- @告诉make在运行时不要回显要输出的配方。
- -告诉make忽略配方的返回值
虽然cmake已经很成熟了,但是make和Ninja(pg 16采用Ninja而不是cmake)仍然广泛在使用中,并且相比cmake,make更加的透明。可以说掌握makefile是linux下开发从入门到进阶第一步。
#------------------------------------------------------------------------- # # Makefile for backend/utils # # Portions Copyright (c) 1996-2020, PostgreSQL Global Development Group # Portions Copyright (c) 1994, Regents of the University of California # # src/backend/utils/Makefile # #------------------------------------------------------------------------- subdir = src/backend/utils top_builddir = ../../.. include $(top_builddir)/src/Makefile.global OBJS = fmgrtab.o SUBDIRS = adt cache error fmgr hash init mb misc mmgr resowner sort time # location of Catalog.pm catalogdir = $(top_srcdir)/src/backend/catalog include $(top_srcdir)/src/backend/common.mk all: distprep probes.h generated-header-symlinks distprep: fmgr-stamp errcodes.h .PHONY: generated-header-symlinks generated-header-symlinks: $(top_builddir)/src/include/utils/header-stamp $(top_builddir)/src/include/utils/probes.h $(SUBDIRS:%=%-recursive): fmgr-stamp errcodes.h # fmgr-stamp records the last time we ran Gen_fmgrtab.pl. We don't rely on # the timestamps of the individual output files, because the Perl script # won't update them if they didn't change (to avoid unnecessary recompiles). fmgr-stamp: Gen_fmgrtab.pl $(catalogdir)/Catalog.pm $(top_srcdir)/src/include/catalog/pg_proc.dat $(top_srcdir)/src/include/access/transam.h $(PERL) -I $(catalogdir) $< --include-path=$(top_srcdir)/src/include/ $(top_srcdir)/src/include/catalog/pg_proc.dat touch $@ errcodes.h: $(top_srcdir)/src/backend/utils/errcodes.txt generate-errcodes.pl $(PERL) $(srcdir)/generate-errcodes.pl $< > $@ ifneq ($(enable_dtrace), yes) probes.h: Gen_dummy_probes.sed endif # We editorialize on dtrace's output to the extent of changing the macro # names (from POSTGRESQL_foo to TRACE_POSTGRESQL_foo) and changing any # "char *" arguments to "const char *". probes.h: probes.d ifeq ($(enable_dtrace), yes) $(DTRACE) -C -h -s $< -o $@.tmp sed -e 's/POSTGRESQL_/TRACE_POSTGRESQL_/g' \ -e 's/( *char \*/(const char */g' \ -e 's/, *char \*/, const char */g' $@.tmp >$@ rm $@.tmp else sed -f $(srcdir)/Gen_dummy_probes.sed $< >$@ endif # These generated headers must be symlinked into builddir/src/include/, # using absolute links for the reasons explained in src/backend/Makefile. # We use header-stamp to record that we've done this because the symlinks # themselves may appear older than fmgr-stamp. $(top_builddir)/src/include/utils/header-stamp: fmgr-stamp errcodes.h prereqdir=`cd '$(dir $<)' >/dev/null && pwd` && \ cd '$(dir $@)' && for file in fmgroids.h fmgrprotos.h errcodes.h; do \ rm -f $$file && $(LN_S) "$$prereqdir/$$file" . ; \ done touch $@ # probes.h is handled differently because it's not in the distribution tarball. $(top_builddir)/src/include/utils/probes.h: probes.h cd '$(dir $@)' && rm -f $(notdir $@) && \ $(LN_S) "../../../$(subdir)/probes.h" . .PHONY: install-data install-data: errcodes.txt installdirs $(INSTALL_DATA) $(srcdir)/errcodes.txt '$(DESTDIR)$(datadir)/errcodes.txt' installdirs: $(MKDIR_P) '$(DESTDIR)$(datadir)' .PHONY: uninstall-data uninstall-data: rm -f $(addprefix '$(DESTDIR)$(datadir)'/, errcodes.txt) # fmgroids.h, fmgrprotos.h, fmgrtab.c, fmgr-stamp, and errcodes.h are in the # distribution tarball, so they are not cleaned here. clean: rm -f probes.h maintainer-clean: clean rm -f fmgroids.h fmgrprotos.h fmgrtab.c fmgr-stamp errcodes.h
$(call recurse,clean)
在任何稍微复杂一点的c/c++应用中,Makefile(M大写)几乎是必不可少的(除非采用cmake工程),它可以用来帮助自动化的判断哪些源程序需要重新编译。典型的应用通常是这样的:
make程序有很多版本的实现,通常使用最广泛的是GNU make,它在linux下是标准make实现,目前主要版本是3和4,可以通过make --version查看版本。
[root@lightdb1 ~]# make --version GNU Make 3.82 Built for x86_64-redhat-linux-gnu Copyright (C) 2010 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law.
一般configure以及三方构建对make版本没有要求(cmake、gcc则有版本要求居多)。
注:在大型系统中,Makefile通常不是完全人工硬编码,而是通过automake基于configure机制从模板文件创建。
configure
对于开源库和稍微复杂一点的系统,configure通常是采用源码分发执行的第一个步骤。大到postgresql、小至sysbench,通常都执行./configure检查依赖项目,并打印出每一项的符合情况,然后生成make所需的最终Makefile。
$ ./configure
The above command makes the shell run the script named configure which exists in the current directory.
The configure script basically consists of many lines which are used to check some details about the machine on which the software is going to be installed. This script checks for lots of dependencies on your system. For the particular software to work properly, it may be requiring a lot of things to be existing on your machine already.
When you run the configure script you would see a lot of output on the screen , each being some sort of question and a respective yes/no as the reply. If any of the major requirements are missing on your system, the configure script would exit and you cannot proceed with the installation, until you get those required things. ./configure may fail if it finds that dependencies are missing.
The main job of the configure script is to create a Makefile. This is a very important file for the installation process. Depending on the results of the tests (checks) that the configure script performed it would write down the various steps that need to be taken (while compiling the software) in the file named Makefile.
[zjh@hs-10-20-30-193 lightdb13.3-21.1]$ ./configure --help `configure' configures PostgreSQL 13.3 to adapt to many kinds of systems. Usage: ./configure [OPTION]... [VAR=VALUE]... To assign environment variables (e.g., CC, CFLAGS...), specify them as VAR=VALUE. See below for descriptions of some of the useful variables. Defaults for the options are specified in brackets. Configuration: -h, --help display this help and exit --help=short display options specific to this package --help=recursive display the short help of all the included packages -V, --version display version information and exit -q, --quiet, --silent do not print `checking ...' messages --cache-file=FILE cache test results in FILE [disabled] -C, --config-cache alias for `--cache-file=config.cache' -n, --no-create do not create output files --srcdir=DIR find the sources in DIR [configure dir or `..'] Installation directories: --prefix=PREFIX install architecture-independent files in PREFIX [/usr/local/pgsql] --exec-prefix=EPREFIX install architecture-dependent files in EPREFIX [PREFIX] By default, `make install' will install all the files in `/usr/local/pgsql/bin', `/usr/local/pgsql/lib' etc. You can specify an installation prefix other than `/usr/local/pgsql' using `--prefix', for instance `--prefix=$HOME'. For better control, use the options below. Fine tuning of the installation directories: --bindir=DIR user executables [EPREFIX/bin] --sbindir=DIR system admin executables [EPREFIX/sbin] --libexecdir=DIR program executables [EPREFIX/libexec] --sysconfdir=DIR read-only single-machine data [PREFIX/etc] --sharedstatedir=DIR modifiable architecture-independent data [PREFIX/com] --localstatedir=DIR modifiable single-machine data [PREFIX/var] --libdir=DIR object code libraries [EPREFIX/lib] --includedir=DIR C header files [PREFIX/include] --oldincludedir=DIR C header files for non-gcc [/usr/include] --datarootdir=DIR read-only arch.-independent data root [PREFIX/share] --datadir=DIR read-only architecture-independent data [DATAROOTDIR] --infodir=DIR info documentation [DATAROOTDIR/info] --localedir=DIR locale-dependent data [DATAROOTDIR/locale] --mandir=DIR man documentation [DATAROOTDIR/man] --docdir=DIR documentation root [DATAROOTDIR/doc/postgresql] --htmldir=DIR html documentation [DOCDIR] --dvidir=DIR dvi documentation [DOCDIR] --pdfdir=DIR pdf documentation [DOCDIR] --psdir=DIR ps documentation [DOCDIR] System types: --build=BUILD configure for building on BUILD [guessed] --host=HOST cross-compile to build programs to run on HOST [BUILD] Optional Features: --disable-option-checking ignore unrecognized --enable/--with options --disable-FEATURE do not include FEATURE (same as --enable-FEATURE=no) --enable-FEATURE[=ARG] include FEATURE [ARG=yes] --disable-integer-datetimes obsolete option, no longer supported --enable-nls[=LANGUAGES] enable Native Language Support --disable-rpath do not embed shared library search path in executables --disable-spinlocks do not use spinlocks --disable-atomics do not use atomic operations --enable-debug build with debugging symbols (-g) --enable-profiling build with profiling enabled --enable-coverage build with coverage testing instrumentation --enable-dtrace build with DTrace support --enable-tap-tests enable TAP tests (requires Perl and IPC::Run) --enable-depend turn on automatic dependency tracking --enable-cassert enable assertion checks (for debugging) --disable-thread-safety disable thread-safety in client libraries --disable-largefile omit support for large files Optional Packages: --with-PACKAGE[=ARG] use PACKAGE [ARG=yes] --without-PACKAGE do not use PACKAGE (same as --with-PACKAGE=no) --with-extra-version=STRING append STRING to version --with-template=NAME override operating system template --with-includes=DIRS look for additional header files in DIRS --with-libraries=DIRS look for additional libraries in DIRS --with-libs=DIRS alternative spelling of --with-libraries --with-pgport=PORTNUM set default port number [5432] --with-blocksize=BLOCKSIZE set table block size in kB [8] --with-segsize=SEGSIZE set table segment size in GB [1] --with-wal-blocksize=BLOCKSIZE set WAL block size in kB [8] --with-CC=CMD set compiler (deprecated) --with-llvm build with LLVM based JIT support --with-icu build with ICU support --with-tcl build Tcl modules (PL/Tcl) --with-tclconfig=DIR tclConfig.sh is in DIR --with-perl build Perl modules (PL/Perl) --with-python build Python modules (PL/Python) --with-gssapi build with GSSAPI support --with-krb-srvnam=NAME default service principal name in Kerberos (GSSAPI) [postgres] --with-pam build with PAM support --with-bsd-auth build with BSD Authentication support --with-ldap build with LDAP support --with-bonjour build with Bonjour support --with-openssl build with OpenSSL support --with-pmem build with PMEM support --with-selinux build with SELinux support --with-systemd build with systemd support --without-readline do not use GNU Readline nor BSD Libedit for editing --with-libedit-preferred prefer BSD Libedit over GNU Readline --with-uuid=LIB build contrib/uuid-ossp using LIB (bsd,e2fs,ossp) --with-ossp-uuid obsolete spelling of --with-uuid=ossp --with-libxml build with XML support --with-libxslt use XSLT support when building contrib/xml2 --with-system-tzdata=DIR use system time zone data in DIR --without-zlib do not use Zlib --with-gnu-ld assume the C compiler uses GNU ld [default=no] Some influential environment variables: CC C compiler command CFLAGS C compiler flags LDFLAGS linker flags, e.g. -L<lib dir> if you have libraries in a nonstandard directory <lib dir> LIBS libraries to pass to the linker, e.g. -l<library> CPPFLAGS (Objective) C/C++ preprocessor flags, e.g. -I<include dir> if you have headers in a nonstandard directory <include dir> CXX C++ compiler command CXXFLAGS C++ compiler flags LLVM_CONFIG path to llvm-config command CLANG path to clang compiler to generate bitcode CPP C preprocessor PKG_CONFIG path to pkg-config utility PKG_CONFIG_PATH directories to add to pkg-config's search path PKG_CONFIG_LIBDIR path overriding pkg-config's built-in search path ICU_CFLAGS C compiler flags for ICU, overriding pkg-config ICU_LIBS linker flags for ICU, overriding pkg-config XML2_CONFIG path to xml2-config utility XML2_CFLAGS C compiler flags for XML2, overriding pkg-config XML2_LIBS linker flags for XML2, overriding pkg-config LDFLAGS_EX extra linker flags for linking executables only LDFLAGS_SL extra linker flags for linking shared libraries only PERL Perl program PYTHON Python program MSGFMT msgfmt program for NLS TCLSH Tcl interpreter program (tclsh) Use these variables to override the choices made by `configure' or to help it to find libraries and programs with nonstandard names/locations. Report bugs to <https://github.com/hslightdb>. PostgreSQL home page: <https://www.hs.net/lightdb/>.
config.status
================================
config.log
Makefile语法
make程序默认从当前目录的Makefile读取配置,也可以通过-f指定文件。如果是一个工程由很多子工程,每个子工程有自己的makefile,可以通过-I(大写i)选项包含目录(这种通常是递归)。
Makefile核心部分由一系列规则组成(最简单的情况下,只由规则组成):
targets: prerequisites|components
command
command
command
# 或
targets ...: target-pattern: prereq-patterns ...
command
command
command
从例子可以看出,Makefile一般的格式是:
target:components
rule第一行表示的是依赖关系,第二行是规则,特别要注意,rule这行必须是TAB键开头。
targets是文件名,由空格隔开,一般一个规则一个文件名。其中除了标准规则外,还包括静态规则、隐示规则、模式规则、双冒号规则。
commands则用来生成目标文件,可以是任何shell能执行的命令,包括自定义程序、perl、甚至java。它必须tab开头,不能空格(跟yaml规则类似,约定俗成)。如果需要多个命令才能完成,除了&&外,可以多个命令独立各自一行。
prerequisites/components也是文件名,在为目标运行命令之前,这些文件必须已经存在,也就是依赖。如果依赖文件不存在,make会先搜索有没有对应的target,有的话先执行,如果依赖的target又依赖其它target,则一路递归下去。如下所示:
blah: blah.o cc blah.o -o blah # Runs third blah.o: blah.c cc -c blah.c -o blah.o # Runs second blah.c: echo "int main() { return 0; }" > blah.c # Runs first
clean:
rm -rf blah
如果执行make blah,会首先执行blah.c,再执行blah.o,最后执行blah。注1:默认情况下,make会运行第一个target(clean【用来清理目标文件】、all(用来一次性运行多个目标)这些只是约定俗称的习惯用法,并不是make的保留关键字)。第二次运行的时候,如果blah.c没有修改过,则不会重新执行,否则会重新执行。
上面说到过,一个targets可以有多个文件,此时对于每个文件,command都会为其执行一遍,相当于for循环。要在command中引用目标名称,可以使用$@内置变量。如下:
f1.o f2.o: echo $@
定义变量
有时候Makefile程序比较复杂,就可以定义一些变量。变量必须是字符串,在定义中,字符串一般是不双引号括起来的,这个要注意下。可以通过$()或${}引用(和velocity有点类似)。
files = file1 file2 some_file: $(files) echo "Look at this variable: " ${files} touch some_file file1: touch file1 file2: touch file2
file3 file4:
echo $@ # 内置变量$@代表target name clean: rm -f file1 file2 some_file
=和:=的关系
=
在真正执行命令的时候才会对变量求值,所以变量值可能会在中间因为其他引用的其他变量被改变而不是预期的。
=:
在赋值的时候直接对变量求值,以后如果不重新赋值是不会变化的。
自动变量和通配符
$(TARGET):$(CXX_FILES) $(SRC_DIRS)
$(info target: $@)
$(info all: $^)
$(info first: $<)
$(info SRC_DIRS_all: $(SRC_DIRS))
$(CC) -o $@ $^ $(INC_DIRS) $(CXXFLAGS) $(LIBS)
$@ 表示目标文件
$^ 表示所有的依赖文件
$< 表示第一个依赖文件
$? 表示比目标还要新的依赖文件列表
详细可参见http://www.360doc.com/content/21/1111/12/18945873_1003705062.shtml
hey: one two # Outputs "hey", since this is the first target echo $@ # Outputs all prerequisites newer than the target echo $? # Outputs all prerequisites echo $^ touch hey one: touch one two: touch two clean: rm -f hey one two
thing_wrong := *.o # Don't do this! '*' will not get expanded thing_right := $(wildcard *.o) # *主要用于文件搜索。可以用在target, prerequisites和wildcard函数中。但是不建议直接用于变量定义和直接在依赖中引用,否则如果没有匹配的话,会被当做本文量处理 all: one two three four # Fails, because $(thing_wrong) is the string "*.o" one: $(thing_wrong) # Stays as *.o if there are no files that match this pattern :( two: *.o # Works as you would expect! In this case, it does nothing. three: $(thing_right) # Same as rule three four: $(wildcard *.o)
%则主要用于通配符,和sql like有点类似。
objects = foo.o bar.o all.o all: $(objects) # These files compile via implicit rules # Syntax - targets ...: target-pattern: prereq-patterns ... # In the case of the first target, foo.o, the target-pattern matches foo.o and sets the "stem" to be "foo". # It then replaces the '%' in prereq-patterns with that stem $(objects): %.o: %.c # 可以用来代替枚举下列三个显示target # foo.o: foo.c # bar.o: bar.c # all.o: all.c all.c: echo "int main() { return 0; }" > all.c %.c: touch $@ clean: rm -f *.c *.o all
隐示规则
- 编译c程序。n.o目标如果未明确声明,则会自动在n.c上执行$(CC) -c $(CPPFLAGS) $(CFLAGS)生成。
- 编译c++程序。n.o目标如果未明确声明,则会自动在n.cc和n.cpp上执行$(CXX) -c $(CPPFLAGS) $(CXXFLAGS)生成。
- 链接对象文件。 n目标如果未明确声明,则会自动在n.cc和n.cpp上执行$(CC) $(LDFLAGS) n.o $(LOADLIBES) $(LDLIBS)生成。
所以会自动使用一些变量(他们默认由具体的c编译器定义,如gcc https://www.gnu.org/software/make/manual/make.html#Catalogue-of-Rules):
- CC
- CXX
- CFLAGS
- CXXFLAGS
- CPPFLAGS
- LDFLAGS
CC = gcc # Flag for implicit rules CFLAGS = -g # Flag for implicit rules. Turn on debug info # Implicit rule #1: blah is built via the C linker implicit rule # Implicit rule #2: blah.o is built via the C compilation implicit rule, because blah.c exists blah: blah.o blah.c: echo "int main() { return 0; }" > blah.c clean: rm -f blah*
命令执行
命令必须在单独一行,这个java调用是一样的。默认shell是/bin/sh,Linux下默认是/bin/bash。make中可通过SHELL修改。
SHELL=/bin/bash
all: cd .. # The cd above does not affect this line, because each command is effectively run in a new shell echo `pwd` # This cd command affects the next because they are on the same line cd ..;echo `pwd` # Same as above cd ..; \ echo `pwd`
shell执行的结果可以赋值给变量,如下:
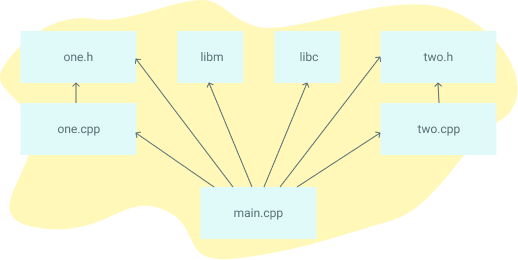
# Find all the C and C++ files we want to compile # Note the single quotes around the * expressions. Make will incorrectly expand these otherwise. SRCS := $(shell find $(SRC_DIRS) -name '*.cpp' -or -name '*.c' -or -name '*.s') INC_DIRS := $(shell find $(SRC_DIRS) -type d)
条件判断
foo = ok all: ifeq ($(foo), ok) echo "foo equals ok" else echo "nope" endif # 变量空值判断 nullstring = foo = $(nullstring) # end of line; there is a space here all: ifeq ($(strip $(foo)),) echo "foo is empty after being stripped" endif ifeq ($(nullstring),) echo "nullstring doesn't even have spaces" endif
# 查看变量是否已定义 bar = foo = $(bar) all: ifdef foo echo "foo is defined" endif ifdef bar echo "but bar is not" endif
# 查看make的选项 bar = foo = $(bar) all: # Search for the "-i" flag. MAKEFLAGS is just a list of single characters, one per flag. So look for "i" in this case. ifneq (,$(findstring i, $(MAKEFLAGS))) echo "i was passed to MAKEFLAGS" endif
函数
函数一般通过$(fn, arguments) or ${fn, arguments}调用,也可使用call显示调用,make包含很多内置函数。注意事项比较多,尤其是拼接和空格。
comma := , empty:= space := $(empty) $(empty) foo := a b c bar := $(subst $(space), $(comma) , $(foo)) all: # Output is ", a , b , c". Notice the spaces introduced @echo $(bar)
四个特殊符号的意义@、$@、$^、$<
$@、$^、$<
这三个分别表示:
$@ --代表目标文件(target)
$^ --代表所有的依赖文件(components)
$< --代表第一个依赖文件(components中最左边的那个)。
main.out:main.o line1.o line2.o
g++ -o $@ $^
main.o:main.c line1.h line2.h
g++ -c $<
line1.o:line1.c line1.h
g++ -c $<
line2.o:line2.c line2.h
g++ -c $<参见https://www.jianshu.com/p/9756f766700a最后。
Makefile文件中的 .PHONY 的作用
https://zhuanlan.zhihu.com/p/347929747
调用子目录makefile
makefile编译子目录 包括调用xxx_src对应的xxx_src_test目录执行测试用例。
https://zhuanlan.zhihu.com/p/362922473 include使用场景。
其他
参考
cmake版本可以参见https://www.cnblogs.com/zhjh256/p/15637621.html
https://www.gnu.org/prep/standards/html_node/index.html#SEC_Contents GNU编码规范