项目框架
1.体会到了封装项目开发框架对于项目开发效率的重要性,如有字符串操作、xml操作,时间操作,目录和文件,日志文件,网络通讯,进程通讯,ftp客户端,数据库操作。
2.项目帮助文档提供了测试用例以及参数说明,先跑通,测试后进入主函数了解项目整体功能和架构,跟随日志顺着主函数流程理解子函数逻辑排查错误,手动打印排查,然后再详细研究每个子函数的代码逻辑,只关注关键部分代码和设计思想不研究太麻烦的小细节,遇到问题CSDN GPT GITHUB 经典书籍 老师的帮助。
3.项目文件分层:public开发框架数据库、网络编程、常用头文件、公共类、ftp库和测试demo,通用模块几乎包含,参数配置,二进制文件,源代码,idc包含项目启动sh等
4.这是一个通用的功能模块,通过配置脚本或者,实现功能
框架细节
- 封装细节:
-
字符串:最实用的如分割字符串文件、正则表达式匹配文件,解析xml字符串常用于解析参数或者带xml文件
-
文件: 支持格式化输出字符串常用于日志
-
时间: 字符串和整数的时间能够互相转换用于日志记录时间,简洁的定时器日志和守护进程心跳服务
-
日志:日志程序的运行时间,运行阶段的状态,处理数据的情况,很方便进行排查错误,多线程日志加锁,超过日志大小切换切换日志文件,日志文件命名,时间和文件相关名字拼接
-
网络通讯:封装了socket通讯的基本客户端服务端编写,输入必要的参数,简化了流程,粘包问题,有一个参数存放单次打算接受的数据,设置超时机制
-
文件目录:最主要的线程冲突,文件操作没有锁机制,根据生成临时文件并且改名的方式
-
进程通讯:信号量用于互斥锁和生产者消费者模型,进程心跳,把当前进程的信息加入共享内存进程组中,更新共享内存进程组中当前进程的心跳时间,超时时间释放
-
封装ftp:ftp使用github上现成的ftplib库进行个性定制保留项目需要的api,用户不需要特别安装ftp客户端,额外保存失败的原因记录到日志当中,能够额外将上传下载获取列表以文件的形式额外保存起来
-
封装oracle,orcale的oci库很麻烦,直接在网咯上找到大佬的oracle库封装一下就行了
-
- 怎么使用:注释详细,掌握使用方法和一些小细节,刚开始写的代码都忘干净了,并且框架迥异能实现效果就行,研究业务而不是沉迷于技术当中
- 可能询问:
-
xml:使用xml等上述框架是因为项目现成的 XML 解析模块无法满足。比如在将不同的数据转化成xml数据的时候现成的解析模块无法处理,处理大文件的时候性能不好,还有个性化要求。将网上的xml模块进行封装
-
刚开始不知道有这些框架,跟随开发东一点西一点,还有才知道有个freecplus类似,锻炼代码能力,另外你招我进去不就是要求我写业务吗?
-
粘包怎么解决:分隔符:发送方在每个数据包之间加入特定的分隔符,比如换行符或者其他特殊字符。接收方根据分隔符来切分数据包,确保每个数据包都能正确解析。
-
文件传输大模块
ftp分为下载和上传
已知服务器的文件路径名和保存到本地的文件路径名,在知道远程服务器的ip端口和ftp用户名密码的情况下,把服务器上某个目录的文件全部下载到本地目录(可以指定文件名匹配规则)。文件下载成功后,服务器可以选择备份或者删除文件,支持增量传输的功能,可以通过配置脚本文件通过xml转换成参数实现文件上传和下载的功能。使用容器来保存下载过的文件和新增的文件。
上传和下载模块功能类似
为什么使用ftp协议:创建服务容易,适合在内部网络进行文件传输,比如我们的校园网,但真要效率、数据安全、防火墙还得tcp;
tcp分为下载和上传
已知服务器的文件路径名和保存到本地的文件路径名,在知道远程服务器的ip端口和ftp用户名密码的情况下,把服务器上某个目录的文件全部下载到本地目录(可以指定文件名匹配规则)。文件下载成功后,服务器可以选择备份或者删除文件,支持增量传输的功能,可以通过配置脚本文件通过xml转换成参数实现文件上传和下载的功能。使用容器来保存下载过的文件和新增的文件。这一部分和前面一样,
效率高。
心跳机制:通过定时发送心跳包来保持连接的活跃状态,如果一段时间内没有收到心跳包,可以断开连接。来保持长链接
tcp的文件传输服务端模块需要自己写,tcp的通讯协议可以自己定义,符合socket标准就行
登录报文请求,打开文件目录获取清单,文件名文件大小文件时间给服务端,服务端模式选择解析请求报文的内容,成功接收然后拼接+确认,每次规定发送文件的大小防止粘包,本质也是互相反过来就可以了把标志位给为下载位就可以了,通过epoll实现异步通讯,
数据核心模块
数据服务总线
1.业务系统使用SQL直连数据中心的应用数据库,可以任意访问数据,适合政府
2.业务系统使用HTTP协议在浏览器输入url获取数据中心的应用数据库的数据,适合公众
请求方法只用到了GET,hhtps加密更加安全,在浏览器url旁边会显示一把锁,因为前者麻烦所以使用了http
使用c++模拟实现http的三种方式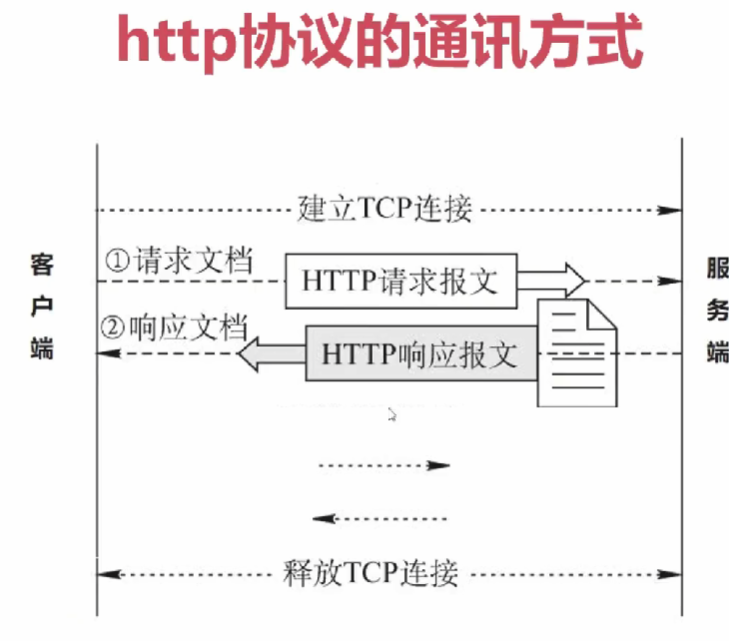 使用长链接一问一答的方式字段:值connection:kepp-alive保持活跃
使用长链接一问一答的方式字段:值connection:kepp-alive保持活跃
右键网页查看源代码也可以查看响应报文的内容只不过没有状态行需要在network里面看
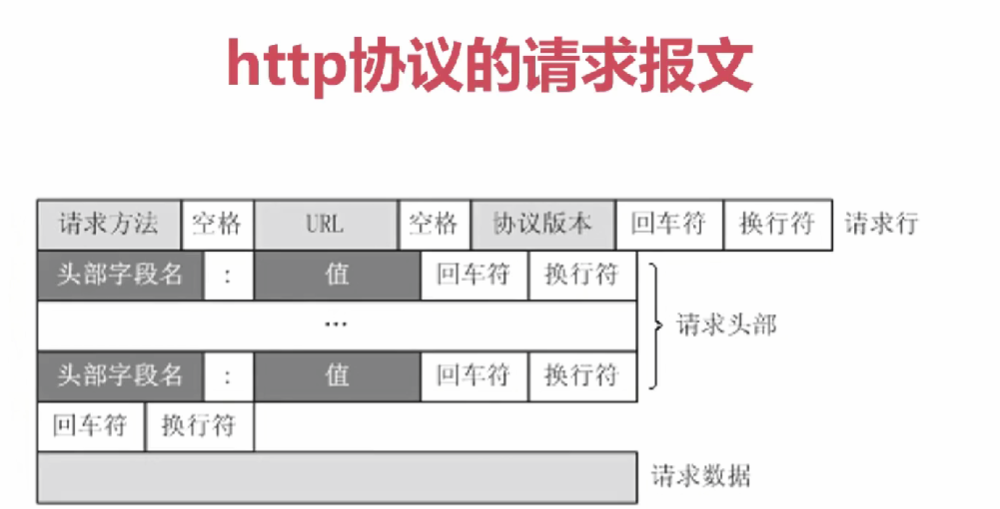 请求的内容按固定格式拼接成字符串
请求的内容按固定格式拼接成字符串
检测请求报文的字符串格式:在虚拟机上运行一个常见的scoekt程序绑定端口,接受的报文打印到控制台,在浏览器url上输入ip和端口
get / 根目录,host必填,端口缺省80小心占用,url?前html表面来源页,后面&间隔表示参数,参数值格式可以自己定义,模拟标准的
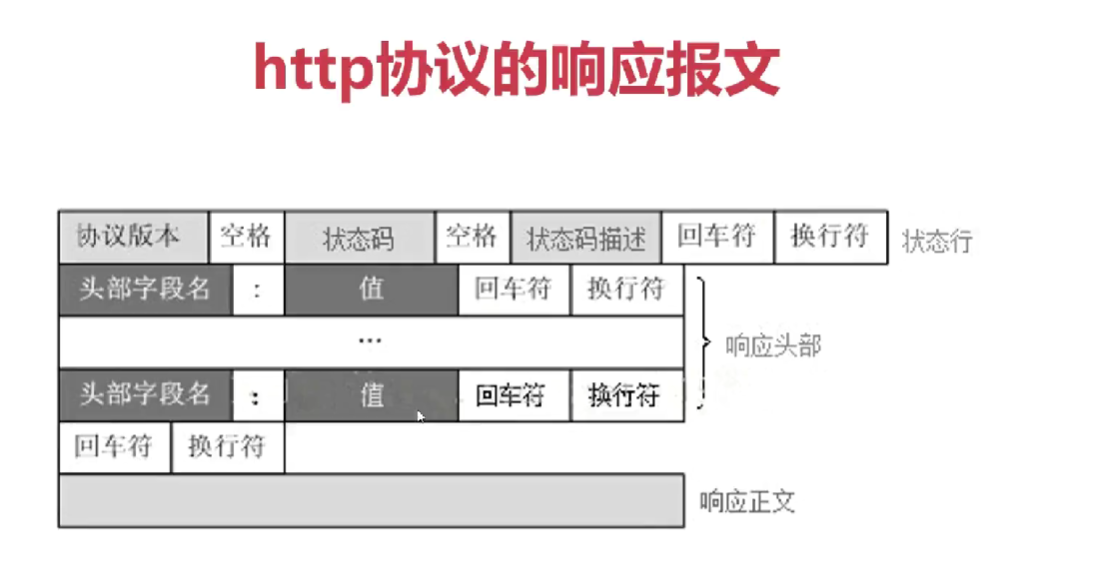
写一个最简单的客户端程序模拟浏览器,模拟像知乎发送一个格式标准的请求报文,注意报文里面的回车符和换行符,然后将相应报文打印到控制台上,网页内容太多的时候需要while读完不然只会读取一部分,输出的html文件对比观察学习
相应报文的重点是状态码,和相应报文的长度Content-Length可以判断相应是否结束还是分块传输
接受浏览器请求,发送准备好的相应文件。接受连接请求,生成相应报文固定状态行,报文长度用文件参数填充,发送相应报文后,再发送文件,限制每次发送文件buffer片段的长度
c++开发网页很麻烦,但是后端发送并且生成csv json这些文件效率最高,有socket
简易的数据访问接口,接收http请求,解析请求参数,从Oracle的T_ZHOBTMIND1表中查询数据,返回给客户端
接口参数一般是:http,ip地址和端口、用户名和密码(数据库)、接口名(哪个表)、接口参数(具体字段主键站点编号、起始时间和截止时间)
接受请求报文 把相应报文发送给客户端 解析请求报文参数从表中查询数据返回在客户端,解析请求报文长度主要是依次查找参数名的位置然后阶段存放在字符串当中
然后使用封装的oracle连接数据库,连接前检测url是否合法
数据抽取模块
将数据库连接和事务操作封和SQL语句封装成类。通用操作,登录数据库,连接数据库对象,准备SQL语句,绑定参数,放到结果集中,执行提交事务,错误信息会存储在对象中可以打印
SQL注入:
在使用动态表绑定数据库查询参数时,参数值是以变量形式传递给查询语句的,而不是直接拼接到查询语句中。这种方式可以避免SQL注入攻击,因为参数值不会被解释为SQL代码,而是被视为数据。
需要在oracle创建全国气象站点参数表和气象观测数据表
用于从数据源的数据库中抽取数据的结果集字段一条条改变前后缀,生成xml文件,按查询条件抽取表中全部数据全量抽取和按查询条件抽取表中新增数据增量抽取(每次只抽取新增的数据)
增量抽取:从文件或数据库中获取上次已抽取数掉的增量字段的最大值绑定输入变量 (已抽取数据的增量字段的最大值)获取结果集的时候,要把增量字段的最大值保存在临时变量中,推取完数据之后,把增量字段的最大值保存在文件或数据库中。xml文件将用于入库,如果文件太大,数据库会产生大事务。
根据数据量做到增删改查,不要删除,大表会数据库引擎可能需要重新组织数据存储,索引维护,事务日志和回滚段,数据一致性,只修改。
数据入库模块
把从各政府部门抽取出来的xml 文件入库到共享平台的数据库中。 数据集有几千种,为每种数据写一个入库程序吗?
配置入库参数xml文件,入库的xml文件名和表名等正则表达式匹配规则,并且设置更新规则
数据字典是一个记录了数据集中各种数据元素,列出了数据集中所有的数据项,比如字段名、变量名
步骤
查找入库参数,根据待入库的文件名,得到对应的表名
根据表名,读取数据字典,得到表的字段名和主键
根据表的字段名和主键,拼接插入和更新的SQL语句
执行插入或更新的SQL语句
可实现通用的模块
数据处理模块
将不同格式的文本转换成xml格式再交给入库程序使用,这里使用了github的开源,数据源文件的格式千奇百怪,所以,数据处理模块由若干个小模块组成,每个小模块负责处理一种格式的文件
数据管理模块
当前数据重要,表过大查询和插入性能会下降,迁移备份不方便,历史数据不需要保留或者单独保存到表当中,一次性删除或者迁移数据会产生大事务,执行前计数要删除或者迁移的条数,每次执行递增,只操作一部分。
根据主键从删除表查询需要删除的记录然后执行sql批量删除。
从原表获取数据插入到目的表,批量插入表,从迁移表删除记录,这里的逻辑很简单只需要使用最简单
数据同步模块(重要)
单点故障,服务器或者软硬件出现错误,虽然有守护进程和调度程序,但是硬盘内存故障,虚拟机故障,网络出现问题
oracle自带RAC,一个数据库多个实例,在配置文件设置,性能瓶颈在数据库的IO,而不在节点那么多。RAC要求至少两台高性能服务器,或者自带存储设备太贵了自带容错没有单点故障,实例之间协调损耗性能,只能做到高可用。
oracle的DATAGuard太贵了,OGG也是,可以在不同的数据库产品之间复制数据,可以在不同结构的表之间复制数据。可以指定复制数据的条件。
通过oracle之间建立dblink数据库连接可以实现数据同步,主从机,
数据入库放到核心库,其他业务库分类历史库 接口库多个实例数据同步
数据库链接自己模拟效果
刷新同步模块
创建两个表来模拟,表要求结构一致
对于没有建立数据库链路的程序,先数据抽取再数据处理再数据入库
针对需要覆盖本地表的情况,开发了刷新同步模块,删除本地表中的数据把,根据判断条件主键中满足where条件的记录插入到本地表中
从远程表中查找需要同步记录的key字段的值,达到一定数量(maxcount) 执行delete和insert语句
增量同步模块
数据同步模块的应用场景
不分批刷新适用于数据量较小的表,可同步插入、修改和删除操作。
分批刷新适用于数据量较大的表,可同步插入、修改操作。
增量同步适用于数据量很大,表中数据只插入,没有修改和删除。
从本地表查询已经同步记录的最大id每次保存在数据库当中,从远程表中查询需要同步的记录,再把记录分批插入
与刷新同步中的分批同步类似,这里select中需要查找本地最大的id从远程收集比这个id更大的数据加入delete和select参数
总结





上述思路很重要

通用模块
服务程序的调度模块
周期性启动服务程序或shell脚本运行在后台,生成fork()子进程,父进程退出 子进程中再fork一个字进程,子进程使用execv(argv[2], pargv);真正后台程序代替这个子进程,父进程等待子进程终止,wait()函数会阻塞,直到被调度的程序终止,休眠timetvl秒,然后回到循环
检查后台服务程序模块
用于检查后台服务程序是否超时,如果已经超时,就终止它,
创建/获取共享内存,将共享内存连接到当前进程的地址空间,获取当前时间ti,这里有一个心跳模块被封装记录了时间,判断进程的心跳是否超时,如果超时了,就终止它把共享内存从当前进程中分离。
压缩清理模块
把文件的时间与历史文件的时间点比较,如果更早,就需要函数遍历目录和子目录中的文件然后删除,调用操作系统的gzip,删除文件调用REMOVE
问题
为什么使用oracle
Oracle VS MySQL
MySQL: 免费,性能、安全性较低,适用于不重要的、数据量小 (单表记录数不超过一百万) 的项目。
Oracle: 收费,性能卓越,安全可靠,适用于重要的、数据量大 (单表记录数几十亿) 的项目。
Oracle VS MySQL
互联网公司:数据库以MySQL为主,免费是关键,性能(可用redis 代替) 和安全性 (用分布式解决) 不是重点。钱存放在Oracle中。
传统行业:数据库以Oracle为主,不重要并且数据量小的项目才用 MySQL。
✓ 互联网大厂VS 中小公司,程序员的占比如何?