1.算法仿真效果
matlab2022a仿真结果如下:
2.算法涉及理论知识概要
ID3算法是一种贪心算法,用来构造决策树。ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。
ID3算法最早是由罗斯昆(J. Ross Quinlan)于1975年在悉尼大学提出的一种分类预测算法,算法的核心是“信息熵”。ID3算法通过计算每个属性的信息增益,认为信息增益高的是好属性,每次划分选取信息增益最高的属性为划分标准,重复这个过程,直至生成一个能完美分类训练样例的决策树。
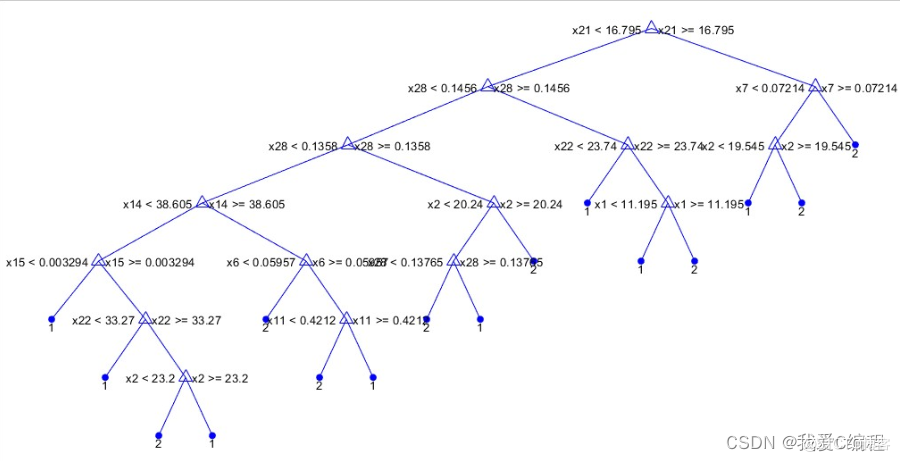
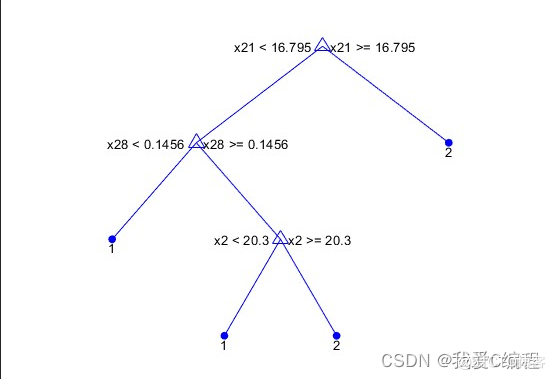
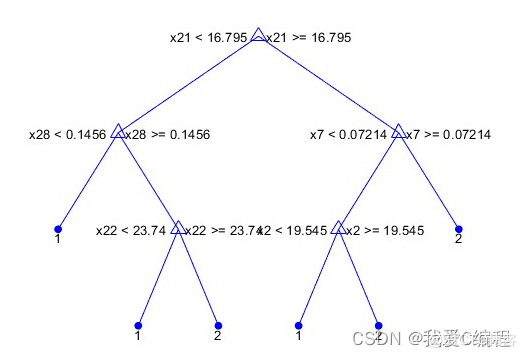
决策树是对数据进行分类,以此达到预测的目的。该决策树方法先根据训练集数据形成决策树,如果该树不能对所有对象给出正确的分类,那么选择一些例外加入到训练集数据中,重复该过程一直到形成正确的决策集。决策树代表着决策集的树形结构。
决策树由决策结点、分支和叶子组成。决策树中最上面的结点为根结点,每个分支是一个新的决策 结点,或者是树的叶子。每个决策结点代表一个问题或决策,通常对应于待分类对象的属性。每一个叶子结点代表一种可能的分类结果。沿决策树从上到下遍历的过程中,在每个结点都会遇到一个测试,对每个结点上问题的不同的测试输出导致不同的分支,最后会到达一个叶子结点,这个过程就是利用决策树进行分类的过程,利用若干个变量来判断所属的类别。
在利用原始数据集构建决策树之前,需要对这些历史用电信息做以下工作:
a) 由于原始数据集中包含有错误的用电调度信息,比如在电价高的时段对蓄电池充电,为了提高决策树的分类正确率,必须先从原始数据集中除去错误和无利用价值的用电调度信息。
b) 由专业人员根据样本中的性能指标数据,运用专业的知识和经验做出正确的调度决策。
c) 在选择分类属性时考虑到各数据之间大小关系对最终决策结果的影响,构建决策树所使用的分类属性定义如下:
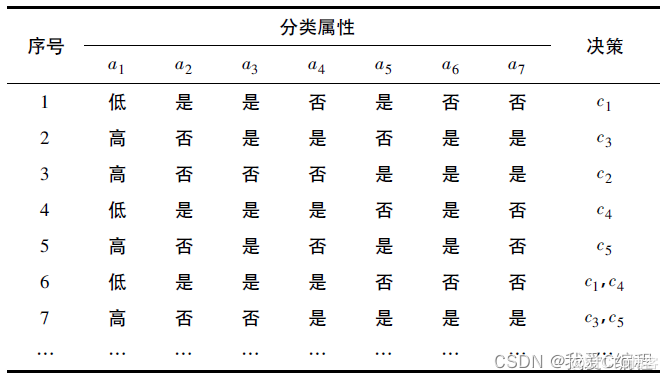
ID3 算法是决策树的经典构建算法,它根据信息增益来评估和选择特征进行划分,每次选择信息增益最大的特征作为判断的模块(即特征节点),可用于划分标称型数据集(即数据中没有缺省特征值的数据集),虽然 ID3 比较灵活方便,但是有以下几个缺点:
(1)采用信息增益进行分裂,缺少剪枝的过程,很可能会出现过拟合的问题。我们可以合并相邻的无法产生大量信息增益的叶子结点(如设置信息增益阈值)。
(2)信息增益和属性的值域范围成正比,也就是有些特征(属性)取值很多,ID3算法很大可能将其作为分裂属性,导致分裂的精确度可能没有采用信息增益率进行分裂高。
(3)不能处理连续分布的数据特征,只能通过将连续性数据转化为离散型数据来解决,也不能处理数据集中的缺省值。
3.MATLAB核心程序
% 2. 训练数据
P_train = Train(:,3:end);
T_train = Train(:,2);
% 3. 测试数据
P_test = Test(:,3:end);
T_test = Test(:,2);
% III. 创建决策树分类器
ctree = ClassificationTree.fit(P_train,T_train);
.............................................................
disp(['病例总数:' num2str(569)...
' 良性:' num2str(total_B)...
' 恶性:' num2str(total_M)]);
disp(['训练集病例总数:' num2str(500)...
' 良性:' num2str(count_B)...
' 恶性:' num2str(count_M)]);
disp(['测试集病例总数:' num2str(69)...
' 良性:' num2str(number_B)...
' 恶性:' num2str(number_M)]);
disp(['良性乳腺肿瘤确诊:' num2str(number_B_sim)...
' 误诊:' num2str(number_B - number_B_sim)...
' 确诊率p1=' num2str(number_B_sim/number_B*100) '%']);
disp(['恶性乳腺肿瘤确诊:' num2str(number_M_sim)...
' 误诊:' num2str(number_M - number_M_sim)...
' 确诊率p2=' num2str(number_M_sim/number_M*100) '%']);
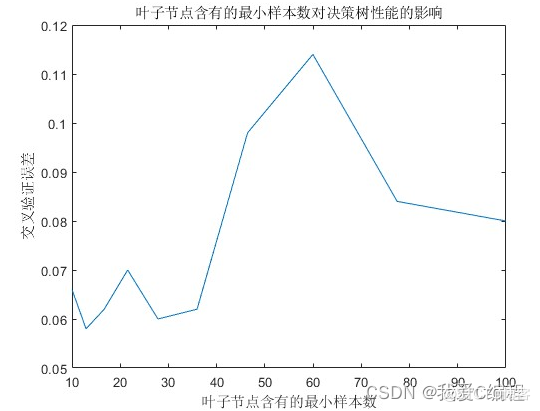
plot(leafs,err);
xlabel('叶子节点含有的最小样本数');
ylabel('交叉验证误差');
title('叶子节点含有的最小样本数对决策树性能的影响')
......................................................................
% 1. 计算剪枝后决策树的重采样误差和交叉验证误差
resubPrune = resubLoss(cptree);
lossPrune = kfoldLoss(crossval(cptree));