分布式事务
分布式事务是什么
分布式事务是一种在分布式系统中确保数据一致性的机制。在分布式系统中,数据通常被存储在多个节点上,每个节点都可以独立地执行事务操作。分布式事务需要保证所有节点在执行事务期间的数据操作是一致的,即要么所有节点都成功地执行了事务,要么所有节点都没有执行事务。
分布式事务通常采用两阶段提交(Two-Phase Commit)协议来实现。在两阶段提交协议中,有一个协调者节点和多个参与者节点。协调者负责协调所有参与者节点的事务操作,以保证所有节点的数据操作的一致性。协议的第一阶段是准备阶段,协调者会向所有参与者节点发送准备请求,并等待它们的准备反馈。如果所有参与者节点都准备好执行事务,则进入第二阶段,协调者发送提交请求,参与者执行事务提交操作。如果任何一个参与者节点无法准备好或者出现错误,协调者发送中止请求,参与者执行事务回滚操作。
分布式事务的实现可以使用不同的技术,例如数据库的分布式事务支持,消息队列等。分布式事务可以确保数据的一致性和可靠性,但也会引入一定的性能开销和复杂性。在设计分布式系统时,需要权衡数据一致性和性能等因素,选择合适的分布式事务方案。
事务特性

- 原子性(Atomicity):原子性是指事务中的所有操作要么全部执行成功,要么全部回滚到事务开始之前的状态,没有中间状态。这确保了事务要么完全成功,要么完全失败,不会出现部分操作成功的情况。在分布式事务中,保证原子性需要使用协调协议,如两阶段提交协议。
- 一致性(Consistency):一致性是指事务执行前后数据的完整性和一致性得到保证。事务执行过程中,数据库的数据必须符合定义的约束和规则,以及事务中的业务逻辑。如果一个事务违反了约束或规则,数据库将回滚到事务开始之前的状态,以保证数据的一致性。
- 隔离性(Isolation):隔离性指的是事务的执行在逻辑上互相隔离,即一个事务的操作不会干扰到其他事务的操作。事务在隔离级别下执行,可以控制事务之间的相互影响,例如读未提交、读已提交、可重复读和串行化等级别。隔离性旨在解决并发事务引起的问题,如脏读、不可重复读和幻读。
- 持久性(Durability):持久性是指事务提交后,其对数据库的修改是永久性的,即使系统发生故障或崩溃,修改的数据也会被保留。持久性通过将事务的日志写入磁盘或者其他非易失性存储介质来实现。一旦事务提交,对应的日志就会被持久化,以确保数据的持久性。
这四个特性代表了传统数据库事务的ACID特性
在分布式事务中,这四个特性同样适用,但是实现它们更具挑战性。分布式事务涉及多个节点和网络通信,需要使用协调机制来保证原子性和一致性。隔离性可以通过不同的隔离级别来实现,但需要考虑到跨节点的并发操作。持久性需要确保在分布式环境中日志的持久化,以防止节点故障导致数据的丢失。
总结起来,原子性、一致性、隔离性和持久性是传统数据库事务的关键特性,在分布式事务中也同样重要。但在分布式环境下,实现这些特性需要考虑到节点间通信、并发操作、故障恢复等因素,增加了分布式事务的复杂性。
分布式事务对比传统事务的区别
-
事务类型:
- 传统事务:传统事务通常是刚性的,即所有相关操作要么全部成功,要么全部失败。在传统数据库中,事务的操作是在同一数据库实例上进行的。
- 分布式事务:分布式事务可以是刚性的,也可以是柔性的。柔性事务允许部分成功,在分布式系统中,可能涉及到多个独立的节点或数据库,每个节点都可以独立地执行事务操作。
-
时间要求:
- 传统事务:传统事务通常要求立刻响应,即事务操作的响应时间很短,通常在毫秒级别。
- 分布式事务:分布式事务的时间要求相对较为弹性,可以容忍更长的响应时间。由于涉及到网络通信和多个节点之间的协调,分布式事务的响应时间可能在几十毫秒到几秒甚至更长。
-
一致性要求:
- 传统事务:传统事务通常要求强一致性,即事务执行过程中的数据始终保持一致状态,不会出现矛盾或冲突。
- 分布式事务:分布式事务的一致性要求相对较为灵活。可以选择强一致性,即所有节点在事务处理期间的数据始终保持一致,或者选择最终一致性,即允许在一定时间段内存在数据的不一致状态,但最终会达到一致性状态。
综上所述,分布式事务与传统事务在事务类型、时间要求和一致性要求等方面存在一些区别。分布式事务允许柔性事务和更弹性的响应时间,同时具备强一致性或最终一致性的选择。这些差异使得分布式事务在处理分布式系统中的数据操作和协调方面更加复杂,需要使用特定的协议和机制来实现数据的一致性和可靠性。
CAP理论和BASE理论
分布式事务与传统事务产生区别的原因可以通过 CAP 理论(Consistency、Availability、Partition tolerance)和 BASE 理论(Basically Available, Soft state, Eventually consistent)来解释。
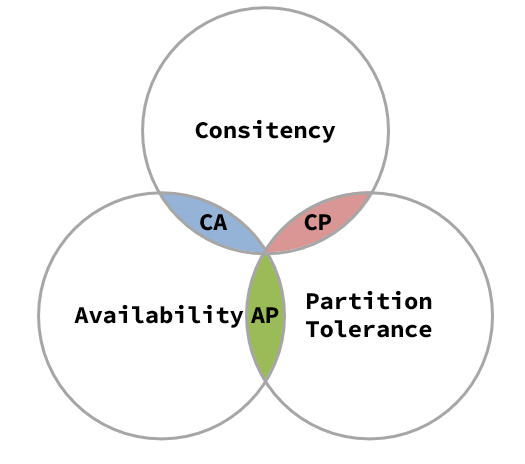
CAP 理论:
Consistency(一致性):传统事务追求强一致性,即在事务执行期间保证数据一致性。而在分布式系统中,由于网络分区、节点故障等因素,无法保证在分区故障时实现强一致性。
Availability(可用性):传统事务通常追求高可用性,即系统始终能够对外提供服务。然而,在分布式系统中,当网络分区或节点故障时,无法保证全局的高可用性,可能需要在设计中做出妥协。
Partition tolerance(分区容错性):分布式系统必须具备分区容错性,即能够在面对网络分区时继续正常工作。这是分布式系统在可靠性和可扩展性方面的特点。
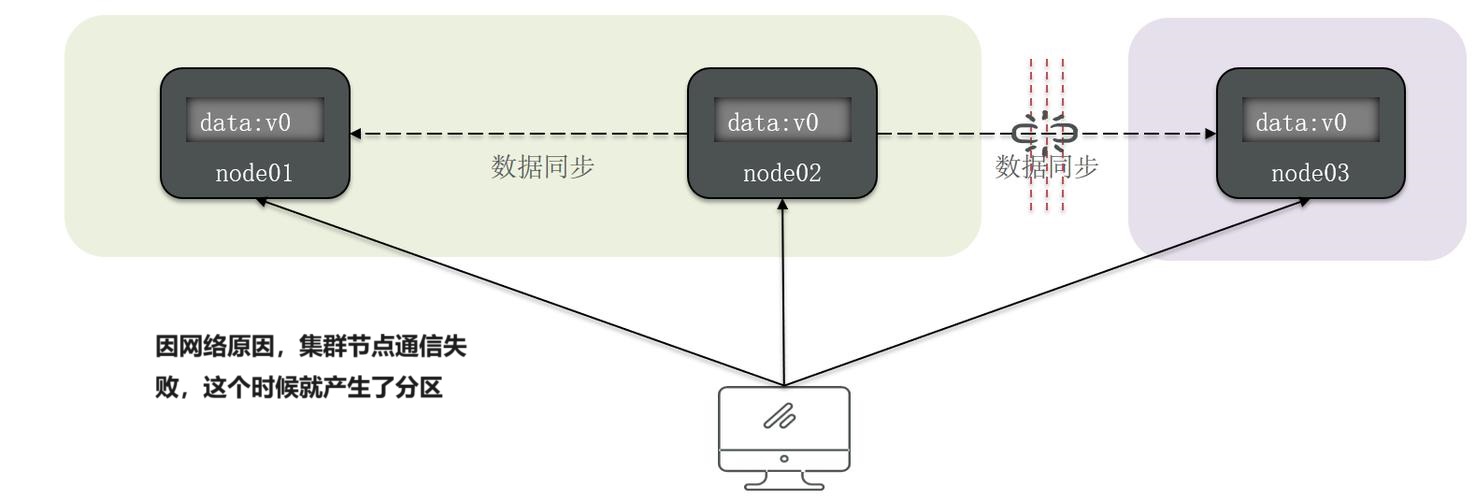
因此,由于 CAP 理论的限制,分布式事务与传统事务在一致性、可用性和分区容错性上产生了区别。传统事务强调一致性和可用性之间的折中,而分布式事务需要在强一致性和可用性之间进行权衡。
-
BASE 理论:
- Basically Available(基本可用性):分布式系统在面对故障或分区时,仍然可以部分正常工作,提供基本的服务响应。这与传统事务追求的立即响应和高可用性有所不同。
- Soft state(软状态):分布式系统允许在一段时间内存在数据的不一致状态,即允许暂时的数据部分更新,而不要求立即同步一致。
- Eventually consistent(最终一致性):分布式系统在一定时间内,通过协调和同步,最终达到全局数据的一致性。这与传统事务强一致性的要求有所不同。
BASE 理论强调在分布式系统中可能存在的局部不一致性和延迟一致性,以提供更高的可用性和性能。与传统事务相比,分布式事务相对更关注基本可用性和最终一致性,可以在一定程度上容忍数据的暂时不一致,以优化系统的伸缩性和可靠性。
综上所述,CAP 理论和 BASE 理论解释了分布式事务与传统事务产生区别的原因。分布式事务需要在一致性、可用性和分区容错性之间进行权衡,以达到基本可用性和最终一致性的目标。而传统事务则追求强一致性和立即响应的特点。
分布式事务的解决思路
-
AP模式
-
最终一致性
-
各子事务分别执行和提交,允许出现结果不一致,然后采用弥补措施恢复数据即可,实现最终一致。
- 譬如:增加了一条数据,后面有操作失败了,那么,补偿措施只需要把增加的那条数据删除即可
- 因为子事务提交了,那么提交后的状态是一个中间状态,也就是软状态
-
-
CP模式
-
强一致性
-
各个子事务执行后互相等待,同时提交,同时回滚,达成强一致。但事务等待过程中,处于弱可用状态。
- 事务执行过程中,会锁定操作的资源,那么这个资源暂时是不可用的。所以整个系统是基本可用
-
-
子事务
- 分支事务
-
全局事务
- 事务协调者,用来监控和通知各个分支事务
分布式事务解决方案
在分布式系统中,有多种解决方案来处理分布式事务的一致性问题。以下是几种常见的分布式事务解决方案:
- 两阶段提交(Two-Phase Commit,2PC):2PC 是一种同步的分布式事务协议,通过协调者(Coordinator)和参与者(Participant)之间的协作来实现事务的一致性。在2PC中,协调者先向所有参与者发送准备请求,并等待所有参与者的回复。如果所有参与者都反馈可以提交,则协调者发送提交请求,否则发送中止请求。
- 三阶段提交(Atomic Commit Protocol,3PC):3PC 根据2PC的基本思想,在其中增加超时机制和可以恢复的准备阶段,以减少二阶段提交中可能出现的资源一直被占用的问题。
- 补偿事务(Compensating Transaction):补偿事务是一种异步的解决方案,用于处理分布式事务的回滚操作。它通过在事务的每个参与者上定义补偿操作,当事务失败或回滚时,通过执行逆操作来恢复到先前的状态。
- 消息队列(Message Queue):使用消息队列来实现分布式事务中的异步提交和通知机制。事务操作被发送到消息队列,并由消费者异步处理。如果事务成功,消费者完成进一步的业务操作,否则可以回滚或执行补偿操作。
- Saga 模式(Saga Pattern):Saga 是一种长时间运行的分布式事务协议,将长事务拆分为一系列较小的、局部事务(Compensating Transaction)组成的序列。每个局部事务都有正常和补偿两个操作,以保证全局事务的一致性。
- 分布式数据库:使用支持分布式事务的分布式数据库,如Google Spanner、TiDB、CockroachDB等。这些数据库提供了内置的分布式事务支持,可以通过统一的 SQL 接口管理和操作分布式事务。
Seata
Seata(Simple Extensible Autonomous Transaction Architecture)是一种开源的分布式事务解决方案。它旨在解决分布式系统中的事务一致性问题,提供高性能和可靠性的分布式事务支持。
Seata提供了一套完整的事务处理机制,其中包括三个核心组件:
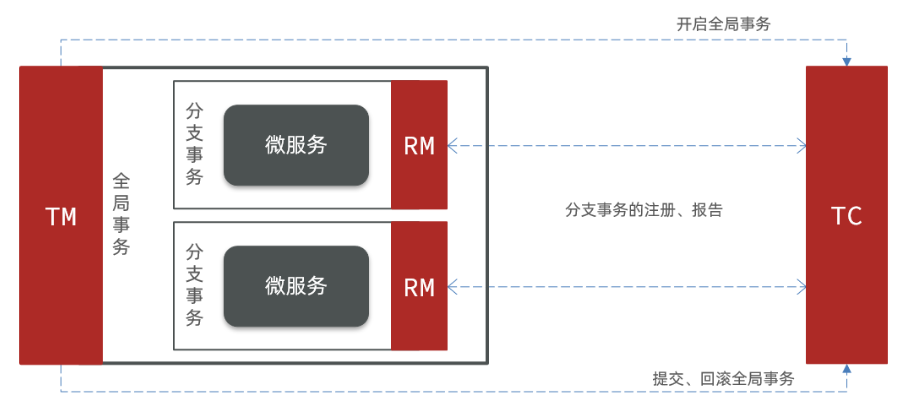
- Transaction Coordinator(TC,事务协调器):负责全局事务的协调和控制,协调参与者的事务操作,保证全局事务的一致性。TC将事务划分为全局事务和分支事务,并通过事务上下文(TransactionContext)进行管理和传递。
- Resource Manager(RM,资源管理器):负责本地事务的管理和提交。RM与具体的业务数据库或其他资源进行交互,参与本地事务的执行,并将事务操作的结果报告给TC。
- Transaction Manager(TM,事务管理器):提供了全局事务的生命周期管理功能,协调TC和RM之间的交互,保证分布式事务的正确执行。TM负责事务的开启、提交、回滚等操作,并与TC和RM进行通信协调。
Seata还提供了一些其他的特性和功能,包括:
- 分布式事务的并发控制:通过各个RM向TC上报锁信息,实现对全局事务的并发控制,避免冲突和资源竞争。
- 多种存储模式:支持使用关系型数据库或其他类型的存储介质来存储事务数据和日志。
- 分布式事务的回滚和补偿机制:用于处理事务中的异常情况和故障恢复。
- 客户端透明的API支持:Seata提供了各种编程语言的客户端库,方便开发人员在应用程序中使用分布式事务。
使用Seata可以解决分布式系统中的事务一致性问题,提供了高性能和可靠性的分布式事务支持。它是一个灵活、可扩展的解决方案,可以与现有应用程序集成,并通过配置简化分布式事务的管理和控制。
seata支持模式
在 Seata 中,主要有以下几种模式:
- AT 模式(Automatic Transaction Mode):AT 模式是 Seata 默认采用的模式,也是最常用的模式。在 AT 模式下,Seata 通过对业务代码进行无侵入的注解方式,自动实现分布式事务的管理。当业务代码执行时,Seata 将根据注解信息自动生成事务上下文,并通过拦截器的方式在参与者(RM)和协调者(TC)之间实现事务的协调和一致性控制。
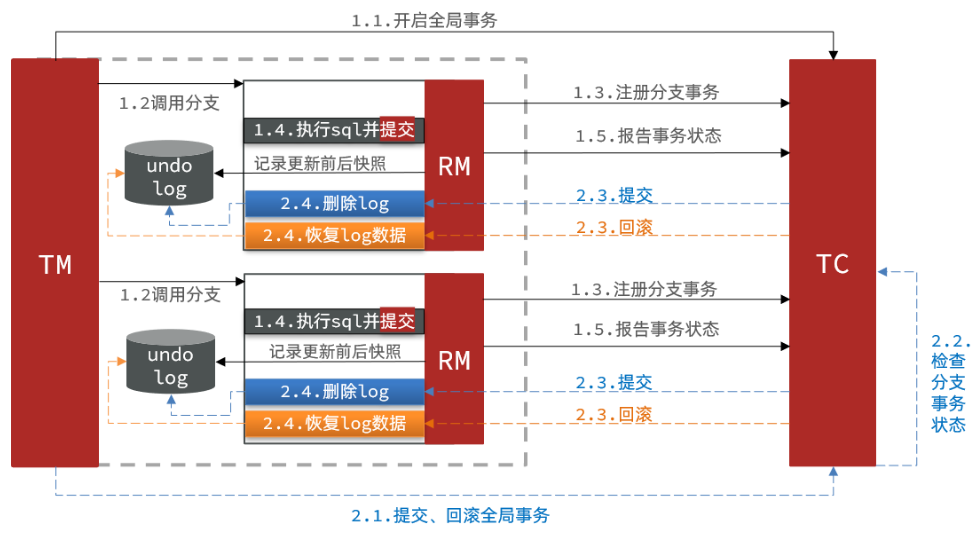
- TCC 模式(Try-Confirm-Cancel Mode):TCC 模式是一种基于补偿的分布式事务模式。在 TCC 模式中,业务功能被拆分为 Try、Confirm 和 Cancel 三个阶段。在 Try 阶段,尝试执行业务操作前,先执行预留资源的操作;在 Confirm 阶段,确认所有业务操作都成功执行;在 Cancel 阶段,回滚所有业务操作。TCC 模式对业务代码有一定的要求,需要用户明确定义 Try、Confirm 和 Cancel 方法。
- SAGA 模式(Saga Mode):SAGA 模式是一种长事务解决方案,通过拆分长事务为多个局部事务,并通过补偿操作实现全局事务的一致性。SAGA 模式由一系列相互关联的局部事务组成,每个局部事务都有正向操作和补偿操作。当某个局部事务失败时,可以通过补偿操作执行撤销或回滚。Seata 的 Saga 模式提供了编程方式和注解方式两种使用方式。
- XA 模式(eXtended Architecture Mode):XA 模式是一种基于 XA 协议的分布式事务模式。在 XA 模式下,Seata 作为一个 XA 事务管理器(TM)与 RM 通过 XA 接口进行事务协调和控制。XA 模式要求数据源(数据库)支持 XA 事务,需要在业务代码中显式地调用事务管理相关的方法。

这些模式在 Seata 中提供了不同的分布式事务解决方案,其中AT模式是Seata默认支持的模式,也可以根据具体的业务需求选择合适的模式来实现分布式事务的管理和控制。
转载于https://juejin.cn/post/7283102575070691382