\) 点的最短距离。但是最后是可以把 \(k\) 这一维给压掉的。
代码:
inline void Floyd() {
for(int k=1;k<=n;k++)
for(int i=1;i<=n)
for(int j=1;j<=n;j++)
dis[i][j]=min(dis[i][j],dis[i][k]+dis[k][j]);
}
这玩意儿时间复杂度是 \(\mathcal{O}(n^3)\) 的,适合偷懒的时候写。
- dijkstra:
dijkstra算法是典型的单源最短路算法。
其主要过程:
初始化 \(dis\) 正无穷,从未更新节点集合中,选取一个 \(dis\) 值最小的结点 \(y\),移到已更新集合中。
对于 \(y\),我们对于每条以 \(y\) 为起点的边执行松弛操作。(松弛操作:如果有一条边起点 \(y\) 终点 \(z\) 权值 \(v\) ,我们算出 \(dis_y+v\) 与 \(dis_z\) 比较,如果前者小则执行 \(dis_z=dis_y+v\))。
基本原理是:每次新更新一个距离最短的点,更新与其相邻的点的距离数组 \(dis\)。当所有边权都为正时,由于不会存在一个最短路更短的且没更新过的点,所以这个点的距离永远不会再被改变,因而保证了算法的正确性。
\(n\) 个点每个点要更新一次,每次要套一个找 \(vis\) 最小未更新点的循环。
以及还有尝试使用每条边来松弛,故总复杂度 \(\mathcal{O}(n^2+m)\)。
优化方向:更快找到 \(vis\) 更小的点。
考虑使用优先队列或者堆来加速寻找最小点的过程。但是我不会堆,所以优先队列。
时间复杂度是 \(\mathcal{O}(m\log m)\) 的。
代码:
inline void dijkstra() {
for(int i=1;i<=n;i++)
dis[i]=2147483647;
dis[s]=0;
q.push(mp(0,s));
while(!q.empty()) {
int u=q.top().second;
q.pop();
if(vis[u]) continue;
vis[u]=true;
for(auto x:g[u])
if(dis[u]+x.w<dis[x.v]) {
dis[x.v]=dis[u]+x.w;
q.push(mp(dis[x.v],x.v));
}
}
}
- Bellman-Ford
没听。
- SPFA
实质上是队列优化的Bellman-Ford,是一种极其容易死去的算法。
很多时候,给定的图存在负权边,这时类似dijkstra等算法便没有了用武之地,而Bellman-Ford算法的复杂度又过高,SPFA算法便派上用场了。SPFA的复杂度大约是 \(\mathcal{O}(kn)\),\(k\) 是每个点的平均进队次数(一般的,\(k\)是一个常数,在稀疏图中小于2)。
但是,SPFA算法稳定性较差,在稠密图中SPFA算法时间复杂度会退化。
实现方法:建立一个队列,初始时队列里只有起始点,在建立一个表格记录起始点到所有点的最短路径(该表格的初始值要赋为极大值,该点到他本身的路径赋为 \(0\))。然后执行松弛操作,用队列里有的点去刷新起始点到所有点的最短路,如果刷新成功且被刷新点不在队列中则把该点加入到队列最后。重复执行直到队列为空。
此外,SPFA算法还可以判断图中是否有负权环,即一个点入队次数超过 \(n\)。
代码:
inline void spfa() {
for(int i=1;i<=n;i++)
dis[i]=2147483647;
q.push(s),dis[s]=0,vis[s]=false;
while(!q.empty()) {
int u=q.front();
q.pop();
vis[u]=false;
for(auto x:g[u])
if(dis[u]+x.w<dis[x.v]) {
dis[x.v]=dis[u]+x.w;
if(!vis[x.v]) vis[x.v]=true,q.push(x.v);
}
}
}
- Johnson
Johnson是个不典型的全源最短路算法。
任意两点间的最短路可以通过枚举起点,跑 \(n\) 次Bellman-Ford算法解决,时间复杂度是 \(\mathcal{O}(n^2m)\) 的,也可以直接用Floyd算法解决,时间复杂度为 \(\mathcal{O}(n^3)\) 。
注意到堆优化的dijkstra算法求单源最短路径的时间复杂度比Bellman-Ford更优,如果枚举起点,跑 \(n\) 次 dijkstra 算法,就可以在 \(\mathcal{O}(nm\log m)\) (本文中的dijkstra采用 priority_queue 实现,下同)的时间复杂度内解决本问题,比上述跑 \(n\) 次 Bellman-Ford 算法的时间复杂度更优秀,在稀疏图上也比 Floyd 算法的时间复杂度更加优秀。
但 dijkstra 算法不能正确求解带负权边的最短路,因此我们需要对原图上的边进行预处理,确保所有边的边权均非负。
一种容易想到的方法是给所有边的边权同时加上一个正数 \(x\) ,从而让所有边的边权均非负。如果新图上起点到终点的最短路经过了 \(k\) 条边,则将最短路减去 \(kx\) 即可得到实际最短路。
但这样的方法是错误的。考虑下图:
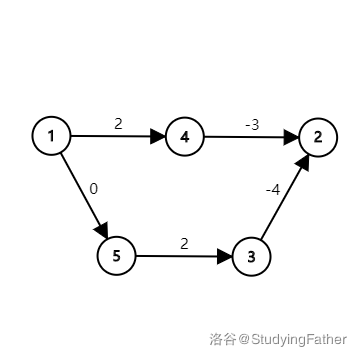
\(1 \to 2\) 的最短路为 \(1 \to 5 \to 3 \to 2\),长度为 \(-2\)。
但假如我们把每条边的边权加上 \(5\) 呢?
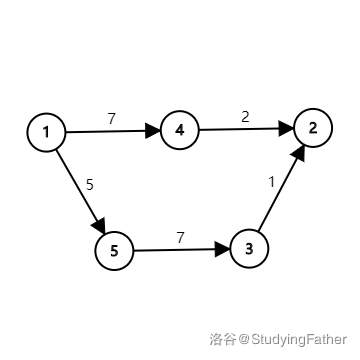
新图上 \(1 \to 2\) 的最短路为 \(1 \to 4 \to 2\) ,已经不是实际的最短路了。
Johnson算法则通过另外一种方法来给每条边重新标注边权。
我们新建一个虚拟节点(在这里我们就设它的编号为 \(0\) )。从这个点向其他所有点连一条边权为 \(0\) 的边。
接下来用 Bellman-Ford 算法求出从 \(0\) 号点到其他所有点的最短路,记为 \(h_i\) 。
假如存在一条从 \(u\) 点到 \(v\) 点,边权为 \(w\) 的边,则我们将该边的边权重新设置为 \(w+h_u-h_v\) 。
接下来以每个点为起点,跑 \(n\) 轮dijkstra算法即可求出任意两点间的最短路了。
容易看出,该算法的时间复杂度是 \(\mathcal{O}(nm\log m)\) 。
为什么这样重新标注边权的方式是正确的呢?
在讨论这个问题之前,我们先讨论一个物理概念——势能。
诸如重力势能,电势能这样的势能都有一个特点,势能的变化量只和起点和终点的相对位置有关,而与起点到终点所走的路径无关。
势能还有一个特点,势能的绝对值往往取决于设置的零势能点,但无论将零势能点设置在哪里,两点间势能的差值是一定的。
接下来回到正题。
在重新标记后的图上,从 \(s\) 点到 \(t\) 点的一条路径 \(s\to p_1\to p_2\to\dots\to p_k\to t\) 的长度表达式如下:
化简后得到:
无论我们从 \(s\) 到 \(t\) 走的是哪一条路径, \(h_s-h_t\) 的值是不变的,这正与势能的性质相吻合。
为了方便,下面我们就把 \(h_i\) 称为 \(i\) 点的势能。
上面的新图中 \(s\to t\) 的最短路的长度表达式由两部分组成,前面的边权和为原图中 \(s\to t\) 的最短路,后面则是两点间的势能差。因为两点间势能的差为定值,因此原图上 \(s\to t\) 的最短路与新图上 \(s\to t\) 的最短路相对应。
到这里我们的正确性证明已经解决了一半——我们证明了重新标注边权后图上的最短路径仍然是原来的最短路径。接下来我们需要证明新图中所有边的边权非负,因为在非负权图上,dijkstra算法能够保证得出正确的结果。
根据三角形不等式,新图上任意一边 \((u,v)\) 上两点满足: \(h_v \leq h_u + w(u,v)\) 。这条边重新标记后的边权为 \(w'(u,v)=w(u,v)+h_u-h_v \geq 0\) 。这样我们证明了新图上的边权均非负。
至此,我们就证明了Johnson算法的正确性。
ps:虽然上面都是用的Bellman-Ford,但是我还是喜欢用SPFA(。
代码:
#include<bits/stdc++.h>
#define ll long long
using namespace std;
const int N=3e3+5;
ll n,m,u,v,cnt[N],dis[N],ans,w,d[N],inf=1e9;
struct node{ll v,w;};
vector<node>a[N];
bool vis[N];
bool spfa() {
queue<ll> q;
for(int i=1;i<=n;i++) {
d[i]=inf;
a[0].push_back(node{i,0});
}
q.push(0);vis[0]=1;
while(q.size()) {
u=q.front();q.pop();vis[u]=0;
for(int i=0;i<a[u].size();i++) {
v=a[u][i].v,w=a[u][i].w;
if(d[v]>d[u]+w) {
d[v]=d[u]+w;
if(!vis[v]) {
if(++cnt[v]==n+1) return 1;
q.push(v);vis[v]=1;
}
}
}
}
return 0;
}
void dijkstra(int s) {
priority_queue<pair<ll,int> > q;
for(int i=1;i<=n;i++)
vis[i]=0,dis[i]=inf;
q.push(make_pair(0,s));
dis[s]=0;
while(q.size()) {
u=q.top().second;q.pop();
if(vis[u]) continue;
vis[u]=1;
for(int i=0;i<a[u].size();i++) {
v=a[u][i].v,w=a[u][i].w;
if(dis[v]>dis[u]+w) {
dis[v]=dis[u]+w;
if(!vis[v])q.push(make_pair(-dis[v],v));
}
}
}
}
void query(int x) {
ans=0;
for(int i=1;i<=n;i++) {
if(dis[i]==inf) ans+=i*inf;
else ans+=i*(dis[i]+d[i]-d[x]);
}
printf("%lld\n",ans);
}
int main() {
scanf("%lld%lld",&n,&m);
for(int i=1;i<=m;i++) {
scanf("%lld%lld%lld",&u,&v,&w);
a[u].push_back(node{v,w});
}
if(spfa()) return puts("-1"),0;
for(int i=1;i<=n;i++)
for(int j=0;j<a[i].size();j++)
a[i][j].w+=d[i]-d[a[i][j].v];
for(int i=1;i<=n;i++) {
dijkstra(i);
query(i);
}
return 0;
}
- 负环:
上面讲完了啊。
- 差分约束
给出一组包含 \(m\) 个不等式,有 \(n\) 个未知数的形如:
的不等式组,求任意一组满足这个不等式组的解。
用数学的思维来看,这是个 \(NP\) 问题。但我们是OIER。像这一类问题我们就可以使用差分约束来解决。上面那一堆柿子可以看作一个差分约束系统。
怎样解这个差分约束系统呢?我们将上面的不等式变形一下:
容易发现这个形式和最短路中的三角形不等式 \(dis_v \leq dis_u + w\) 非常相似。
因此我们就将这个问题转化为一个求最短路的问题:比如对于上面这个不等式,我们从 \(j\) 向 \(i\) 连一条权值为 \(c_k\) 的边。
接下来,我们再新建一个 \(0\) 号点,从 \(0\) 号点向其他所有点连一条权值为 \(0\) 的边。
这个操作相当于新增了一个变量 \(x_0\) 和 \(n\) 个约束条件:\(x_i \leq x_0\),从而将所有变量都和 \(x_0\) 这一个变量联系起来。
然后以 \(0\) 号点为起点,用 Bellman-Ford 跑最短路。如果有负权环,差分约束系统无解。否则设从 \(0\) 号点到 \(i\) 号点的最短路为 \(dis_i\),则 \(x_i = dis_i\) 即为差分约束系统的一组可行解。
ps:这个 \(0\) 号点其实就是我们所说的超级源点。
很多时候差分约束的条件并不是简单的小于等于号,这时候我们需要稍微做点变形。
如果有 \(x_i - x_j \geq c_k\),则可以两边同时乘 \(-1\),将不等号反转过来。
如果有 \(x_i - x_j = c_k\),则可以把这个等式拆分为 \(x_i - x_j \leq c_k\) 和 \(x_i - x_j \geq c_k\) 两个约束条件。
代码:
#include<bits/stdc++.h>
using namespace std;
const int N=5e3+5;
struct Node{int v,w;};
vector<Node> g[N];
int n,m,dis[N],cnt[N],vis[N],u,v,w;
queue<int> q;
bool spfa(int s) {
memset(dis,0x3f,sizeof(dis));
dis[s]=0,vis[s]=1;
q.push(s);
while(q.size()) {
u=q.front();q.pop();
vis[u]=0;
for(auto x:g[u]) {
v=x.v,w=x.w;
if(dis[v]>dis[u]+w) {
dis[v]=dis[u]+w,cnt[v]=cnt[u]+1;
if(cnt[v]>n) return false;
if(!vis[v]) q.push(v),vis[v]=1;
}
}
}
return true;
}
int main() {
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++) {
scanf("%d%d%d",&u,&v,&w);
g[v].push_back((Node){u,w});
}
for(int i=1;i<=n;i++)
g[0].push_back((Node){i,0});
if(spfa(0))
for(int i=1;i<=n;i++)
printf("%d ",dis[i]);
else puts("NO");
return 0;
}
- 0-1 BFS
0-1 BFS通常是维护一个无权图的最短路。它是无权图中最高效的最短路算法。
以下内容来源于CF日报,我只是将其翻译并加以优化。
问题:
您有一个具有 $V $个顶点和 \(E\) 条边的图 \(G\)。该图是一个加权图,但权重有一个限制,即它们只能是 \(0\) 或 \(1\)。编写一个高效的代码来计算来自给定源的最短路径。
解决方案:
朴素解——dijkstra算法。
这在其最佳实现中具有 \(\mathcal{O}(E+V\log V)\) 的复杂性。你可以尝试试探法,但最坏的情况仍然是一样的。在这一点上,你可能会考虑如何优化dijkstra,或者为什么我要写一个如此高效的算法作为天真的解决方案?
好的,首先,有效的解决方案不是dijkstra的优化。其次,这是一个天真的解决方案,因为几乎每个人第一次看到这样的问题时都会编码,假设他们知道dijkstra的算法。
假设dijkstra的算法是你最好的代码,我想向你展示一个非常简单但优雅的技巧,用广度优先搜索(BFS)来解决这类图上的问题。
在我们深入研究算法之前,需要一个引理,以便稍后将事情弄清楚。
在BFS的执行过程中,包含顶点的队列最多只包含BFS树的两个连续级别的元素。
说明:BFS树是在任何图上执行BFS期间建立的树。这个引理是真的,因为在BFS执行的每个点上,我们只遍历到一个顶点的相邻顶点,因此队列中的每个顶点与队列中的所有其他顶点最多相距一级。
让我们从 0-1 BFS开始吧。
0-1 BFS:
之所以如此命名,是因为它适用于边权重为 \(0\) 和 \(1\) 的图。让我们以BFS的执行点为例,当你在一个具有权重为 \(0\) 和 \(1\) 的边的任意顶点 \(u\) 上时。与dijkstra类似,只有当一个顶点被前一个顶点松弛时,我们才会将其放入队列中(通过在该边上移动来减少距离),并且我们还保持队列在每个时间点按与源的距离排序。
现在,当我们在 \(u\) 时,我们确信一件事:沿着边 \((u,v)\) 移动将确保 \(v\) 与 \(u\) 处于同一水平或处于下一个连续水平。这是因为边权重分别为 \(0\) 和 \(1\)。边缘权重为 \(0\) 意味着它们位于同一水平上,而边缘权重为 \(1\) 意味着它们处于下面的水平上。我们还知道,在BFS期间,我们的队列最多保持两个连续级别的顶点。因此,当我们处于顶点 \(u\) 时,我们的队列包含级别 \(L_u\) 或 \(L_u+1\) 的元素。
我们还知道,对于边 \((u,v)\),\(L_v\) 要么是 \(L_u\),要么是 \(L_u+1\)。因此,如果顶点 \(v\) 是松弛的,并且具有相同的级别,我们可以将其推到队列的前面,如果它具有下一级别,我们也可以将其推向队列的末尾。这有助于我们按级别对队列进行排序,以便BFS正常工作。
但是,使用普通的队列数据结构,我们不能插入并保持它在 \(\mathcal{O}(1)\) 的时间内排序。使用优先队列会花费我们 \(\mathcal{O}(\log N)\)来保持它的排序。普通队列的问题是缺少帮助我们执行所有这些功能的方法:
-
移除顶部元素(为BFS获取顶点)
-
在开始处插入(推动具有相同级别的顶点)
-
在末尾插入(将顶点推到下一级)
幸运的是,所有这些操作都得到了双端队列(C++ STL deque)的支持。让我们来看看这个技巧的伪代码:
for all v in vertices:
dist[v] = inf
dist[source] = 0;
deque d
d.push_front(source)
while d.empty() == false:
vertex = get front element and pop as in BFS.
for all edges e of form (vertex , u):
if travelling e relaxes distance to u:
relax dist[u]
if e.weight = 1:
d.push_back(u)
else:
d.push_front(u)
正如你所看到的,这与BFS+dijkstra非常相似。但这个代码的时间复杂度是 \(\mathcal{O}(E+V)\),它是线性的,比dijkstra更有效。正确性的分析和证明也与BFS相同。
在着手解决在线评测的问题之前,请尝试以下练习,以确保您完全理解0-1 BFS的工作原理和方式:
如果我们的边权只能是 \(0\) 和 \(x(x\ge 0)\),或 \(x\) 和 \(x+1(x\ge 0)\),或 \(x\) 和 \(y(x,y\ge 0)\),我们能应用同样的技巧吗?
这个技巧其实很简单,但知道这个的人不多。
拓扑排序
拓扑排序要解决的问题是给一个图的所有节点进行排序,形成一个线性序列。
详细的说,就是在一张在有向无环图(又称DAG)中找到一个序列,使得对于图中的所有边 \(u\to v\),在拓扑序中 \(u\) 必须出现在 \(v\) 的前面。
也就是说,只有当一个节点入度为 \(0\) 时,对于它的约束才解除。
我们可以用一个队列来储存入度为 \(0\) 的点,每一次都将队首元素所连的点的入度减 \(1\),当一个点的入度为 \(0\) 时,它就会入队。
那么显然,当队列空时还有节点仍然留在图内,就说明出现了环。
代码:
inline void toposort() {
while(!q.empty()) {
int x=q.front();
q.pop();
for(auto u:g[x]) {
inv[u]--;
if(!inv[u]) q.push(u);
}
ans[++cnt]=x;
}
}
最小生成树
有的时候,我们想在一张无向图中选取一些边,使得 \(n\) 个点联通。一般来说,我们会选择最少的 \(n-1\) 条边来完成这个任务,此时我们的这 \(n\) 个点和 \(n-1\) 条边相当于组成了一棵树,这棵树就叫生成树。
如果边或点有权值,我们一般考虑边或点总和最小的生成树,这棵生成树又叫最小生成树。当然,结果可能是不唯一的。我们一般讨论边权的最小生成树。
我们现在需要考虑如何去解决关于最小生成树的问题。
- kruskal
考虑一种贪心的思想:从小到大加边。
我们给边排序,当然不是直接把前 \(n-1\) 条边全选上---因为会构成环,出现环
的时候我们应该是要去掉最大权值的那条。因为我们已经给边排完序了,所以最大权值的边其实也就是后枚举到的那条。
那么我们考虑维护点的连通性,如果两个点已经联通,则这两个点之间的路径无法添加。我们这里使用并查集解决连通性的判断。
时间复杂度是排序的 \(\mathcal{O}(m\log m)\)。
代码:
#include <bits/stdc++.h>
#define int long long
using namespace std;
const int N=5e5+5;
int n,m,u,v,w,ans,cnt,f[N];
struct Node {int u,v,w;} g[N];
inline bool cmp(Node a,Node b) {return a.w<b.w;}
inline int find(int x) {
if(x!=f[x]) f[x]=find(f[x]);
return f[x];
}
signed main() {
ios_base::sync_with_stdio(NULL);
cin.tie(nullptr);
cout.tie(nullptr);
cin>>n>>m;
for(int i=1;i<=m;i++)
cin>>g[i].u>>g[i].v>>g[i].w;
for(int i=1;i<=n;i++)
f[i]=i;
sort(g+1,g+1+m,cmp);
for(int i=1;i<=m;i++) {
u=find(g[i].u),v=find(g[i].v);
if(u==v) continue;
ans+=g[i].w,f[v]=f[u];
if(++cnt==n-1) return cout<<ans,0;
}
cout<<"orz";
return 0;
}
- prim
对于最小生成树的问题,我们还有一种基于点的解决方式,即通过不断向当前生成树中加点生成最小生成树。此算法就是prim。
算法流程如下:
-
先随便选择一个点 \(s\) 作为起点,把其他所有点设为未添加节点,再设一 \(dis\) 数组,代表每个节点到最小生成树最近点的距离,易得一开始只有 \(dis_s=0\) 其他均为 \(+\infty\)。
-
每轮找到 \(dis\) 值最小且未添加过的节点加入生成树中,且使用这个节点的邻边去更新它的邻点的 \(dis\) 值,如更新点为 \(u\),\(u\to v\) 有一条长度为 \(x\) 的边,则我们可以更新 \(dis_v\) 为 \(\min\{dis_v,x\}\)。
-
重复执行上一个操作,直到所有点全部被添加。
算法思想和dijkstra类似,复杂度为 \(\mathcal{O}(n^2+m)\)。同样也可以用堆/优先队列优化,但是优化后的复杂度为 \(\mathcal{O}(m\log n(or\ m))\) 级别的,其实和kruskal比占不到优势,还不如就暴力在稠密图的时候占据优势。
这个我不常用,所以没有代码。