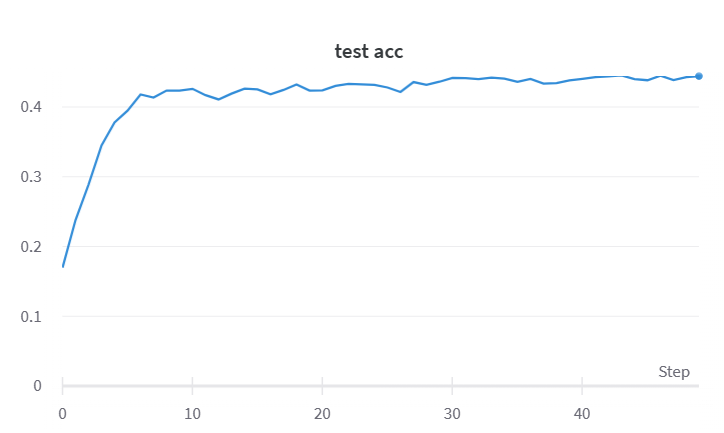
1 # 导入所需的包 2 import torch 3 #import wandb 4 import torch.nn as nn 5 from torchvision import transforms 6 from torchvision.datasets import CIFAR100 7 from torch.utils.data import DataLoader 8 9 # 使用Compose容器组合定义图像预处理方式 10 11 12 transf = transforms.Compose([ 13 # 将给定图片转为shape为(C, H, W)的tensor 14 transforms.ToTensor() 15 ]) 16 # 数据准备 17 train_set = CIFAR100( 18 # 数据集的地址 19 root="./", 20 # 是否为训练集,True为训练集 21 train=True, 22 # 使用数据预处理 23 transform=transf, 24 # 是否需要下载, True为需要下载 25 download=True 26 ) 27 test_set = CIFAR100( 28 root="./", 29 train=False, 30 transform=transf, 31 download=True 32 ) 33 # 定义数据加载器 34 train_loader = DataLoader( 35 # 需要加载的数据 36 train_set, 37 # 定义batch大小 38 batch_size=16, 39 # 是否打乱顺序,True为打乱顺序 40 shuffle=True 41 ) 42 test_loader = DataLoader( 43 test_set, 44 batch_size=16, 45 shuffle=False 46 ) 47 48 49 # 定义VGG16网络 50 # 提示:nn.Sequetial():按顺序包装 51 # nn.ModuleList():像list一样包装,用[ ] 52 # nn.ModuleDict():像dict一样包装,用{ } 53 # 以上几个不能同时使用,可以选其中一种 54 import torch.nn as nn 55 class My_VGG(nn.Module): 56 def __init__(self, num_classes): 57 super(My_VGG, self).__init__() 58 # 第一个卷积块 59 self.conv1 = nn.Sequential( 60 nn.Conv2d(3, 64, kernel_size=(3, 3), stride=1, padding=1),nn.ReLU(), 61 # nn.BatchNorm2d(64)归一化处理,注意括号中是指通道数, 62 # 在样本过少的时候采用GroupNorm或LayerNorm 63 nn.Conv2d(64, 64, kernel_size=(3, 3), stride=1, padding=1),nn.ReLU(), 64 ) 65 self.pool1 = nn.MaxPool2d((2, 2), 2) 66 # 第二个卷积块 67 self.conv2 = nn.Sequential( 68 nn.Conv2d(64, 128, kernel_size=(3, 3), stride=1, padding=1),nn.ReLU(), 69 nn.Conv2d(128, 128, kernel_size=(3, 3), stride=1, padding=1),nn.ReLU(), 70 ) 71 self.pool2 = nn.MaxPool2d((2, 2), 2) 72 # 第三个卷积块 73 self.conv3 = nn.Sequential( 74 nn.Conv2d(128, 256, kernel_size=(3, 3), stride=1, padding=1),nn.ReLU(), 75 nn.Conv2d(256, 256, kernel_size=(3, 3), stride=1, padding=1),nn.ReLU(), 76 nn.Conv2d(256, 256, kernel_size=(3, 3), stride=1, padding=1),nn.ReLU(), 77 ) 78 self.pool3 = nn.MaxPool2d((2, 2), 2) 79 # 第四个卷积块 80 self.conv4 = nn.Sequential( 81 nn.Conv2d(256, 512, kernel_size=(3, 3), stride=1, padding=1),nn.ReLU(), 82 nn.Conv2d(512, 512, kernel_size=(3, 3), stride=1, padding=1),nn.ReLU(), 83 nn.Conv2d(512, 512, kernel_size=(3, 3), stride=1, padding=1),nn.ReLU(), 84 ) 85 self.pool4 = nn.MaxPool2d((2, 2), 2) 86 # 第五个卷积块 87 self.conv5 = nn.Sequential( 88 nn.Conv2d(512, 512, kernel_size=(3, 3), stride=1, padding=1),nn.ReLU(), 89 nn.Conv2d(512, 512, kernel_size=(3, 3), stride=1, padding=1),nn.ReLU(), 90 nn.Conv2d(512, 512, kernel_size=(3, 3), stride=1, padding=1),nn.ReLU(), 91 ) 92 self.pool5 = nn.MaxPool2d((2, 2), 2) 93 # 全连接层部分 94 self.output = nn.Sequential( 95 nn.Linear(512*1*1, 4096),nn.ReLU(),nn.Dropout(), 96 nn.Linear(4096, 4096),nn.ReLU(),nn.Dropout(0.5), 97 nn.Linear(4096, num_classes) 98 ) 99 '''在此处初始化, 100 定义在网络里 101 如下两种: 102 ''' 103 #Xavier初始化 104 for m in self.modules(): 105 if isinstance(m, nn.Linear) or isinstance(m, nn.Conv2d): 106 torch.nn.init.xavier_uniform_(m.weight) 107 # 108 #He初始化(Kaiming初始化) 109 # for m in self.modules(): 110 # if isinstance(m, nn.Linear) or isinstance(m, nn.Conv2d): 111 # torch.nn.init.kaiming_normal_(m.weight) 112 113 114 def forward(self,x): 115 x = self.pool1(self.conv1(x)) 116 x = self.pool2(self.conv2(x)) 117 x = self.pool3(self.conv3(x)) 118 x = self.pool4(self.conv4(x)) 119 x = self.pool5(self.conv5(x)) 120 x = x.view(x.size(0), -1) 121 outer = self.output(x) 122 return outer 123 124 125 # 定义网络的预训练 126 def train(net, train_loader, test_loader, device, l_r = 0.01, num_epochs=25): 127 # 使用wandb跟踪训练过程 128 #experiment = wandb.init(project='VGG16', resume='allow', anonymous='must') 129 # 定义损失函数 130 criterion = nn.CrossEntropyLoss() 131 # 定义优化器 132 optimizer = torch.optim.Adam(net.parameters(), lr=l_r) 133 134 # 将网络移动到指定设备 135 net = net.to(device) 136 # 正式开始训练 137 for epoch in range(num_epochs): 138 # 保存一个Epoch的损失 139 train_loss = 0 140 # 计算准确度 141 test_corrects = 0 142 # 设置模型为训练模式 143 net.train() 144 for step, (imgs, labels) in enumerate(train_loader): 145 # 训练使用的数据移动到指定设备 146 imgs = imgs.to(device) 147 labels = labels.to(device) 148 output = net(imgs) 149 # 计算损失 150 loss = criterion(output, labels) 151 # 将梯度清零 152 optimizer.zero_grad() 153 # 将损失进行后向传播 154 loss.backward() 155 # 更新网络参数 156 optimizer.step() 157 train_loss += loss.item() 158 pre_lab = torch.argmax(output, 1) 159 train_batch_corrects = (torch.sum(pre_lab == labels.data).double() / imgs.size(0)) 160 if step % 100 == 0: 161 print("train {} {}/{} loss: {} acc: {}".format(epoch, step, len(train_loader), loss.item(), 162 train_batch_corrects.item())) 163 # 设置模型为验证模式 164 net.eval() 165 for step, (imgs, labels) in enumerate(test_loader): 166 imgs = imgs.to(device) 167 labels = labels.to(device) 168 output = net(imgs) 169 loss = criterion(output, labels) 170 pre_lab = torch.argmax(output, 1) 171 test_batch_corrects = (torch.sum(pre_lab == labels.data).double() / imgs.size(0)) 172 test_corrects += test_batch_corrects.item() 173 if step % 100 == 0: 174 print("val {} {}/{} loss: {} acc: {}".format(epoch, step, len(test_loader), loss.item(), 175 test_batch_corrects.item())) 176 177 # 一个Epoch结束时,使用wandb保存需要可视化的数据 178 # experiment.log({ 179 # 'epoch':epoch, 180 # 'train loss': train_loss / len(train_loader), 181 # 'test acc': test_corrects / len(test_loader), 182 # }) 183 print('Epoch: {}/{}'.format(epoch, num_epochs-1)) 184 print('{} Train Loss:{:.4f}'.format(epoch, train_loss / len(train_loader))) 185 print('{} Test Acc:{:.4f}'.format(epoch, test_corrects / len(test_loader))) 186 # 保存此Epoch训练的网络的参数 187 torch.save(net.state_dict(), './VGG16.pth') 188 189 if __name__ == "__main__": 190 # 定义训练使用的设备 191 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') 192 # 使用自定义的VGG16类实现VGG16网络 193 # 由于CIFAR100有100种类别,所以修改VGG网络的输出层神经元数量,num_classes = 100 194 195 My_VGG16=My_VGG 196 net = My_VGG16(num_classes = 100) 197 train(net, train_loader, 198 test_loader, device, 199 #更改学习率 200 l_r=0.00003, 201 num_epochs=50)