选题背景
垃圾分类是一项重要的环保举措,通过将垃圾按照可回收和有机垃圾进行分类,可以实现有效的资源回收和减少对环境的污染。然而,传统的垃圾分类方法需要大量的人力和时间,并且存在主观判断的问题。因此,利用机器学习技术来自动识别和分类垃圾是一个有意义的研究方向。
有机垃圾和可回收垃圾的识别是垃圾分类中的关键任务之一。有机垃圾包括食物残渣、植物废料等,而可回收垃圾包括塑料瓶、玻璃瓶、纸张等可以回收再利用的材料。通过将这两类垃圾进行准确的分类,可以方便地进行后续的垃圾处理和资源回收工作。
机器学习技术可以通过对大量标记好的垃圾图像进行训练,学习到分类垃圾的模式和特征。使用卷积神经网络(CNN)等深度学习模型,可以从图像中提取有用的特征,并对垃圾进行分类。通过机器学习模型的训练和优化,可以实现高准确度和高效率的垃圾分类系统。
步骤
1下载数据集
数据集来源:kaggle,网址:https://www.kaggle.com/
数据集里包括实际的测试集目录路径,实际的训练集目录路径,DATASET数据集,该数据集是图片数据,分为训练集85%(Train)和测试集15%(Test)。其中O代表Organic(有机垃圾),R代表Recycle(可回收)


2检测训练集中和测试集中的文件目录
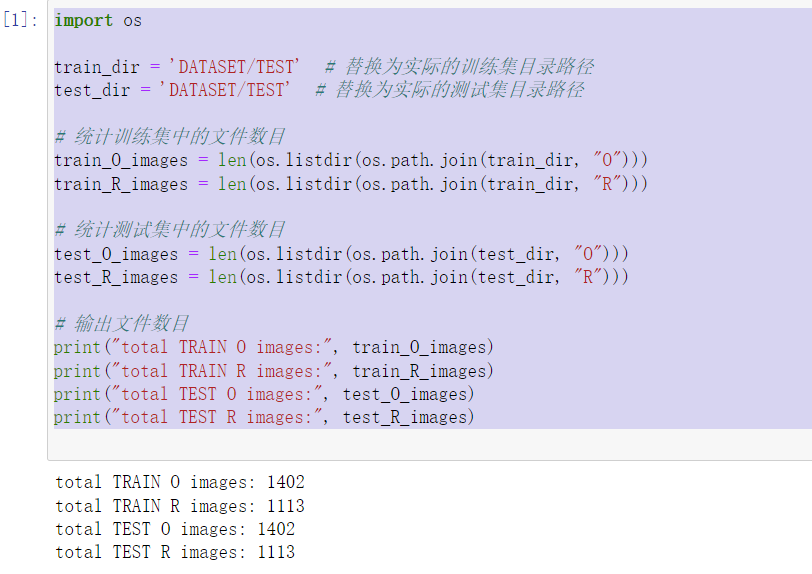
import os train_dir = 'DATASET/TEST' # 替换为实际的训练集目录路径 test_dir = 'DATASET/TEST' # 替换为实际的测试集目录路径 # 统计训练集中的文件数目 train_O_images = len(os.listdir(os.path.join(train_dir, "O"))) train_R_images = len(os.listdir(os.path.join(train_dir, "R"))) # 统计测试集中的文件数目 test_O_images = len(os.listdir(os.path.join(test_dir, "O"))) test_R_images = len(os.listdir(os.path.join(test_dir, "R"))) # 输出文件数目 print("total TRAIN O images:", train_O_images) print("total TRAIN R images:", train_R_images) print("total TEST O images:", test_O_images) print("total TEST R images:", test_R_images)
3加载并准备训练集和测试集数据
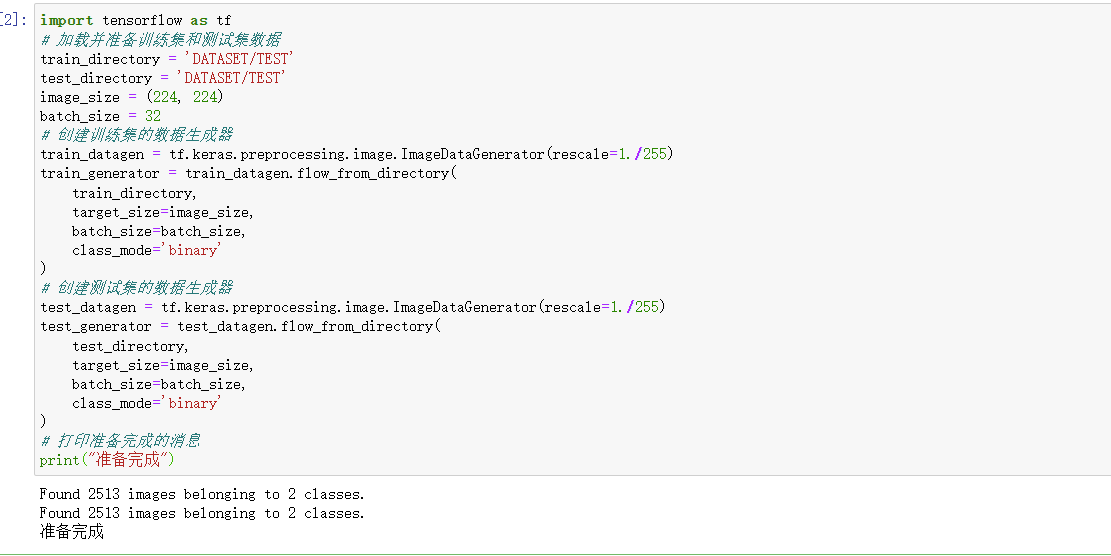
import tensorflow as tf # 加载并准备训练集和测试集数据 train_directory = 'DATASET/TEST' test_directory = 'DATASET/TEST' image_size = (224, 224) batch_size = 32 # 创建训练集的数据生成器 train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255) train_generator = train_datagen.flow_from_directory( train_directory, target_size=image_size, batch_size=batch_size, class_mode='binary' ) # 创建测试集的数据生成器 test_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255) test_generator = test_datagen.flow_from_directory( test_directory, target_size=image_size, batch_size=batch_size, class_mode='binary' ) # 打印准备完成的消息 print("准备完成")
4定义CNN模型(训练20次将准确率达到1.0000)
# 定义CNN模型 model = tf.keras.Sequential([ tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(224, 224, 3)), tf.keras.layers.MaxPooling2D((2, 2)), tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D((2, 2)), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D((2, 2)), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(1, activation='sigmoid') ]) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) # 训练模型 history = model.fit( train_generator, epochs=20, validation_data=test_generator ) print("结束训练")

5. 用测试集数据生成器对模型进行评估
validation_loss, validation_accuracy = model.evaluate(test_generator) print(f"Validation Loss: {validation_loss:.4f}")#使用测试集数据生成器对模型进行评估,返回验证集的损失和准确率。 print(f"Validation Accuracy: {validation_accuracy:.4f}") print("评估结束")

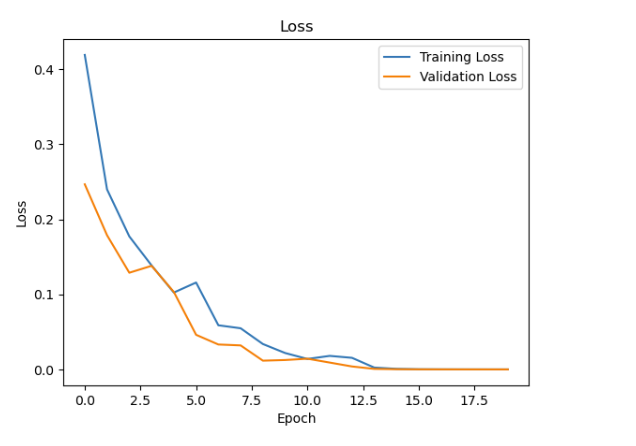
6.绘制训练和验证的损失曲线
print("结束训练") # 绘制训练和验证的损失曲线 plt.plot(history.history['loss'], label='Training Loss') plt.plot(history.history['val_loss'], label='Validation Loss') plt.title('Loss') plt.xlabel('Epoch') plt.ylabel('Loss') plt.legend() plt.show()
# 绘制训练和验证的准确率曲线 plt.plot(history.history['accuracy'], label='Training Accuracy') plt.plot(history.history['val_accuracy'], label='Validation Accuracy') plt.title('Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend() plt.show() print("训练和绘图完成")

7.准备测试单个图像
# 加载测试图像 test_image_path = 'egg.jpg' test_image = tf.keras.preprocessing.image.load_img(test_image_path, target_size=(224, 224)) test_image = tf.keras.preprocessing.image.img_to_array(test_image) test_image = test_image / 255.0 # 归一化像素值 # 将图像转换为批次数据(因为模型输入是一个批次的图像) test_image = tf.expand_dims(test_image, axis=0) # 进行预测 predictions = model.predict(test_image) class_names = ['Organic', 'Recycle'] # 类别名称 predicted_class = class_names[int(predictions[0][0])] print(f"这个垃圾是: {predicted_class}") # 显示加载的图像 image = plt.imread(test_image_path) plt.imshow(image) plt.title(f"Predicted Class: {predicted_class}") plt.axis('off') plt.show()
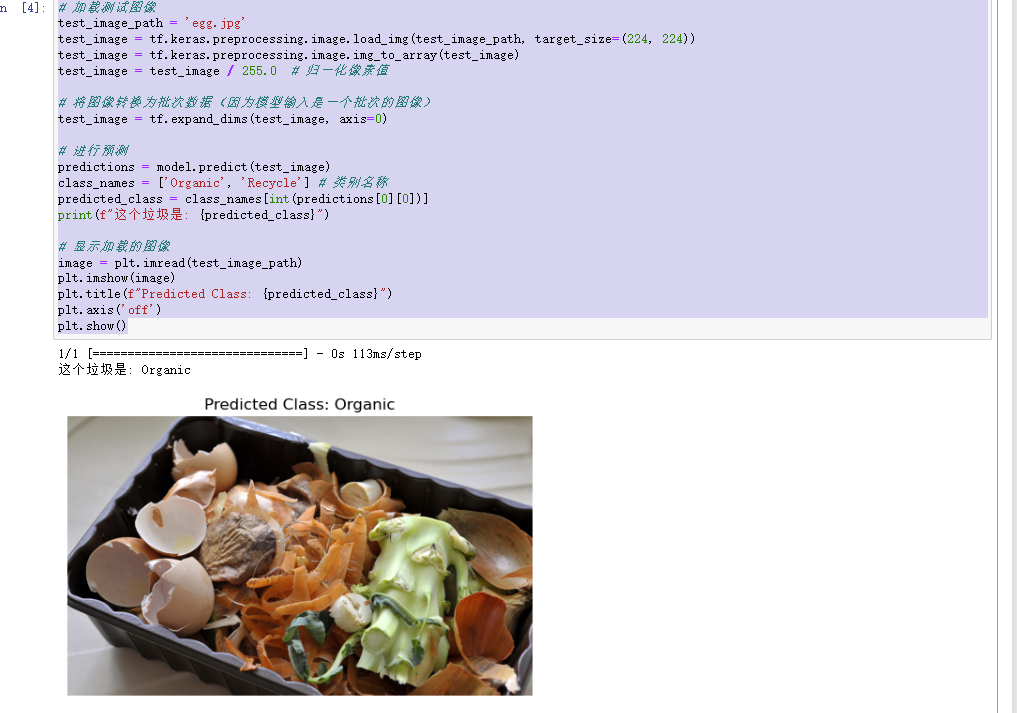
8发现无误后保存模型
print("准备保存模型") model.save('test.h5') print("模型保存成功")

9. 准备一个文件夹,自己放入5张照片
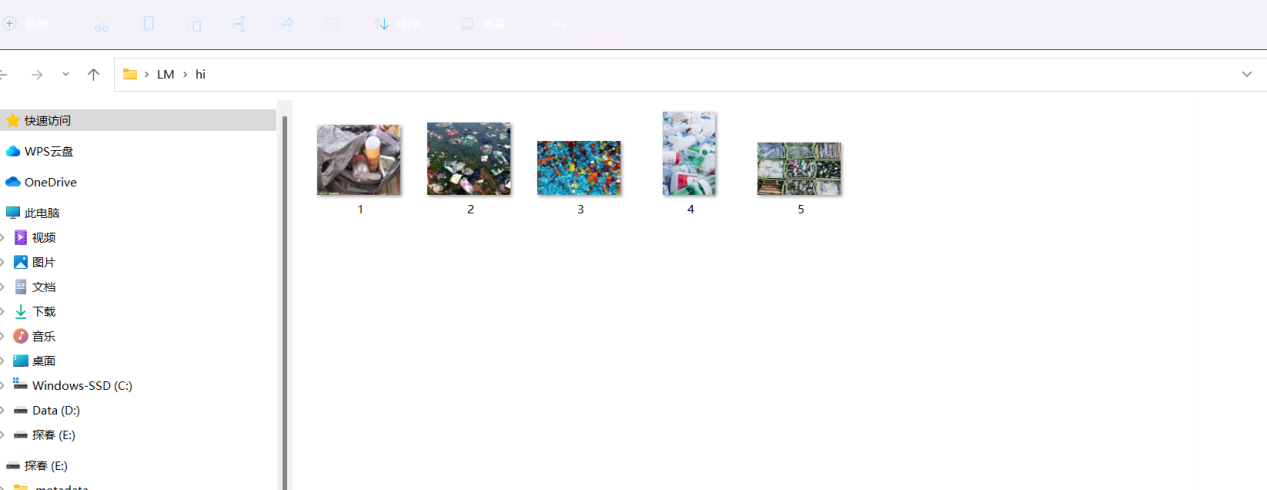
10. 导入保存好的模型来识别
import os from PIL import Image import tensorflow as tf import matplotlib.pyplot as plt # 加载训练好的模型 model = tf.keras.models.load_model('test.h5') import os os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" # 定义类别名称 class_names = ['Organic', 'Recycle'] # 遍历图像文件夹 image_folder = 'hi' for filename in os.listdir(image_folder): if filename.endswith('.jpg') or filename.endswith('.png'): # 加载图像 image_path = os.path.join(image_folder, filename) image = Image.open(image_path) image = image.convert("RGB") # 调整图像尺寸为模型需要的大小 image = image.resize((224, 224)) # 归一化像素值 image = tf.keras.preprocessing.image.img_to_array(image) image = image / 255.0 # 将图像转换为批次数据(因为模型输入是一个批次的图像) image = tf.expand_dims(image, axis=0) # 进行预测 predictions = model.predict(image) predicted_class = class_names[int(predictions[0][0])] # 显示图像 plt.imshow(image[0]) plt.title(f"Predicted Class: {predicted_class}") plt.axis('off') plt.show()


收获:
熟悉了机器学习的基本流程:从数据准备、模型选择、训练到评估和预测等步骤,对整个机器学习项目的流程有了更深入的理解。
掌握了数据处理和特征工程技巧:在项目中,我学会了对数据进行清洗、转换和特征选择等处理,以提高模型的准确性和泛化能力。
熟悉了常用的机器学习算法和模型:通过实践,我对常见的机器学习算法和模型有了更深入的了解,包括线性回归、决策树、支持向量机等。
学会了使用机器学习工具和库:在项目中,我使用了Python编程语言和常用的机器学习库,如Scikit-learn和TensorFlow,提高了开发效率和模型构建的灵活性。
总结:
这个机器学习项目的设计和实现让我更好地理解了机器学习的应用和实践过程。通过处理真实的数据集和构建机器学习模型,我能够将理论知识应用到实际问题中,并通过不断的实验和调整来优化模型的性能。
在项目中,我也发现了一些挑战和改进的方向。其中包括:
数据质量和特征选择:数据的质量对机器学习的结果有着重要影响。在未来的项目中,我需要更加关注数据的质量和准确性,并进行更好的特征选择,以提高模型的性能。
模型调参和优化:在这个项目中,我对模型的调参和优化只是进行了简单的尝试,但这是提高模型性能的重要环节。在未来的项目中,我会更加深入地研究模型的参数调节和优化方法,以获得更好的结果。
扩展性和实时性:这个项目是基于离线数据集的机器学习任务,但在实际应用中,往往需要考虑实时性和大规模数据处理的问题。在未来的项目中,我希望能够扩展到更复杂的场景,并研究实时数据处理和在线学习的方法。
改进:
为了进一步提升机器学习项目的质量和效果,我计划采取以下改进措施:
更多的数据收集和预处理:收集更多的数据样本,并进行更全面和准确的预处理,以提高数据的质量和覆盖范围。
模型选择和调参策略:针对不同的任务和数据特点,选择更合适的模型,并进行更细致的调参和优化,以获得更好的性能。
模型评估和迭代优化:对模型的性能进行全面的评估,并通过迭代优化的方式,不断改进模型的准确性和泛化能力。
实时性和扩展性考虑:在未来的项目中,考虑到实时性和扩展性的需求,采用更适合的技术和方法,如流式处理和分布式计算等。
#全部代码 import tensorflow as tf import matplotlib.pyplot as plt import os os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" # 加载并准备训练集和测试集数据 train_directory = 'DATASET/TEST' test_directory = 'DATASET/TEST' image_size = (224, 224) batch_size = 32 # 创建训练集的数据生成器 train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255) train_generator = train_datagen.flow_from_directory( train_directory, target_size=image_size, batch_size=batch_size, class_mode='binary' ) # 创建测试集的数据生成器 test_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255) test_generator = test_datagen.flow_from_directory( test_directory, target_size=image_size, batch_size=batch_size, class_mode='binary' ) # 打印准备完成的消息 print("准备完成") # 定义CNN模型 model = tf.keras.Sequential([ tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(224, 224, 3)), tf.keras.layers.MaxPooling2D((2, 2)), tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D((2, 2)), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D((2, 2)), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(1, activation='sigmoid') ]) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) # 训练模型 history = model.fit( train_generator, epochs=15, validation_data=test_generator ) print("结束训练") validation_loss, validation_accuracy = model.evaluate(test_generator) print(f"Validation Loss: {validation_loss:.4f}")#使用测试集数据生成器对模型进行评估,返回验证集的损失和准确率。 print(f"Validation Accuracy: {validation_accuracy:.4f}") print("评估结束") # 绘制训练和验证的损失曲线 plt.plot(history.history['loss'], label='Training Loss') plt.plot(history.history['val_loss'], label='Validation Loss') plt.title('Loss') plt.xlabel('Epoch') plt.ylabel('Loss') plt.legend() plt.show() # 绘制训练和验证的准确率曲线 plt.plot(history.history['accuracy'], label='Training Accuracy') plt.plot(history.history['val_accuracy'], label='Validation Accuracy') plt.title('Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend() plt.show() print("训练和绘图完成") # 加载测试图像 test_image_path = 'egg.jpg' test_image = tf.keras.preprocessing.image.load_img(test_image_path, target_size=(224, 224)) test_image = tf.keras.preprocessing.image.img_to_array(test_image) test_image = test_image / 255.0 # 归一化像素值 # 将图像转换为批次数据(因为模型输入是一个批次的图像) test_image = tf.expand_dims(test_image, axis=0) # 进行预测 predictions = model.predict(test_image) class_names = ['Organic', 'Recycle'] # 类别名称 predicted_class = class_names[int(predictions[0][0])] print(f"这个垃圾是: {predicted_class}") # 显示加载的图像 image = plt.imread(test_image_path) plt.imshow(image) plt.title(f"Predicted Class: {predicted_class}") plt.axis('off') plt.show() print("准备保存模型") model.save('test.h5') print("模型保存成功") import os from PIL import Image import tensorflow as tf import matplotlib.pyplot as plt # 加载训练好的模型 model = tf.keras.models.load_model('test.h5') import os os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" # 定义类别名称 class_names = ['Organic', 'Recycle'] # 遍历图像文件夹 image_folder = 'hi' for filename in os.listdir(image_folder): if filename.endswith('.jpg') or filename.endswith('.png'): # 加载图像 image_path = os.path.join(image_folder, filename) image = Image.open(image_path) image = image.convert("RGB") # 调整图像尺寸为模型需要的大小 image = image.resize((224, 224)) # 归一化像素值 image = tf.keras.preprocessing.image.img_to_array(image) image = image / 255.0 # 将图像转换为批次数据(因为模型输入是一个批次的图像) image = tf.expand_dims(image, axis=0) # 进行预测 predictions = model.predict(image) predicted_class = class_names[int(predictions[0][0])] # 显示图像 plt.imshow(image[0]) plt.title(f"Predicted Class: {predicted_class}") plt.axis('off') plt.show()