1.算法描述
支持向量机(support vector machines, SVM)是二分类算法,所谓二分类即把具有多个特性(属性)的数据分为两类,目前主流机器学习算法中,神经网络等其他机器学习模型已经能很好完成二分类、多分类,学习和研究SVM,理解SVM背后丰富算法知识,对以后研究其他算法大有裨益;在实现SVM过程中,会综合利用之前介绍的一维搜索、KKT条件、惩罚函数等相关知识。本篇首先通过详解SVM原理,后介绍如何利用python从零实现SVM算法。
实例中样本明显的分为两类,黑色实心点不妨为类别一,空心圆点可命名为类别二,在实际应用中会把类别数值化,比如类别一用1表示,类别二用-1表示,称数值化后的类别为标签。每个类别分别对应于标签1、还是-1表示没有硬性规定,可以根据自己喜好即可,需要注意的是,由于SVM算法标签也会参与数学运算,这里不能把类别标签设为0。
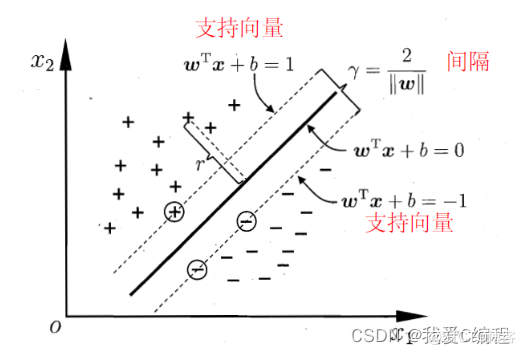


线性核:
主要用于线性可分的情况,我们可以看到特征空间到输入空间的维度是一样的,其参数少速度快,对于线性可分数据,其分类效果很理想
通常首先尝试用线性核函数来做分类,看看效果如何,如果不行再换别的
优点:方案首选、简单、可解释性强:可以轻易知道哪些feature是重要的
缺点:只能解决线性可分的问题
高斯核:
通过调控参数,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。
如果σ \sigmaσ选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;
如果σ \sigmaσ选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。
优点:可以映射到无限维、决策边界更为多维、只有一个参数
缺点:可解释性差、计算速度慢、容易过拟合
多项式核
多项式核函数可以实现将低维的输入空间映射到高纬的特征空间,
但是多项式核函数的参数多
当多项式的阶数比较高的时候,核矩阵的元素值将趋于无穷大或者无穷小,计算复杂度会大到无法计算。
优点:可解决非线性问题、主观设置
缺点:多参数选择、计算量大
sigmoid核
采用sigmoid核函数,支持向量机实现的就是只包含一个隐层,激活函数为 Sigmoid 函数的神经网络。
应用SVM方法,隐含层节点数目(它确定神经网络的结构)、隐含层节点对输入节点的权值都是在设计(训练)的过程中自动确定的。
而且支持向量机的理论基础决定了它最终求得的是全局最优值而不是局部最小值,也保证了它对于未知样本的良好泛化能力而不会出现过学习现象。
如图, 输入层->隐藏层之间的权重是每个支撑向量,隐藏层的计算结果是支撑向量和输入向量的内积,隐藏层->输出层之间的权重是支撑向量对应的
蚁群算法是受到对真实蚂蚁群觅食行为研究的启发而提出。生物学研究表明:一群相互协作的蚂蚁能够找到食物和巢穴之间的最短路径,而单只蚂蚁则不能。生物学家经过大量细致观察研究发现,蚂蚁个体之间的行为是相互作用相互影响的。蚂蚁在运动过程中,能够在它所经过的路径上留下一种称之为信息素的物质,而此物质恰恰是蚂蚁个体之间信息传递交流的载体。蚂蚁在运动时能够感知这种物质,并且习惯于追踪此物质爬行,当然爬行过程中还会释放信息素。一条路上的信息素踪迹越浓,其它蚂蚁将以越高的概率跟随爬行此路径,从而该路径上的信息素踪迹会被加强,因此,由大量蚂蚁组成的蚁群的集体行为便表现出一种信息正反馈现象。某一路径上走过的蚂蚁越多,则后来者选择该路径的可能性就越大。蚂蚁个体之间就是通过这种间接的通信机制实现协同搜索最短路径的目标的。
蚁群算法是对自然界蚂蚁的寻径方式进行模拟而得出的一种仿生算法。蚂蚁在运动过程中,能够在它所经过的路径上留下信息素进行信息传递,而且蚂蚁在运动过程中能够感知这种物质,并以此来指导自己的运动方向。因此,由大量蚂蚁组成的蚁群的集体行为便表现出一种信息正反馈现象:某一路径上走过的蚂蚁越多,则后来者选择该路径的概率就越大。
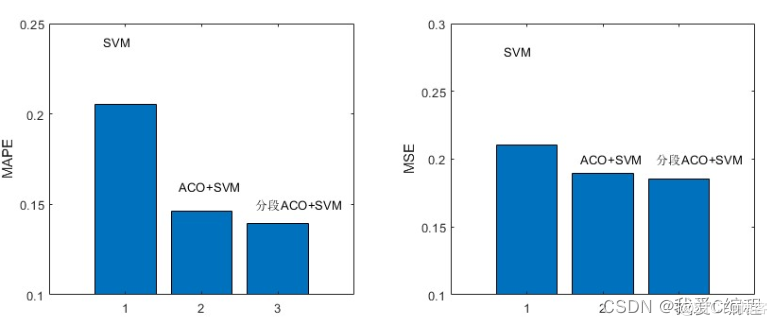
2.仿真效果预览
matlab2022a仿真结果如下:


3.MATLAB核心程序
%% 第一步:初始化
M = length(LB);%决策变量的个数
%蚁群位置初始化
X = zeros(M,N);
for i=1:M
x=unifrnd(LB(i),UB(i),1,N);
X(i,:)=x;
end
%输出变量初始化
BESTX = cell(K,1);%细胞结构,每一个元素是M×1向量,记录每一代的最优个体
BESTY = zeros(K,1);%K×1矩阵,记录每一代的最优个体的评价函数值
k = 1;%迭代计数器初始化
Tau = ones(1,N);%信息素初始化
Y = zeros(1,N);%适应值初始化
%% 第二步:迭代过程
while k<=K
k
YY=zeros(1,N);
for n=1:N
x = X(:,n);
J = func_fitness(X_train,X_test,T_train,T_test,x(1),x(2),x(3));
YY(n) = J;
end
maxYY = max(YY);
temppos = find(YY==maxYY);
POS = temppos(1);
%蚂蚁随机探路
for n=1:N
x = X(:,n);
J = func_fitness(X_train,X_test,T_train,T_test,x(1),x(2),x(3));
Fx = J;
mx = x + Lambda*rand*x;
J = func_fitness(X_train,X_test,T_train,T_test,mx(1),mx(2),mx(3));
Fmx = J;
if Fmx<Fx
X(:,n)=mx;
Y(n)=Fmx;
else
X(:,n)=x;
Y(n)=Fx;
end
end
%朝信息素最大的地方移动
for n=1:N
rng(n*k);
if n~=POS & rand <= 1-k/K
.............................................................
end
end
indy = find(Y==0);
Y(indy) = 1;
%更新信息素并记录
Tau = Tau*(1-Rho);
maxY = max(Y);
minY = min(Y);
DeltaTau = Q*(maxY-Y)/(maxY-minY)/1e1;
p = 0.05*Tau;
Tau = (1-p).*Tau + DeltaTau;
minY = min(Y);
pos4 = find(Y==minY);
BESTX{k} = X(:,pos4(1));
%更新移动速度
if k <= 1
e1 = minY;
Lambda = Lambda;
else
Lambda = Lambda + 0.15*(minY-e1);
e1 = minY;
end
k=k+1;
end
C0 = BESTX{end}(1);
gamma0 = BESTX{end}(2);
tt0 = BESTX{end}(3);
save ACO.mat C0 gamma0 tt0
end
if SEL == 2
load ACO.mat
%调用四个最优的参数
C = C0;
gamma = gamma0;
tt = tt0;
cmd = ['-s 3',[' -t ', num2str(ceil(tt))],[' -c ', num2str(C)],[' -g ',num2str(gamma)],' -p 0.00001'];
model = svmtrain(T_train,X_train,cmd);
[yIn,input1ps] = mapminmax(In');
[Predict1,error1] = svmpredict(Out,yIn',model);