1、自己准备一个数据量比较小的txt文件

然后将其上传到虚拟机本地:
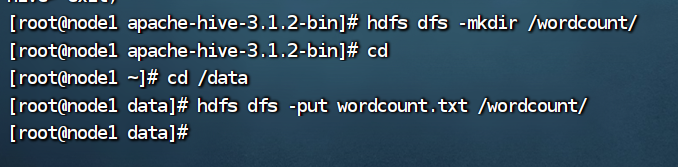
之后上传到hdfs里面:
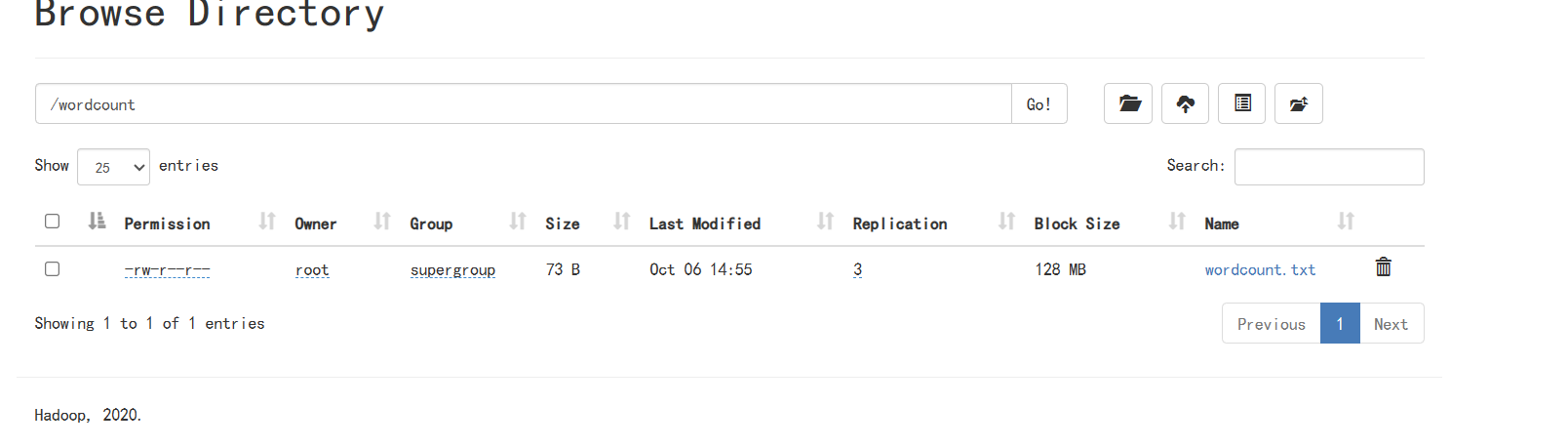
2、编写代码
1、引入相关依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.0</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
2、编写mapper类
package org.example;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable,Text,Text,LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text text=new Text();
LongWritable longWritable=new LongWritable();
String[] split=value.toString().split(",");
for(String word:split){
text.set(word);
longWritable.set(1);
context.write(text,longWritable);
}
}
}
3、编写reduce类
package org.example;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count=0;
for(LongWritable value:values){
count+=value.get();
}
context.write(key,new LongWritable(count));
}
}
4、编写主类代码
package org.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
//创建一个job任务对象
Job job=Job.getInstance(super.getConf(),"wordCount");
//指定文件读取的路径和对象
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node1:2181/wordcount"));
//指定map阶段的处理方式和数据类型
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//指定reduce阶段的处理方式和数据类型
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置输出类型
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("hdfs://node1:2181/wordcount"));
//等待任务结束
boolean b1=job.waitForCompletion(true);
return b1?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration=new Configuration();
//启动job任务
int run= ToolRunner.run(configuration,new JobMain(),args);
System.exit(run);
}
}
3、代码运行
1、进行代码打包
clean之后package:
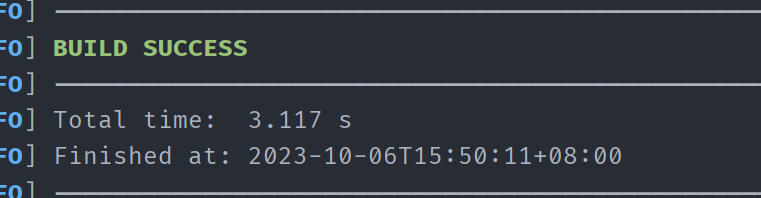
在target下面看到jar包啦:

将jar包上传到虚拟机本地:
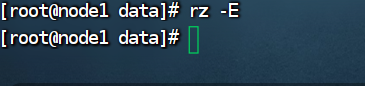
使用rz -E命令在本地查找jar包并上传;
然后使用hadoop命令进行使用:

hadoop jar testHadoop1006-1.0-SNAPSHOT.jar org.example.JobMain
然后运行即可;