简介
本文是论文Embedding-based Retrieval in Facebook Search的学习笔记
FB的社交搜索
搜索无处不在,搜索的种类多种多样,谷歌、百度、bing的全网搜索、淘宝京东的电商搜索,fb、微博、Twitter的社交搜索在人们的日常搜索中无处不在。区别于全网搜索,电商搜索、社交搜索有较高的个性化诉求。本文作为FB的EBR双塔召回模型的学习笔记,聚焦于社交搜索
由于全网搜索历史悠久,提到新兴的社交搜索之类,难免要跟全网搜做一个对比。不难发现除了全网搜索中历史悠久基于倒排索引的文本term匹配外,社交搜索还要关注搜索的上下文,而FB中用户之间的社交关系是最重要的一种上下文。例如在FB总可能有很多个叫张三 的人,某个用户搜索这个名字的时候,潜在的目的是搜索熟人、朋友中的张三。
论文发表前,FB的召回技术是经典且比较老的bool检索,所谓的bool检索就是将用户的query分词为多个term,每一个term召回一个倒排拉链,根据term之间的and or 等关系求交或者并集。随着神经网络模型的兴起,Ebr技术已经在全文检索领域广泛使用,却不常见于非全网搜场景。
FB的目的是将EBR技术运用到自家社交搜索,将单个Ebr扩展为联合embedding,实现一个个性化的双塔召回模型,并基于现有的倒排索引部署训练出的embedding,以提高搜索的高效性。
EBR技术
1 文本匹配
传统的基于倒排索引的召回属于文本匹配,例如一个搜索query 北京欢迎你 在去掉停用词后可能被切分成北京、欢迎 两个term,然后去倒排索引中的词典中找这两个词,有的话就把对应的倒排数据拉出来,然后通过bool检索 posting(北京) and posting(欢迎)找出同时出现这两个词的doc返回。
2 模糊匹配、语意理解
文本匹配的优点是能够做到精确匹配,但是也有缺点
-
模糊搜索:尽管文本匹配可以通过同义词等手段进行一定程度的模糊匹配,但是并不具有泛化通用性。而Ebr向量检索天然擅长这个
-
语意理解:搜索query A,A分词后term并不在文档D中,但实际上两者相关性很高。这就是另外一篇论文ranking relevance in yahoo search 中所说的query语言和文档语言不在一个“空间”内导致的语意gap,那篇论文里面提到了向量传播算法等解决方案。而深度学习Ebr技术天生擅长语意理解
Ebr是什么
简单来说就是把一个实体如term经过隐式计算,最终以低维稠密向量表示,然后这些实体、特征的embeding表示作为另一个业务场景的深度神经网络模型的输入参与模型训练。word2vec是一个专门把词训练成向量表示的工具,训练出来的词具有一些有意思的特征,例如它能得出如下关系:ebr(中国) - ebr(北京) + ebr(巴黎) = ebr(法国)
-
可以看出这是一种表示学习(represention)流派,学习term、各种特征的向量表示
-
正如word2vec论文中所说,emdeding的运用包括两个阶段
-
第一个阶段:通过一个语言模型的神经网络进行训练,作为中间参数的副产品被提取出来当作词的embedding。换句话说,这个模型的训练目标是A,然后训练完,我把某一层的参数向量拿出来作为词向量
-
第二阶段:某个特定的业务场景,比如电商搜索等可以将训练好的词向量作为模型的输入
-
Ebr 的运用和挑战
可以运用在召回、排序等阶段,但是在召回阶段可用武之地更大,召回阶段面临的是海量的数据,召回的数据质量的好坏,对最终的效果有根本的影响。
Ebr技术最终转换为向量空间2个emdeding的相似度,然而想一下,一个query如果和索引库里面所有的embeding比较,在耗时上是一个根本无法完成的任务,可以将之转换为近邻检索问题,以解决检索性能的问题。
-
训练阶段、在线服务阶段面临的数据规模非常大
-
不同于计算机视觉,检索场景在召回层面还有统筹考虑文本匹配召回
EBR在Fb搜索场景的运用、难点、trics
1 FB搜索场景
fb的搜索场景里,不仅要考虑搜索的query,还要考虑是谁在搜索这个query,以及相应的社交关系上下文等。因而不能简单地只对query进行embedding化,而是需要一个联合embedding框架,它能同时把多个特征编码到同一个embedding中。基于联合embedding技术,fb提出了一个双塔模型,其中一个是query 塔,另外一个是doc 塔,每一个可以联合embedding多种特征,每一个塔是一个单独的神经网络。2个塔之间最终产生的向量它们之间的相似度作为训练目标。
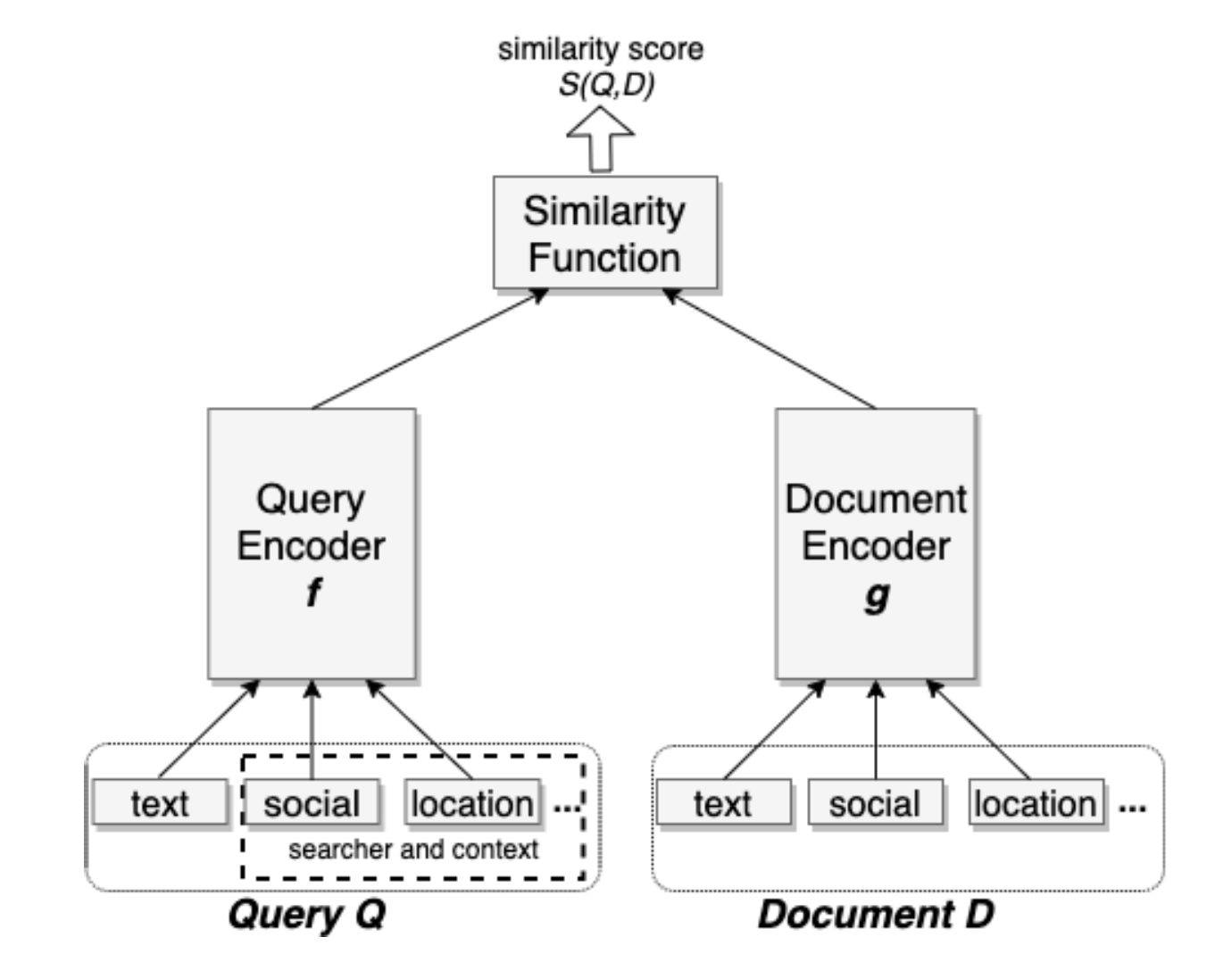
2 难点
从搜索日志中挖掘提取训练样本,从搜索上下文中提取特征,为了快速迭代使用召回评估标准。题外话:谷歌有一篇关于冷启动问题的论文,讨论了很多<query,doc>不在搜索日志中的处理方案。
构建一个基于表示的检索模型有效率、有效性两方面的挑战。本文使用了一些技巧
-
hard mining:挖掘难的正负样本,难指的是距离反方向的目标样本非常接近但并不是他,例如难负样本和和正样本非常接近,但是它其实是负样本。感性上来看,训练数据变的更难了,那么训练出的模型识别doc的敏感度就会提高。当然同时也会受到其他因素的因素,并不是难的样本越多越好,后文会谈到这点
-
ensemble embeding:将模型划分为多个阶段,每一个阶段可以有不同的召回精度和性能之间的tradeoff。例如后文提到的模型的级联、加权
3 部署方案的简介
单独部署embeding检索同路并和现有的倒排召回结合是次优方案,不是最优的,它的缺点如下
-
实验证明有较大的性能问题
-
双路索引维护成本较大
-
2路索引重叠部分比较大
因此fb搞了一个混合检索框架,将embedding-knn融入到现有的倒排召回方案中,实现一个基于倒排的ann检索。embeding的召回表达式可以嵌入到bool表达式中。具体来说是使用FAISS库将embedding向量量化压缩作为一个特征存储到倒排索引中。
FB还将embedding送入到排序层,来建立一个反馈回路来验证一些badcase,修正校准底层召回模型。
个人理解:相对于召回层,排序层看到的候选集合比较小,因此可以利用更多的特征对结果进行排序,
排序的结果更准确,假如embeding召回的顺序是1,2 排序后是2 1,那么这个也可以反过来调整召
回模型的训练。
模型
把搜索看作一个召回率优化问题,进而把召回问题看作排序问题:query和doc之间的距离。 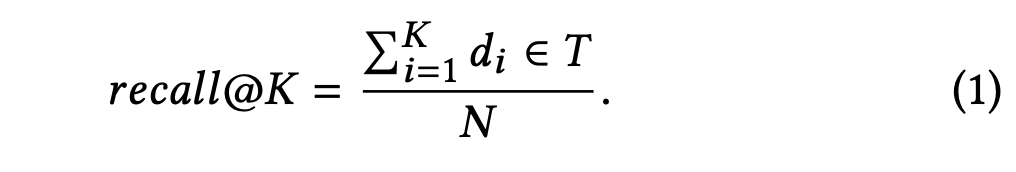
损失函数
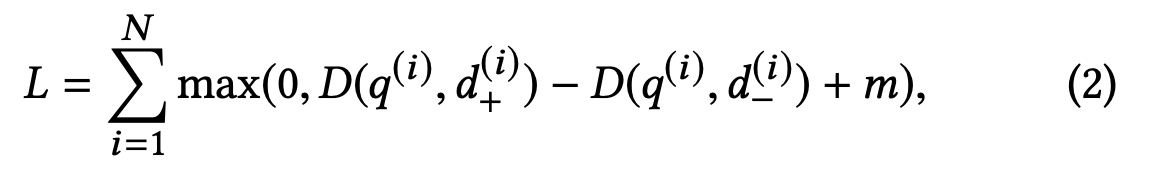
看这个损失函数:query和正样本的距离 减去 query和负样本的距离,直觉上前者的值代表query和正样本的相似度,越大越好,后者越小越好,整合起来整个算式越大越好。其中调整m的值比较重要,在不同的训练集上甚至可以达到5%-10%的准确度差异。
这种损失函数是所谓的tripplet 损失(\(q,d_+,d_-\)),更常见的一种损失函数式L = f(x) - y这种,f(x)是预测值,y是标签值,最小化L就是训练目标,一般是通过求导反向传播的方式更新参数,会使用到诸如随机梯度下降、丢弃法等手段来解决模型迭代过程中的一些问题。
Unified Embedding Model
即前文提到的将多个特征联合到一块embedding,query侧可以联合用户地理位置、社交关系;doc侧联合地理位置和群组信息等一块embedding。
挖掘训练数据
用户点击过的样本作为正样本,负样本有2种,一种是随机产生的样本作为负样本,另一种是展现但是未点击过的doc作为负样本。实验结果显示第二种负样本方案效果比较差。作者认为可能是搜索中绝大多数doc都是不匹配的简单case,而展现未点击属于比较难的case,因此训练集中难的样本分布和实际搜索的分布不一致,导致效果较差。后文作者会提出如何运用难的样本来区分不容易判断正负相关的问题,同时又不会损失对简单case的区分。
-
点击过的算正样本
-
把召回看作排序,排序在TOP的结果也是召回想返回的,因此同等对待展现但是未点击的样本,无差别地看作正样本
特征工程
文本特征
使用基于字符的n-gram比word-n-gram效果更好,lookup表小、更健壮、没有out-of-vocabulary 问题。不过在char-3-gram里引入word-ngram会带来些许提升。淘宝的多粒度语义似乎有类似的思想。
和bool检索比,即使ebr只使用文本特征去embedding也能取得在模糊搜索、可替代搜索方面更好的效果。前者:kacis creationsvs Kasie’s creations; 后者:mini cooper nw vs Mini cooper owner/drivers club
地理位置特征
-
query (城市、国家、语言)
-
doc (管理员标记的group location)
社交关系特征
使用一个单独的模型来基于社交关系训练用户、其他实体的embedding,最后集成到联合embedding方案中。
在线服务
1 ANN
构建一个基于倒排索引的近似最紧邻检索系统,经过量化压缩的embedding占用存储空间较小,且能和现有的检索系统结合,这是一个优点。首先使用FAISS进行量化压缩,然后集成部署到现有的倒排索引库。
量化压缩的2个主要部分:粗量化、production 量化
-
粗聚类:使用k-means算法划分粗粒度的cluster,IMI IVF
-
production 量化: 目的是为了高效的计算向量之间的距离,PQ OPQ
-
nprobe: 决定query应该被分配多少个cluster,进而影响检索的粗聚类的个数
总结出来的一些trics
-
用扫描到的文档数量来作为评判标准对召回进行tune
-
ANN对模型的特点比较敏感,如果模型有不可忽略的改变,那么要调整ANN的参数
- 例如当使用了量化压缩后,不调整ann参数的情况下,表现反而不如基线
-
我们需要对之前的数据进行量化,OPQ表现的比PCA好
-
pq压缩后的字节数,最好是d/4, d是原始embedding向量的维度。过高的字节数虽能获得高精度,但是内存吃不消。
-
在线调整Tune nprobe, num_clusters, and pq_bytes等参数,以在性能和召回之间达到一个tradeoff
2 系统实现
扩展现有的文档表示,引入embedding以支持NN。索引阶段的做法论文原文如下,看起来意思应该是:embeding量化后,存入term对应的倒排表和payload里面。在lucene里面每一个文档可以有若干个名字为payload的属性,在检索的时候可以提供一些信息,此处的payload应该也是类似的用法。
At indexing time, each document embedding is quantized and
turned into a term (for its coarse cluster) and a payload (for the
quantized residual).
TopK mode 需要遍历全部文档找到最相似的结果,residual mode只需要遍历部分文档效率高,本文是residual模式。residual模式理解起来,应该是说匹配的过程根据近邻算法,只需要遍历某几个cluster,在cluster里面找到residual符合要求的doc.
混合检索

模型在线服务
双塔模型训练完后,query 侧的模型用于在线对query进行推理;doc侧的模型训练出的embedding和其他元信息一块存储到正排索引中,经过粗量化、笛卡尔积量化压缩后发布到倒排索引中
3 query和index选取
有明确意图的不会出发ebr检索。
后续阶段到优化
-
当前fb到排序模型是针对当前到系统,新引入的embedding如何进行排序?一个方案是将embedding作为一路排序特征携带过来
-
ebr检索和文本检索比在精度上有劣势,引入基于人工评估的闭环反馈回路,不断调整相关性模块。
后续淘宝的Ebr论文里面也提到了embedding召回的相关性问题,并提出了一些解决办法:平滑训练数据集中的噪音、通过差值计算生成难负样本,其中难负样本应该是借鉴了FB论文里面的技巧。
高级话题
1 难样本挖掘
随机负样本有时候表现不太好,应该提升样本识别的难度,以提高模型对正负样本的区分度。用大白话说,所谓的难负样本就是:识别为负样本的难度比较大,不小心的话就识别成正样本了。难正样本概念类似。
1.1 在线难负样本挖掘
正如模型训练阶段使用的mini-batch一样,一个batch里面有多个query,每一个query对应一个正样本,我们把这个batch里面的所有正样本收集起来,去掉QueryN对应的正样本后,剩余的样本集作为难负样本参与模型训练。实验发现每一个正样本最多2个难样本参与训练,否则模型的质量会退化。原因可能是:真实的搜索场景里大部分doc都是比较简单的负例,很容易区分,难的只占少数
1.2 离线难负样本挖掘
根据实验,反直觉的是:仅仅只用难负样本不如使用随机负样本的效果。如下是离线挖掘难负样本的步骤
-
为每一个query召回topK
-
根据策略选择难负样本
-
混合随机负样本、难负样本,easy:hard = 100:1
-
101 - 500 位置的数据作为难负样本。当然考虑到计算资源问题,可以用ANN在随机的cluster上召回数据来产生难负样本。
-
-
重新训练模型
-
迭代上面步骤
迁移学习(transfer learning): 实验还发现,训练的easy模型迁移到hard模型上没有效果,反之则有明显的效果。论文里面的迁移学习应该指的是预训练:已经训练好的模型具有泛化性,它的参数迁移到新的模型上去参与训练。
1.3 难正样本挖掘
新入库的结果,没有成功被召回过,但是确实正样本,通过失败的搜索会话,挖掘潜在的样本作为难正样本
2 ensemble 模型
用随机负样本训练的模型对大的k of topK比较有效,对于小k效果一般。用未展现未点击的样本在小数据集上进行排序效果不错,但是在召回阶段却失败了。因此提出一个组合模型,多阶段,多hard-level方案,第一阶段聚焦召回,第二阶段在第一阶段召回的结果基础上将比较接近的结果区分开来。包括并行加权和级联模式
并行加权
如下图所示,n个模型训练出来的emd表示计算cosine相似度后加权打分来衡量<q,doc>对的相近程度。最后多个模型训练的向量需要整合到一个最终的embedding里面。
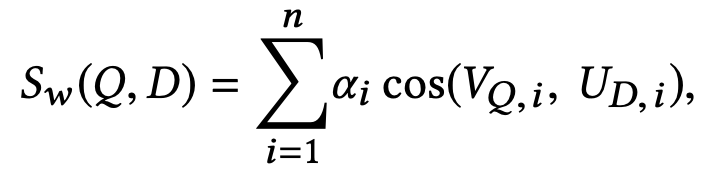
整合的方式如下,归一化加权
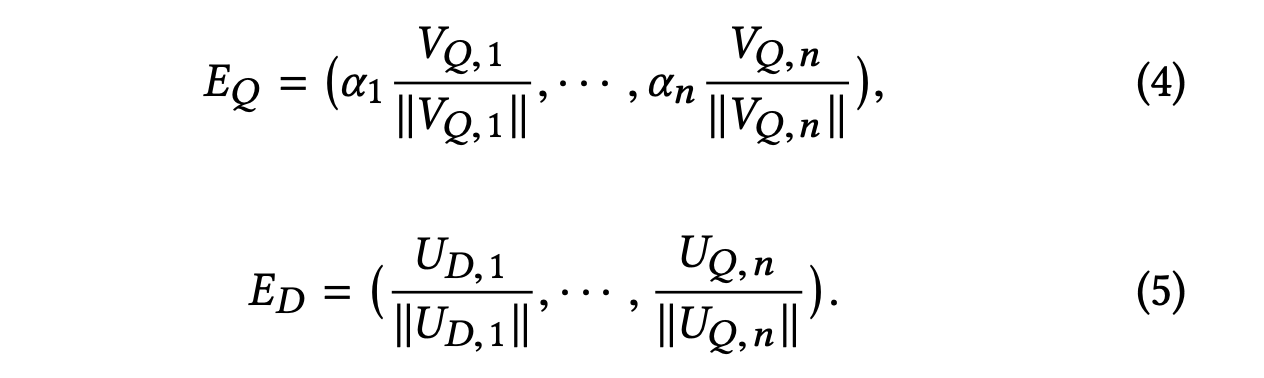
它们的打分等比于\(S_w\)(\(Q\),\(D\))
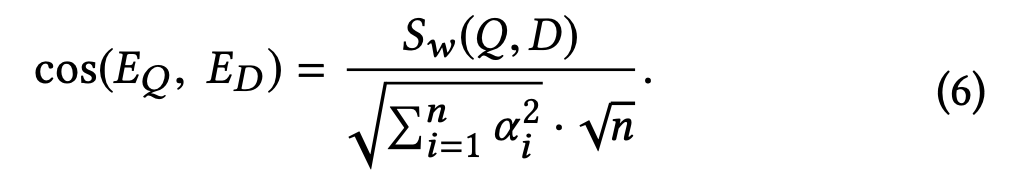
在第二阶段,使用展现未点击的样本训练模型可以提高Knn的召回率,但是相较于单模型在向量量化压缩后会损失精度。发现最好的策略是,用简单的模型训练离线挖掘的难负样本,在连线评估阶段效果差点,但是在线效果好。
模型级连
多个模型串行级连,第二阶段的模型的输入使用上一个阶段模型的输出,发现使用难负样本效果比使用展现未点击的样本效果好。
发现联合embedding的效果整体上虽然比较好,但是它更聚焦于位置、社交关系,反而导致出现文本匹配失败的情况。解决方案是先使用只有文本特征embedding的模型召回数据,接着在使用联合embedding方案选取最好的结果呈现。