hadoop包下载 https://archive.apache.org/dist/hadoop/common/
安装好jdk并配置环境变量
下载hadoop压缩包并放至 /data/hadoop目录
解压
tar -zxvf hadoop-3.3.5.tar.gz
1配置
1.1在Hadoop安装目录下进入到etc/hadoop目录,修改Hadoop相关配置文件。
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.80.236:9000</value>
<!--配置hdfs NameNode的地址,9000是RPC通信的端口-->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/data/tmp</value>
<!--hadoop的临时目录-->
</property>
<!-- 在Web UI访问HDFS使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
1.2 修改hdfs-site.xml 配置文件。
hdfs-site.xml文件主要配置跟HDFS相关的属性,具体配置内容如下所示。
<!-- NN web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.80.236:9870</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/data/dfs/name</value>
<!--配置namenode节点存储fsimage的目录位置-->
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/data/dfs/data</value>
<!--配置datanode节点存储block的目录位置-->
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<!--配置hdfs副本数量-->
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<!--关闭hdfs的权限检查-->
</property>
1.3 修改hadoop-env.sh配置文件。
hadoop-env.sh文件主要配置跟hadoop环境相关的变量,这里主要修改JAVA_HOME的安装目录,具体配置内容如下所示
JAVA_HOME=/usr/lib/jvm/jdk1.8.0_231/
1.4修改mapred-site.xml配置文件。
mapred-site.xml 文件主要配置跟MapReduce 相关的属性,这里主要将MapReduce的运行框架名称配置为YARN,具体配置内容如下所示。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<!--指定运行mapreduce的环境为YARN-->
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.80.236:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.80.236:19888</value>
</property>
1.5.修改 yarn-site.xml配置文件。
yarn-site.xml文件主要配置跟YARN 相关的属性,具体配置内容如下所示。
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>db</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<!--开启日志聚合-->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!--日志聚合hdfs存储路径-->
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data/hadoop/hadoop-3.3.5/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<!--hdfs上的日志保留时间-->
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<!--应用执行时存储路径-->
<name>yarn.nodemanager.log-dirs</name>
<value>file:///data/hadoop/hadoop-3.3.5/logs</value>
</property>
<property>
<!--应用执行完日志保留的时间,默认0,即执行完立刻删除-->
<name>yarn.nodemanager.delete.debug-delay-sec</name>
<value>604800</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://192.168.80.236:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.80.236:8088</value>
</property>
1.6 修改 workers
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
192.168.80.236
1.7 配置Hadoop环境变量。
vim ~/.bashrc
export HADOOP_HOME=/data/hadoop/hadoop-3.3.5
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
使用source命令执行.bashrc文件,才能使Hadoop环境变量生效
1.8 创建Hadoop相关数据目录
mkdir -p /data/hadoop/data/tmp
mkdir -p /data/hadoop/data/dfs/data
mkdir -p /data/hadoop/data/dfs/name
2.启动
2.1在Hadoop安装目录下,使用如下命令对NameNode进行格式化
bin/hdfs namenode -format
注意:第一次安装Hadoop集群需要对NameNode进行格式化,Hadoop集群安装成功之后,下次只需要使用脚本start-all.sh一键启动Hadoop集群即可。
2.2在Hadoop安装目录下,使用脚本一键启动Hadoop集群,具体操作如下所示
sbin/start-all.sh
2.3查看Hadoop服务进程
通过jps命令查看Hadoop伪分布集群的服务进程,具体操作如下所示。
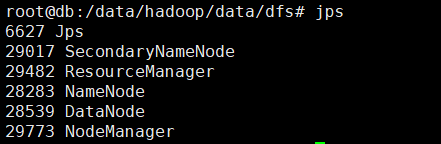
如果服务进程中包含Resourcemanager、Nodemanager、NameNode、DataNode和SecondaryNameNode等5个进程,这就说明Hadoop伪分布集群启动成功。
2.4查看HDFS文件系统在浏览器中输入http://192.168.80.236:9870/地址,通过web界面查看HDFS文件系统,具体操作如图所示
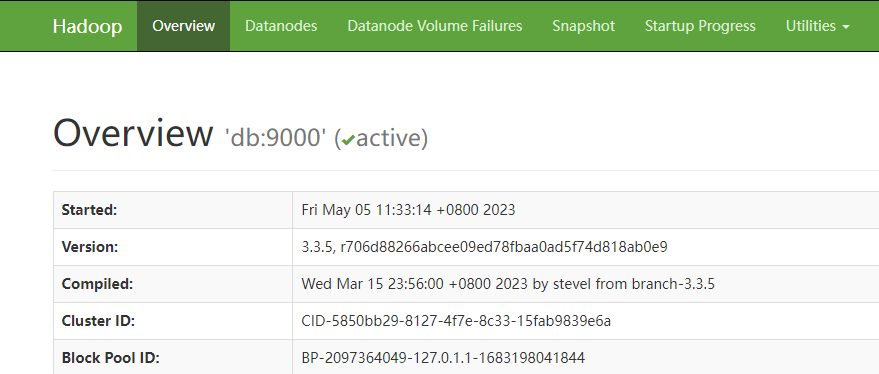
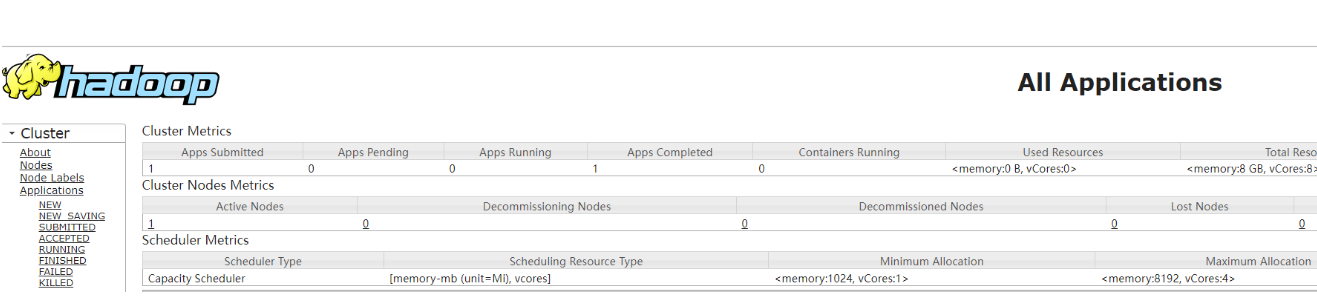
2.5查看YARN资源管理系统
在浏览器中输入http://192.168.80.236:8088/地址,通过web界面查看YARN资源管理系统,具体操作如图所示。
- 测试运行
Hadoop伪分布集群启动之后,我们以Hadoop自带的WordCount案例来检测Hadoop集群环境的可用性
3.1查看HDFS目录
在HDFS shell中,使用ls命令查看HDFS文件系统目录,具体操作如下所示。
bin/hdfs dfs -ls /
由于是第一次使用HDFS文件系统,所以HDFS中目前没有任何目录和文件
3.2 创建HDFS目录
在HDFS shell中,使用mkdir命令创建HDFS文件目录/test,具体操作如下所示。
bin/hdfs dfs -mkdir /test
3.3 准备测试数据集
在Hadoop根目录下,新建words.log文件并输入测试数据,具体操作如下所示。
vim words.log
hadoop hadoop hadoop
spark spark sparkflink
flink flink
3.4测试数据上传至HDFS
使用put命令将words.log文件上传至HDFS的/test目录下,具体操作如下所示。
bin/hdfs dfs -put words.log /test
3.5运行WordCount案例
使用yarn脚本将Hadoop自带的WordCount程序提交到YARN集群运行,具体操作如下所示。
bin/yarn jarshare/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar wordcount /test/words.log /test/out
3.6 查看作业运行状态
在浏览器中输入http://192.168.80.236:8088/地址,通过web界面查看YARN中作业运行状态,具体操作如图所示。
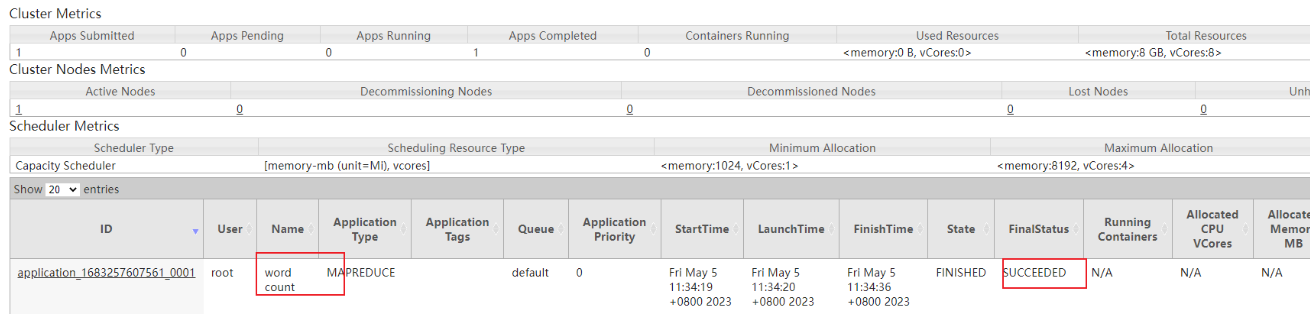
如果在YARN 集群的Web界面中,查看到WordCount作业最终的运行状态为SUCCESS,就说明MapReduce程序可以在YARN集群上成功运行。
3.7查询作业运行结果
使用cat命令查看WordCount作业输出结果,具体操作如下所示。
bin/hdfs dfs -cat /test/out/*
flink 3
hadoop 3
spark 3
如果WordCount运行结果符合预期值,说明Hadoop伪分布式集群已经搭建成功!
- 问题解决
4.1 解决 Hadoop 启动 ERROR: Attempting to operate on hdfs namenode as root 的方法
解决方案: 输入如下命令,在环境变量中添加下面的配置
vi /etc/profile
然后向里面加入如下的内容
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
输入如下命令使改动生效
source /etc/profile
4.2 Hadoop启动datanode节点All specified directories are failed to load报错解决方案
原因在于每次格式化时,namenode的clusterID会改变,而datanode的clusterID不会改变,造成namenode和datanode的clusterID不一致。以下是解决过程
此问题有两种解决方法
4.2.1更改datanode的clusterID,使其与namenode的ID一致
打开namenode的VERSION文件
vim data/dfs/name/current/
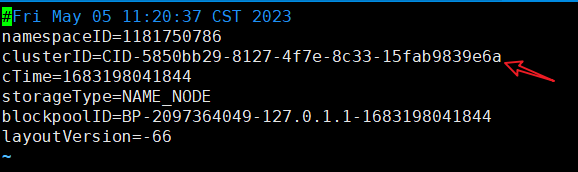
复制namenode的clusterID
打开datanode的VERSION文件,把clusterID修改为namenode的clusterID就好了
vim data/dfs/name/current/
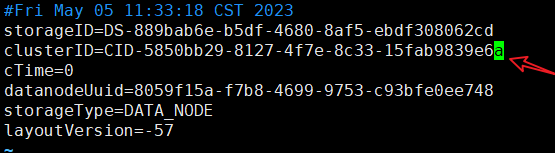
4.2.2 删除data目录的文件
cd到tmp目录下的data目录将data里面的文件全删了
4.3 Hadoop中的IP:50070无法连接
搭建完Hadoop分布式安装后,使用IP:50070显示无法连接,这是因为使用Hadoop3.0以上版本安装时,它的默认端口已经更改为9870,可以使用
netstat -ant查看端口是否开启
4.4 Hadoop-Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
在hadoop 环境下运行MapReduce 下wordCount出现以下错误:
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
根据报错提示
找到hadoop安装目录下$HADOOP_HOME/etc/hadoop/mapred-site.xml,增加以下代码
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>