第四章:超越经典搜索
上一章所讨论的问题具有如下性质:环境是可观察的、确定的、已知的,问题是一个行动序列。本章将讨论不受环境性质的约束。
1. 局部搜索算法和最优化问题
上一章提到的搜索算法,是为了找到一条或多条达到目标的路径。而在许多问题中,到达目标的路径是不相关的。在这种情况下我们要考虑一种不关心路径的算法。
「局部搜索」 算法从单个当前结点触发,通常只移动到它的邻近的状态。一般情况下不保留搜索路径。它只用很少的内存,能在很大或连续的状态空间中找到合理的解。
为了理解局部搜索,我们借助于 「状态空间地形图」。局部搜索算法就是探索这个地形图,最优的的局部搜索算法总能找到全局的最小值/最大值(具体最大最小,要看 \(y\) 轴代表什么)。
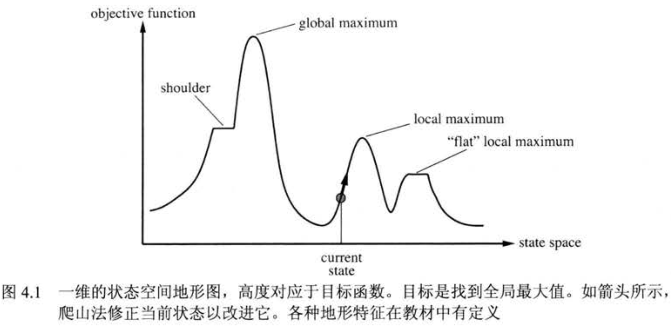
「爬山法」,是最基本的局部搜索计算,它是简单的用循环不断向值增加的方向持续移动。它只记录相邻状态,当相邻状态中没有比它值更高时就停止。因此,它可以很快朝着解的方向进展。
但我们也很清楚它的困境,它只能保证找到一个局部极大值,但它未必就是最大值,因此它更有可能只找到局部最优解;再者遇到「山脊」或比较平坦的「高原」,爬山法可能会迷路。

当然,有些技巧可以缓解这些情况。比如在高原上停止时进行 「侧向移动」,同时设置允许连续侧向移动的限制步数(为了避免死循环),这可以提升找到最优解的概率(和限制步数有关);
还有一些爬山法的变形,比如 「随机爬山法」,它的实现之一—— 「首选爬山法」,随机地生成后继结点直到生成一个优于当前结点的后继,虽说这会导致搜索时间的增加,但在后继结点很多时是个好策略。
但到目前为止我们描述的爬山法仍会困于局部极大值。而 「随机重启爬山法」 会在陷入停滞时,随机生成初始状态来引导爬山法继续搜索,直到找到目标。这种做法成功的概率接近1,因为它最终会生成一个目标状态作为初始状态(也就是选中了最大值作为起点)。
爬山法搜索从不下山,肯定是不完备的,可能会卡在局部极大值;纯粹的随机行走是完备的,但效率极低。而 「模拟退火搜索」 将二者进行了结合,兼具效率与完备性。其逻辑如下(用C++形式伪代码表示):
SolutionState Simulated_Annealing(problem, schedule)
{
SolutionState current = MakeNode(problem.INITAL_STATE);
for(int i = 0; i < Infinity; ++i)
{
float t = schedule(i);
if(t = 0) return current;
//随机获取1个后继状态结点作为移动点
SolutionState next = GetRandomNextNode(current);
//评估值 ΔE 衡量此移动是好是坏
float deltaE = next.value - current.value;
if(deltaE > 0) //如果这次移动变好,就进行移动
current = next;
else //如果这次移动变坏,就以e^(ΔE/t)的概率接受移动
current = ProbabilityTure(exp(deltaE/time));
}
}
「局部束搜索」 保存多个结点,且进行并行搜索。它从 \(k\) 个随机生成的状态开始,生成 \(k\) 个状态的所有后继状态,如果其中有一个为目标状态就停止,否则从生成的所有后继状态中选择最佳的 \(k\) 个状态并重复这个过程。
但如果这 \(k\) 个状态缺乏多样性,这个搜索过程就相当于重复执行了多次的普通爬山法。「随机束搜索」 可以解决这种问题,与随机爬山法类似,它不再从后继集合中选择最好的 \(k\) 个状态,而是随机选择 \(k\) 个后继状态,其中选择给定后继状态的概率是状态值的递增函数。
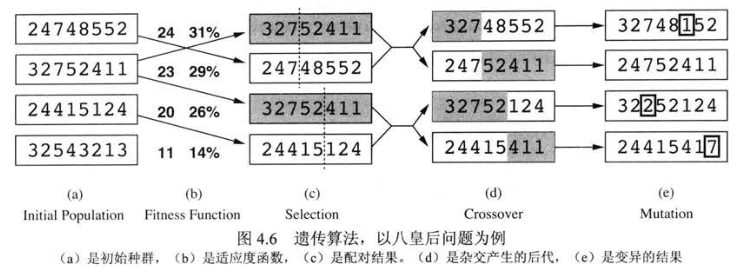
「遗传算法」 是随机束搜索的一个变形,它进一步模拟了自然选择的过程。像束搜索一样,它也从 \(k\) 个(为了方便繁殖,取偶数)随机生成的状态开始,我们称它们为 「种群」 其中每个状态就是「个体」。状态由它的目标函数或适应度函数给出评估值,对于好的状态,函数应当返回较高的值。
- 在每次搜索中,我们首先算出种群的总适应度(各个个体适应度之和),在求出每个个体的适应度与总适应度的比值作为每个个体的「繁殖概率」。繁殖概率是该个体被选中作为配对亲本的概率。
- 而后根据繁殖概率选出 \(k/2\) 对(一对中的两个个体不相同)个体,两两进行配对,配对的方法多种多样,比如选择 杂交点, 交换亲本中的某些数据。
- 通过上述步骤,我们会得到新的 \(k\) 个个体,我们还可以对它们进行「变异」,变异的方式同样多种多样,比如随机挑些一些数值进行变换。
- 用新个体重复执行这个过程,直到找到最优解。
2. 连续空间中的局部搜索
在第二章中我们区分了离散空间和连续空间,然而我们讨论过的算法(除了首选爬山法和模拟退火)没有一个能处理连续的状态和动作空间,因为连续空间里的分支因子是无限的。这一节我们来简要介绍在连续状态空间上寻找最优解的一些局部搜索技术。
避免连续性问题的一种简单途径就是将每个状态的邻近状态离散化。我们可以用尝试以一个很小的常数 \(a\) 作为 步长(就像微积分中的表示极小值的\(\delta\)),但调整 \(a\) 的具体值也是个学问,如果太小,搜索耗时会过大;过大,有可能会错过最大值;当目标函数无法用微分形式表示时,我们可以评估小的增减对其带来的影响,来决定爬山方向。
如果问题的解必须满足变量的某些严格约束,称此优化问题是受约束的。约束最优化问题的难点取决于约束和目标函数的性质。最著名的一种是 线性规划。
3. 使用不确定动作的搜索
如果环境是部分可观察的或是不确定的,Agent就无法直接感知每个行动的结果,感知信息就变得十分有用。这时,由于无法知道未来的动作,问题的解就不再是一个序列,而是一个 「应急规划」,即实时根据感知到的结果,来决定下一步行动,这就意味着它们是由嵌套if-else语句组成的树而不是序列。
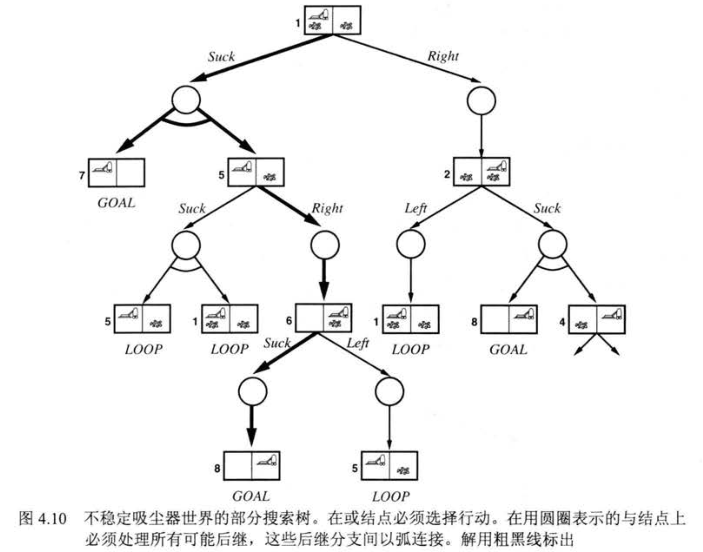
与或树的搜索同样可以用深度优先搜索和广度优先搜索,但要注意环的问题。也有一些别的算法,例如A*的变形,这些就不赘述了。
有时还会由于行动的不稳定,可能会出现问题的解是循环规划的情况,例如一个动作是将房卡插入房间锁,如果一次打不开,可能只是没插好,也有可能是拿错卡了。而我们需要对循环解作出判断,哪些时候视为放弃,哪些继续尝试,比如,就刚才的例子,在尝试多次仍打不开房门就应该是拿错卡了,可以考虑放弃。
4. 使用部分可观察信息的搜索
当Agent感知不足以精确描述状态,就需要 「信念状态」 。
1. 无观察信息的搜索
如果Agent感知不到任何信息,我们称之为 无传感问题,也称 相容问题。无传感Agent的问题很多时候是可解的,而且它不依赖传感器,有时反而更有用。
要求解无感知信息的问题,我们要在信念状态空间而不是实际状态空间中进行搜索。信念状态指各个状态的所有可能组合构成的大集合,包括那些不可能到达的。Agent的行动会将当前的信念状态转换到另一个信念状态,而Agent总是知道自己的信念状态空间,因此可以看作完全可观察,也就是说解总是一个行动序列。
但这种求解的方法需要非常多的信念状态,对于这个问题,我们可以尝试用更紧凑的方式来表示信念状态;也可以避免使用标准的搜索算法。
但即便是最有效的求解算法,在问题无解的情况下也毫无作为。
5. 联机搜索Agent和未知环境
联机搜索是指不再只是进行“头脑”推理,而是要联动机器,亲力亲为地搜索。迄今为止我们讨论的都是脱机搜索算法,而联机搜索Agent能通过交替地计算和行动来完成任务。这会让Agent把精力更集中在实际发生的事件上。
1. 联机搜索问题
联机搜索问题只能通过Agent执行行动来求解,它不是纯粹的计算过程。以寻找最短路径为例,如果Agent事先知道最短路径,那Agent会用实际经过的路径开销与之比较,这称之为 「竞争比」 ,并希望这个值越小越好。
尽管这听起来很合理,但某些情况下最好的竞争比仍是无穷大。比如走进死胡同的状态,这不同于脱机搜索,因为这是亲力亲为,一旦走进死胡同就不能在退回了。这也是机器人探索中的一个难点——各种各样的自然地形都可能是不可逆行的。
2. 联机搜索Agent
在每个活动之后,联机Agent都能接收到感知信息,告诉它到达的当前状态。在联机搜索中,Agent不得不实际进行回溯,要做到这一点,需要维护一个表,列出每个状态的所有还没回溯过的祖先状态。当Agent没有可回溯的状态了,那搜索就完成了。
3. 联机局部搜索
对联机Agent而言,爬山法用处不大,因为它陷入局部极大值后可能无路可走,并且不能随机重启(除非机器人可以传送)。
这时可以考虑 「随机行走」 来代替随机重启,以探索环境。随机行走是指在当前状态下随机选择可能的行动之一,选择的时候可以偏向选择那些尚未尝试过的行动。这个过程会很慢,但在状态空间有限的情况下,最终是可以找到目标的。
增加爬山法的内存而不是随机性是个更有效的方法。基本思想是存储从每个已经访问的状态s达到目标的代价的“当前最佳估计”,当Agent卡住时,就根据邻居状态的代价估计来选择达到目标的最佳可能路径。这样的Agent被称为实时学习A(LRTA)Agent,LRTA* Agent在任何有限的、可安全探索的环境中都确保能找到目标。
剩下一些关于联机Agent的学习等相关知识,还得后续章节中聊更合适。