DSTAGNN模型可以看我上一个博客 学习笔记:DSTAGNN: Dynamic Spatial-Temporal Aware Graph Neural Network for Traffic Flow Forecasting
这篇博客主要写了我对代码中ST块部分的阅读。
写这篇模型的初衷,是这篇论文结构图和语言描述不太一致,再加上我想要学习怎么写一个时空预测的代码,所以就读了一下这个模型是怎么实现的。这篇博客的内容是ST块的几个组成成分,目前还在修改中。
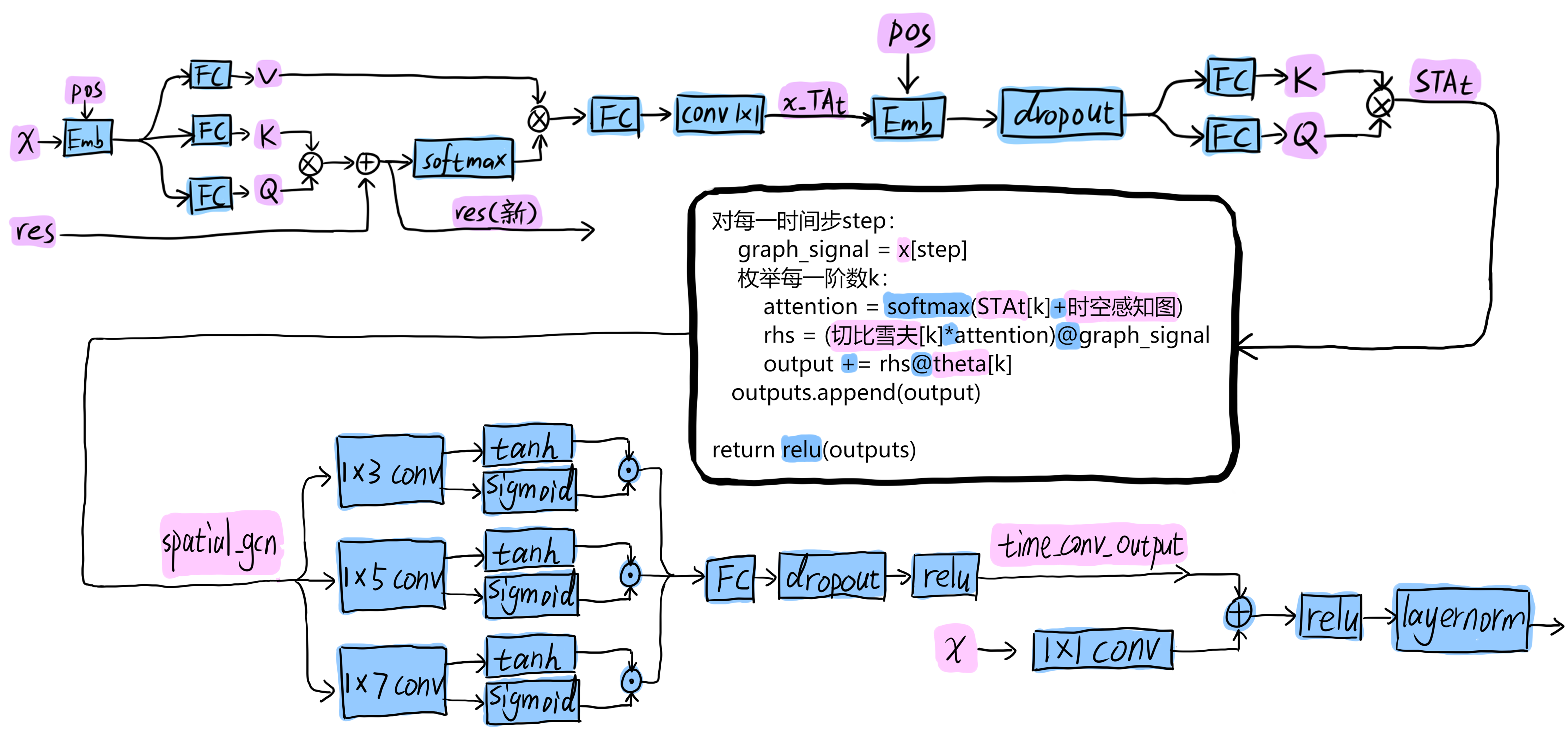 |
|---|
| 图1:整个ST块的结构 |
ST块分为 时间注意力模块TA、空间注意力模块SA、空间图卷积 Spatial Graph-Conv、时间图卷积 Temporal Gated-Conv、残差 共五个部分。
整体的代码为:
class DSTAGNN_block(nn.Module):
def __init__(self, DEVICE, num_of_d, in_channels, K, nb_chev_filter, nb_time_filter, time_strides, cheb_polynomials, adj_pa, adj_TMD, num_of_vertices, num_of_timesteps, d_model, d_k, d_v, n_heads):
super(DSTAGNN_block, self).__init__()
self.sigmoid = nn.Sigmoid()
self.tanh = nn.Tanh()
self.relu = nn.ReLU(inplace=True)
self.adj_pa = torch.FloatTensor(adj_pa).cuda()
self.pre_conv = nn.Conv2d(num_of_timesteps, d_model, kernel_size=(1, num_of_d))
self.EmbedT = Embedding(num_of_timesteps, num_of_vertices, num_of_d, 'T')
self.EmbedS = Embedding(num_of_vertices, d_model, num_of_d, 'S')
self.TAt = MultiHeadAttention(DEVICE, num_of_vertices, d_k, d_v, n_heads, num_of_d)
self.SAt = SMultiHeadAttention(DEVICE, d_model, d_k, d_v, K)
self.cheb_conv_SAt = cheb_conv_withSAt(K, cheb_polynomials, in_channels, nb_chev_filter, num_of_vertices)
self.gtu3 = GTU(nb_time_filter, time_strides, 3)
self.gtu5 = GTU(nb_time_filter, time_strides, 5)
self.gtu7 = GTU(nb_time_filter, time_strides, 7)
self.pooling = torch.nn.MaxPool2d(kernel_size=(1, 2), stride=None, padding=0, return_indices=False, ceil_mode=False)
self.residual_conv = nn.Conv2d(in_channels, nb_time_filter, kernel_size=(1, 1), stride=(1, time_strides))
self.dropout = nn.Dropout(p=0.05)
self.fcmy = nn.Sequential(
nn.Linear(3 * num_of_timesteps - 12, num_of_timesteps),
nn.Dropout(0.05),
)
self.ln = nn.LayerNorm(nb_time_filter)
def forward(self, x, res_att):
'''
:param x: (Batch_size, N, F_in, T)
:param res_att: (Batch_size, N, F_in, T)
:return: (Batch_size, N, nb_time_filter, T)
'''
batch_size, num_of_vertices, num_of_features, num_of_timesteps = x.shape # B,N,F,T
# TAT
if num_of_features == 1:
TEmx = self.EmbedT(x, batch_size) # B,F,T,N
else:
TEmx = x.permute(0, 2, 3, 1)
TATout, re_At = self.TAt(TEmx, TEmx, TEmx, None, res_att) # B,F,T,N; B,F,Ht,T,T
x_TAt = self.pre_conv(TATout.permute(0, 2, 3, 1))[:, :, :, -1].permute(0, 2, 1) # B,N,d_model
# SAt
SEmx_TAt = self.EmbedS(x_TAt, batch_size) # B,N,d_model
SEmx_TAt = self.dropout(SEmx_TAt) # B,N,d_model
STAt = self.SAt(SEmx_TAt, SEmx_TAt, None) # B,Hs,N,N
# graph convolution in spatial dim
spatial_gcn = self.cheb_conv_SAt(x, STAt, self.adj_pa) # B,N,F,T
# convolution along the time axis
X = spatial_gcn.permute(0, 2, 1, 3) # B,F,N,T
x_gtu = []
x_gtu.append(self.gtu3(X)) # B,F,N,T-2
x_gtu.append(self.gtu5(X)) # B,F,N,T-4
x_gtu.append(self.gtu7(X)) # B,F,N,T-6
time_conv = torch.cat(x_gtu, dim=-1) # B,F,N,3T-12
time_conv = self.fcmy(time_conv)
if num_of_features == 1:
time_conv_output = self.relu(time_conv)
else:
time_conv_output = self.relu(X + time_conv) # B,F,N,T
# residual shortcut
if num_of_features == 1:
x_residual = self.residual_conv(x.permute(0, 2, 1, 3))
else:
x_residual = x.permute(0, 2, 1, 3)
x_residual = self.ln(F.relu(x_residual + time_conv_output).permute(0, 3, 2, 1)).permute(0, 2, 3, 1)
return x_residual, re_At
时间注意力模块TA
语法说明
pre_conv = nn.Conv2d(T, d_model, kernel_size=(1, 1)) 三个参数分别是in_channels, out_channels, kernel_size。TATout是(B,F,T,N),而pre_conv( (B,T,N,F) )后得到 (B,d_model,N,F)
过程说明
 |
|---|
| 图2:时间注意力模块结构图 |
虽然特征数只有1,但是经过一次节点嵌入,将特征数变为F。
经过TAt函数后,得到TATout (B, F, T, N)和过程中用到的残差数据re_At (B, F, Ht(num_heads), T, T)
对TATout使用二维卷积操作,并变形得到 (B, N, d_model)
'''
:param x: (Batch_size, N, F_in, T)
:param res_att: (Batch_size, N, F_in, T)
:return: (Batch_size, N, nb_time_filter, T)
'''
batch_size, num_of_vertices, num_of_features, num_of_timesteps = x.shape # B,N,F,T
# TAT
if num_of_features == 1:
TEmx = self.EmbedT(x, batch_size) # B,F,T,N
else:
TEmx = x.permute(0, 2, 3, 1)
TATout, re_At = self.TAt(TEmx, TEmx, TEmx, None, res_att) # B,F,T,N; B,F,Ht,T,T
x_TAt = self.pre_conv(TATout.permute(0, 2, 3, 1))[:, :, :, -1].permute(0, 2, 1) # B,N,d_model
Embedding(N,d_Em,F)
语法说明
pos_embed = nn.Embedding(nb_seq, d_Em)表示词典中一共nb_seq个词,将每个词映射成一个d_Em维的向量。使用方法为embedding = pos_embed(x)
x.permute(0,2,3,1)就是调换维度位置。假如说调换后的是y,那么x[0,2,3,1]=y[0,1,2,3]
norm=nn.LayerNorm(d_Em)是对每单个batch进行归一化,即减去均值,再除以标准差。用法为Emx=norm(embedding)
过程
对于时间类型T:
pos是1到N的等差序列,它的形状变化:(N) -> (1,1,N) -> (B,F,N)
x是原始的数据,将x变形为(B,F,T,N)后,与pos_embed(pos)相加,也就是对x中不同的点进行了区分
最后进行归一化(B,F,T,N)
对于控件类型S:
pos是1到N的等差序列,它的形状变化:(N) -> (1,N) -> (B,N)
x形状为(B,N,d_model),与pos相加后,返回归一化后的结果 (B,N,d_model)
class Embedding(nn.Module):
def __init__(self, nb_seq, d_Em, num_of_features, Etype):
super(Embedding, self).__init__()
self.nb_seq = nb_seq
self.Etype = Etype
self.num_of_features = num_of_features
self.pos_embed = nn.Embedding(nb_seq, d_Em)
self.norm = nn.LayerNorm(d_Em)
def forward(self, x, batch_size):
if self.Etype == 'T':
pos = torch.arange(self.nb_seq, dtype=torch.long).cuda()
pos = pos.unsqueeze(0).unsqueeze(0).expand(batch_size, self.num_of_features,self.nb_seq) # [seq_len] -> [batch_size, seq_len]
embedding = x.permute(0, 2, 3, 1) + self.pos_embed(pos)
else:
pos = torch.arange(self.nb_seq, dtype=torch.long).cuda()
pos = pos.unsqueeze(0).expand(batch_size, self.nb_seq)
embedding = x + self.pos_embed(pos)
Emx = self.norm(embedding)
return Emx
MultiHeadAttention(d_model, d_k, d_v, n_heads, num_of_d)
语法说明
view操作是将原数据拉成一条后,再填充到新的形状中。对于Q.view(B,n_d,-1,n_heads,d_k),Q原本形状为(B, len_q, d_k*n_heads) -> (B, n_d, len_q/n_d, n_heads, d_k)。
过程
输入:Q、K、V,形状分别为:
(B, n_d, len_q, d_model)
(B, n_d, len_k, d_model)
(B, n_d, len_v(=len_k), d_model)
分别经过线性层后,再依次变形为
(B, n_d, n_heads, len_q, d_k)
(B, n_d, n_heads, len_k, d_k)
(B, n_d, n_heads, len_v(=len_k), d_v)
接着将Q K V输入到ScaleDotProductAttention函数中计算,得到
context=注意力结果(B, n_d, n_heads, len_q, d_v),res_attn=下一个res
再将context转置与变形成(B, n_d, len_q, n_heads*d_v)
然后经过全连接层,得到output (B, n_d, len_q, d_model)
最后 结果为归一化的output+原始的Q,作为残差流
返回 归一化后的结果,以及res_attn
class MultiHeadAttention(nn.Module):
def __init__(self, DEVICE, d_model, d_k ,d_v, n_heads, num_of_d):
super(MultiHeadAttention, self).__init__()
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.n_heads = n_heads
self.num_of_d = num_of_d
self.DEVICE = DEVICE
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask, res_att):
'''
input_Q: [batch_size, len_q, d_model]
input_K: [batch_size, len_k, d_model]
input_V: [batch_size, len_v(=len_k), d_model]
attn_mask: [batch_size, seq_len, seq_len]
'''
residual, batch_size = input_Q, input_Q.size(0)
# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)
Q = self.W_Q(input_Q).view(batch_size, self.num_of_d, -1, self.n_heads, self.d_k).transpose(2, 3) # Q: [batch_size, n_heads, len_q, d_k]
K = self.W_K(input_K).view(batch_size, self.num_of_d, -1, self.n_heads, self.d_k).transpose(2, 3) # K: [batch_size, n_heads, len_k, d_k]
V = self.W_V(input_V).view(batch_size, self.num_of_d, -1, self.n_heads, self.d_v).transpose(2, 3) # V: [batch_size, n_heads, len_v(=len_k), d_v]
if attn_mask is not None:
attn_mask = attn_mask.unsqueeze(1).repeat(1, self.n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
# context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k]
context, res_attn = ScaledDotProductAttention(self.d_k, self.num_of_d)(Q, K, V, attn_mask, res_att)
context = context.transpose(2, 3).reshape(batch_size, self.num_of_d, -1, self.n_heads * self.d_v) # context: [batch_size, len_q, n_heads * d_v]
output = self.fc(context) # [batch_size, len_q, d_model]
return nn.LayerNorm(self.d_model).to(self.DEVICE)(output + residual), res_attn
ScaleDotProductAttention()
语法说明
torch.matmul(a,b)两个矩阵做矩阵乘法。实际上不论a、b是多少维度的,都做的是二维矩阵乘法运算,只是把多余的维度看作batch罢了,可以参考torch.matmul()用法介绍
F.softmax(scores,dim=3)中dim是指执行softmax的维度。并不是把全部的加起来做分母,而是可能不同维度下分别计算。这里,scores的形状为(8,1,3,12,12),这里的12是时间窗口,dim=3这一维实际上是对时间维度做softmax。
过程说明
就如公式所说的:
返回的两个结果是Att和A。
不解 这里softmax(A)和V居然是矩阵乘法
class ScaledDotProductAttention(nn.Module):
def __init__(self, d_k, num_of_d):
super(ScaledDotProductAttention, self).__init__()
self.d_k = d_k
self.num_of_d =num_of_d
def forward(self, Q, K, V, attn_mask, res_att):
'''
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask: [batch_size, n_heads, seq_len, seq_len]
'''
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(self.d_k) + res_att # scores : [batch_size, n_heads, len_q, len_k]
if attn_mask is not None:
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True.
attn = F.softmax(scores, dim=3)
context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v]
return context, scores
空间注意力模块SA
 |
|---|
| 图3:空间注意力模块结构图 |
首先通过EmbedS对节点嵌入位置信息,归一化,dropout,得到SEmx_TAt (B, N, d_model)
再通过SAt函数,得到注意力系数STAt (B, n_heads, N, N)
# SAt
SEmx_TAt = self.EmbedS(x_TAt, batch_size) # B,N,d_model
SEmx_TAt = self.dropout(SEmx_TAt) # B,N,d_model
STAt = self.SAt(SEmx_TAt, SEmx_TAt, None) # B,Hs,N,N
SMultiHeadAttention(d_model, d_k, d_v, K)
输入为:Q和K (B, N, d_model)
Q和K --线性变换--> (B, N, d_k*n_heads) --变形--> (B, N, n_heads, d_k) --转置--> (B, n_heads, N, d_k)
返回 attn = 注意力中V需要乘的系数,形状为(B, n_heads, N, N)
class SMultiHeadAttention(nn.Module):
def __init__(self, DEVICE, d_model, d_k ,d_v, n_heads):
super(SMultiHeadAttention, self).__init__()
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.n_heads = n_heads
self.DEVICE = DEVICE
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
def forward(self, input_Q, input_K, attn_mask):
residual, batch_size = input_Q, input_Q.size(0)
# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)
Q = self.W_Q(input_Q).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2) # Q: [batch_size, n_heads, len_q, d_k]
K = self.W_K(input_K).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2) # K: [batch_size, n_heads, len_k, d_k]
if attn_mask is not None:
attn_mask = attn_mask.unsqueeze(1).repeat(1, self.n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
# context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k]
attn = SScaledDotProductAttention(self.d_k)(Q, K, attn_mask)
return attn
SScaledDotProductAttention(d_k)
和ScaledDotProductAttention类似,输入为Q和K (B, n_heads, N, d_k)
返回计算结果:\(QK^\top/\sqrt{d_k}\)
形状为 (B, n_heads, N, N)
class SScaledDotProductAttention(nn.Module):
def __init__(self, d_k):
super(SScaledDotProductAttention, self).__init__()
self.d_k = d_k
def forward(self, Q, K, attn_mask):
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(self.d_k) # scores : [batch_size, n_heads, len_q, len_k]
if attn_mask is not None:
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True.
return scores
空间图卷积 Spatial Graph-Conv
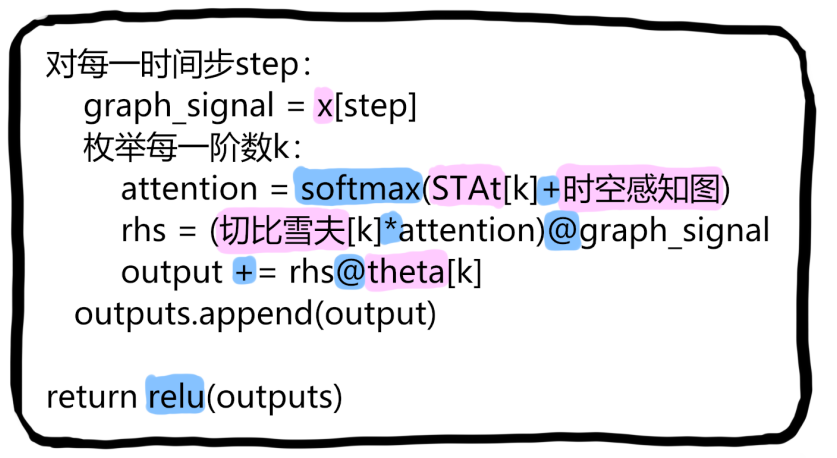 |
|---|
| 图4:空间图卷积结构图 |
输入:注意力系数STAt (B, n_heads, N, N)
输出:spatial_gcn (B, N, F, T)
# graph convolution in spatial dim
spatial_gcn = self.cheb_conv_SAt(x, STAt, self.adj_pa) # B,N,F,T
cheb_conv_withSAt(K, cheb_polynomials, in_channels, nb_chev_filter, num_of_vertices)
对每一时间步step:
graph_signal = x[step]
枚举每一阶数k:
attention = softmax(STAt[k]+时空感知图)
rhs = (切比雪夫[k]*attention)@graph_signal
output += rhs@theta[k]
outputs.append(output)
return relu(outputs)
class cheb_conv_withSAt(nn.Module):
'''
K-order chebyshev graph convolution
'''
def __init__(self, K, cheb_polynomials, in_channels, out_channels, num_of_vertices):
'''
:param K: int
:param in_channles: int, num of channels in the input sequence
:param out_channels: int, num of channels in the output sequence
'''
# 省略一部分
self.Theta = nn.ParameterList(
[nn.Parameter(torch.FloatTensor(in_channels, out_channels).to(self.DEVICE)) for _ in range(K)])
self.mask = nn.ParameterList( [nn.Parameter (torch.FloatTensor (num_of_vertices, num_of_vertices).to(self.DEVICE)) for _ in range(K)])
def forward(self, x, spatial_attention, adj_pa):
'''
Chebyshev graph convolution operation
:param x: (batch_size, N, F_in, T)
:return: (batch_size, N, F_out, T)
'''
batch_size, num_of_vertices, in_channels, num_of_timesteps = x.shape
outputs = []
for time_step in range(num_of_timesteps):
graph_signal = x[:, :, :, time_step] # (b, N, F_in)
output = torch.zeros(batch_size, num_of_vertices, self.out_channels).to(self.DEVICE) # (b, N, F_out)
for k in range(self.K):
T_k = self.cheb_polynomials[k] # (N,N)
mask = self.mask[k]
myspatial_attention = spatial_attention[:, k, :, :] + adj_pa.mul(mask)
myspatial_attention = F.softmax(myspatial_attention, dim=1)
T_k_with_at = T_k.mul(myspatial_attention) # (N,N)*(N,N) = (N,N) 多行和为1, 按着列进行归一化
theta_k = self.Theta[k] # (in_channel, out_channel)
rhs = T_k_with_at.permute(0, 2, 1).matmul(graph_signal) # (N, N)(b, N, F_in) = (b, N, F_in) 因为是左乘,所以多行和为1变为多列和为1,即一行之和为1,进行左乘
output = output + rhs.matmul(theta_k) # (b, N, F_in)(F_in, F_out) = (b, N, F_out)
outputs.append(output.unsqueeze(-1)) # (b, N, F_out, 1)
return self.relu(torch.cat(outputs, dim=-1)) # (b, N, F_out, T)
cheb_polynomial(L_tilde, K)
语法说明
np.identity(N)返回一个大小为N*N的单位矩阵
过程说明
返回k阶切比雪夫序列,也就是一个包含了k个NxN大小矩阵的列表。
(切比雪夫的推导方法:\(T_0=1,~T_1=x,~T_k=2xT_{k-1}-T_{k-2}\),这里的x是L拉普拉斯矩阵)
def cheb_polynomial(L_tilde, K):
'''
compute a list of chebyshev polynomials from T_0 to T_{K-1}
Parameters
----------
L_tilde: scaled Laplacian, np.ndarray, shape (N, N)
K: the maximum order of chebyshev polynomials
Returns
----------
cheb_polynomials: list(np.ndarray), length: K, from T_0 to T_{K-1}
'''
N = L_tilde.shape[0]
cheb_polynomials = [np.identity(N), L_tilde.copy()]
for i in range(2, K):
cheb_polynomials.append(2 * L_tilde * cheb_polynomials[i - 1] - cheb_polynomials[i - 2])
return cheb_polynomials
时间图卷积 Temporal Gated-Conv
 |
|---|
| 图5:时间图卷积结构图 |
输入:spatial_gcn
输出:time_conv_output
gtu3, gtu5, gtu7
fcmy=FC+Dropout
relu
# convolution along the time axis
X = spatial_gcn.permute(0, 2, 1, 3) # B,F,N,T
x_gtu = []
x_gtu.append(self.gtu3(X)) # B,F,N,T-2
x_gtu.append(self.gtu5(X)) # B,F,N,T-4
x_gtu.append(self.gtu7(X)) # B,F,N,T-6
time_conv = torch.cat(x_gtu, dim=-1) # B,F,N,3T-12
time_conv = self.fcmy(time_conv)
if num_of_features == 1:
time_conv_output = self.relu(time_conv)
else:
time_conv_output = self.relu(X + time_conv) # B,F,N,T
GTU(in_channels, time_strides, kernel_size)
输入:x (B,F,N,T)
x --conv2d--> [p,q] --tanh(p)*sigmoid(q)--> output
class GTU(nn.Module):
def __init__(self, in_channels, time_strides, kernel_size):
super(GTU, self).__init__()
self.in_channels = in_channels
self.tanh = nn.Tanh()
self.sigmoid = nn.Sigmoid()
self.con2out = nn.Conv2d(in_channels, 2 * in_channels, kernel_size=(1, kernel_size), stride=(1, time_strides))
def forward(self, x):
x_causal_conv = self.con2out(x)
x_p = x_causal_conv[:, : self.in_channels, :, :]
x_q = x_causal_conv[:, -self.in_channels:, :, :]
x_gtu = torch.mul(self.tanh(x_p), self.sigmoid(x_q))
return x_gtu
残差
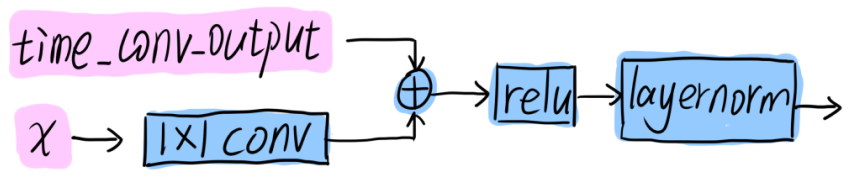 |
|---|
| 图6:残差结构图 |
# residual shortcut
if num_of_features == 1:
x_residual = self.residual_conv(x.permute(0, 2, 1, 3))
else:
x_residual = x.permute(0, 2, 1, 3)
x_residual = self.ln(F.relu(x_residual + time_conv_output).permute(0, 3, 2, 1)).permute(0, 2, 3, 1)