- hashcode()、equals()
- string、stringbuffer、stringbuilder
- extends、super
- == 、 equals
- 重载、重写
- list、set
- arraylist、linkedlist
- concurrenthashmap扩容机理
- JDK版本变迁,hashmap的主要变更
- hashmap的put方法
- 深拷贝与浅拷贝
- hashmap扩容机理
- copyonwriteArrayList
- 字节码
- Java异常体系
- 什么时候抛异常?什么时候捕获异常?
- 类加载器
- 类加载器的双亲委派模型
- 线程共享区 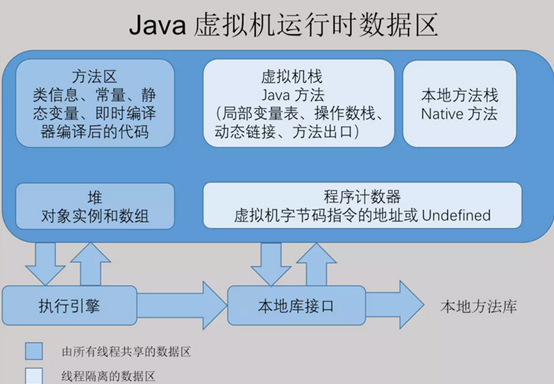
- 如何排查JVM问题-※
- 从加载JVM到GC清理,一共经历什么过程-√
- 如何确定对象是否需要回收
- JVM垃圾回收机制
- 什么是STW
- arraylist
- arraylist
- arraylist
- arraylist
1.如果hashcode()不相同,两个对象一定不是同一个对象
2.如果hashcode()相同,两个对象不一定上同一个对象,需要进一步判别equals
3.如果equals相同,应当认为两个对象就是相同对象
由于hashcode方法仅返回一个值,equals里面有若干逻辑,因此,部分集合类的判断中,会优先判断hashcode,如果相同再继续equals判断
结论:如果改写了equals方法,则必须改写hashcode方法,以便于逻辑一致
string:常量,每次修改都会创建新的字符串常量
stringbuffer:线程安全的字符串变量
stringbuilder:不安全的字符串变量
<? extends T>:?是T的子类
<? super T>:?是T的基类
==:基本类型-看值;引用类型-看引用地址
euqals:看各种类的重写逻辑[逻辑里面也有可能复用==]
重载:针对单一类中,相同方法名,不同方法签名
重写:针对父子类,相同方法名,相同方法签名
重写:返回值类型、抛出异常都必须小于等于父类;访问修饰符大于等于父类
list:有序,可重复,允许多个null,支持下标随机访问
set:无序,不可重复,单一null,必须遍历访问
arraylist:基于数组实现,有利于查找、修改,不利于插入、删除[适用场景不同]
linkedlist:基于链表实现,有利于插入、删除,不利于查找、修改[适用场景不同]
1.7之前:基于segment分段hashmap存储实现的,segment分段存储部分不扩容,仅内部的hashmap进行扩容[哪个线程对应的内部hashmap需要扩容,哪个线程就负责做这个事情]
1.8之后:不是基于segment分段存储实现的,所有的K-V对都包含在一个map中,只是扩容的时候,那就每个子线程都参与扩容
1.7:底层是数组+链表,哈希算法复杂
1.8:底层是数组+链表+红黑树,由于引入红黑树,哈希算法得到简化,从而优化hashmap的插入、查询效率
大体流程:
1.依据key和哈希算法计算下标
2.如果下标位置为空,则封装成对象(1.7:entry对象,1.8:node对象),放置该位置
3.如果下标位置不空,
3.1 JDK1.7:判断是否需要扩容,然后,头插法插入到对应位置的链表中
3.2 JDK.8:判断是红黑树节点还是链表节点,然后插入到hashmap里面,最后判断扩容
3.2.1 红黑树节点:将KV对封装成红黑树节点,加入到红黑树中
3.2.2 链表节点:尾插法插入到对应位置的链表中,如果多于等于8个节点,将链表转为红黑树
浅拷贝:基本数据类型拷贝了第二份,引用类型的变量全部都是拷贝了一份引用地址,指向了原来的地方。
深拷贝:所有数据类型都拷贝了第二份,不仅仅拷贝引用地址。
1.7:生成新数组,遍历原数组上的每个链表,将内部数据逐个转移至新数组
1.8:生成新数组,遍历原数组上的每个链表与红黑树
①如果原数组上是链表,遍历每个元素,重新计算下标并转移
②如果原数组上是红黑树,遍历每个元素,重新计算下标并转移,有冲突再购建链表与红黑树
线程安全的arrayList,底层也是用数组实现的,主要集中在读与写操作上
读:由于读写分别在老新数组上,因此,互相不干扰,也因此,读的性能不会受写的性能影响[适用于读多写少]
写:写操作会生成新数组,在完成之前,其他线程无法进行写操作[上了锁,线程安全];在完成之前,读的是原数组,写的是新数组,两者是不会互相干扰的。
定义:字节码文件是Java源码编译过后的一种格式,各个平台上相同的源码编译出的字节码是相同的,但是,字节码转化的机器码不相同,这个转化上JDK(JRE)做的,因此,Java上跨平台语言
相当于编译过程所指的,中间代码[前有词法分析、语法分析、语义分析][后有代码优化、目标代码生成]
优点:实现了语言的跨平台;编译过程可以做代码优化,提高执行效率
graph TD;
Throwable
-->
Exception
Throwable
-->
Error
Exception
-->
RuntimeException
Exception
-->
非RuntimeException
error是非常严重的错误,程序已无法正常运行,没必要捕获
运行时异常,一般是逻辑问题,应尽量避免
非运行时异常,不处理无法正常运行,必须处理
抛:自身无法处理就往上抛,由上级处理
捕获:自身能处理就捕获,捕获走既定处理流程
graph TD;
bootstrapClassLoader负责加载JAVA_HOME下lib里面的jar包与类文件
-->
ExtClassLoader负责加载JAVA_HOME下lib下ext里面的jar包与类文件
-->
AppClassLoader负责加载classpath路径下的类文件
由16可知,类加载器共三个,AppClassLoader有两个父类
当AppClassLoader加载时,会优先调用父类的加载器,这种JVM机制叫做双亲委派模型
AppClassLoader.loadClass(){
ExtClassLoader.loadClass(){
bootstrapClassLoader.loadClass();
}
}
堆区与方法区是所有线程共享的
栈区:主要存放基本数据类型与对象引用(仅限局部变量,成员变量不管是不是基本数据类型都存放于堆)
堆区:主要存放对象实例与数组[我的理解就是,由代码操作生成的对象或者说引用类型存放于堆]
方法区:类信息(class文件)、静态变量与静态方法
本地方法栈:非静态方法
空间:jmap 查看 JVM各个区域的占用情况,查看是否栈区过大?是否堆区过大?
时间:jstack 查看线程的运行情况,是否存在死锁或者阻塞?
OOM:
查看: jstat 查看垃圾回收情况,fullgc 与 younggc 的运行情况
记录: JVM启动参数 --> -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/base,发生OOM的时候记录下当时的情况-dump文件,便于回溯定位问题
分析:jvisualvm 可以针对dump文件进行分析异常对象,异常线程
1.方法区加载字节码,加载静态方法、静态成员变量
2.堆区创建实例化对象,保存至 年轻代 Eden 区
3.将引用传回栈区
4.经过minor GC,对象每次存活,年龄加一,并迁移至survival区-存活区,年龄大于等于15的时候,对象进入老年代
5.栈区的引用被移除以后,对象最终被GC回收
根可达算法:所有对象都是基于一个根对象上的,从根对象开始遍历,能找到引用的就是还需要的对象,否则就是不需要的对象。
总共三种算法:
标记:将所有对象判断是否根可达,将不可达对象标记并进行删除
缺点:会有碎片空间出现
复制法:申请一块与当前存储空间相同的空间,根可达算法标记所有存活对象,将存活对象迁移至新申请空间,迁移完毕以后,原空间统一清空
缺点:需要的空间较大
标记优化法:根可达算法标记所有存活对象,并将存活对象重新排列至连续空间,标记以及迁移排列完毕以后,将存活对象连续空间以外的空间统一清除
STW,stop the world,即,在GC运行过程中,要将所有Java进程冻结,以便于GC进程进行垃圾回收。
参考:
- https://blog.csdn.net/liwenxiang629/article/details/109508530
- https://blog.csdn.net/weixin_43235210/article/details/90444710?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-90444710-blog-109508530.235%5Ev38%5Epc_relevant_sort&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-90444710-blog-109508530.235%5Ev38%5Epc_relevant_sort&utm_relevant_index=2