为何要做性能工程
性能是购买软件各种特性的货币:我们可以牺牲性能来换取下图中的属性

2004年之后,多核处理器流行了起来。其中每个独立的处理器核都可以参与各种运算,但性能工程仍然复杂因为其涉及到多个方面。如何编写软件来最大化利用硬件,这是此系列课程将要解决的问题。
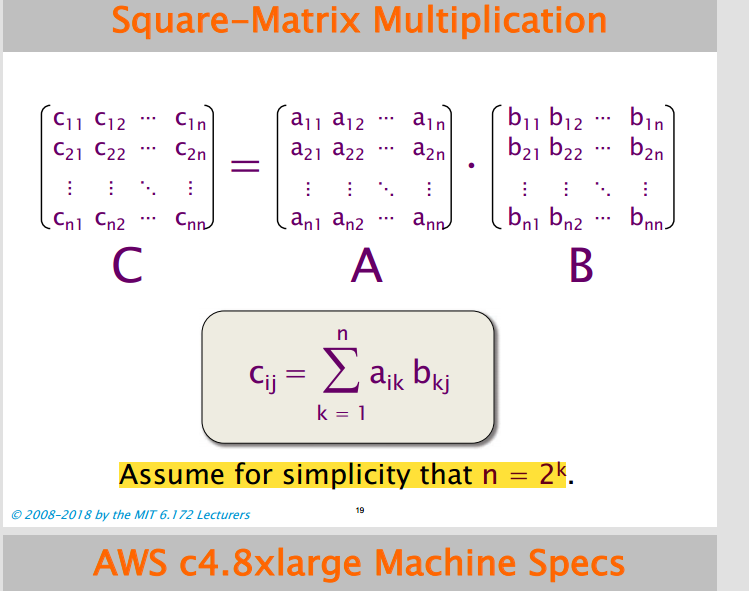
程序优化实例:矩阵乘法
矩阵乘法原理如下图,假设矩阵的大小为2的整数幂。
测试机器配置如下图:
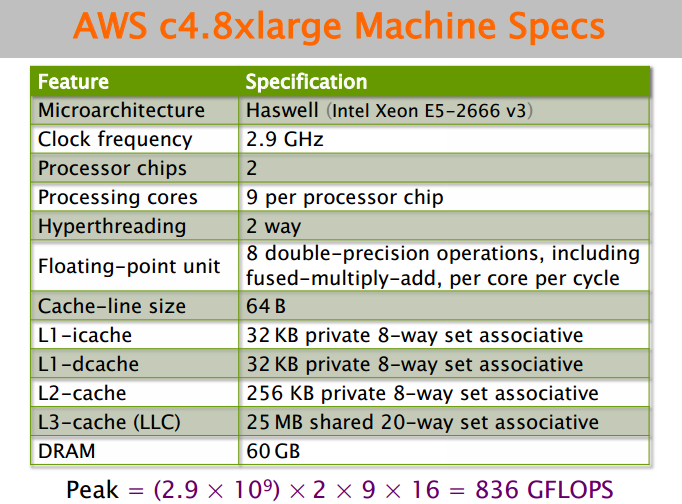
FLOPS(floating point operations per second)是衡量硬件性能的指标。
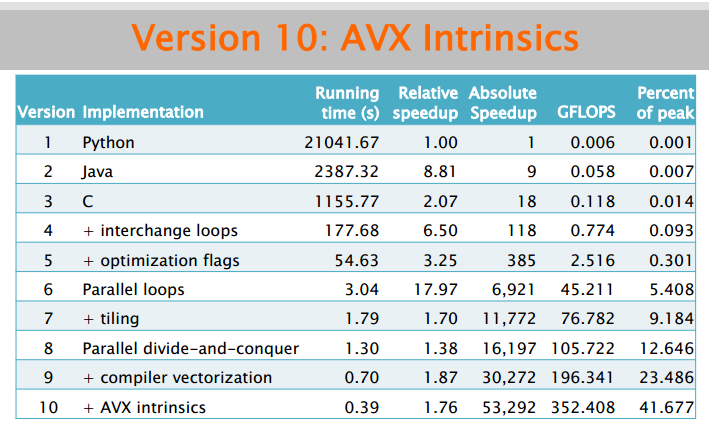
不同语言的性能差异
分别用Python、Java、C语言实现矩阵乘法,得到了下图所示的性能:

C最快,Python最慢。Python是解释型语言,解释器对于每条Python语句都需要读取语句、解释语句、执行语句、更新计算机状态这四个步骤。
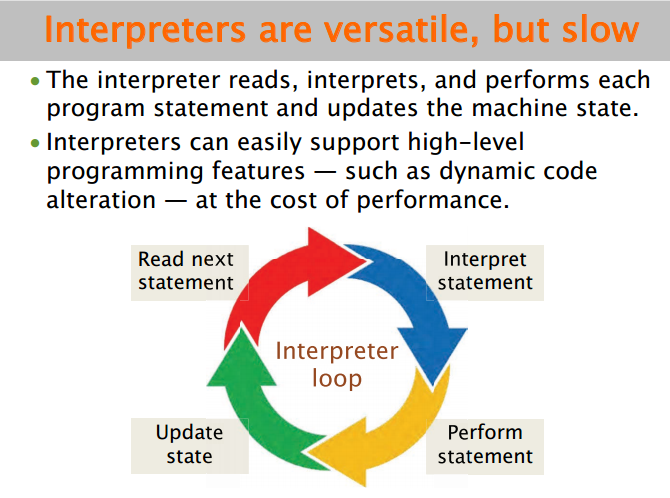
尽管解释器能容易地支持高级语言,但是相应地程序性能就下降了(性能作为货币)。
JIT编译器可以弥补解释器地部分性能缺陷:当某段Java代码被频繁执行时,运行时系统(runtime system)会把这段代码编译为机器码。
C编译器会将C代码编译为机器码,因此速度最快。
循环次序对性能的影响
如下图为i、j、k版本的矩阵乘法:

总共有6种循环次序,并且不同循环次序程序的性能差异可能很大。

这是由Cache命中率造成的。Cache line用来存储内存中连续的数据,每个CPU核都会从Cache读写数据,当要读写的数据已经在Cache时,读写速度非常快(Cache hit)。
来看j、k、i版本的矩阵乘法:
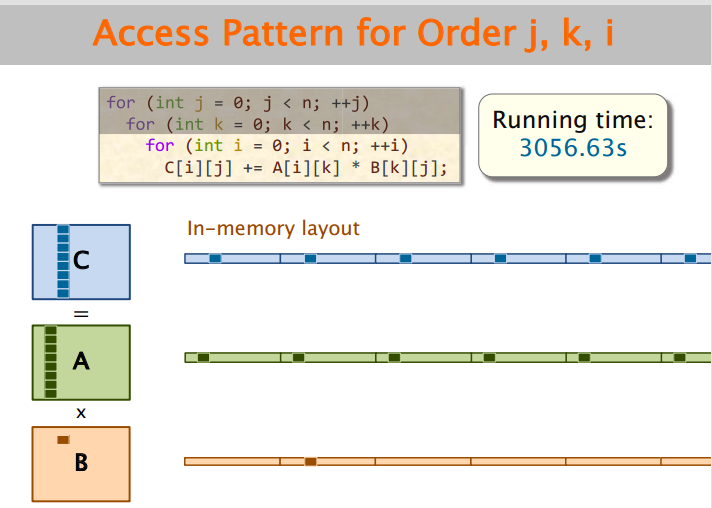
对矩阵C、A、B,每次读写的数据都是分散的,不能有效利用Cache,因此程序性能差。
编译器优化
为了进一步提高程序性能,在编译C程序时,加上O2标志让编译器优化程序。

多核并行
到目前为止,我们只用了18核中的1个核,这是一种浪费。clik_for(并行循环)可以使多核并行地执行循环。现在有三个循环,经过测试,把最外层循环的for替换为clik_for可以得到最佳的性能。一条经验:尽量并行化外层循环

分块矩阵乘法
回到Cache,我们可以重新组织矩阵的结构,使计算时得到更高的Cache命中率。把4096*4096的矩阵分块,做分块矩阵乘法。

经测试,分为32*32的子矩阵可以得到最佳性能
两级Cache的分块
之前的分块我们只有一个参数s,现在增加一个参数t,如下图:

我们能够写出下图的代码,这段代码会根据矩阵的规模选定不同的处理方式,当规模小于某个THRESHOLD时,直接用上图版本的代码,当规模较大时,用递归版本。

我们得到了更好的性能。
向量计算
现代处理器支持向量计算,以SIMD方式处理数据。
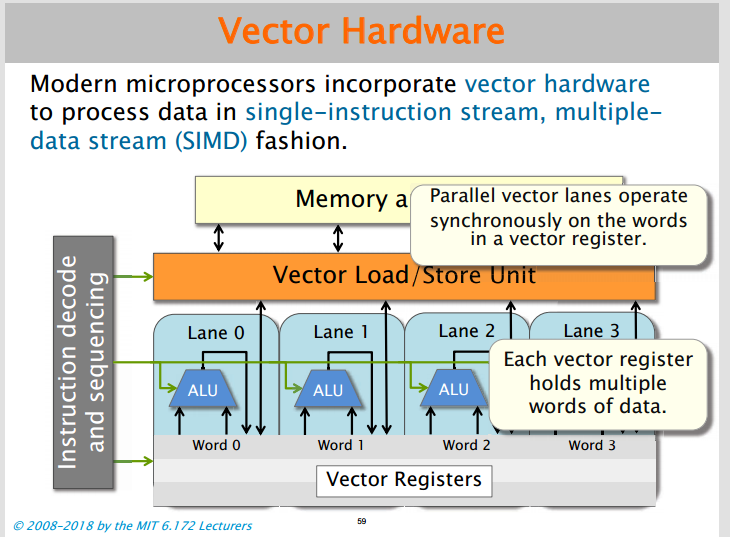
编译器可以为程序生成向量指令。我们得到了矩阵乘法程序的最终版本,程序的性能有了显著提高。