作业①:
要求:
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(
)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
(spider)点击查看代码
import scrapy
from demo.items import WeatherItem
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider"
start_urls = 'http://www.weather.com.cn/'
imagePath = r"C:\Users\王俊凯wjk\PycharmProjects\pythonProject\数据采集作业点\数据采集"
def start_requests(self):
url = MySpider.start_urls
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
images = selector.xpath("//img/@src").getall()
for image in images:
item = WeatherItem()
item['wimage'] = image
yield item
except Exception as err:
print(err)
(items)点击查看代码
class WeatherItem(scrapy.Item):
# NO = scrapy.Field()
wimage = scrapy.Field()
pass
(pipelines)点击查看代码
class WeatherImagePipeline(object):
count = 0
def process_item(self, item, spider):
WeatherImagePipeline.count += 1
try:
imagepath = "./爬虫图片" + str(WeatherImagePipeline.count) + ".jpg"
urllib.request.urlretrieve(item['wimage'], filename=imagepath)
imageurl = requests.get(item['wimage'])
with open(imagepath, "wb") as f:
f.write(imageurl.content)
print("下载成功")
except Exception as err:
print(err)
return item
多线程
CONCURRENT_REQUESTS = 32
输出结果
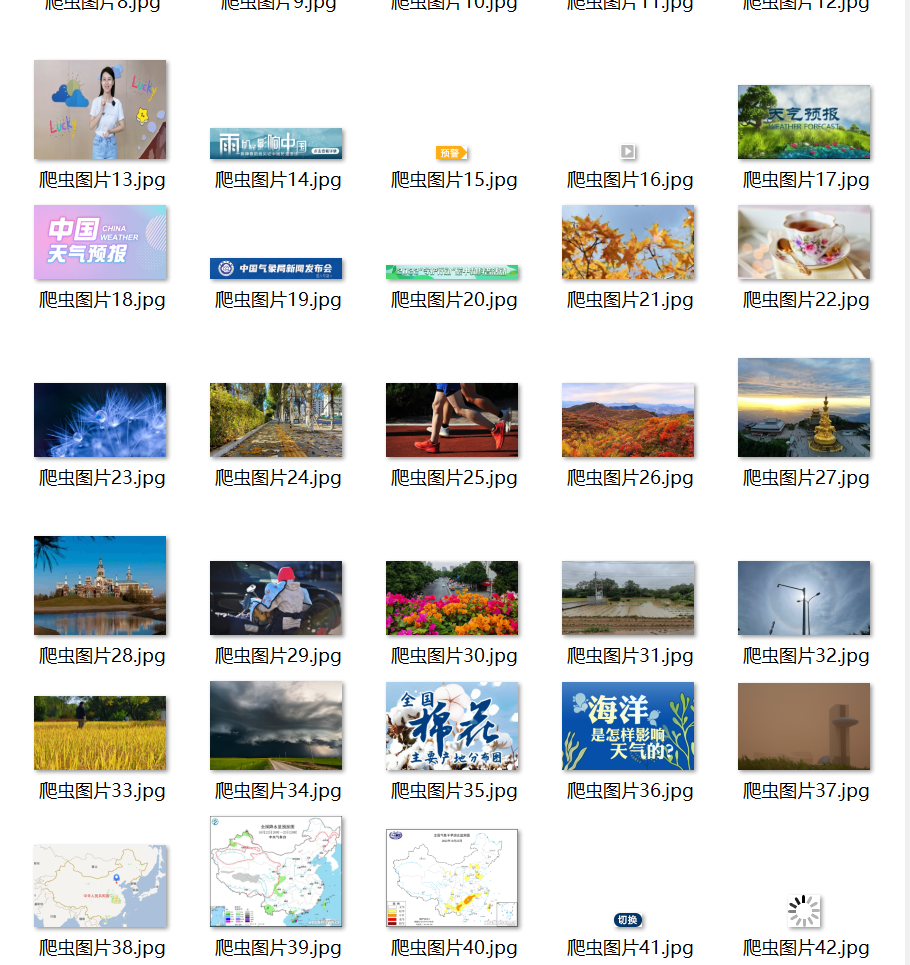
心得体会
该实验就是还是简单的使用到这个scrapy的框架,然后将图片存储下来的话还是很有难度的,后面也是回顾了之前的作业才搞定
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 振幅 最高 最低 今开 昨收
1 688093 N世华 28.47 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.20 17.55
2……
(spider)点击查看代码
import requests
import scrapy
from demo.items import StokeItem
from bs4 import UnicodeDammit
import re
import pandas as pd
import sqlite3
import pymysql
num = 1
class MySpider(scrapy.Spider):
name = "mySpider2"
start_urls = 'https://www.eastmoney.com/'
imagePath = r"C:\Users\王俊凯wjk\PycharmProjects\pythonProject\数据采集作业点\数据采集"
def start_requests(self):
url = MySpider.start_urls
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
url = 'http://84.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124015654504524695545_1697702280661&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18&_=1697702280662'
html = requests.get(url)
html = html.text
try:
m1 = re.findall('"f12":(.*?),', html)
m2 = re.findall('"f14":(.*?),', html)
m3 = re.findall('"f2":(.*?),', html)
m4 = re.findall('"f3":(.*?),', html)
m5 = re.findall('"f4":(.*?),', html)
m6 = re.findall('"f5":(.*?),', html)
m7 = re.findall('"f6":(.*?),', html)
m8 = re.findall('"f7":(.*?),', html)
m9 = re.findall('"f15":(.*?),', html)
m10 = re.findall('"f16":(.*?),', html)
m11 = re.findall('"f17":(.*?),', html)
m12 = re.findall('"f18":(.*?)}', html)
# print(m1)
item =StokeItem()
global num
for i in range(0, len(m1)):
item['m0'] =num
item['m1'] =m1[i]
item['m2'] =m2[i]
item['m3'] =m3[i]
item['m4'] = m4[i]
item['m5'] = m5[i]
item['m6'] = m6[i]
item['m7'] = m7[i]
item['m8'] = m8[i]
item['m9'] = m9[i]
item['m10'] = m10[i]
item['m11'] = m11[i]
item['m12'] = m12[i]
print(item)
yield item
num +=1
except Exception as err:
print(err)
(items)点击查看代码
class StokeItem(scrapy.Item):
m0 = scrapy.Field()
m1 = scrapy.Field()
m2 = scrapy.Field()
m3 = scrapy.Field()
m4 = scrapy.Field()
m5 = scrapy.Field()
m6 = scrapy.Field()
m7 = scrapy.Field()
m8 = scrapy.Field()
m9 = scrapy.Field()
m10 = scrapy.Field()
m11= scrapy.Field()
m12 = scrapy.Field()
pass
(pipeines)点击查看代码
class StockPipeline1(object):
num = 0
def process_item(self, item, spider):
conn = pymysql.connect(host="localhost", user="root", password="admin123", database="user",
charset='utf8') # 配置数据库信息
cursor = conn.cursor()
sql = '''
create table if not exists stock(
序号 int not null,
代码 char(30) not null,
名称 char(30) not null,
最新价格 char(30) not null,
跌涨额 char(30) not null,
跌涨幅 char(30) not null,
成交量 char(30) not null,
成交额 char(30) not null,
振幅 char(30) not null,
最高 char(30) not null,
最低 char(30) not null,
今开 char(30) not null,
昨收 char(30) not null)
''' # 创建对应的表wjk
cursor.execute(sql)
print(item['m1'], item['m2'], item['m3'], item['m4'], item['m5'], item['m6'],end='')
print("\t" + item['m7']+item['m8'], item['m9'], item['m10'], item['m11'], item['m1'])
cursor.execute(
"INSERT INTO stock(序号, 代码, 名称, 最新价格, 跌涨额, 跌涨幅, 成交量, 成交额, 振幅, 最高, 最低, 今开, 昨收) VALUES(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(item['m0'],item['m1'], item['m2'], item['m3'], item['m4'], item['m5'], item['m6'], item['m7'], item['m8'], item['m9'],
item['m10'], item['m11'], item['m12']))
conn.commit() # 提交指令
StokePipeline1.num += 1
return item
输出结果
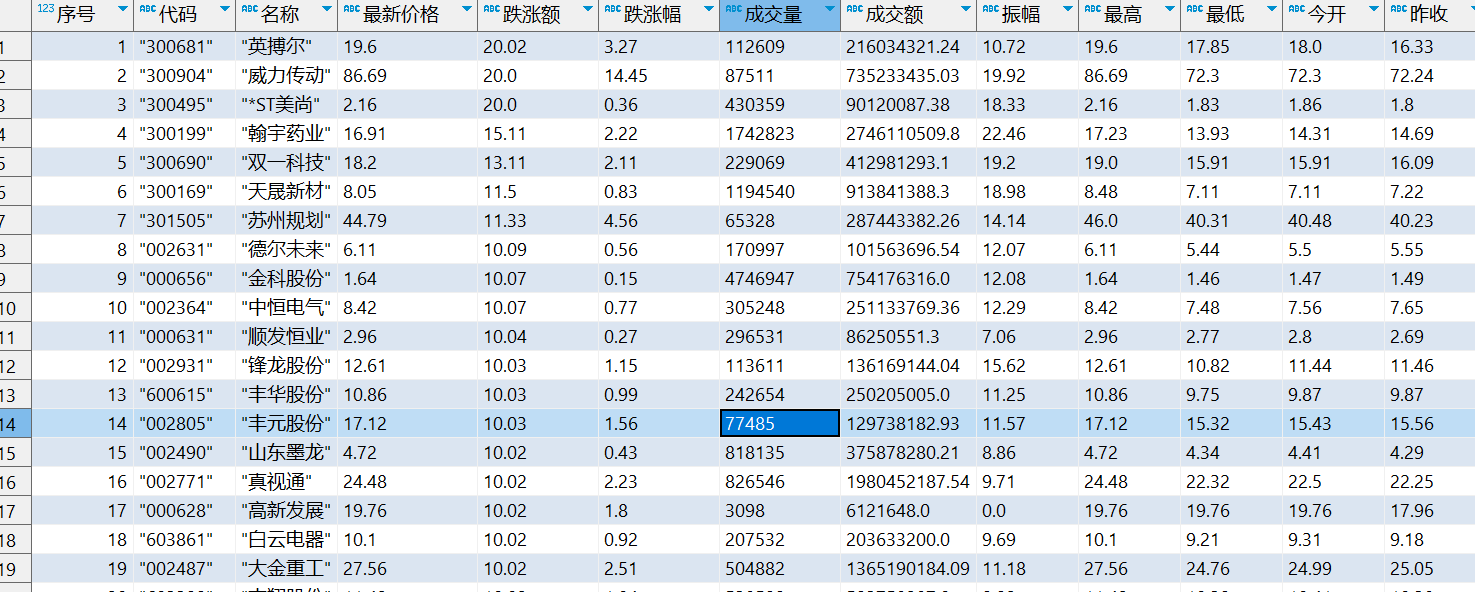
心得体会
虽然比较简单的爬取到了实验的数据但是对于怎么样把数据放入到数据库里面确实一大难点,后面再去研究了一下,才艰难搞定
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:****中国银行网:https://www.boc.cn/sourcedb/whpj/
输出信息:
Currency TBP CBP TSP CSP Time
阿联酋迪拉姆 198.58 192.31 199.98 206.59 11:27:14
(spider)点击查看代码
import re
import scrapy
from demo.items import CurrentItem
from bs4 import UnicodeDammit
from bs4 import BeautifulSoup
num = 1
class MySpider(scrapy.Spider):
name = "mySpider3"
start_urls = 'https://www.boc.cn/sourcedb/whpj/'
imagePath = r"C:\Users\王俊凯wjk\PycharmProjects\pythonProject\数据采集作业点\数据采集"
def start_requests(self):
url = MySpider.start_urls
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
global num
try:
html= BeautifulSoup(response.body, features='lxml')
table = html.find_all('table')[1]
rows= table.find_all('tr')
rows.pop(0)
for row in rows:
item = CurrentItem()
column = row.find_all('td')
item['no'] = num
item['name'] = column[0].text
item['TBP'] = column[1].text
item['CBP'] = column[2].text
item['TSP'] = column[3].text
item['CSP'] = column[4].text
item['Time'] = column[6].text
yield item
num +=1
except Exception as err:
print(err)
(items)点击查看代码
class CurrentItem(scrapy.Item):
no = scrapy.Field()
name = scrapy.Field()
TBP = scrapy.Field() # 现汇买入价
CBP = scrapy.Field() # 现钞买入价
TSP = scrapy.Field() # 现汇卖出价
CSP = scrapy.Field() # 现钞卖出价
Time = scrapy.Field()
pass
(pipelines)点击查看代码
class CurrentPipeline(object):
count=0
def process_item(self, item, spider):
conn = pymysql.connect(host="localhost", user="root", password="admin123", database="user",
charset='utf8') # 配置数据库信息
cursor = conn.cursor()
sql = '''
create table if not exists current(
no int not null,
name char(30) not null,
TBP char(30) not null,
CBP char(30) not null,
TSP char(30) not null,
CSP char(30) not null,
Time char(30) not null)
''' # 创建对应的表wjk
cursor.execute(sql)
# cuosor.execute("insert into stock(代码) values(%s)",item['m1'])
# insert = '''
# "INSERT INTO stock(序号, 代码, 名称, 最新价格, 跌涨额, 跌涨幅, 成交量, 成交额, 振幅, 最高, 最低, 今开, 昨收) VALUES(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
# '''
# param = (str(num), item['m1'],item['m2'],item['m3'],item['m4'],item['m5'],item['m6'],item['m7'],item['m8'],item['m9'],item['m10'],item['m11'],item['m12'])
# cursor.execute(insert,param)
cursor.execute(
"INSERT INTO current(no,name,TBP,CBP,TSP,CSP,Time) VALUES(%s,%s,%s,%s,%s,%s,%s)",
(item['no'],item['name'],item['TBP'],item['CBP'],item['TSP'],item['CSP'],item['Time']))
conn.commit() # 提交指令
return item
输出结果
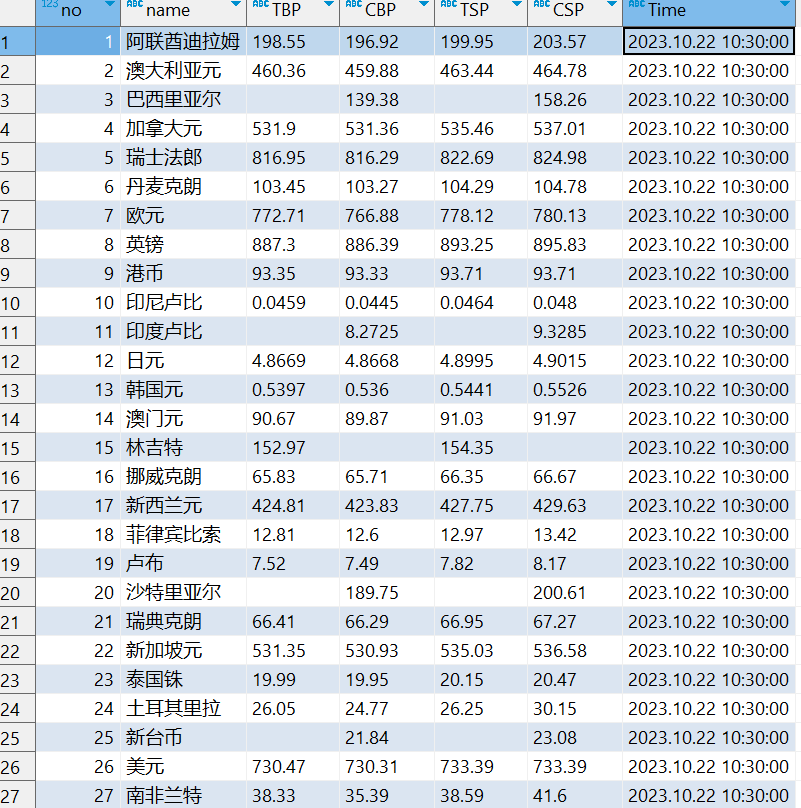
心得体会
这个就和上一个差不多,主要有了上一个将数据导入数据库的经验这个就简单一些了