1、MySql的架构——单进程,多线程
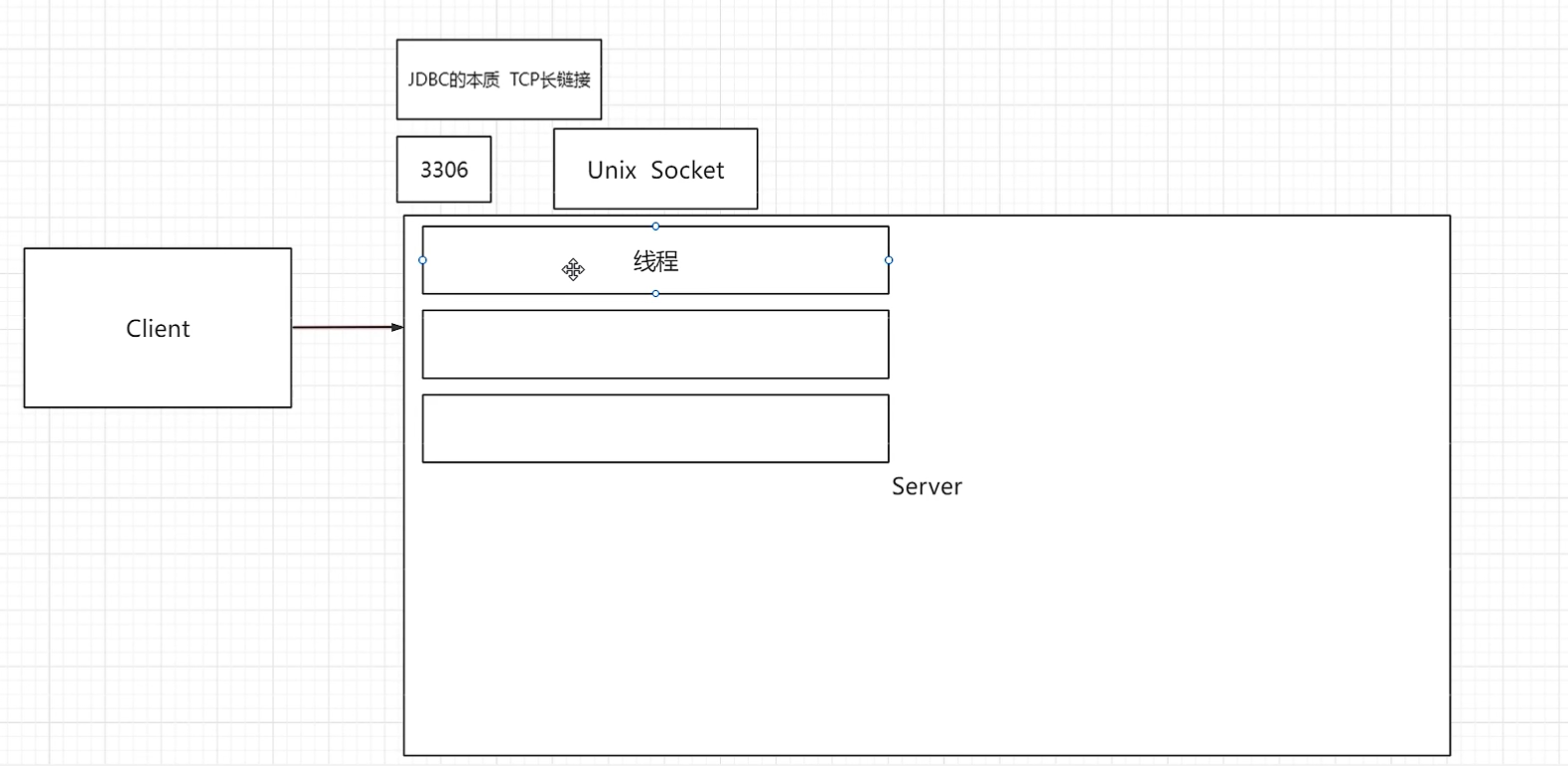
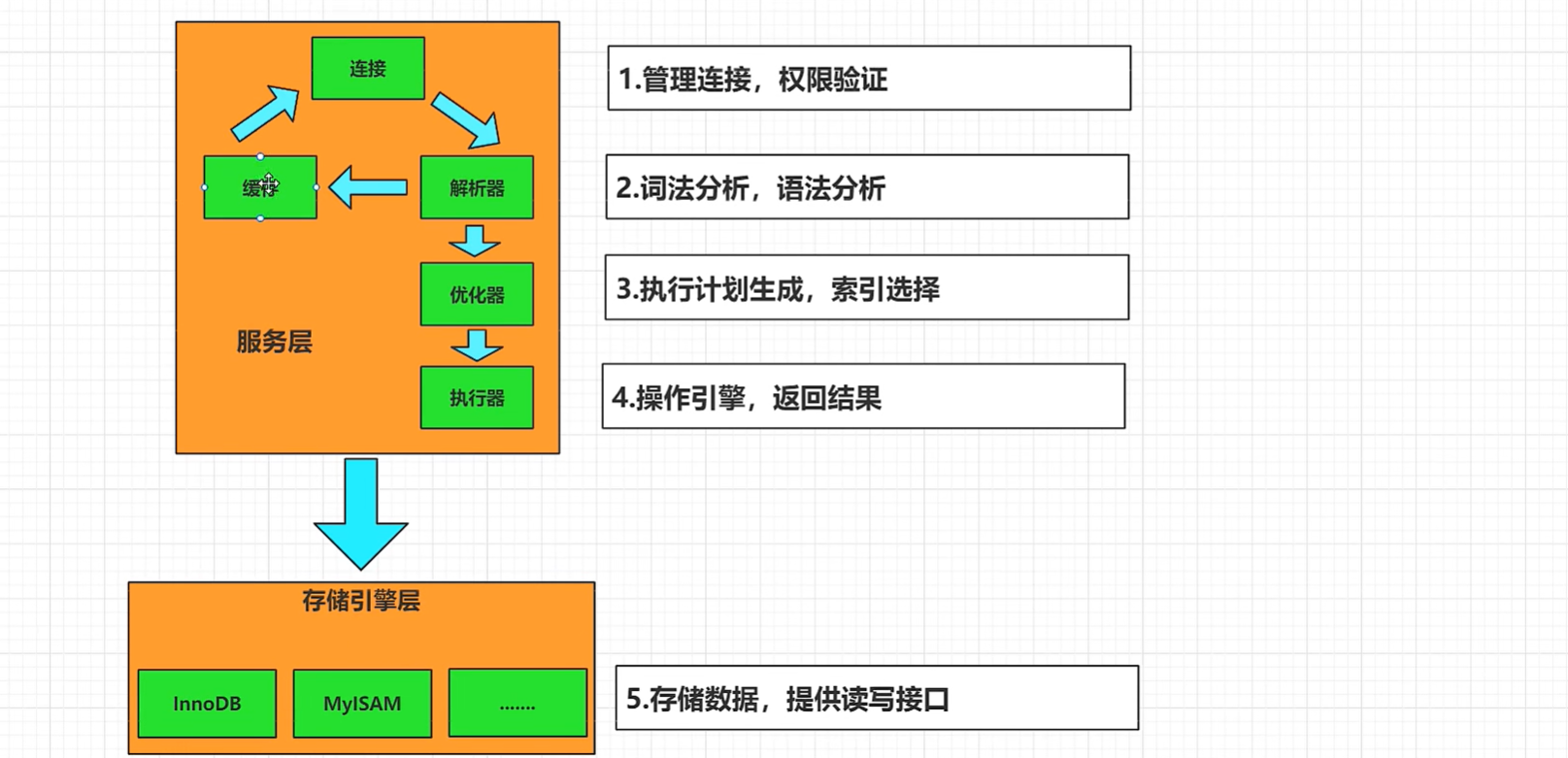
2、Client与Service的连接方式:1)TCP长连接,也是JDBC的本质
2)Unix Socket


注:1)JDBC是Java DataBase Connectivity的缩写,
它是Java程序访问数据库的标准接口。
使用JDBC的好处是:
各数据库厂商使用相同的接口,Java代码不需要针对不同数据库分别开发;
Java程序编译期仅依赖java.sql包,不依赖具体数据库的jar包;
可随时替换底层数据库,访问数据库的Java代码基本不变。
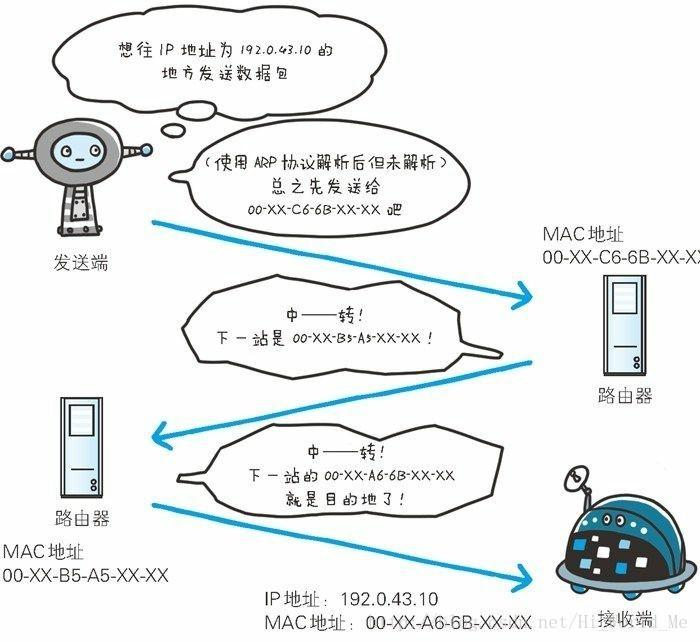
2) TCP协议群
TCP/IP 协议族各层的作用如下。
应用层
应用层决定了向用户提供应用服务时通信的活动。
TCP/IP 协议族内预存了各类通用的应用服务。
比如,FTP(FileTransfer Protocol,文件传输协议)和
DNS(Domain Name System,域名系统)服务就是其中两类。
HTTP 协议也处于该层。
传输层
传输层对上层应用层,提供处于网络连接中的两台计算机之间的数据传输。
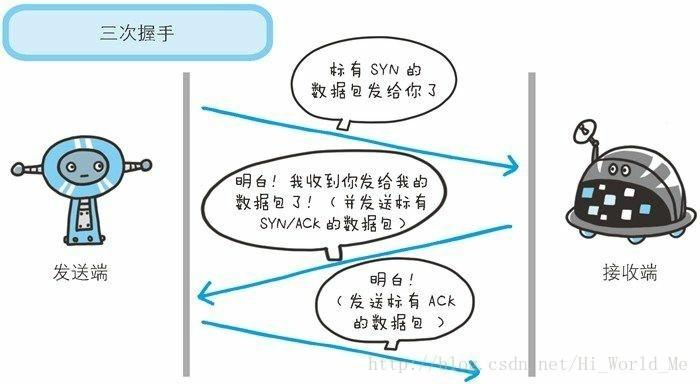
在传输层有两个性质不同的协议:TCP(Transmission ControlProtocol,
传输控制协议)和UDP(User Data Protocol,用户数据报协议)。
网络层(又名网络互连层)
网络层用来处理在网络上流动的数据包。
数据包是网络传输的最小数据单位。
该层规定了通过怎样的路径(所谓的传输路线)到达对方计算机,
并把数据包传送给对方。
与对方计算机之间通过多台计算机或网络设备进行传输时,
网络层所起的作用就是在众多的选项内选择一条传输路线。
链路层(又名数据链路层,网络接口层)
用来处理连接网络的硬件部分。
包括控制操作系统、硬件的设备驱动、NIC(Network Interface Card,
网络适配器,即网卡),
及光纤等物理可见部分(还包括连接器等一切传输媒介)。
硬件上的范畴均在链路层的作用范围之内。
3、MySql的端口号:3306
4、1)查看所有的线程:show global status like '%Threads%'
2)查看非交互式的超时时间,比如JDBC程序:show global variables like ‘wait_timeout'
3)查看交互式的超时时间,比如数据库工具:show global variables like 'interactive_timeout'
4)查看最大连接数:show variables like 'max_connections',项目连接数的合理设置值 = 数据库(8G)的占用内存大小/8M,如8G/8M = 1000,注意数据库为8G,但是服务器可能是16G
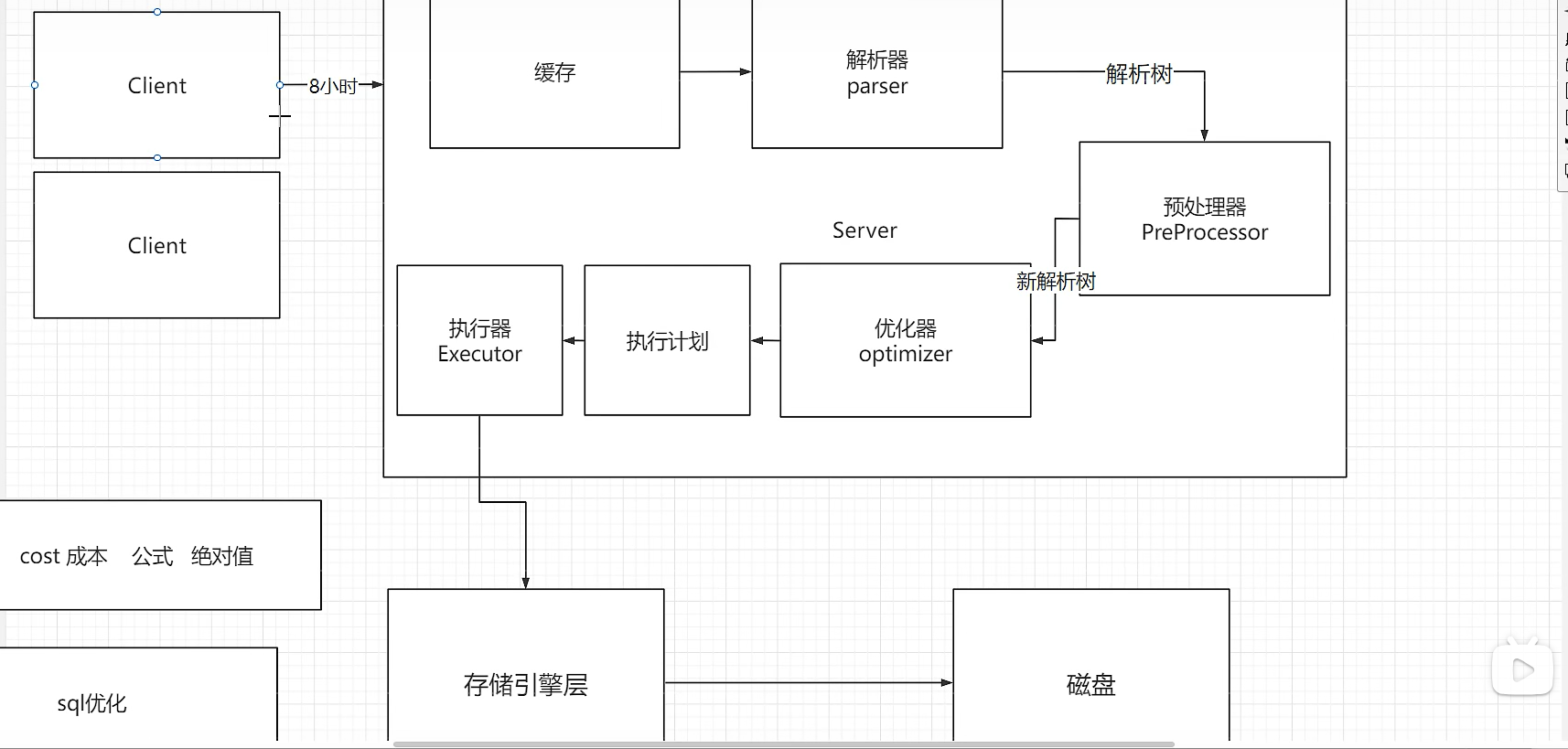
5、缓存——解析器——预处理器——优化器模块
MySql解析器有词法解析和语法解析
语义解析在预处理器上
6、存储引擎:存储及管理数据的方法,MySql5.7版本及以上默认是InnoDB
为什么要有存储引擎?需求不同
1)要求很快的访问速度,不关心它持久化的问题,即使关机就没了。直接存在内存里,内存里是最快的。
2)存储历史数据,不能更改,不需要索引。那么要求支持压缩。
3)读写并发,读写竞争,读写不冲突,要求比较高的一致性
7、增上改查只分为两类:查和改,源码里只有doSelect和doUpdate方法
更新操作会从磁盘中把数据拿到内存中执行

8、InnoDB更新操作
因为在磁盘中做IO操作太慢,所以有一个预读取的概念。
局部性原理:假设你的操作是有关联的
操作系统页:大部分操作系统的页是4KB
MySql的数据页:16KB
每次更新操作都会做一次查询操作
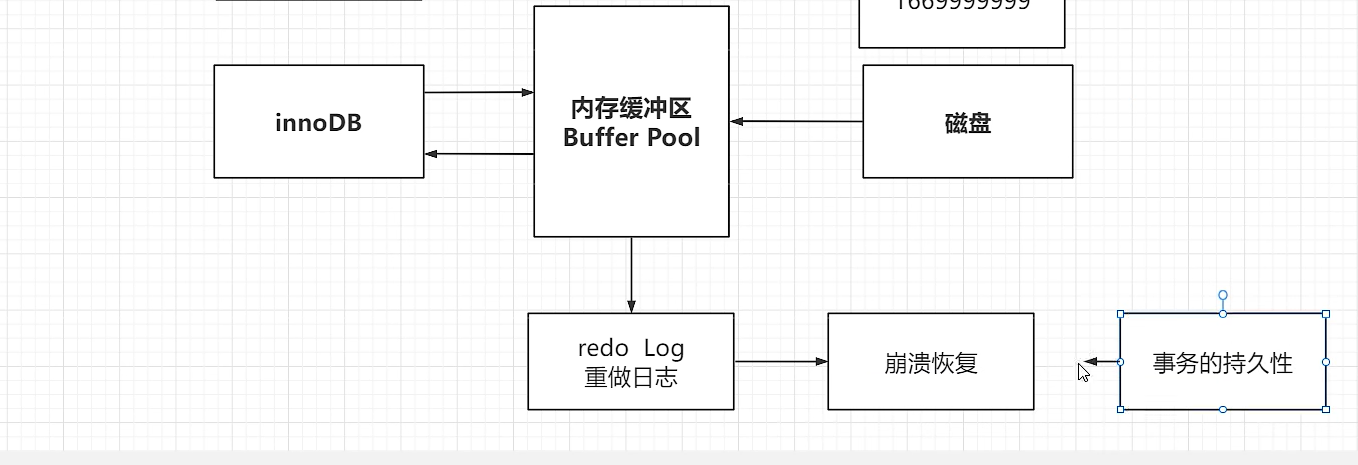
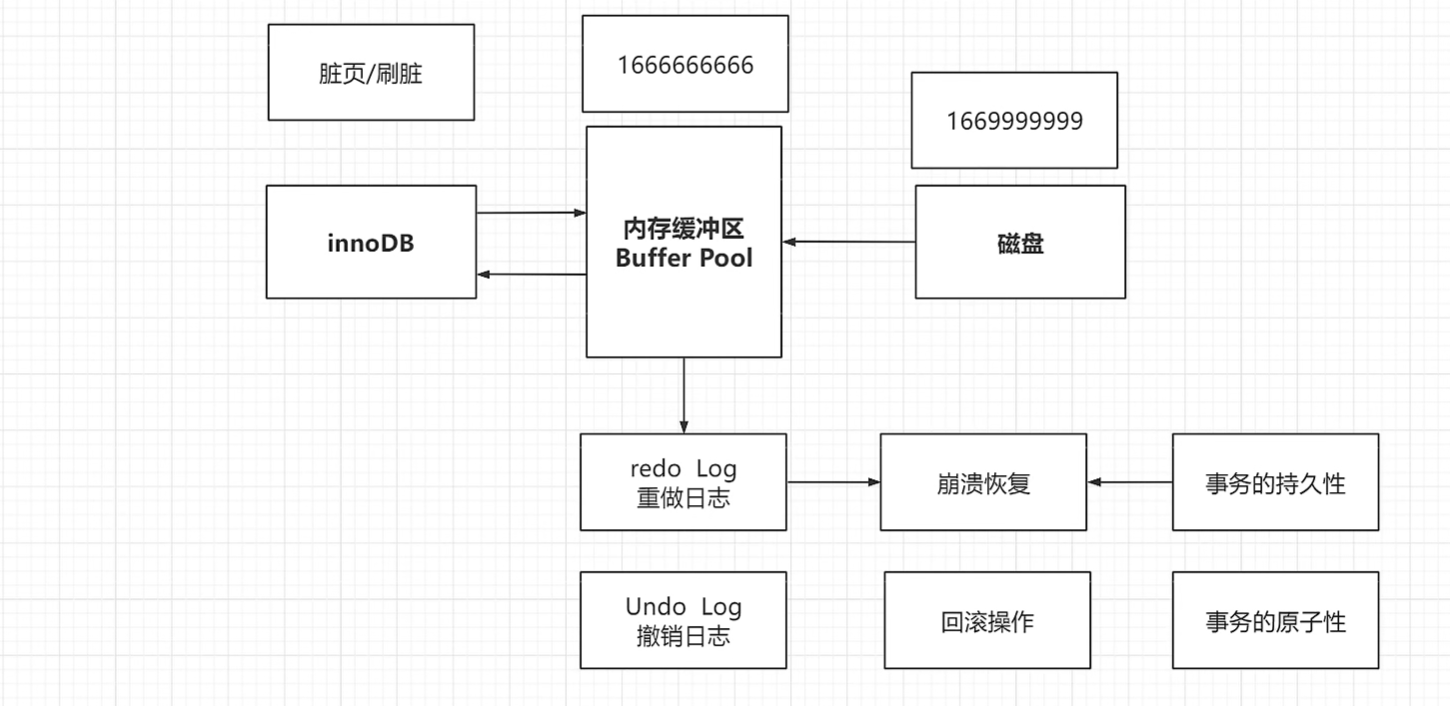
如果每次更新都此磁盘中获取数据然后和Service做交互太慢了,所以更新操作的查询操作执行后,会有一个内存缓冲区BufferPool
在缓冲区还没同步到磁盘的数据叫脏页,把这些数据同步到磁盘的操作叫刷脏页
BufferPool的大小会明显影响数据库的性能
缓冲区语句:show variables like '%innodb_buffer_pool%'
BufferPool的默认大小是8M,Linux是128M,在专用的数据库服务器上BufferPool应该占内存的60%~80%,200G~160G
万一在刷脏页之前数据库电脑宕机了,断电重启了,怎么办,InnoDB有一个Redo Log——重做日志
把Redo Log 恢复到BufferPool中就可以解决,这个过程叫崩溃恢复
查看崩溃恢复语句:show variables like 'innodb_log%' 默认是48M,两组
Redo Log——重做日志的特点
1)记录数据页的改动,物理日志,绝对操作
2)InnoDB特有
3)BufferPool也是InnoDB特有
4)Redo Log的作用是:崩溃恢复
5)保持事务的持久性
缓冲区太慢会导致丢失数据的几率增大,虽然可以系统性能消耗小些
Undo Log撤销日志的特点
1)记录事务发生前的状态
2)保持事务的原子性
3)默认放在系统表空间
查看撤销日志的语句:show variables like ‘%undo%’


9、update user set name = 'A' where name ='B'
用执行器调用存储引擎的接口把磁盘加载到内存中,InnoDB不修改数据,由Service修改
1)从存储引擎,拿到数据,记录在BufferPool里面,然后进一步返回给Service层
2)Service层会把这个数据页里面的这条记录改成'A'
3)调用存储引擎,记录到BufferPool
4)Undo Log 和 Redo Log
5)事务提交
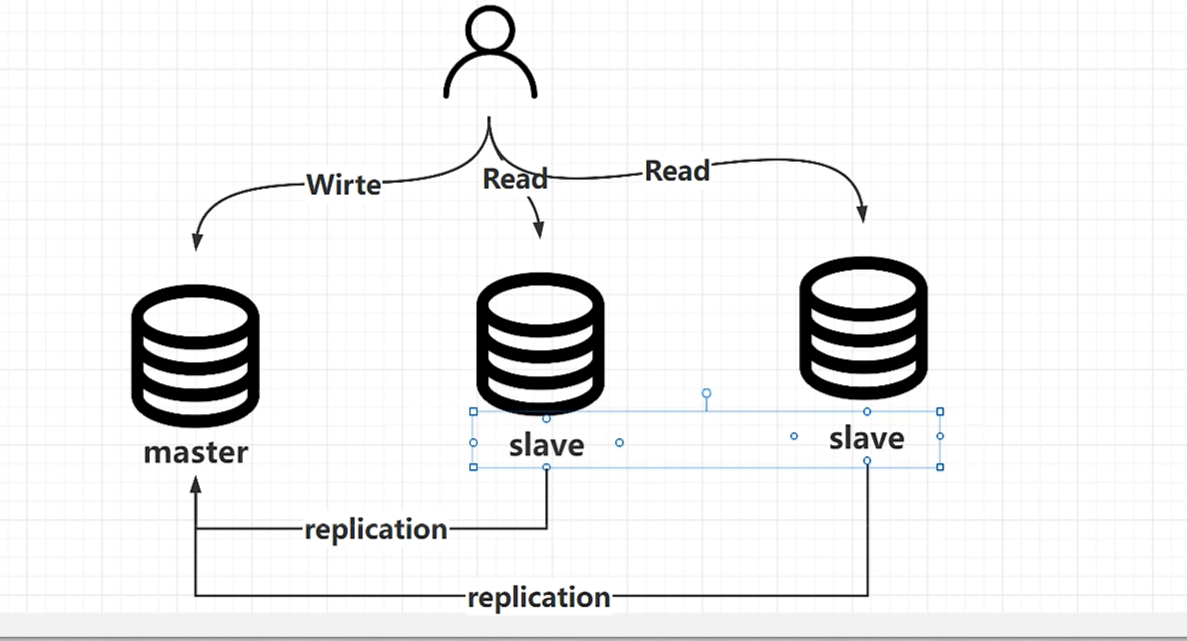
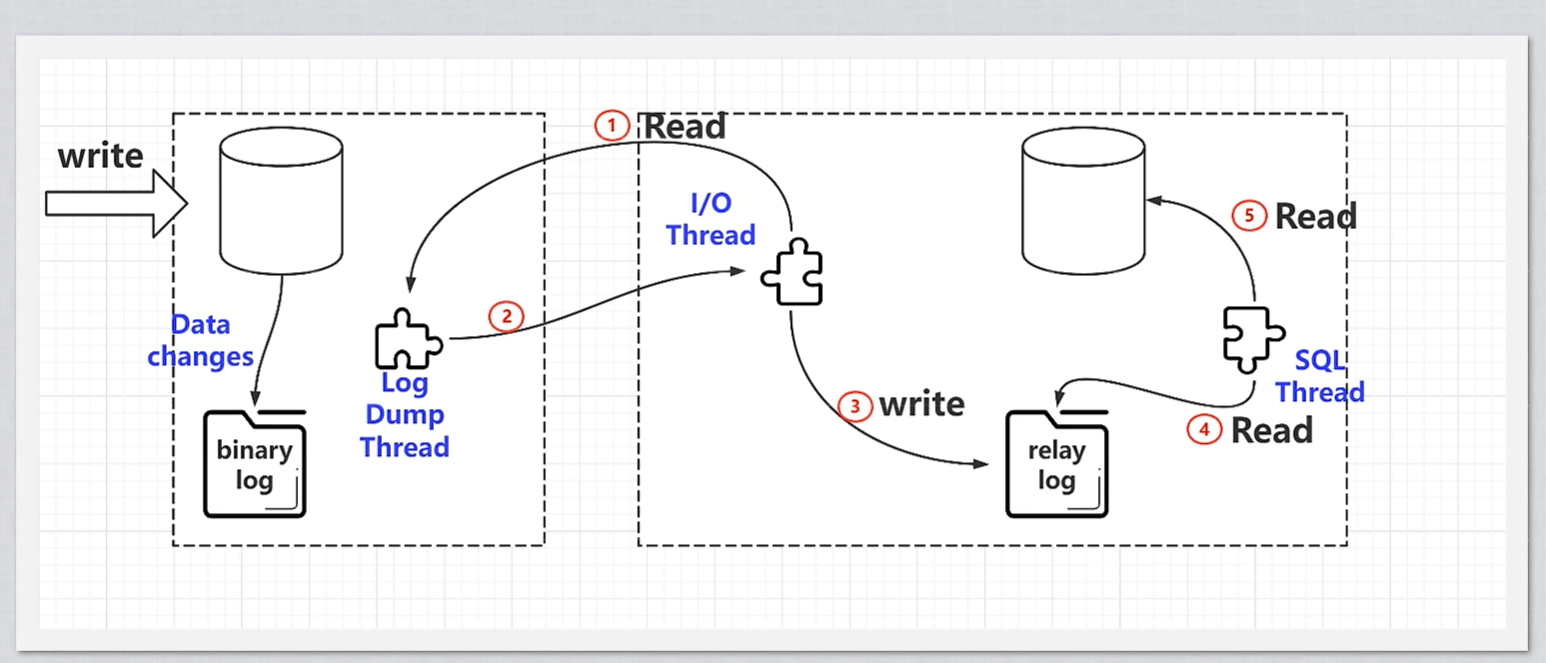
10、Service层有一个bin Log
bin Log的作用由两个
1)数据恢复,业务目的,要区别崩溃恢复
2)主从复制——读写分离
内容:DDL、DML
特点:它是一个逻辑日志