应用
应用1:Leetcode 112. 路径总和
题目
分析
DFS
这里,我们深度优先遍历的思路,遍历过程中,同时记录根节点到当前节点的路径和\(current\)。
递归的结束条件是:当前节点是否为叶子节点,即当前节点的 左右子树同时为空节点。
代码实现
class Solution:
def hasPathSum(self, root: Optional[TreeNode], targetSum: int) -> bool:
return self.dfs(root, 0, targetSum)
def dfs(self, root, current, target):
if not root:
return False
# 根节点到当前节点的前缀和
current += root.val
# 到达叶子节点
if not root.left and not root.right:
return current == target
return self.dfs(root.left, current, target) or self.dfs(root.right, current, target)
应用2:Leetcode 113. 路径总和 II
题目
分析
回溯
这里,我们深度优先遍历的思路,遍历过程中,同时记录根节点到当前节点的路径和\(current\) 和路径 \(path\)。
递归过程中,如果当前节点是叶子节点,即当前节点的 左右子树同时为空节点,并且路径和等于 \(target\),就将路径路径加入结果集 \(results\) 中。
注意,与 112. 路径总和 不同是,在回溯过程,遇到符合条件的路径时,不能直接退出,需要将当前节点的父节点从路径中移除,以便继续回溯其他路径。
代码实现
class Solution:
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> List[List[int]]:
results = list()
path = list()
self.dfs(root, path, results, 0, targetSum)
return results
def dfs(self, root, path, results, current, target):
if not root:
return
path.append(root.val)
current += root.val
if not root.left and not root.right and current == target:
results.append(list(path))
self.dfs(root.left, path, results, current, target)
self.dfs(root.right, path, results, current, target)
path.pop()
return
应用3:Leetcode 437. 路径总和 III
题目
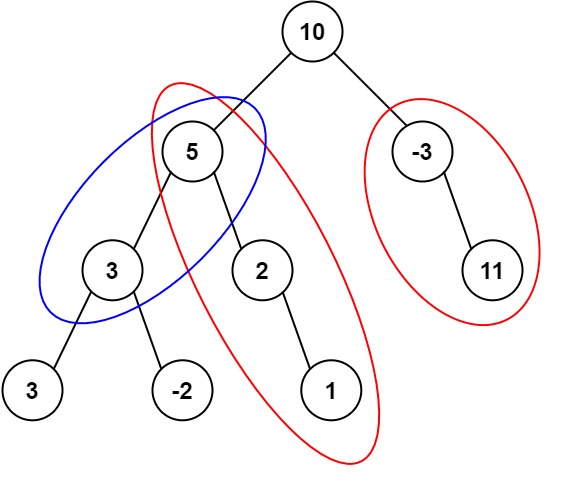
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
示例 1:
输入:root = [10,5,-3,3,2,null,11,3,-2,null,1], targetSum = 8
输出:3
解释:和等于 8 的路径有 3 条,如图所示。
分析
方法一:DFS
比较朴素的思想是枚举所有可能结果,即遍历树上的每一个节点 \(node\),并以当前节点为起始节点,找到所有满足条件的路径。
这里,我们首先定一个函数,用于表示,以节点 \(root\) 为起点,且满足路径和为 \(target\) 的路径数目:
def root_sum(self, root: Optional[TreeNode], target: int) -> int:
然后,我们使用前序遍历的方式,从根节点遍历该二叉树,累加每个节点满足条件的路径总和。
方法二:回溯 + 前缀和
由于我们到达每个节点时,根节点到当前节点的路径上的所有节点对应的前缀和,就已经计算出来了,所以,我们不需要对每个节点都进行多次计算前缀和。
例如,假设根节点为 \(root\),当前节点为 \(node\),假设根节点到当前节点的路径为:
假设它们所对应的前缀和分别为:
由于,到达当前节点 \(node\) 之前,会先经过节点:\(p_1, \ p_2, \ \cdots , \ p_n\),经过这些节点时,我们可以先将这些 节点对应的前缀和 及 其出现的次数,保存在 \(Hash\) 表 \(prefix\) 中。
这样,在到达节点 \(node\) 的时候,我们可以通过差值 \(diff\):
判断是否存在某一段子路径是否满足路径和为 \(target\)。
这样,我们就可以通过回溯每个节点的差值,如果差值已经在 \(prefix\) 中,则说明存在一条以当前节点结尾的路径。
注意,由于回溯的时候,为了避免额外处理 根节点等于 \(target\) 的场景,这里,我们设置 \(prefix[0] = 1\),表示前缀和为零的节点有一个。
代码实现
【方法一】
class Solution:
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> int:
if not root:
return 0
count = self.root_sum(root, targetSum)
count += self.pathSum(root.left, targetSum)
count += self.pathSum(root.right, targetSum)
return count
def root_sum(self, root: Optional[TreeNode], target: int) -> int:
count = 0
if not root:
return 0
value = root.val
if value == target:
count += 1
count += self.root_sum(root.left, target - value)
count += self.root_sum(root.right, target - value)
return count
【方法二】
class Solution:
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> int:
# 记录每个前缀和出现的次数
prefix = defaultdict(int)
# 处理根节点等于target的场景
prefix[0] = 1
return self.dfs(root, prefix, 0, targetSum)
def dfs(self, root: Optional[TreeNode], prefix, current: int, target: int):
if not root:
return 0
result = 0
# 计算到达当前节点的前缀和
current += root.val
# 统计是否存在已经访问过的节点的前缀和与当前节点的前缀和的差值满足条件
result += prefix[current - target]
# 回溯当前节点的前缀和的出现次数
prefix[current] += 1
result += self.dfs(root.left, prefix, current, target)
result += self.dfs(root.right, prefix, current, target)
prefix[current] -= 1
return result
参考: