1. Load DATA
回想一下,当在 Hive 中创建好表之后,默认就会在 HDFS 上创建一个与之对应的文件夹,默认路径是由参数 hive.metastore.warehouse.dir 控制,默认值是 /user/hive/warehouse。
要想让 Hive 的表和结构化的数据文件产生映射,就需要把文件移到到表对应的文件夹下面,当然,可以在建表的时候使用 LOCATION 语句指定数据文件的路径。但是不管路径在哪里,必须把数据文件移动到对应的路径下面。
最原始暴力直接的方式就是使用 hadoop fs –put/-mv 等方式将数据移动到路径下面。
Hive 官方推荐使用 Load 命令将数据加载到表中。
1.1 语法
在将数据加载到表中时,Hive 不会进行任何转换。加载操作是将数据文件移动到与 Hive 表对应的位置的纯「复制」/「移动」操作。

【filepath】
filepath 表示待移动数据的路径。可以指向文件(在这种情况下,Hive 将文件移动到表中),也可以指向目录(在这种情况下,Hive 将把该目录中的所有文件移动到表中)。
filepath 文件路径支持下面 3 种形式,要结合 LOCAL 关键字一起考虑:
- 相对路径,如:project/data1
- 绝对路径,如:/user/hive/project/data1
- 具有 schema 的完整 URI,如:hdfs://namenode:9000/user/hive/project/data1
【LOCAL】
- 指定 LOCAL 将在本地文件系统中查找文件路径
- 若指定相对路径,将相对于用户的当前工作目录进行解释;
- 用户也可以为本地文件指定完整的 URI,如:file:///user/hive/project/data1;
- 是将本地文件复制到 HDFS 上的表路径下。
- 没指定 LOCAL 关键字
- 如果 filepath 指向的是一个完整的 URI,会直接使用这个 URI;
- 如果没有指定 schema,Hive 会使用在 Hadoop 配置文件中参数 fs.default.name 指定的(不出意外,都是 HDFS 上的文件);
- 要注意的是,该文件已经在 HDFS 上了,所以 LOAD 是将该文件移动到 HDFS 上的对应的表路径下。
LOCAL 本地是哪里?如果对 HiveServer2 服务运行此命令,本地文件系统指的是 Hiveserver2 服务所在机器的本地 Linux 文件系统,而不是 Hive 客户端所在的本地文件系统。
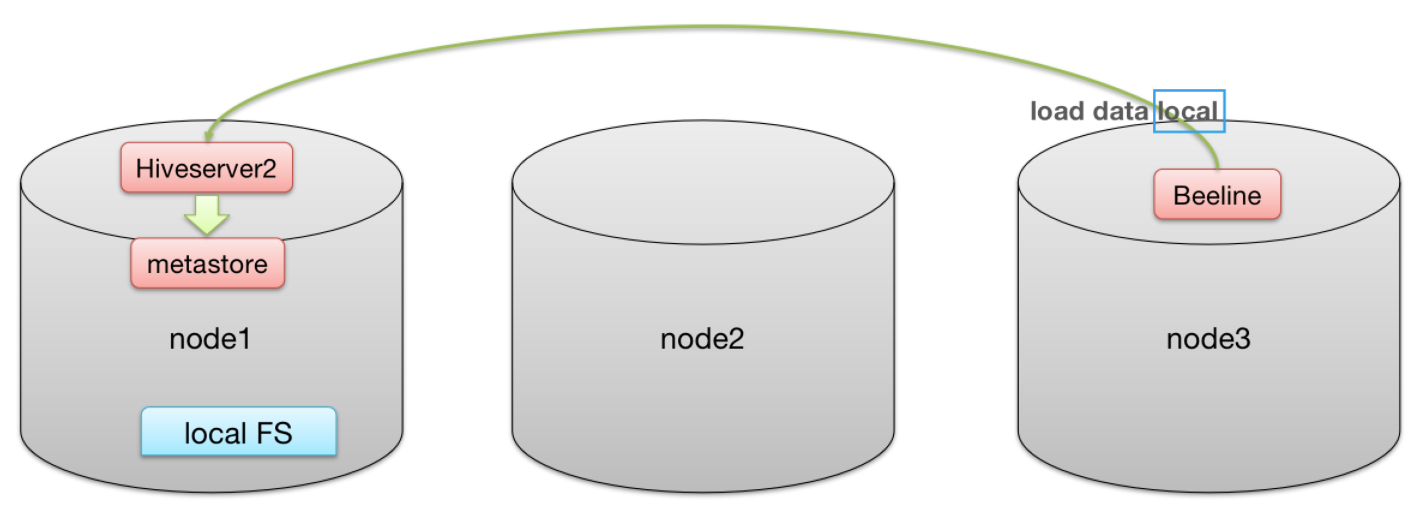
【OVERWRITE】
默认是将结果追加到目标表。如果使用了 OVERWRITE 关键字,则目标表(或者分区)中的已经存在的数据会被删除,然后再将 filepath 指向的文件/目录中的内容添加到表/分区中。
【PARTITION】
表示上传到指定分区;若目标是分区表,需指定分区。
1.2 案例
-- step1 建表 --
-- 建表student_local 用于演示从本地加载数据
create table student_local
(
num int,
name string,
sex string,
age int,
dept string
) row format delimited
fields terminated by ',';
-- 建表student_HDFS 用于演示从HDFS加载数据
create external table student_HDFS
(
num int,
name string,
sex string,
age int,
dept string
) row format delimited
fields terminated by ',';
-- 建表student_HDFS_p 用于演示从HDFS加载数据到分区表
create table student_HDFS_p
(
num int,
name string,
sex string,
age int,
dept string
) partitioned by (country string)
row format delimited
fields terminated by ',';
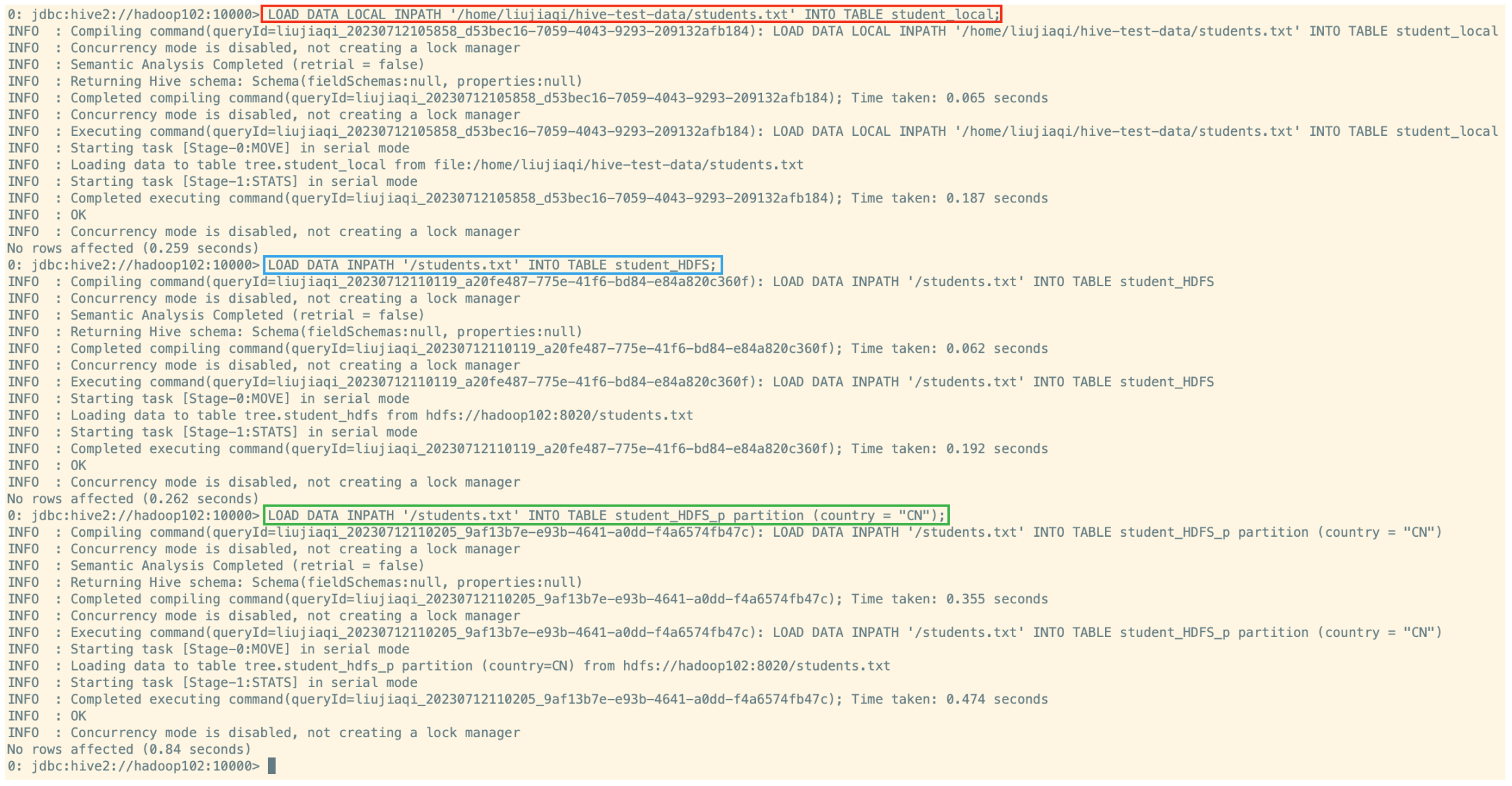
-- step2 加载数据(建议使用beeline客户端 可以显示出加载过程日志信息)--
-- 从本地加载数据
-- 数据位于HS2(node1)本地文件系统 本质是 hadoop fs -put 上传操作
LOAD DATA LOCAL INPATH '/home/liujiaqi/hive-test-data/students.txt' INTO TABLE student_local;
-- 从HDFS加载数据
-- 数据位于HDFS文件系统根目录下 本质是 hadoop fs -mv 移动操作
-- 先把数据上传到 HDFS 上 hadoop fs -put /home/liujiaqi/hive-test-data/students.txt /
LOAD DATA INPATH '/students.txt' INTO TABLE student_HDFS;
-- 从HDFS加载数据到分区表中并制定分区
-- 先把数据上传到 HDFS 上 hadoop fs -put /home/liujiaqi/hive-test-data/students.txt /
LOAD DATA INPATH '/students.txt' INTO TABLE student_HDFS_p partition (country = "CN");
使用 beeline 客户端可以显示出加载过程日志信息:
1.3 新特性
Hive 3.0 及更高版本中,除了移动复制操作之外,还支持其他加载操作,因为 Hive 在内部在某些场合下会将加载重写为 INSERT AS SELECT。
比如,如果表具有分区,则 LOAD 命令没有指定分区,则将 LOAD 转换为 INSERT AS SELECT,并假定最后一组列为分区列。如果文件不符合预期的架构,它将引发错误。
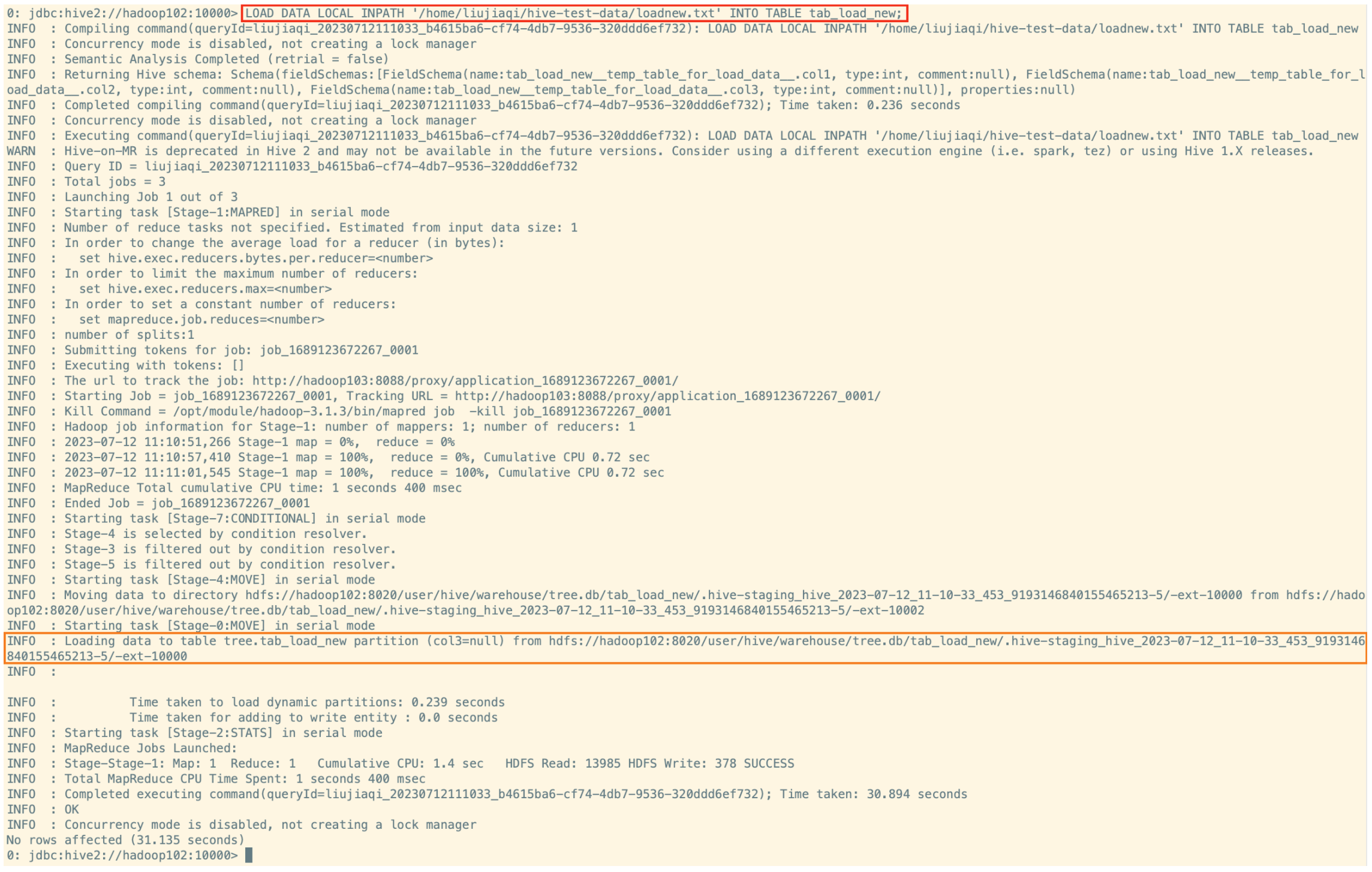
------- Hive3.0 LOAD 命令新特性 -------
CREATE TABLE if not exists tab_load_new (col1 int, col2 int)
PARTITIONED BY (col3 int)
row format delimited fields terminated by ',';
-- 加载到 Hive
LOAD DATA LOCAL INPATH '/home/liujiaqi/hive-test-data/loadnew.txt' INTO TABLE tab_load_new;
-- tab1.txt 内容如下
11,22,1
33,44,2
本来加载的时候没有指定分区,语句是报错的,但是文件的格式符合表的结构,前两个是 col1,col2,最后一个是分区字段 col3,则此时会将 LOAD 语句转换成为 INSERT AS SELECT 语句。在 Hive3.0 中,还支持使用 inputformat、SerDe 指定任何 Hive 输入格式,例如文本、ORC 等。
查看 HDFS:
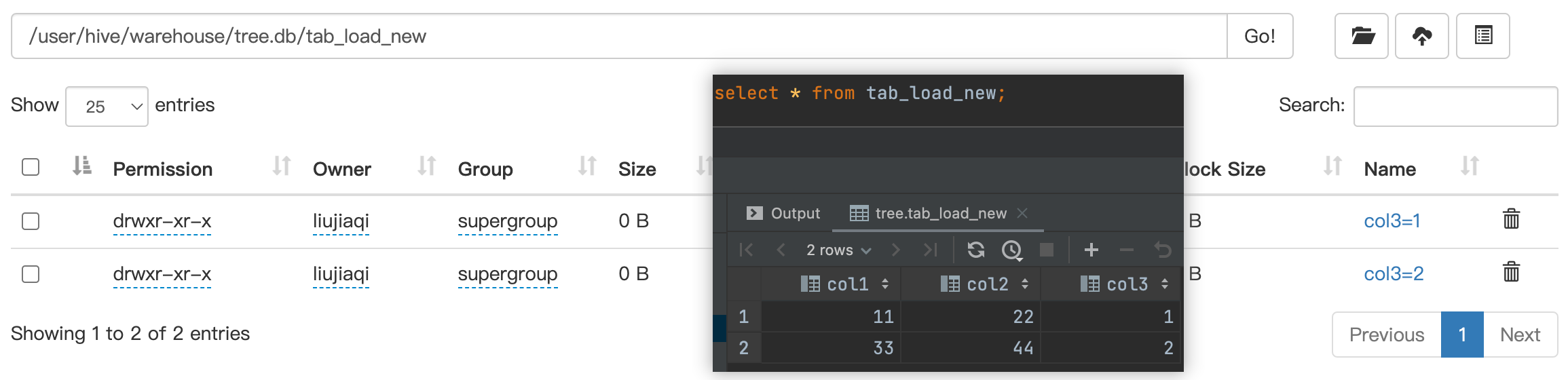
1.4 Export&Import
Export 导出语句可将表的数据和元数据信息一并导出的 HDFS 路径,Import 可将 Export 导出的内容导入 Hive,表的数据和元数据信息都会恢复。Export 和 Import 可用于两个 Hive 实例之间的数据迁移。
语法:
-- 导出
EXPORT TABLE tablename TO 'export_target_path'
-- 导入
IMPORT [EXTERNAL] TABLE new_or_original_tablename FROM 'source_path' [LOCATION 'import_target_path']
案例:
-- 导出(此时指定目录下会生成一个_metadata文件和一个data目录)
export table default.student to '/user/hive/warehouse/export/student';
-- 导入
import table student2 from '/user/hive/warehouse/export/student';
2. INSERT
Hive 官方推荐加载数据的方式:清洗数据成为结构化文件,再使用 Load 语法加载数据到表中。这样的效率更高。但是并不意味 INSERT 语法在 Hive 中没有用武之地。
INSERT (INTO | OVERWRITE) TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)] VALUES values_row [, values_row ...]
2.1 Insert & Select
Hive 中 insert 主要是结合 select 查询语句使用,将查询结果插入到表中,语法如下:

- 将后面查询返回的结果作为内容插入到指定表中,注意 OVERWRITE 将覆盖已有数据。
- 需要保证查询结果列的数目和需要插入数据表格的列数目一致。
- 如果查询出来的数据类型和插入表格对应的列数据类型不一致,将会进行转换,但是不能保证转换一定成功,转换失败的数据将会为 NULL。
示例:
-- step1 创建一张源表 student
drop table if exists student;
create table student
(
num int,
name string,
sex string,
age int,
dept string
)
row format delimited
fields terminated by ',';
-- 加载数据
load data local inpath '/root/hivedata/students.txt' into table student;
-- step2 创建一张目标表 只有两个字段
create table student_from_insert
(
sno int,
sname string
);
-- 使用 insert+select 插入数据到新表中
insert into table student_from_insert
select num, name from student;
select * from student_from_insert;
2.2 Multiple Insert
Multiple Insert 可以翻译成为多次插入、多重插入,核心是:一次扫描,多次插入。
语法目的就是减少扫描的次数,在一次扫描中完成多次 insert 操作。
示例:
-- 当前库下已有一张表 student
select * from student;
-- 创建两张新表
create table student_insert1 (sno int);
create table student_insert2 (sname string);
-- 多重插入
from student
insert overwrite table student_insert1
select num
insert overwrite table student_insert2
select name;
2.3 Dynamic Partion Insert
对于分区表的数据导入加载,最常见最基础的是通过 load 命令加载数据。
在 load 过程中,分区值是手动指定写死的,叫做「静态分区」插入。如下所示:
create table student_HDFS_p
(
Sno int,
Sname string,
Sex string,
Sage int,
Sdept string
)
partitioned by (country string)
row format delimited fields terminated by ',';
-- 分区字段 country 的值是在导入数据的时候手动指定的 China
LOAD DATA INPATH '/students.txt' INTO TABLE student_HDFS_p partition (country = "China");
接下来我们考虑一下性能问题:
假如说现在有全球 224 个国家的人员名单(每个国家名单单独一个文件),让你导入数据到分区表中,不同国家不同分区,如何高效实现?使用 load 语法导入 224 次?
再假如,现在有一份名单 students.txt,内容如下:

让你创建一张分区表,根据最后一个字段(选修专业)进行分区,同一个专业的同学分到同一个分区中,如何实现?如果还是 load 加载手动指定,即使最终可以成功,效率也是极慢的。
为此,Hive 提供了动态分区插入的语法。
所谓「动态分区」插入指的是:分区的值是由后续的 select 查询语句的结果来动态确定的。根据查询结果自动分区。
启用 Hive 动态分区,需要在 Hive 会话中设置两个参数:
| 参数 | 参数值 | 解释 |
|---|---|---|
| hive.exec.dynamic.partition | true | 设置为 true 表示开启动态分区功能 |
| hive.exec.dynamic.partition.mode | strict|nonstick | 在 strict 模式下,用户必须至少指定一个静态分区,以防用户意外覆盖所有分区;在 nonstrict 模式下,允许所有分区都是动态的。 |
关于严格模式、非严格模式,演示如下:
FROM page_view_stg pvs
INSERT OVERWRITE TABLE page_view PARTITION(dt='2008-06-08', country)
SELECT pvs.viewTime, pvs.userid, pvs.page_url, pvs.referrer_url, null, null, pvs.ip, pvs.cnt
-- 在这里,country 分区将由 SELECT 子句(即 pvs.cnt)的最后一列动态创建,而 dt 分区是手动指定写死的。
-- 如果是 nonstrict 模式,dt 分区也可以动态创建。
动态分区插入·示例:
-- 1、首先设置动态分区模式为非严格模式(默认已经开启了动态分区功能)
set hive.exec.dynamic.partition = true;
set hive.exec.dynamic.partition.mode = nonstrict;
-- 2、当前库下已有一张表 student
select * from student;
-- 3、创建分区表 以sdept作为分区字段(注意:分区字段名不能和表中的字段名重复)
create table student_partition
(
Sno int,
Sname string,
Sex string,
Sage int
) partitioned by (Sdept string);
-- 4、执行动态分区插入操作
-- 其中,Sno,Sname,Sex,Sage 作为表的字段内容插入表中,Sdept 作为分区字段值
insert into table student_partition partition (Sdept)
select Sno, Sname, Sex, Sage, Sdept from student;
2.4 Insert & Directory
Hive 支持将 select 查询的结果导出成文件存放在文件系统中。语法格式如下:

注意:导出操作是一个 OVERWRITE 覆盖操作,directory 指定的目录最好是一个空目录,否则会覆盖目录下的内容。
目录可以是完整的 URI。如果未指定 scheme,则 Hive 将使用 Hadoop 配置变量 fs.default.name 来决定导出位置;如果使用 LOCAL 关键字,则 Hive 会将数据写入本地文件系统上的目录。
写入文件系统的数据被序列化为文本,列之间用 \001 隔开,行之间用换行符隔开。如果列都不是原始数据类型,那么这些列将序列化为 JSON 格式。也可以在导出的时候指定分隔符换行符和文件格式。
-- 当前库下已有一张表 student
select * from student_local;
-- 1、导出查询结果到HDFS指定目录下
insert overwrite directory '/opt/hive_export/student'
row format serde 'org.apache.hadoop.hive.serde2.JsonSerDe'
select * from student;
-- 2、导出时指定分隔符和文件存储格式
insert overwrite directory '/tmp/hive_export/e2'
row format delimited fields terminated by ','
stored as orc
select * from student;
-- 3、导出数据到本地文件系统指定目录下
insert overwrite local directory '/root/hive_export/e1'
select * from student;
3. Transaction Table
3.1 概述
Hive 事务背景知识
Hive 本身从设计之初时,就是不支持事务的,因为 Hive 的核心目标是将已经存在的结构化数据文件映射成为表,然后提供基于表的 SQL 分析处理,是一款面向分析的工具。且映射的数据通常存储于 HDFS 上,而 HDFS 是不支持随机修改文件数据的,其常见的模型是一次写入,多次读取。
这个定位就意味着在早期的 Hive 的 SQL 语法中是没有 UPDATE、DELETE 操作的,也就没有所谓的事务支持了,因为都是 SELECT 查询分析操作。
从 Hive 0.14 版本开始,具有 ACID 语义的事务已添加到 Hive 中,以解决以下场景下遇到的问题:
(1)流式传输数据
使用如 Apache Flume 或 Apache Kafka 之类的工具将数据流式传输到 Hadoop 集群中。虽然这些工具可以每秒数百行或更多行的速度写入数据,但是 Hive 只能每隔 15min 到 1h 添加一次分区。频繁添加分区会很快导致表中大量的分区。因此通常使用这些工具将数据流式传输到现有分区中,但是这会使读者感到脏读(也就是说,他们将在开始查询后看到写入的数据),并将许多小文件留在目录中,这将给 NameNode 带来压力。通过事务功能,同时允许读者获得一致的数据视图并避免过多的文件。
(2)尺寸变化缓慢
在典型的星型模式数据仓库中,维度表随时间缓慢变化。例如,零售商将开设新商店,需要将其添加到商店表中,或者现有商店可能会更改其平方英尺或某些其他跟踪的特征。这些更改导致插入单个记录或更新 记录(取决于所选策略)。
(3)数据更新
有时发现收集的数据不正确,需要局部更正。从 Hive 0.14 开始,可以通过 INSERT、UPDATE 和 DELETE 支持这些用例 。
Hive 事务表局限性
虽然 Hive 支持了具有 ACID 语义的事务,但是在使用起来,并没有像在 MySQL 中使用那样方便,有很多局限性。原因很简单,毕竟 Hive 的设计目标不是为了支持事务操作,而是支持分析操作,且最终基于 HDFS 的底层存储机制使得文件的增加删除修改操作需要动一些小心思。具体限制如下:
- 尚不支持 BEGIN、COMMIT 和 ROLLBACK,所有语言操作都是自动提交的;
- 仅支持 ORC 文件格式(STORED AS ORC)
- 默认情况下事务配置为关闭,需要配置参数开启使用;
- 表必须是分桶表(Bucketed)才可以使用事务功能;
- 表参数 transactional 必须为 true;
- 外部表无法创建为事务表,因为 Hive 只能控制元数据,无法管理数据;
- 必须将 Hive 事务管理器设置为 org.apache.hadoop.hive.ql.lockmgr.DbTxnManager 才能使用 ACID 表;
- 事务表不支持 LOAD DATA ... 语句。
3.2 案例
如果不做任何配置修改,直接针对 Hive 中已有的表进行 INSERT、UPDATE、DELETE 操作,会发现只有 INSERT 语句可以执行,UPDATE 和 DELETE 操作会报错。// INSERT 插入操作能够成功的原因在于,底层是直接把数据写在一个新的文件中的。
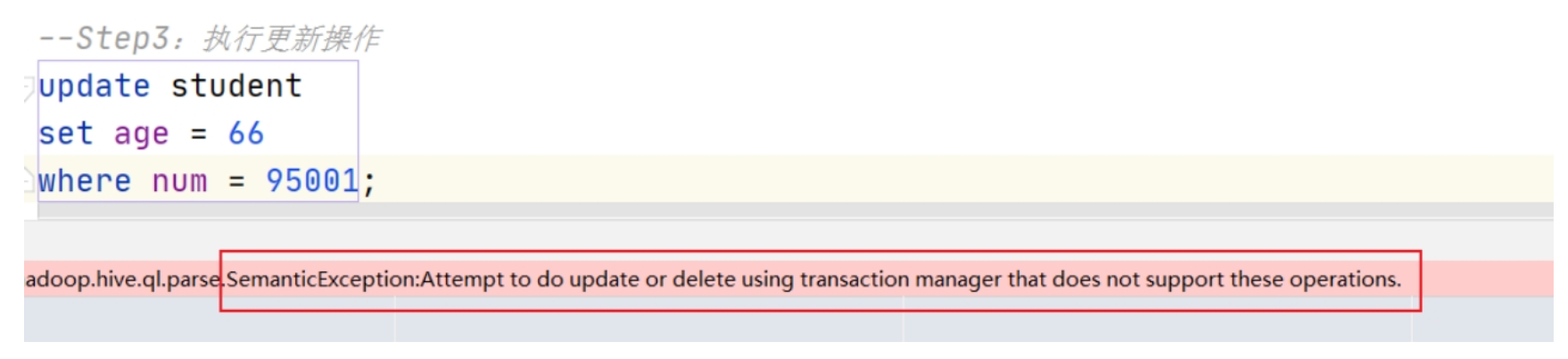
下面看一下如何在 Hive 中配置开启事务表,并且进行操作:
-- 1. 开启事务配置(可以使用set设置当前session生效 也可以配置在hive-site.xml中)
-- Hive是否支持并发
set hive.support.concurrency = true;
-- 是否开启分桶功能
set hive.enforce.bucketing = true;
-- 动态分区模式(非严格)
set hive.exec.dynamic.partition.mode = nonstrict;
-- 事务管理器
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
-- 是否在 Metastore 实例上运行启动线程和清理线程
set hive.compactor.initiator.on = true;
-- 在此 Metastore 实例上运行多少个压缩程序工作线程
set hive.compactor.worker.threads = 1;
-- 2. 创建 Hive 事务表
create table trans_student(
id int,
name String,
age int
)clustered by (id) into 2 buckets stored as orc TBLPROPERTIES('transactional'='true');
-- 3. 针对事务表进行 insert/update/delete 操作
insert into trans_student (id, name, age) values (1, "ljq", 25);
update trans_student
set age = 20
where id = 1;
delete from trans_student where id =1;
select * from trans_student;
查看 HDFS:
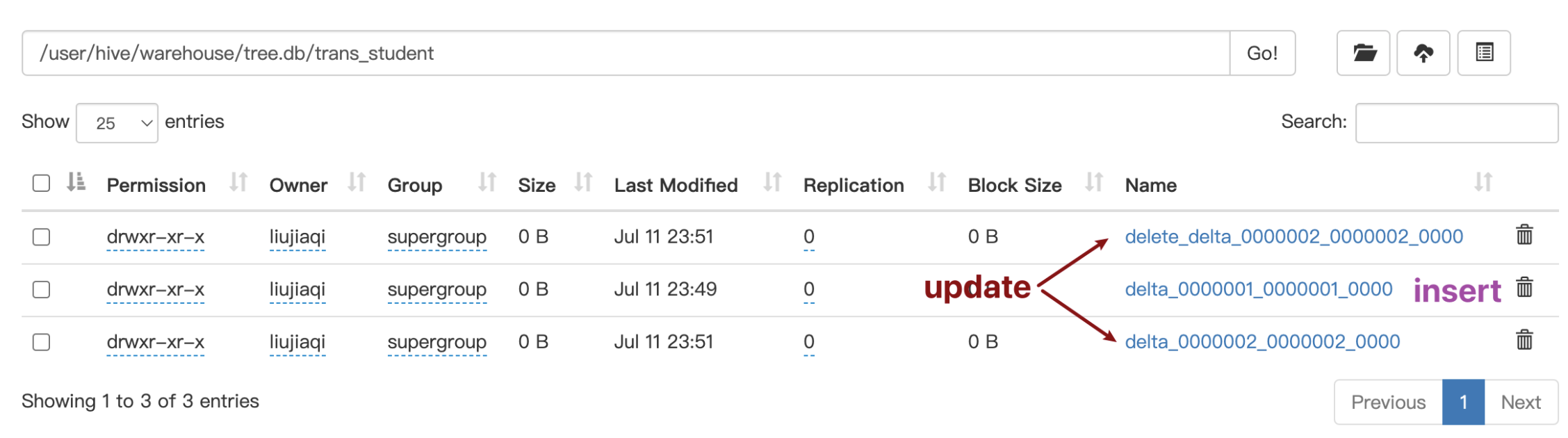
3.3 原理
Hive 的文件是存储在 HDFS 上的,而 HDFS 上又不支持对文件的任意修改,只能是采取另外的手段来完成。
- 用 HDFS 文件作为原始数据(基础数据),用 delta 保存事务操作的记录增量数据;
- 正在执行中的事务,是以一个 staging 开头的文件夹维护的,执行结束就是 delta 文件夹。每次执行一次事务操作都会有这样的一个 delta 增量文件夹;
- 当访问 Hive 数据时,根据 HDFS 原始文件和 delta 增量文件做合并,查询最新的数据。
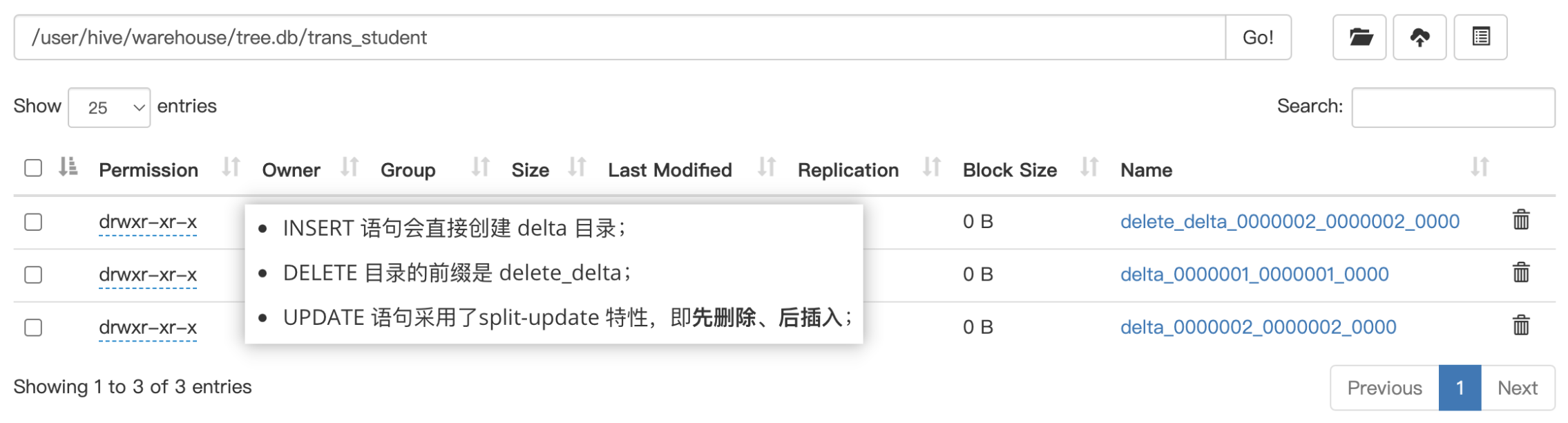
delta 文件夹命名格式:
- delta_minWID_maxWID_stmtID 即 delta 前缀、写事务的 ID 范围、以及语句 ID;删除时前缀是 delete_delta,里面包含了要删除的文件;
- Hive 会为写事务(INSERT、DELETE 等)创建一个写事务 ID(Write ID),该 ID 在表范围内唯一;
- 语句 ID(Statement ID)则是当一个事务中有多条写入语句时使用的,用作唯一标识。
每个事务的 delta 文件夹下,都有两个文件:
(1)_orc_acid_version 的内容是 2,即当前 ACID 版本号是 2。和版本 1 的主要区别是 UPDATE 语句采用了split-update 特性,即先删除、后插入。这个文件不是 ORC 文件,可以下载下来直接查看。
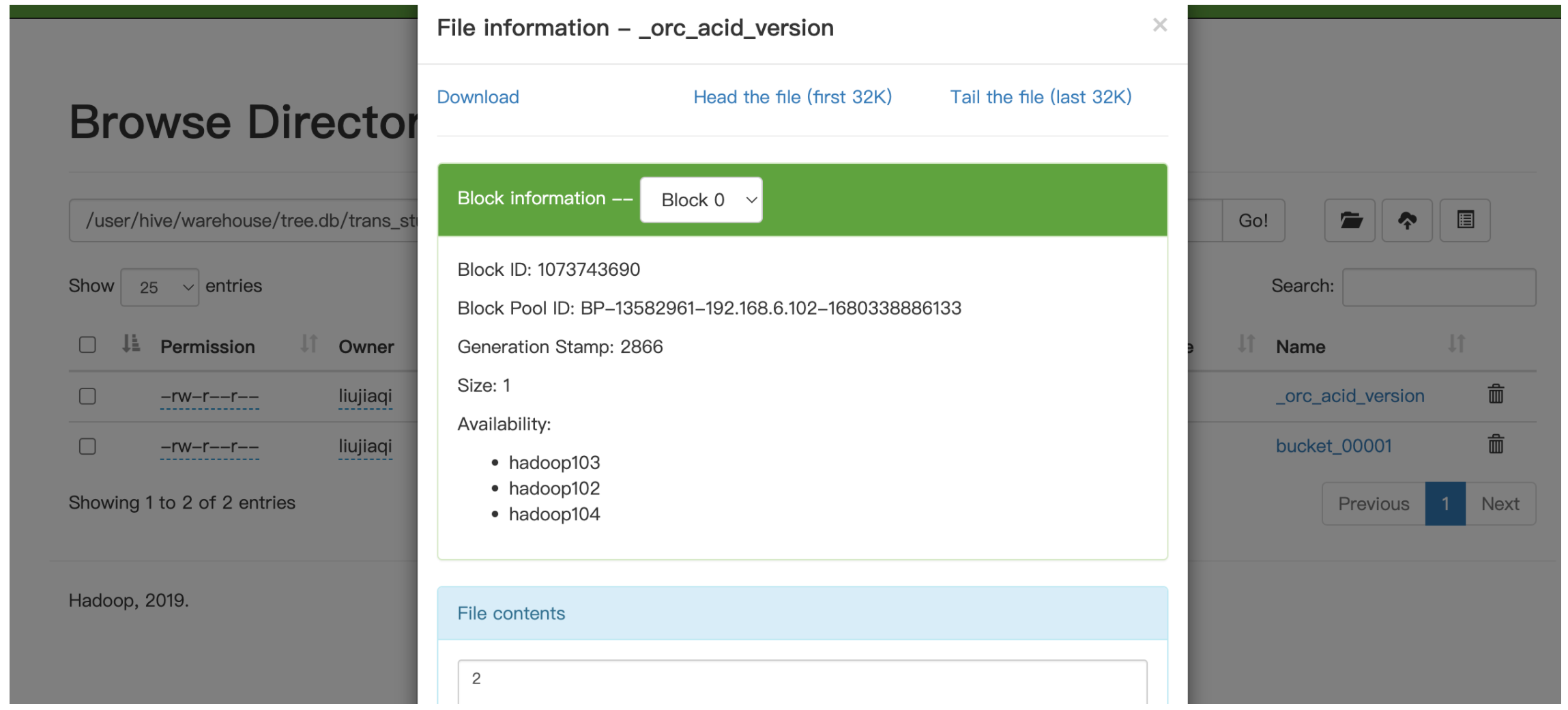
(2)bucket_00001 文件则是写入的数据内容。如果事务表没有分区和分桶,就只有一个这样的文件。文件都以 ORC 格式存储,底层二级制,需要使用 ORC TOOLS(orc-tools-1.6.7-uber.jar)查看。
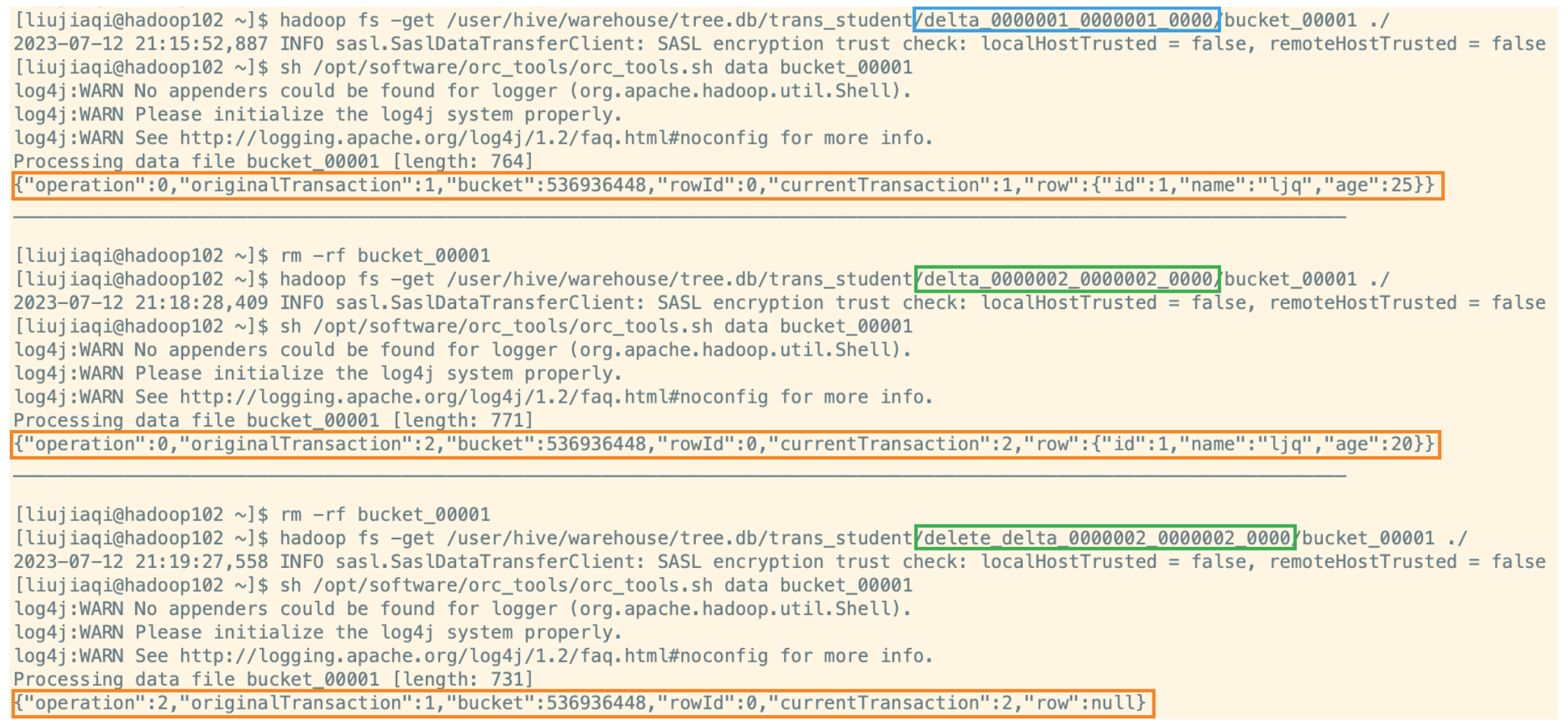
- operation:0 表示插入,1 表示更新,2 表示删除。由于使用了 split-update,所以 UPDATE 是不会出现的,其关联的 delta 文件 operation 是 0 & delete_delta 文件中的 operation 是 2;
- originalTransaction、currentTransaction:该条记录的原始写事务 ID、当前的写事务 ID;
- rowId:一个自增的唯一 ID,在写事务和分桶的组合中唯一;
- row:具体数据。对于 DELETE 语句,则为 null;对于 INSERT 就是插入的数据,对于 UPDATE 就是更新后的数据。
3.4 合并
随着表的修改操作,创建了越来越多的 delta 增量文件,就需要合并以保持足够的性能。
「合并器 Compactor」是一套在 Hive Metastore 内运行,支持 ACID 系统的后台进程。所有合并都是在后台完成的,不会阻止数据的并发读、写。合并后,系统将等待所有旧文件的读操作完成后,删除旧文件。
合并操作分为两种:
- Minor Compaction(小合并)会将一组 delta 增量文件重写为单个增量文件,默认触发条件为 10 个 delta 文件;
- Major Compaction(大合并)将一个或多个增量文件和基础文件重写为新的基础文件,默认触发条件为 delta 文件相应于基础文件占比 10%。
配置参数:

3.5 参数
客户端(可以使用 set 设置当前 session 生效,也可以配置在 hive-site.xml 中):
set hive.support.concurrency = true;
set hive.enforce.bucketing = true;
set hive.exec.dynamic.partition.mode = nonstrict;
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
服务端:
set hive.compactor.initiator.on = true; -- 是否在 Metastore 实例上运行启动压缩合并
set hive.compactor.worker.threads = 1; -- 在此 Metastore 实例上运行多少个合并程序工作线程
4. SELECT 查询
从哪里查询取决于 FROM 关键字后面的 table_reference。可以是普通物理表、视图、JOIN 结果或子查询结果。表名、列名不区分大小写。

数据环境准备:
-- step1: 创建普通表t_usa_covid19
drop table t_usa_covid19;
CREATE TABLE t_usa_covid19
(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int
)
row format delimited fields terminated by ",";
-- 将源数据 load 加载到 t_usa_covid19 表对应的路径下
load data local inpath '/root/hivedata/us-covid19-counties.dat' into table t_usa_covid19;
-- step2: 创建一张分区表 基于 count_date,state 进行分区
CREATE TABLE t_usa_covid19_p
(
county string,
fips int,
cases int,
deaths int
)
partitioned by (count_date string, state string)
row format delimited fields terminated by ",";
-- 使用动态分区插入将数据导入 t_usa_covid19_p 中
set hive.exec.dynamic.partition.mode = nonstrict;
insert into table t_usa_covid19_p partition (count_date, state)
select county, fips, cases, deaths, count_date, state
from t_usa_covid19;
【补充】
如果在下面进行 HQL 测试的时候觉得执行的慢,可以在会话里执行:set mapreduce.framework.name=local;。这样以来,HQL 转成的 MR 任务就不会提交到 YARN,而是在 hiveserver2 本地执行了。
如果设置完之后执行 HQL 报错,要去看 hiveserver2的日志(日志位置:/tmp/用户名/hive.log),有可能是本地执行MR 任务导致 OOM 才报错的,此时,修改 hive-env.sh 把堆内存设高点即可。
4.1 基础查询
(1)select_expr
每个 select_expr 表示要检索的列。必须至少有一个 select_expr。
-- 查询所有字段或者指定字段
select * from t_usa_covid19_p;
-- 重命名一个列,在列名和别名之间加入关键字 AS(也可省略关键字)
select county, cases, deaths from t_usa_covid19_p;
-- 查询匹配正则表达式的所有字段
-- 带反引号的名称被解释为正则表达式
SET hive.support.quoted.identifiers = none;
select `^c.*` from t_usa_covid19_p;
-- 查询当前数据库(省去 from 关键字)
select current_database();
-- 查询使用函数
select count(county) from t_usa_covid19_p;
(2)ALL 、DISTINCT
ALL 和 DISTINCT 选项指定是否应返回重复的行。如果没有给出这些选项,则默认值为 ALL(返回所有匹配的行)。DISTINCT 指定从结果集中删除重复的行。
-- 返回所有匹配的行
select state from t_usa_covid19_p;
-- ||
select all state from t_usa_covid19_p;
-- 返回所有匹配的行 去除重复的结果
select distinct state from t_usa_covid19_p;
-- 多个字段 distinct 整体去重
select distinct county, state from t_usa_covid19_p;
(3)WHERE
WHERE 条件是一个布尔表达式。在 WHERE 表达式中,可以使用 Hive 支持的任何函数和运算符,但聚合函数除外。
从 Hive 0.13 开始,WHERE 子句支持某些类型的子查询。
select * from t_usa_covid19_p where state ="California" and deaths > 1000;
select * from t_usa_covid19_p where 1 > 2; -- 1 > 2 返回 false
select * from t_usa_covid19_p where 1 = 1; -- 1 = 1 返回 true
-- WHERE 条件中使用函数 找出州名字母超过10个
select * from t_usa_covid19_p where length(state) >10 ;
-- WHERE 子句支持子查询
SELECT * FROM A
WHERE A.a IN (SELECT foo FROM B);
-- WHERE 条件中不能使用聚合函数,如下查询会报错 SemanticException:Not yet supported place for UDAF 'sum'
select state, sum(deaths)
from t_usa_covid19_p where sum(deaths) > 100 group by state;
那么为什么不能在 WHERE 子句中使用聚合函数呢?
因为聚合函数要使用它的前提是结果集已经确定。而 WHERE 子句还处于“确定”结果集的过程中,因而不能使用聚合函数。
(4)分区查询、分区裁剪
通常,SELECT 查询将扫描整个表(所谓的全表扫描)。如果使用 PARTITIONED BY 子句创建的分区表,则在查询时可以指定分区查询,减少全表扫描,也叫做分区裁剪。
所谓分区裁剪指的是:对分区表进行查询时,会检查 WHERE 子句或 JOIN 中的 ON 子句中是否存在对分区字段的过滤,如果存在,则仅访问查询符合条件的分区,即裁剪掉没必要访问的分区。
-- 找出来自加州 累计死亡人数大于 1000 的县 state 字段就是分区字段 进行分区裁剪 避免全表扫描
select * from t_usa_covid19_p where state ="California" and deaths > 1000;
-- 多分区裁剪
select * from t_usa_covid19_p where count_date = "2021-01-28" and state ="California" and deaths > 1000;
(5)GROUP BY
GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。
需要注意的是,出现在 GROUP BY 中 select_expr 的字段:要么是 GROUP BY 分组的字段,要么是被聚合函数应用的字段。
原因很简单,避免出现一个字段多个值的歧义。分组字段出现 select_expr 中,一定没有歧义,因为就是基于该字段分组的,同一组中必相同;被聚合函数应用的字段,也没歧义,因为聚合函数的本质就是多进一出,最终返回一个结果。
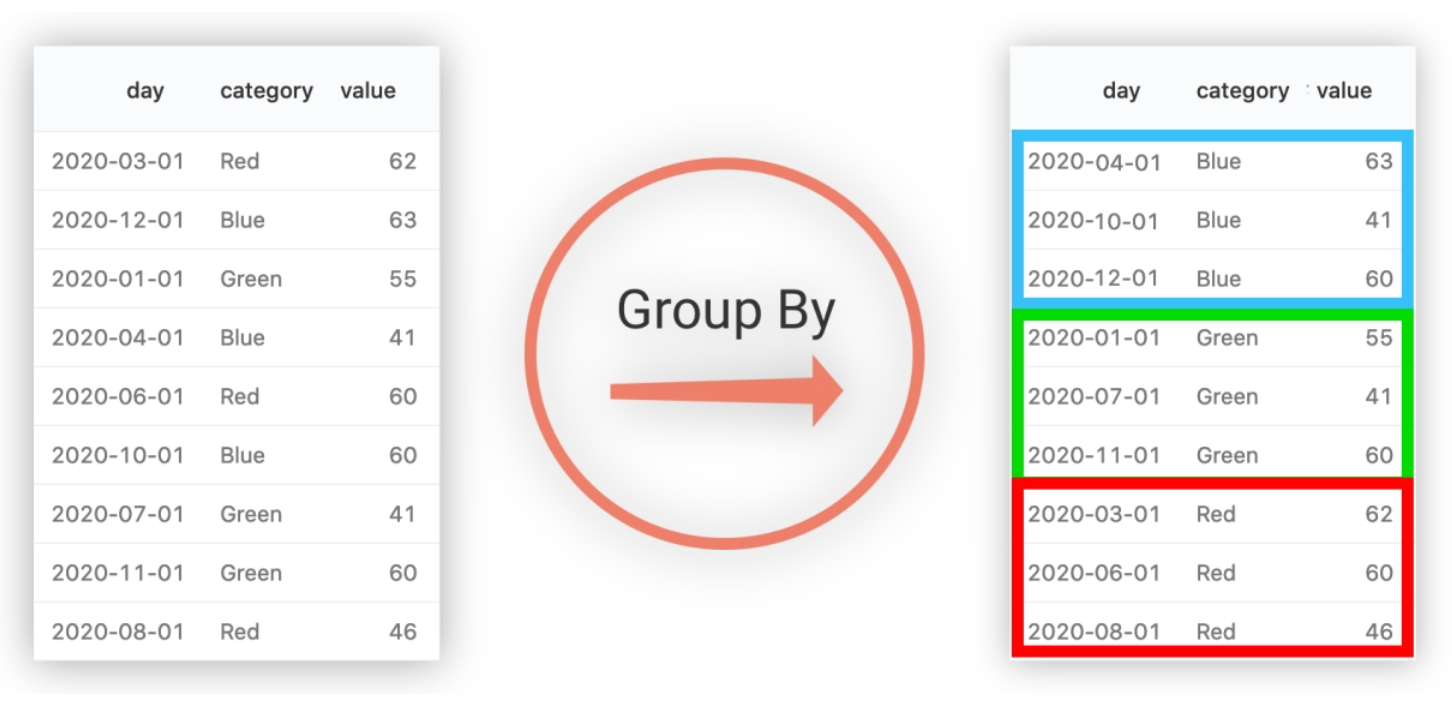
如上图所示,基于 category 进行分组,相同颜色的分在同一组中。
在 select_expr 中,如果出现 category 字段,则没有问题,因为同一组中 category 值一样,但是返回 day 就有问题了,day 的结果不一样。
-- 根据 state 州进行分组,state 是分组字段,可以直接出现在select_expr中,但 deaths 不是分组字段,报错
-- SemanticException:Expression not in GROUP BY key 'deaths'
select state, deaths from t_usa_covid19_p where count_date = "2021-01-28" group by state;
-- 被聚合函数应用
select state, count(deaths) from t_usa_covid19_p where count_date = "2021-01-28" group by state;
(6)HAVING
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 只用于 GROUP BY 分组统计语句。HAVING 子句可以让我们筛选分组后的各组数据,并且可以在 HAVING 中使用聚合函数,因为此时 WHERE、GROUP BY 已经执行结束,结果集已经确定。
-- 先 WHERE 分组前过滤(此处是分区裁剪),再进行 GROUP BY 分组(含聚合),分组后每个分组结果集确定,再使用 HAVING 过滤
select state, sum(deaths)
from t_usa_covid19_p
where count_date = "2021-01-28"
group by state
having sum(deaths) > 10000;
-- 这样写更好:即在 GROUP BY 的时候聚合函数已经作用得出结果 HAVING 直接引用结果过滤,不需要再单独计算一次了
select state, sum(deaths) as cnts
from t_usa_covid19_p
where count_date = "2021-01-28"
group by state
having cnts > 10000;
HAVING 与 WHERE 的区别:
- HAVING 是在分组后对数据进行过滤,WHERE 是在分组前对数据进行过滤;
- HAVING 后面可以使用聚合函数,WHERE 后面不可以使用聚合。
(7)LIMIT
LIMIT 子句可用于约束 SELECT 语句返回的行数。
LIMIT 接受一个或两个数字参数,这两个参数都必须是非负整数常量。
第 1 个参数指定要返回的第一行的偏移量(从 Hive 2.0.0 开始),第 2 个参数指定要返回的最大行数。当给出单个参数时代表最大行数,并且偏移量默认为 0。
-- 没有限制返回2021.1.28 加州的所有记录
select * from t_usa_covid19_p
where count_date = "2021-01-28"
and state = "California";
-- 返回结果集的前5条
select *
from t_usa_covid19_p
where count_date = "2021-01-28"
and state = "California"
limit 5;
-- 返回结果集从第 1 行开始 共 3 行
-- 注意!第一个参数偏移量是从 0 开始的
select *
from t_usa_covid19_p
where count_date = "2021-01-28"
and state = "California"
limit 2,3;
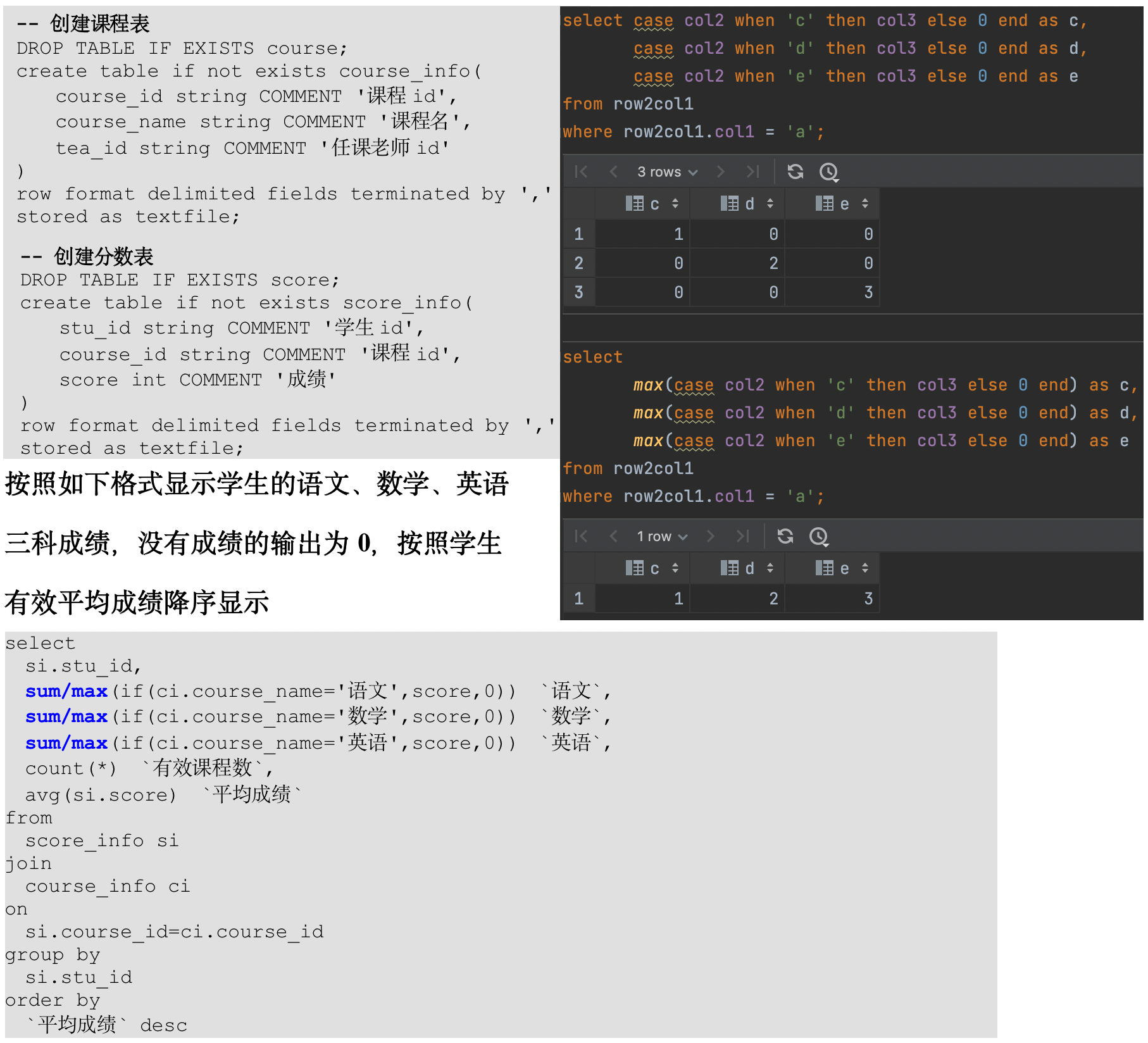
(8)Hive SQL 查询执行顺序
在查询过程中执行顺序:FROM > WHERE > GROUP(含聚合)> HAVING > ORDER > SELECT
所以聚合语句(sum, min, max, avg, count)要比 HAVING 子句优先执行,而 WHERE 子句在查询过程中执行优先级别优先于聚合语句(sum, min, max, avg, count)。
4.2 排序
a. ORDER BY
Hive SQL 中的 ORDER BY 语法类似于 SQL 语言中的 ORDER BY 语法,会对输出的结果进行全局排序,因此底层使用 MapReduce 引擎执行的时候,只会有 1 个 reducetask 执行。也正因此,如果输出的行数太大则会导致需要很长的时间才能完成全局排序。
默认排序顺序为升序(ASC),也可以指定为 DESC 降序。
在 Hive 2.1.0 和更高版本中,支持在 ORDER BY 子句中为每个列指定 null 类型结果排序顺序。ASC 顺序的默认空排序顺序为 NULLS FIRST,而 DESC 顺序的默认空排序顺序为 NULLS LAST。
-- 根据字段进行排序
select *
from t_usa_covid19_p
where count_date = "2021-01-28"
and state = "California"
order by deaths; -- 默认 asc null first
select *
from t_usa_covid19_p
where count_date = "2021-01-28"
and state = "California"
order by deaths desc; -- 指定 desc null last
-- 强烈建议将 LIMIT 与 ORDER BY 一起使用。避免数据集行数过大
-- 当 hive.mapred.mode 设置为 strict 严格模式时,使用不带 LIMIT 的 ORDER BY 会引发异常。
select *
from t_usa_covid19_p
where count_date = "2021-01-28"
and state = "California"
order by deaths desc
limit 3;
b. CLUSTER BY
Hive SQL 中的 CLUSTER BY 语法可以指定根据后面的字段将数据分组,每组内再根据这个字段正序排序(不允许指定排序规则),概况起来就是:根据同一个字段,分且排序(不能指定排序顺序,只能是升序排序)。
- 分组的规则为 hash 散列:hash_func(col_name) % reduce task nums
- 分为几组取决于 reduce task 的个数。
默认情况下,reduce task 的个数由 Hive 在编译期间自己决定。
-- 不指定 reduce task 个数
-- 日志显示:Number of reduce tasks not specified. Estimated from input data size: 1
select * from student cluster by sno;
-- 手动设置 reduce task 个数
set mapreduce.job.reduces = 2;
select * from student cluster by sno;
设置 set mapreduce.job.reduces=2 后,再跑 sql,查询结果分为两个部分,每个部分内正序排序。
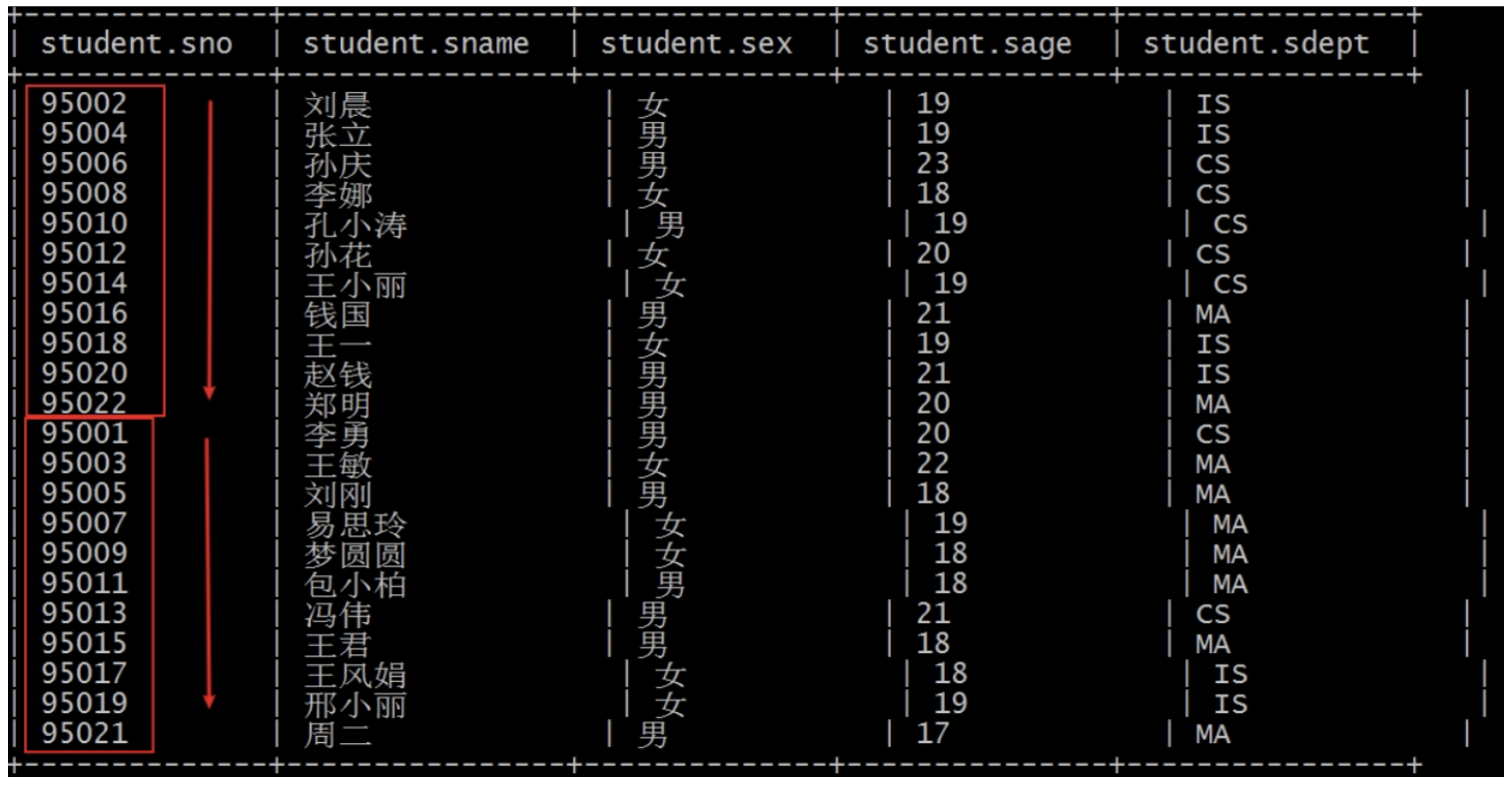
假如现在想法是:把学生表数据根据性别分为两个部分,每个分组内根据年龄的倒序排序。
你会发现 CLUSTER BY 无法完成了。而 ORDER BY 更不能在这里使用,因为它是全局排序,一旦使用 ORDER BY,编译期间就会强制把 reduce task 个数设置为 1。无法满足分组的需求。
c. DISTRIBUTE&SORT BY
在有些情况下,我们需要控制某个特定行应该到哪个 Reducer,通常是为了进行后续的聚集操作。DISTRIBUTE BY 子句可以做这件事。DISTRIBUTE BY 类似 MapReduce 中 Partition(自定义分区)进行分区,通常结合 SORT BY 使用(Hive 要求 DISTRIBUTE BY 语句要写在 SORT BY 语句之前)。
DISTRIBUTE BY 的分区规则同上面说的 CLUSTER BY,都是根据分区字段的 hashcode 与 reduce 的个数进行相除后,余数相同的分到一个区。
如果说 CLUSTER BY 的功能是分且正序排序(同一个字段),那么 DISTRIBUTE BY + SORT BY 就相当于把 CLUSTER BY 一分为二:DISTRIBUTE BY 负责分,SORT BY 负责分组内排序,并且还可以是不同的字段。所以,如果 DISTRIBUTE BY + SORT BY 的字段一样,则可以得出结论:CLUSTER BY = DISTRIBUTE BY + SORT BY。
-- 把学生表数据根据性别分为两个部分,每个分组内根据年龄的倒序排序。
select * from student distribute by sex sort by sage desc;
-- 下面两个语句执行结果一样
select * from student distribute by sno sort by sno;
select * from student cluster by sno;
对于 DISTRIBUTE BY 进行测试,一定要配置多 Reducer 进行处理,否则无法看到 DISTRIBUTE BY 的效果。
d. 小结
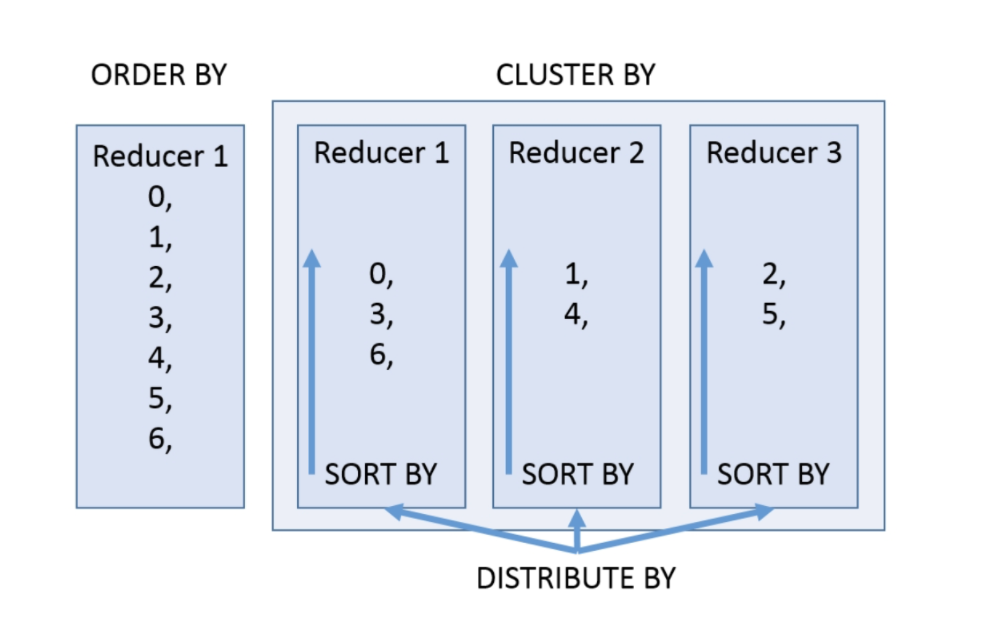
- ORDER BY 会对输入做全局排序,因此只有一个 reducer,会导致当输入规模较大时,需要较长的计算时间。
- SORT BY 不是全局排序,其在数据进入 reducer 前完成排序。因此,如果用 SORT BY 进行排序,并且设置 mapred.reduce.tasks>1,则 SORT BY 只保证每个 reducer 的输出有序,不保证全局有序。
- DISTRIBUTE BY 根据指定字段将数据分到不同的 reducer,分发算法是 hash 散列。
- CLUSTER BY 除了具有DISTRIBUTE BY 的功能外,还会对该字段进行排序。
- 如果 DISTRIBUTE BY 和 SORT BY 的字段是同一个时,此时 CLUSTER BY = DISTRIBUTE BY + SORT BY。
4.3 UNION
UNION 用于将来自多个 SELECT 语句的结果合并为一个结果集。语法如下:

- 使用 DISTINCT 关键字与只使用 UNION 默认值效果一样,都会删除重复行。1.2.0 之前的 Hive 版本仅支持 UNION ALL,在这种情况下不会消除重复的行。
- 使用 ALL 关键字,不会删除重复行,结果集包括所有 SELECT 语句的匹配行(包括重复行)。
- UNION 和 UNION ALL 在上下拼接 SQL 结果时有如下两个要求(不要求字段名一致,合并结果会取第一个 select_statement 的字段名作为最终字段名):
- 两个 select_statement 列的个数必须相同
- 两个 select_statement 上下所对应列的类型必须一致
-- 使用 DISTINCT 关键字与使用 UNION 默认值效果一样,都会删除重复行。
select num, name from student_local
UNION
select num, name from student_hdfs;
-- 和上面一样
select num, name from student_local
UNION DISTINCT
select num, name from student_hdfs;
-- 使用 ALL 关键字会保留重复行
select num, name from student_local
UNION ALL
select num, name from student_hdfs;
-- 如果要将 ORDER BY,SORT BY,CLUSTER BY,DISTRIBUTE BY 或 LIMIT 应用于单个 SELECT
-- 请将子句放在括住 SELECT 的括号内
SELECT sno, sname FROM (select sno, sname from student_local LIMIT 2) subq1
UNION
SELECT sno, sname FROM (select sno, sname from student_hdfs LIMIT 3) subq2
-- 如果要将 ORDER BY,SORT BY,CLUSTER BY,DISTRIBUTE BY 或 LIMIT 子句应用于整个 UNION 结果
-- 请将 ORDER BY,SORT BY,CLUSTER BY,DISTRIBUTE BY 或 LIMIT 放在最后一个之后。
select sno, sname from student_local
UNION
select sno, sname from student_hdfs
order by sno desc;
4.4 Subqueries
FROM 子查询
在 Hive 0.12 版本,仅在 FROM 子句中支持子查询。而且必须要给子查询一个名称,因为 FROM 子句中的每个表都必须有一个名称。
子查询返回结果中的列必须具有唯一的名称。子查询返回结果中的列在外部查询中可用,就像真实表的列一样。子查询也可以是带有 UNION 的查询表达式。Hive 支持任意级别的子查询,也就是所谓的嵌套子查询。
Hive 0.13.0 和更高版本中的子查询名称之前可以包含可选关键字 AS。
-- 子查询
SELECT num
FROM (select num, name
from student_local) tmp;
-- 包含 UNION ALL 的子查询的示例
SELECT t3.name
FROM (select num, name
from student_local
UNION
distinct
select num, name
from student_hdfs) t3;
WHERE 子查询
从 Hive 0.13 开始,WHERE 子句支持某些类型的子查询。
-- 不相关子查询,相当于 IN、NOT IN,子查询只能选择一个列。
-- 1.执行子查询,其结果不被显示,而是传递给外部查询,作为外部查询的条件使用。
-- 2.执行外部查询,并显示整个结果。
SELECT *
FROM student_hdfs
WHERE student_hdfs.num IN (select num from student_local limit 2);
-- 相关子查询,指 EXISTS 和 NOT EXISTS 子查询
-- 1.子查询的 WHERE 子句中支持对父查询的引用
SELECT A
FROM T1
WHERE EXISTS (SELECT B FROM T2 WHERE T1.X = T2.Y);
4.5 CTE
公用表表达式(CTE)是一个临时结果集,该结果集是从 WITH 子句中指定的简单查询派生而来的,该查询紧接在 SELECT 或 INSERT 关键字之前。
CTE 仅在单个语句的执行范围内定义。一个或多个 CTE 可以在 Hive SELECT、INSERT、CREATE TABLE AS SELECT 或 CREATE VIEW AS SELECT 语句中使用。
-- CTE
with q1 as (select sno, sname, sage from student where sno = 95002)
select *
from q1;
-- from
with q1 as (select sno, sname, sage from student where sno = 95002)
from q1
select *;
-- chaining CTEs
with q1 as (select * from student where sno = 95002),
q2 as (select sno, sname, sage from q1)
select *
from (select sno from q2) a;
-- union
with q1 as (select * from student where sno = 95002),
q2 as (select * from student where sno = 95004)
select * from q1
union all
select * from q2;
-- insert
create table s1 like student;
with q1 as (select * from student where sno = 95002)
from q1
insert overwrite table s1
select *;
-- create table as
create table s2 as
with q1 as (select * from student where sno = 95002)
select * from q1;
-- view
create view v1 as
with q1 as (select * from student where sno = 95002)
select * from q1;
5. JOIN 连接查询
根据数据库的三范式设计要求和日常工作习惯来说,我们通常不会设计一张大表把所有类型的数据都放在一起,而是不同类型的数据设计不同的表存储。比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。
在这种情况下,有时需要基于多张表查询才能得到最终完整的结果,SQL中 JOIN 语法的出现是用于根据两个或多个表中的列之间的关系,从这些表中共同组合查询数据,因此有时为了得到完整的结果,我们就需要执行 JOIN。
Hive 作为面向分析的数据仓库软件,为了更好的支持数据分析的功能丰富,也实现了 JOIN 的语法,整体上来看和 RDBMS 中的 JOIN 语法类似,只不过在某些点有自己的特色。需要特别注意。
在 Hive 中,当下版本 3.1.2 总共支持 6 种 JOIN 语法。分别是:
- inner JOIN(内连接)
- LEFT JOIN(左连接)
- RIGHT JOIN (右连接)
- FULL OUTER JOIN(全外连接)
- LEFT SEMI JOIN(左半开连接)
- CROSS JOIN (交叉连接,也叫笛卡尔乘积)
5.1 规则树

- table_reference:是 JOIN 查询中使用的表名,也可以是子查询别名(查询结果当成表参与 JOIN)。
- table_factor:与 table_reference 相同,是联接查询中使用的表名,也可以是子查询别名。
- JOIN_condition:JOIN 查询关联的条件, 如果在两个以上的表上需要连接,则使用 AND 关键字。
Hive 中 JOIN 语法从面世开始其实并不丰富,不像在 RDBMS 中那么灵活,很多早期接触 Hive 的用户在使用 JOIN 的时候,一个最大的感受就是不支持不相等连接。
从 Hive 0.13.0 开始,支持隐式联接表示法(请参阅 HIVE-5558)。这允许 FROM 子句连接以逗号分隔的表列表,而省略 JOIN 关键字。例如:
SELECT *
FROM table1 t1, table2 t2, table3 t3
WHERE t1.id = t2.id AND t2.id = t3.id AND t1.zipcode = '02535';
从 Hive 2.2.0 开始,支持 ON 子句中的复杂表达式,支持不相等连接(请参阅 HIVE-15211 和 HIVE-15251)。在此之前,Hive 不支持不是相等条件的联接条件。
SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department)
SELECT a.* FROM a LEFT OUTER JOIN b ON (a.id <> b.id)
5.2 JOIN 语法
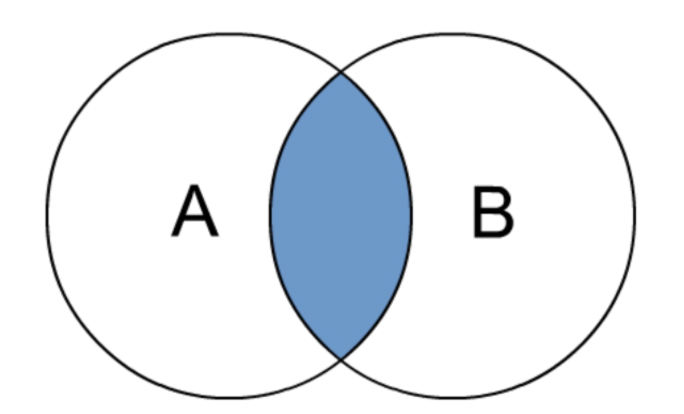
a. INNER JOIN
内连接是最常见的一种连接,它也被称为普通连接,而关系模型提出者 E.FCodd(埃德加·科德)最早称之为自然连接。其中 INNER 可以省略。INNER JOIN == JOIN 等价于早期的连接语法。
内连接,只有进行连接的两个表中都存在与连接条件相匹配的数据才会被留下来。
select e.id, e.name, e_a.city, e_a.street
from employee e
inner join employee_address e_a
on e.id = e_a.id;
-- 等价于 inner join = join
select e.id, e.name, e_a.city, e_a.street
from employee e
join employee_address e_a
on e.id = e_a.id;
-- 等价于 隐式连接表示法
select e.id, e.name, e_a.city, e_a.street
from employee e,
employee_address e_a
where e.id = e_a.id;
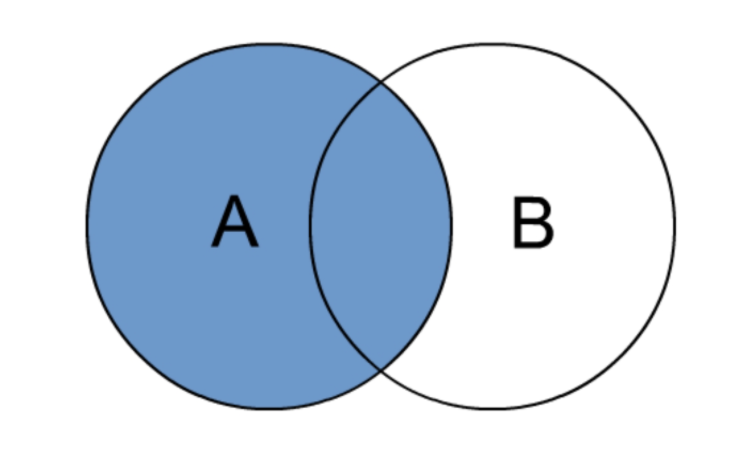
b. LEFT JOIN
LEFT JOIN 中文叫做是左外连接(LEFT OUTER JOIN)或者左连接,其中 OUTER 可以省略,LEFT OUTER JOIN 是早期的写法。LEFT JOIN 的核心就在于 LEFT 左。左指的是 JOIN 关键字左边的表,简称左表。
通俗解释:JOIN 时以左表的全部数据为准,右边与之关联;左表数据全部返回,右表关联上的显示返回,关联不上的显示 NULL 返回。
select e.id, e.name, e_conn.phno, e_conn.email
from employee e
left join employee_connection e_conn
on e.id = e_conn.id;
-- ||
select e.id, e.name, e_conn.phno, e_conn.email
from employee e
left outer join employee_connection e_conn
on e.id = e_conn.id;
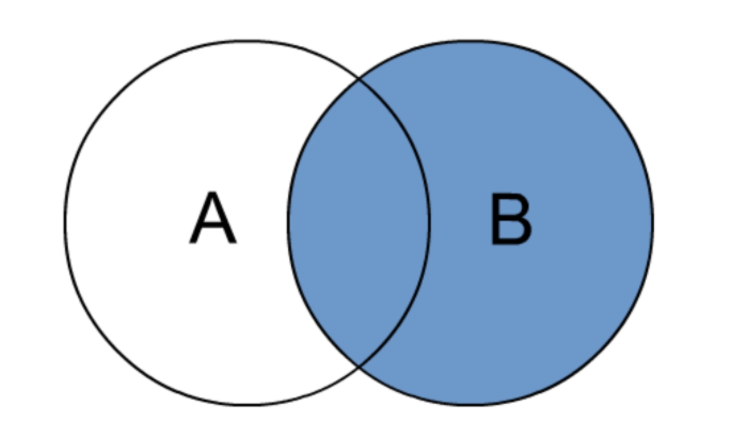
c. RIGHT JOIN
RIGHT JOIN 中文叫做是右外连接(RIGHT OUTER JOIN)或右连接,其中 OUTER 可以省略。
RIGHT JOIN 的核心就在于 RIGHT 右。右指的是 JOIN 关键字右边的表,简称右表。
通俗解释:JOIN 时以右表的全部数据为准,左边与之关联;右表数据全部返回,左表关联上的显示返回,关联不上的显示 NULL 返回。
很明显,RIGHT JOIN 和 LEFT JOIN 之间很相似,重点在于以哪边为准,也就是一个方向的问题。
select e.id, e.name, e_conn.phno, e_conn.email
from employee e
right join employee_connection e_conn
on e.id = e_conn.id;
-- ||
select e.id, e.name, e_conn.phno, e_conn.email
from employee e
right outer join employee_connection e_conn
on e.id = e_conn.id;
d. FULL OUTER JOIN
FULL OUTER JOIN 等价 FULL JOIN,中文叫做全外连接或者外连接。
包含左、右两个表的全部行,不管另外一边的表中是否存在与它们匹配的行 在功能上,它等价于对这两个数据集合分别进行左外连接和右外连接,然后再使用消去重复行的操作将上述两个结果集合并为一个结果集。
select e.id, e.name, e_a.city, e_a.street
from employee e
full outer join employee_address e_a
on e.id = e_a.id;
-- ||
select e.id, e.name, e_a.city, e_a.street
from employee e
full join employee_address e_a
on e.id = e_a.id;
e. LEFT SEMI JOIN
左半开连接(LEFT SEMI JOIN)会返回左边表的记录,前提是其记录对于右边的表满足 ON 语句中的判定条件。
从效果上来看有点像 INNER JOIN 之后只返回左表的结果。
select *
from employee e
left semi
join employee_address e_addr
on e.id = e_addr.id;
-- 相当于 INNER JOIN 只不过效率高一些
select e.*
from employee e
inner join employee_address e_addr
on e.id = e_addr.id;
f. CROSS JOIN
交叉连接 CROSS JOIN 将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积。对于大表来说,CROSS JOIN 慎用。
在 SQL 标准中定义的 CROSS JOIN 就是无条件的 INNER JOIN。返回两个表的笛卡尔积,无需指定关联键。
在 HiveSQL 语法中,CROSS JOIN 后面可以跟 WHERE 子句进行过滤,或者 ON 条件过滤。
-- 下列 A、B、C 执行结果相同,但是效率不一样:
-- A
select a.*, b.*
from employee a,
employee_address b
where a.id = b.id;
-- B
select *
from employee a cross join employee_address b on a.id = b.id;
select *
from employee a cross join employee_address b
where a.id = b.id;
-- C
select *
from employee a inner join employee_address b on a.id = b.id;
一般不建议使用方法 A 和 B,因为如果有 WHERE 子句的话,往往会先进行笛卡尔积返回数据然后才根据 WHERE 条件从中选择。因此,如果两个表太大,将会非常非常慢,不建议使用。
5.3 注意事项
总体来说,随着 Hive 的版本发展,JOIN 语法的功能也愈加丰富。当下我们课程使用的是 3.1.2 版本,有以下几点需要注意:
(1)JOIN 在 WHERE 条件之前进行
(2)允许使用复杂的联接表达式
SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department)
SELECT a.* FROM a LEFT OUTER JOIN b ON (a.id <> b.id)
(3)同一查询中可以连接 2 个以上的表
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
(4)如果每个表在联接子句中使用相同的列,则 Hive 将多个表上的联接转换为单个 MR 作业。
-- 由于联接中仅涉及b的key1列,因此被转换为1个MR作业来执行
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
-- 会转换为两个MR作业,因为在第一个连接条件中使用了b中的key1列,而在第二个连接条件中使用了b中的key2列。
-- 第一个MR作业将a与b联接在一起,然后将结果与c联接到第二个MR作业中。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
(5)JOIN 时的最后一个表会通过 reducer 流式传输,并在其中缓冲之前的其他表,因此,将大表放置在最后有助于减少 reduce 阶段缓存数据所需要的内存。
-- 由于联接中仅涉及b的key1列,因此被转换为1个MR作业来执行,并且表a和b的键的特定值的值被缓冲在reducer的内存中。
-- 然后,对于从c中检索的每一行,将使用缓冲的行来计算联接。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
-- 计算涉及两个MR作业。其中的第一个将a与b连接起来,并缓冲a的值,同时在reducer中流式传输b的值。
-- 在第二个MR作业中,将缓冲第一个连接的结果,同时将c的值通过reducer流式传输。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
(6)在 JOIN 的时候,可以通过语法 STREAMTABLE 提示指定要流式传输的表。如果省略 STREAMTABLE 提示,则 Hive 将流式传输最右边的表。
-- a,b,c三个表都在一个MR作业中联接,并且表b和c的键的特定值的值被缓冲在reducer的内存中。然后,对于从a中检索到的每一行,
-- 将使用缓冲的行来计算联接。如果省略STREAMTABLE提示,则Hive将流式传输最右边的表。
SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
(7)如果除一个要连接的表之外的所有表都很小,则可以将其作为仅 map 作业执行。
-- 不需要reducer。对于A的每个Mapper,B都会被完全读取。限制是不能执行FULL/RIGHT OUTER JOIN b。
SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a JOIN b ON a.key = b.key