Gossip
二阶段提交协议和Raft需要大部分节点能够工作,在极端情况,如只有一个节点能正常运行,这些方法就不适用了。根据Base理论要实现最终一致性。
Gossip协议利用一种随机、带有传染性的方式,将信息传播到网络中,并在一定时间内使所有节点数据一致。
- 直接邮寄(Direct Mail):直接发送数据,当数据发送失败时缓存下来,然后重传。可能因为缓存队列存满了而丢数据。
- 反熵(Anti-entropy):通过异步修复实现最终一致性。常见的最终一致性系统(如Cassandra)都实现了反熵功能。
- 谣言传播(Rumor mongering)
反熵
指集群中节点每隔一段时间随机选择某个其他节点,然后互换数据消除二者差异,实现最终一致性。主要有推、拉、推拉三种方式。熵是指混乱程度,反熵就是指消除数据差异。因为反熵要两两比对所有数据,所以执行反熵的通讯成本很高,不建议频繁执行,且应当引入校验和等机制。
原数据:
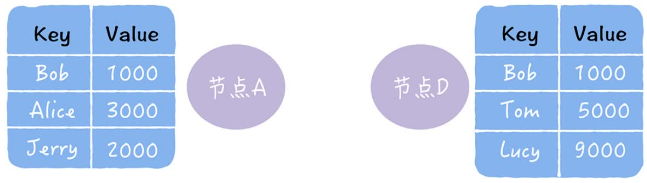
- 推:将自己的所有副本推给对方,修复对方副本中的数据

- 拉:拉去对方的所有副本,修复自己副本中数据:

- 推拉:同时修复自己副本和对方副本中的数据:
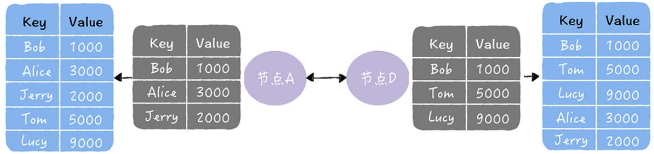
执行反熵时要求:相关节点都是已知的,且数量不能太多。在动态变化或节点较多的分布式环境,如DevOps环境中检测节点故障并维持状态。这时就不能使用反熵,要使用谣言传播。
谣言传播
一个有了新数据的节点会变为活跃节点,并周期性地向其他节点发送新数据,直到所有节点都存储了该数据。
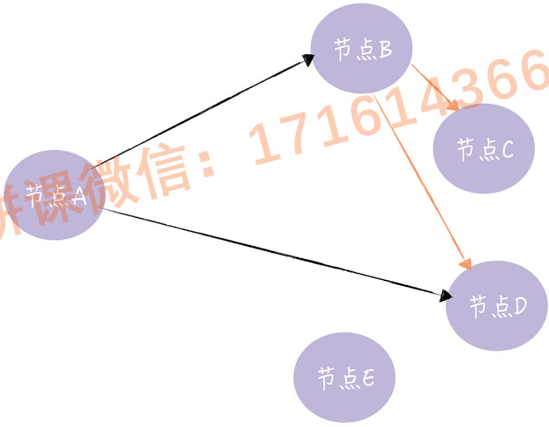
A收到新数据后向节点BD发送新数据,节点B接收新数据后变活跃节点向CD发送数据。其十分具有传播性,适合动态变化的分布式系统。
使用 Anti-entropy 实现最终一致
在自研InfluxDB中一份数据副本由多个分片组成,也就是实现了数据分片
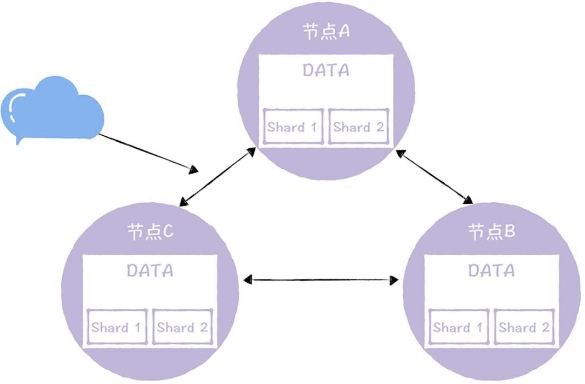
反熵的目标是保证每个DATA节点有元信息指定的分片,且不同节点上同一分组中分片没有差异。数据缺失分两种情况:
缺失分片
将分片数据通过RPC复制即可
节点间分片不一致
按照一定顺序修复节点间数据差异,先随机选一个节点,然后循环修复,每个节点生成自己有、下一个节点没有的差异数据,发送给下一个节点进行修复。假设图中分片在各节点不同:

注意图中最后又对B执行了一次修复,这样C有B没有的数据才能同步到B上。
这里的反熵和之前说的有所不同,不是一个节点不断随机选择一个节点修复,而是设计了一个闭环流程,一次修复所有节点的副本数据不一致性。目的是在一个确定时间内实现数据副本的最终一致性,而不是基于随机性的概率,在一个不确定时间内实现。
总结
- 反熵很消耗性能,应当将是否使用反熵、执行一致性检测的间隔时间等,做成可配置的
- Gossip是一种异步修复、实现最终一致性的协议,在Dynamo、InfluxDB、Cassandra 等使用
- 在需要实现最终一致性时优先考虑反熵
- “谣言”极具传播性,非常适合动态变化的分布式系统
存储组件中,节点都是已知的,一般采用反熵修复数据副本一致性。
集群是变化、节点数较多时,采用谣言传播的方式更新数据,实现最终一致性。
Quorum NWR算法
用于自定义一致性级别
- 强一致性:写操作完成后所有读请求立即能得到最新数据
- 最终一致性:读请求可能得到旧数据,但是最终系统会达到一致,会延迟返回新消息
对于一个AP系统,可能需要临时调整为CP状态以满足业务需求。通过 Quorum NWR 可以自定义一致性级别,临时调整写入或查询方式,开发新功能。当 W + R > N 时就可以实现强一致性了。
在AP型分布式系统中,如 Dynamo、Cassandra、InfluxDB的DATA节点,这都是被用到了。用于灵活地指定一致性级别。
三要素
- N复制因子(Replication Factor):集群中同一份数据有多少副本
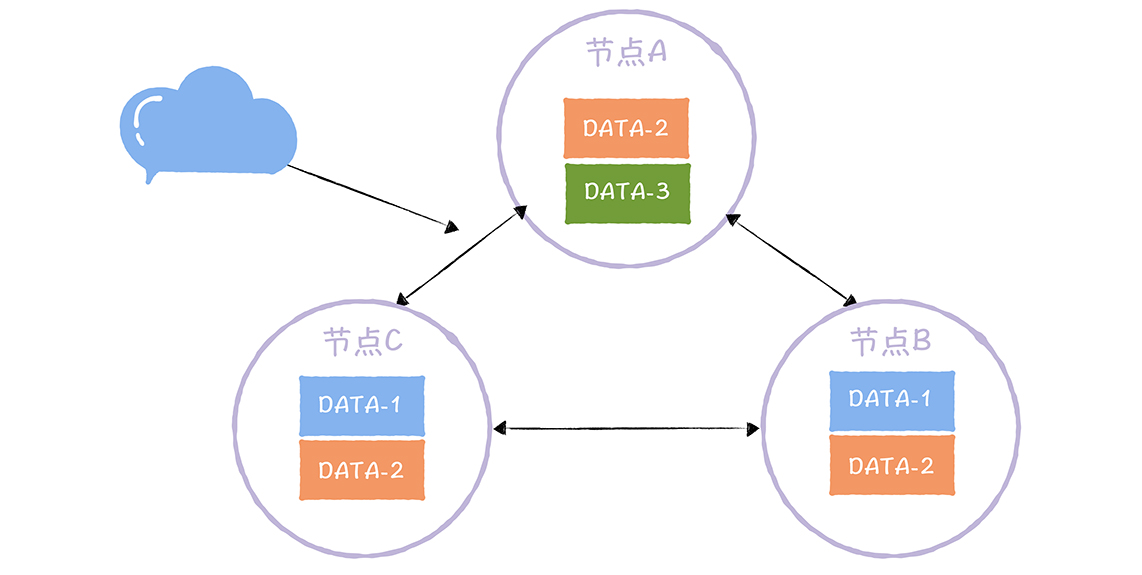
DATA-1,2,3 分别有2,3,1个不同副本。副本数不等于节点数,不同数据可以有不同副本数。在实现Quorum NWR 时需要实现自定义副本数的功能,保证用户可以自定义指定数据的副本数。 - W 写一致性级别(Write Consistency Level):成功完成W个副本更新才算完成写操作

如图,DATA-2的写副本数为2,对DATA-2执行写操作时,完成了2副本的更新(如A、C)才算完成写操作。如果这时读取到第三个副本的数据(如B),那么就无法读取到更新后的值。通过R解决这个问题。 - R 读一致性级别(Read Consistency Level):读取一个数据对象时要读R个副本,然后返回R个副本中最新的那份数据
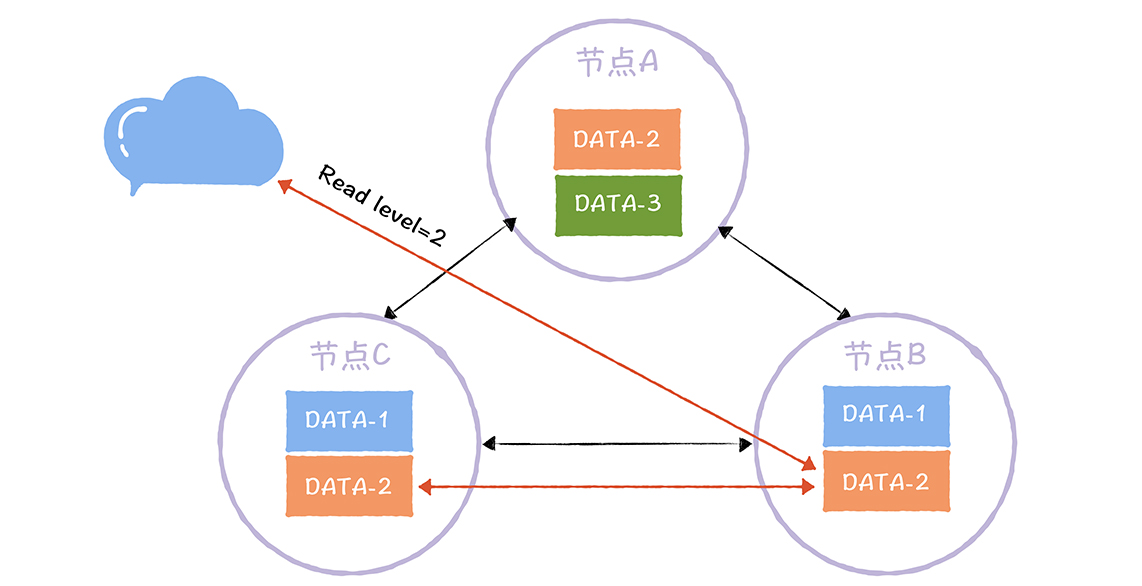
图中DATA-2的读副本数为2,及客户端读取DATA-2数据时,要读取2个副本中的数据并返回最新的那份。即使客户端访问的是未强制更新数据的节点B,但因为W(2) + R(2) > N(3),所以还会读取被强制更新的节点AC,返回的一定是最新的数据。
NWR值的不同组合会产生不同的一致性效果:
- W+R>N 系统保证强一致性,一定返回更新后数据
- W+R<N 保证最终一致性,可能返回旧数据
实现
InfluxDB 在创建保留策略时可设置副本数,注意副本数不能超过节点数。多副本的意义在于冗余,如果一个节点上存在多个副本,那么意义不大。Influx DB 企业版支持四种一致性级别:
- any:任何一个节点写入成功后,或接受节点将数据写入Hinted-handoff缓存(写其他节点失败后,本地节点缓存写失败数据的队列)后,就返回成功给客户端
- one:任何一个节点写入成功后立即返回成功,不包括写入到 Hinted-handoff 缓存
- quorum:大多数节点写入成功后返回成功,竟在副本数大于2时有意义,否则等于all
- all:所有节点写入成功后,返回成功
不同场景使用不同方法。对于时序数据库,读操作会拉取大量数据,查询性能是挑战,故InfluxDB企业版中不支持读一致性级别,只支持写一致性级别。可通过设置写一致性级别为all,实现强一致性。
总结
- 不推荐副本数超过当前节点数
- NWR的设置决定了想优化的性能。
N决定副本的冗余备份能力;W=N读性能较好;R=N写性能较好;W=(N=1)/2, R=(N+1)/2,容错能力较好,能容忍少数节点(n-1)/2的故障
Quorum NWR能有效弥补AP系统缺乏强一致性的痛点,能按需选择一致性级别灵活度。推荐AP系统实现这个算法。
PBFT
在拜占庭错误场景下,口信消息型拜占庭问题中,在叛徒干扰下将军达成一致行动,但是并不能保证结果。这会出现:适合进攻时达成的共识却是撤退。但在实际场景中需要提议的一系列值,在发生拜占庭错误时也能达成共识。这需要PBFT算法。
这是一种能落地的算法,广泛用于区块链。
口信消息型拜占庭问题解的局限
若将军数为n、叛将数位f,算法要递归协商f+1轮,消息复杂的位O(n^(f+1)),消息数量呈指数级。叛将数为64时消息数无法用int64表达。
签名消息的问题解,只要经过f+1轮即可,但同样存在“理论化”和“消息指数级暴增”的痛点。
PBFT如何达成共识
假设苏秦和4位将军商量军机要事,已知其中可能有一位叛徒。如何保证正确、一致地行动?
注意:所有消息都是签名消息,都是无法伪造和篡改的
- 苏秦联系赵发送“进攻”指令,赵接收后执行三阶段协议(Three-phase protocol)
- 赵进入预准备阶段(Pre-prepare),构造包含指令的预准备消息,广播给其他将军
其他将军接收到消息后不能立即执行,因为无法确定其他人接收的消息相同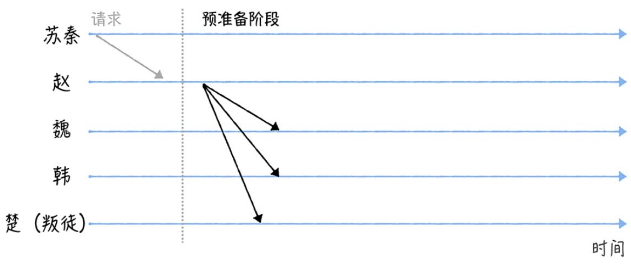
- 魏、韩、楚进入准备阶段(Prepare),分别广播包含指令的准备消息给其他将军。
这里叛徒(楚)通过不发送消息干扰共识协商。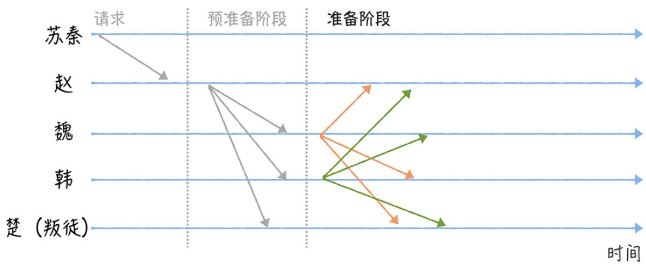
- 当某个将军接收到2f个一致的包含作战指令的准备消息后,进入提交阶段(Commit),并广播其他将军,表示自己准备好了,随时可以执行指令。
这里的2f包括自己,f为叛徒数,此处为1。
此时该将军不能直接执行指令,因为无法确定其他将军是否收到2f个准备消息。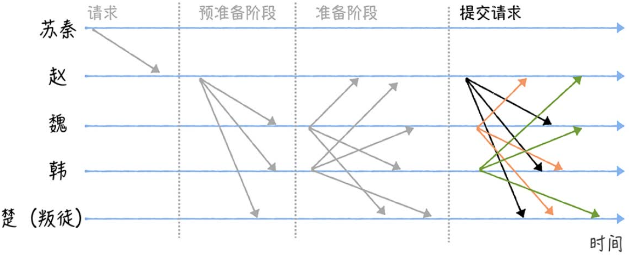
- 当某个将军收到2f+1个验证通过的消息后(包括自己,此处f为1),即大部分达成共识,这时可以执行指令,完毕后发送执行成功指令给发起者
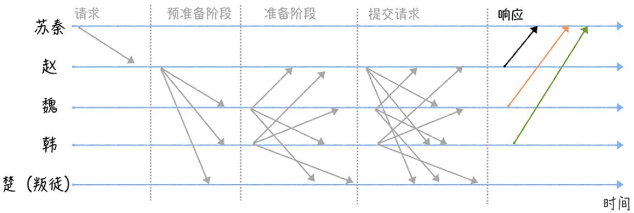
- 最后苏秦收到f+1个相同响应(Reply)时,各将军已达成共识并执行了指令。
这就是一个简化版的 PBFT 算法,其中苏秦是客户端,赵是主节点(Primary node),魏韩楚是从节点(Secondary node)。
PBFT通过签名约束恶意节点行为,基于大多数原则(2f+1)实现共识。如果客户端未在指定时间内收到请求对应的f+1相同响应,就认为共识未达成,重新发送请求。
PBFT通过视图变更(View Change)的方式处理主节点作恶,发现主节点作恶时通过“轮流上岗”推举新的主节点。
PBFT将消息复杂度从口信消息型拜占庭解的O(N^(f+1))降低为O(n^2),但仍然需要相当多的消息用于协商,故仅适用于中小型分布式系统。
总结
- 口信消息型和签名消息型拜占庭问题解都是理论化的,协商成本高,呈指数级。不实用
- PBFT通过签名、三阶段协议,基于大多数原则达成一系列值的共识
- raft不适应有恶意节点的场景,PBFT能容忍 (n-1)/3 的恶意节点,且比起PoW其无需消耗算力。故PBFT适用于“可信”场景,如联盟链
- PBFT和raft的性能都受限于“领导者”
ZAB
兰伯特的Multi-Paxos能保证达成共识后值不再改变,但不保证达成共识的值是什么。也无法保证操作的顺序。
Multi-Paxos 问什么无法实现操作顺序性
在此协议中,对于指定序号位置,最多有一个指令被选定,但不关心是哪一条,即不关心顺序性。
假设有3个节点的集群,被选定指令最大序号为100,新提议的序号为101。
- A是leader,提议了X、Y,但因为网络故障,只有A成功提交了数据
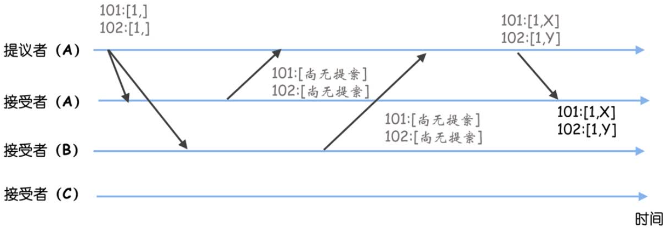
- 此时A故障,B当选leader并作为学习者了解目前被选定的指令。在B看来被选定指令的最大序号为100,并接收客户端请求提议了指令Z,指令Z被复制到了节点B、C
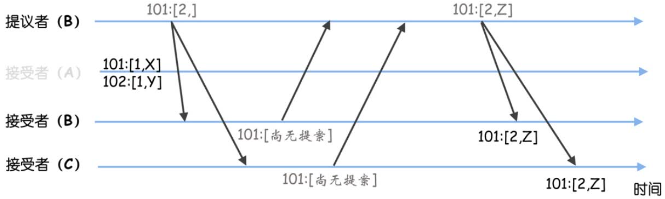
- 之后B故障,A恢复,C当选leader,然后B恢复。C当选leader后要先作为学习者,了解目前被选定的指令。这时它执行Basic Paxos的准备阶段,会发现之前选定的值(如Z、Y),然后发送接受请求,最终在序号101、102处的共识是 Z、Y

- 原本预期的X、Y变为了Z、Y。也就是Multi-Paxos能就一系列值达成共识,但是不关心内容到底是什么
ZAB如何保证操作顺序性
ZAB使用基于主备模式的原子广播协议,最终实现了操作的顺序性。
一个主节点和多个备份节点,所有副本数据以主节点为准。主节点使用二阶段提交,向备份同步数据。如果主节点故障,选数据最完备的节点当主节点。
原子广播协议即广播一组消息,消息的顺序是固定的。
为了提升容错能力,将数据复制到大多数节点后,主节点进入提交执行阶段,通知备份节点执行提交操作(这点与Raft类似)。
如何实现操作的顺序性
- 所有数据以主节点为准
- ZAB实现了FIFO队列,保证消息顺序性
- 主节点更换时,只有日志最完备的才能当选。其包含了所有已提交日志,这能保证已提交的日志不会改变
InfluxDB 企业版
时序数据库
存储时序数据的数据库,按照时间顺序记录系统、设备状态变化的数据,如CPU利用率、某一时间的环境温度。其数据主要来自监控,数据自然是越多越好。
> SELECT * FROM "h2o_feet"
name: h2o_feet
--------------
time level description location water_level
2015-08-18T00:00:00Z below 3 feet santa_monica 2.064
2015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.12
[...]
2015-09-18T21:36:00Z between 3 and 6 feet santa_monica 5.066
2015-09-18T21:42:00Z between 3 and 6 feet santa_monica 4.938它由META和DATA两个逻辑单元组成,且是两个单独的程序。使用场景不同
- META节点:系统运行的关键元信息,如数据库、表、保留策略等。特定是一致性敏感,读写访问量不高,需要一定容错性。
节点数代表容错能力,一般3个即可,因为一般能够容忍一个节点故障即可。 - DATA节点:存放具体的时序数据,特点是:最终一致性、面向业务、性能越高越好,除了容错还要有水平扩展,拓展集群的读写能力
节点数代表了读写性能,在10个以内,越多越好。但太多会导致查询时延迟过大
如何实现META节点一致性
存放系统运行的关键元信息,需要实现CAP模型中的CP模型(如Raft算法)。防止DATA节点读不到最新信息导致相关时序数据写入失败。
如何实现DATA节点一致性
存放具体时序数据,对一致性要求不高,实现最终一致性即可。但因为时序数据量大,要满足水平拓展,选用AP模型。
自定义副本数
为了保证数据安全,需要冗余备份。可以通过 Quorum NWR 实现自定义副本数。通过调整参数可以实现强一致性。
Hinted-handoff
当节点接收到写请求时,要将数据转发一份到其他副本所在节点。这个过程中RPC可能失败。
在InfluxDB企业版中,Hinted-handoff实现:
- 写失败的请求缓存到磁盘
- 周期性尝试重传
- 相关参数可配置,如:缓存大小、缓存周期、尝试间隔
突发流量也会导致系统过载出现RPC失败,这时也需要 Hinted-handoff。当写请求数据大于缓存时数据仍可能丢失。需要反熵实现最终一致性。
反熵
时序数据就像日志数据,创建后不会修改。所以时序数据副本间不一致是因为数据写失败导致丢失,所以修复方式就是两两对比添加缺失数据。