微服务
微服务是一种经过梁高架构设计的分布式架构方案,微服务架构特征:
-
单一职责,微服务拆分粒度更小,每一个服务都对应唯一的业务能力,做到单一职责,避免重复业务开发
-
面相服务,微服务对外暴露业务接口
-
自治:团队独立,技术独立,数据独立,部署独立
-
隔离性强:服务调用做好隔离,容错,降级,避免出现级联问题
-
用户
- 服务网关
- 会员服务--->数据库
- 用户服务--->数据库
- 积分服务--->数据库
- 服务网关
单体架构特点
- 简单方便,高耦合度,扩展性差,适合小型项目
分布式架构特点
松耦合,扩展性好,但架构复杂,难度大,适合大型互联网项目
微服务:一种良好的分布式架构方案
- 优点:拆分粒度更小,服务更独立,耦合度更低
- 缺点:架构非常复杂,运维,监控,部署难度提高
Eureka作用
消费者该如何获取服务提供者具体信息?
- 服务提供者启动时向eureka注册自己的信息
- eureka保存这些信息
- 消费者根据服务名称向eureka拉取提供者信息
如果有多个服务提供者,消费者该如何选择?
- 服务消费者利用负载均衡算法,从服务列表中挑选一个
消费者如何感知服务提供者健康状态?
- 服务提供者会每隔30s向eurekaServer发送心跳请求,报告健康状态
- eureka会更新记录服务列表信息,心跳不正常会被剔除
- 消费者就可以拉取到最新的信息
在Eureka架构中,微服务角色有两类
- EurekaServer:服务端,注册中心
- 记录服务信息
- 心跳监控
- EurekaClient:客户端
- Provider:服务提供者,例如案例中的user-service
- 注册自己的信息到EurekaServer
- 每隔30s向EurekaServer发送心跳
- consumer:服务消费者,例如案例中的order-service
- 根据服务名称从EurekaServer拉取服务列表
- 基于服务列表做负载均衡,选中一个微服务后发起远程调用
- Provider:服务提供者,例如案例中的user-service
搭建EurekaServer
- 引入eureka-server依赖
- 添加@EnableEurekaServer注解
- 在application.yml中配置eureka地址
服务注册
- 引入eureka-client依赖
- 在application.yml中配置eureka地址
服务发现
- 引入eureka-client依赖
- 在application.yml中配置eureka地址
- 给RestTemplate添加@LoadBalanced注解
- 用服务提供者的服务名称远程调用
Ribbon负载均衡规则
- 规则接口是IRule
- 默认实现是ZoneAvoidanceRule,根据zone选择服务列表,然后轮询
负载均衡自定义方式
- 代码方式:配置灵活,但修改时需重新打包发布
- 配置方式:直观方便,无需重新打包发布,但是无法做到全局配置
- 饥饿加载
- 开启饥饿加载
- 指定饥饿加载的微服务名称
Feign的使用步骤
- 引入依赖
- 添加@EnableFeignClients注解
- 编写FeignClient接口
- 使用FeignClient中定义的方法代替RestTemplate
Feign的优化
- 日志尽量使用basic
- 使用HttpClient或OKHttp代替URLConnection
- 引入feign-httpClient依赖
- 配置文件开启HttpClient功能,设置连接池参数
网关的作用
- 对用户请求做身份认证,权限校验
- 将用户请求路由到微服务,并实现负载均衡
- 对用户请求做限流
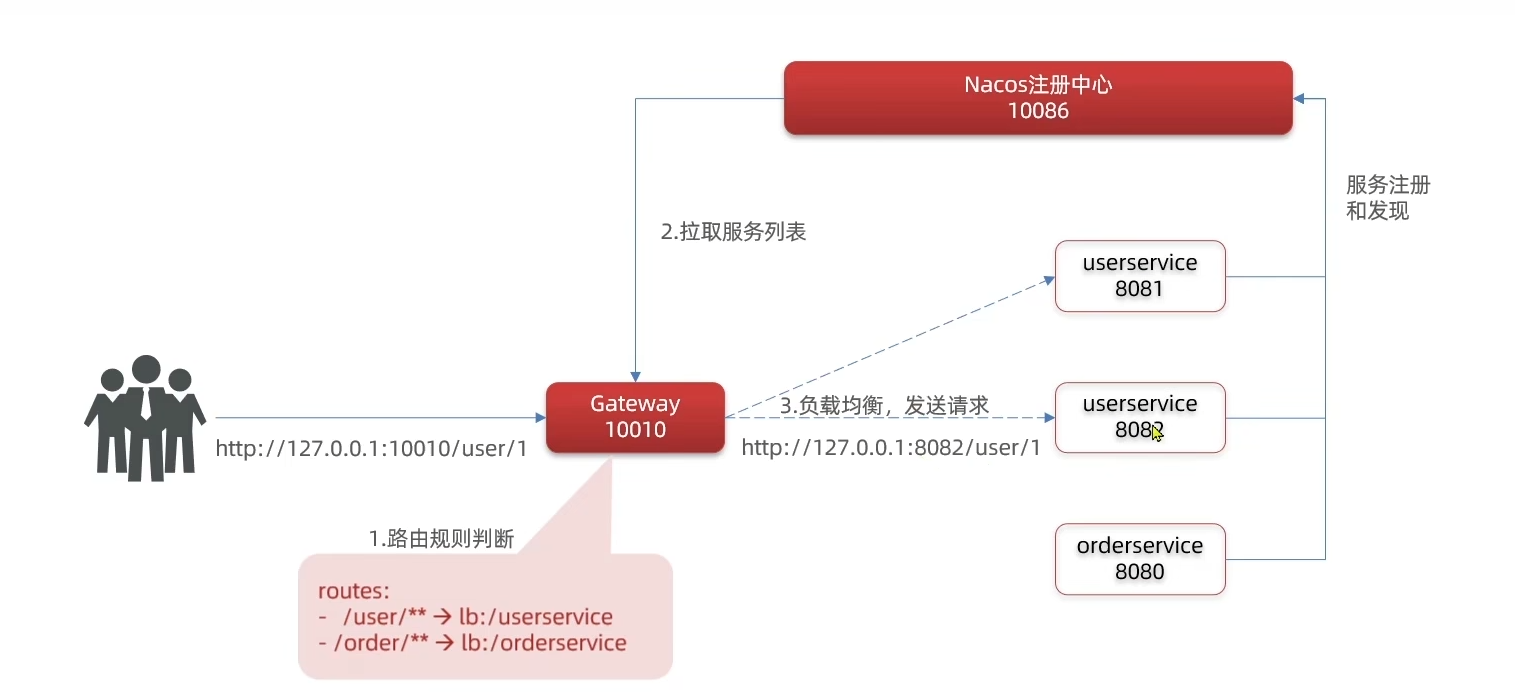
网关搭建步骤
- 创建项目,引入nacos服务发现和gateway依赖
- 配置application.yml,包括服务基本信息,nacos地址,路由
路由配置包括:
- 路由id:路由的唯一标识
- 路由目标(url):路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡
- 路由断言(predicates):判断路由的规则
- 路由过滤器(filters):对请求或响应做处理
PredicateFactory作用
读取用户定义的断言条件,对请求做出判断
Path=/user/**是什么意思
路径以/user开头就认为是符合的
过滤器的作用
- 对路由的请求或响应做加工处理,比如添加请求头
- 配置在路由下的过滤器只对当前路由的请求生效
defaultFilters的作用
对所有路由都生效的过滤器
CORS跨域要配置的参数包括哪几个?
- 允许哪些域名跨域
- 允许哪些请求头
- 允许哪些请求方式
- 是否允许使用cookie
- 有效期是多久
Docker
Docker是一个快速交付应用,运行应用的技术:
- 可以将程序及其依赖,运行环境一起打包为一个镜像,可以迁移到任意Linux操作系统
- 运行时利用沙箱机制形成隔离容器,各个应用互不干扰
- 启动,移除都可以通过一行命令完成,方便快捷
Docker和虚拟机的差异
- Docker是一个系统进程;虚拟机是在操作系统中的操作系统
- Docker体积小,启动快速,性能好,虚拟机体积大,启动速度慢,性能一般
镜像
将应用程序及其依赖,环境,配置打包在一起
容器
镜像运行起来就是容器,一个镜像可以运行多个容器
Docker结构
- 服务端:接收命令或远程请求,操作镜像或容器
- 客户端:发送命令或请求到Docker服务端
DockerHub
一个镜像托管的服务器,类似的还有阿里云镜像服务,统称为DockerRegistry
同步调用的优点
时效性强,可以立即得到结果
同步调用的问题
耦合度高,性能和吞吐能力下降,有额外的资源消耗,由级联失败问题
异步通信的优点
- 耦合度低
- 吞吐量提升
- 故障隔离
- 流量削峰
异步通信的缺点
依赖Broker的可靠性,安全性,吞吐能力
架构复杂了,业务没有明显的流程线,不好追踪管理
AMQP
应用间消息通信的一种协议,与语言和平台无关
SpringAMQP如何发送消息
- 引入amqp的starter依赖
- 配置RabbitMQ地址
- 利用RabbitTemplate的convertAndSend方法
elasticsearch
一个开源的分布式搜索引擎,可以用来实现搜索,日志统计,分析,系统监控等功能
elastic stack(ELK)
elastic stack是以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch
Lucene
Lucene是Apache的开源搜索引擎类库,提供了搜索引擎的核心API
文档和词条
每一条数据就是一个文档
对文档中的内容分词,得到的词语就是词条
正向索引
基于文档id创建索引,查询词条时必须先找到文档,然后判断是否半酣词条
倒排索引
对文档内容分词,对词条创建索引,病句路词条所在文档的信息,查询时现根据词条查询到文档id,然后获取到文档
- 文档:一条数据就是一个文档,es中是json格式
- 字段:json文档中的字段
- 索引:同类型文档的集合
- 映射:索引中文档的约束,比如字段名称,类型
elasticsearch与数据库的关系
数据库负责事务类型操作
elasticsearch负责海量数据的搜索,分析,计算