0.参考文档
1.TensorFlow的几个核心概念
-
张量和计算图
- TensorFlow -> 张量流动
- 程序=数据结构+算法 -> TensorFlow程序=张量数据结构+计算图算法语言
-
三种计算图
- 静态计算图
- 在TensorFlow1.0时代,采用的是静态计算图,需要先使用TensorFlow的各种算子创建计算图,然后再开启一个会话Session,显式执行计算图
- 动态计算图
- 而在TensorFlow2.0时代,采用的是动态计算图,即每使用一个算子后,该算子会被动态加入到隐含的默认计算图中立即执行得到结果,而无需开启Session
- 使用动态计算图即Eager Execution的好处是方便调试程序,它会让TensorFlow代码的变现和Python原生代码的表现一致,写起来像numpy一样,各种日志打印,控制流全部都是可以使用的
- 使用动态计算图的缺点是运行效率相对会低一些。因为使用动态图会有许多次Python进程和TensorFlow的C++进程之间的通信。而静态计算图构建完成之后几乎全部在TensorFlow内核上使用C++代码执行,效率更高。此外静态计算图会对计算步骤进行一定的优化,剪去和结果无关的计算步骤
- Autograph
- 如果需要在TensorFlow2.0中使用静态计算图,可以使用@tf.function装饰器将普通的Python函数转换成对应的TensorFlow计算图构建代码。运行该函数就相当于在TensorFlow1.0中用Session执行代码。使用tf.function构建静态计算图的方式叫作Autograph
- Autograph的使用规范
- 被@tf.function修饰的函数应尽可能使用TensorFlow中的函数而不是Python中的其他函数。例如使用tf.print而不是print,使用tf.range而不是range,使用tf.constant(True)而不是True
- Python中的函数仅仅会在跟踪执行函数以创建静态图的阶段使用,普通Python函数是无法嵌入到静态计算图中的,所以在计算图构建好之后再次调用时,这些Python函数并没有被计算,而TensorFlow中的函数则可以嵌入到计算图中。使用普通的Python函数会导致 被@tf.function修饰前【eager执行】和被@tf.function修饰后【静态图执行】的输出不一致。
- 避免在@tf.function修饰的函数内部定义tf.Variable
- 如果函数内部定义了tf.Variable,那么在【eager执行】时,这种创建tf.Variable的行为在每次函数调用时候都会发生。但是在【静态图执行】时,这种创建tf.Variable的行为只会发生在第一步跟踪Python代码逻辑创建计算图时,这会导致被@tf.function修饰前【eager执行】和被@tf.function修饰后【静态图执行】的输出不一致。实际上,TensorFlow在这种情况下一般会报错。
- 被@tf.function修饰的函数不可修改该函数外部的Python列表或字典等数据结构变量
- 静态计算图是被编译成C++代码在TensorFlow内核中执行的。Python中的列表和字典等数据结构变量是无法嵌入到计算图中,它们仅仅能够在创建计算图时被读取,在执行计算图时是无法修改Python中的列表或字典这样的数据结构变量的。
- 被@tf.function修饰的函数应尽可能使用TensorFlow中的函数而不是Python中的其他函数。例如使用tf.print而不是print,使用tf.range而不是range,使用tf.constant(True)而不是True
- 静态计算图
-
TensorFlow的自动微分机制
-
TensorFlow一般使用梯度磁带tf.GradientTape来记录正向运算过程,然后反播磁带自动得到梯度值;这种利用tf.GradientTape求微分的方法叫作TensorFlow的自动微分机制
-
tf.GradientTape非常灵活,除了对变量张量求导外,可以常量张量求导,增加watch即可;也可以求二阶导数
-
x = tf.Variable(0.0, name='x', dtype=tf.float32) a = tf.constant(1.0) b = tf.constant(-2.0) c = tf.constant(1.0) optimizer = tf.keras.optimizers.SGD(learning_rate=0.01) for _ in range(1000): with tf.GradientTape() as tape: y = a*tf.pow(x, 2) + b*x + c dy_dx = tape.gradient(y, x) optimizer.apply_gradients(grads_and_vars=[(dy_dx, x)]) tf.print('y=', y, ";x=", x) """ y= 0 ;x= 0.999998569 """
-
-
TensorFlow的API分层
-
低阶API
-
低阶API主要包括张量操作,计算图和自动微分
-
import numpy as np import pandas as pd import matplotlib.pyplot as plt import tensorflow as tf # 样本数量 n = 400 # 生成测试用数据集 X = tf.random.uniform([n, 2], minval=-10, maxval=10) w0 = tf.constant([[2.0], [-3.0]]) b0 = tf.constant([[3.0]]) Y = X@w0 + b0 + tf.random.normal([n, 1], mean=0.0, stddev=2.0) # @表示矩阵乘法,增加正态扰动 def data_iter(features, labels, batch_size=8): num_examples = len(features) indices = list(range(num_examples)) np.random.shuffle(indices) # 样本的读取顺序是随机的 for i in range(0, num_examples, batch_size): indexes = indices[i: min(i + batch_size, num_examples)] yield tf.gather(features, indexes), tf.gather(labels, indexes) # 根据indices从params的指定轴axis索引元素 w = tf.Variable(tf.random.normal(w0.shape)) b = tf.Variable(tf.zeros_like(b0, dtype=tf.float32)) # 定义模型 class LinearRegression: # 正向传播 def __call__(self, x): return x@w + b # 损失函数 def loss_func(self, y_true, y_pred): return tf.reduce_mean((y_true - y_pred) ** 2 / 2) model = LinearRegression() @tf.function def train_step(model, features, labels): with tf.GradientTape() as tape: predictions = model(features) loss = model.loss_func(labels, predictions) # 反向传播求梯度 dloss_dw, dloss_db = tape.gradient(loss, [w, b]) # 梯度下降更新参数 w.assign(w - 0.001 * dloss_dw) b.assign(b - 0.001 * dloss_db) return loss def train_model(model, epochs): for epoch in tf.range(1, epochs+1): for features, labels in data_iter(X, Y, 10): loss = train_step(model, features, labels) if epoch % 50 == 0: printbar() tf.print("epoch=", epoch, "loss=", loss) tf.print("w=", w) tf.print("b=", b) train_model(model, epochs=200)
-
-
中阶API
-
TensorFlow的中阶API主要包括各种模型层,损失函数,优化器,数据管道,特征列等等.
-
import tensorflow as tf from tensorflow.keras import layers,losses,metrics,optimizers # 样本数量 n = 800 # 生成测试用数据集 X = tf.random.uniform([n, 2], minval=10, maxval=10) w0 = tf.constant([[2.0], [-1.0]]) b0 = tf.constant(3.0) Y = X@w0 + b0 + tf.random.normal([n, 1], mean=0.0, stddev=2.0) # @表示矩阵乘法,增加正态扰动 # 构建输入数据管道 ds = tf.data.Dataset.from_tensor_slices((X, Y)) \ .shuffle(buffer_size=1000) \ .batch(100) \ .prefetch(tf.data.experimental.AUTOTUNE) # 表示tf.data模块运行时,框架会根据可用的CPU自动设置最大的可用线程数,以使用多线程进行数据通道处理,将机器的算力拉满。注意返回的变量其实是个常量,表示可用的线程数目。 # 定义优化器 optimizer = optimizers.SGD(learning_rate=0.001) linear = layers.Dense(units=1) linear.build(input_shape=(2,)) # 初始化模型 @tf.function def train(epoches): for epoch in tf.range(1, epoches+1): L = tf.constant(0.0) # 使用L记录loss值 for X_batch, Y_batch in ds: with tf.GradientTape() as tape: Y_hat = linear(X_batch) loss = losses.mean_squared_error(tf.reshape(Y_hat, [-1]), tf.reshape(Y_batch, [-1])) grads = tape.gradient(loss, linear.variables) optimizer.apply_gradients(zip(grads, linear.variables)) L = loss if (epoch % 100 == 0): printbar() tf.print("epoch=", epoch, "loss=", L) tf.print("w=", linear.kernel) tf.print("b=", linear.bias) tf.print("") train(500)
-
-
高阶API
- Tensorflow的高阶API主要为 tf.keras.models提供的模型的类接口;使用Keras接口有以下3种方式构建模型:使用Sequential按层顺序构建模型,使用函数式API构建任意结构模型,继承Model基类构建自定义模型
- 后续章节提供代码示例
-
2.构建TensorFlow模型的几个关键元素
-
数据管道Dataset
-
如果需要训练的数据大小不大,例如不到1G,那么可以直接全部读入内存中进行训练,这样一般效率最高。 但如果需要训练的数据很大,例如超过10G,无法一次载入内存,那么通常需要在训练的过程中分批逐渐读入。使用 tf.data API 可以构建数据输入管道,轻松处理大量的数据,不同的数据格式,以及不同的数据转换。
-
可以从 Numpy array, Pandas DataFrame, Python generator, csv文件, 文本文件, 文件路径, tfrecords文件等方式构建数据管道。
其中通过Numpy array, Pandas DataFrame, 文件路径构建数据管道是最常用的方法。
-
import tensorflow as tf from sklearn import datasets import pandas as pd iris = datasets.load_iris() dfiris = pd.DataFrame(iris['data'], columns=iris.feature_names) ds2 = tf.data.Dataset.from_tensor_slices((dfiris.to_dict('list'), iris['target'])) for features, label in ds2.take(3): tf.print(features, label) -
转换功能
-
Dataset数据结构应用非常灵活,因为它本质上是一个Sequece序列,其每个元素可以是各种类型,例如可以是张量,列表,字典,也可以是Dataset。
Dataset包含了非常丰富的数据转换功能。
- map: 将转换函数映射到数据集每一个元素。
- flat_map: 将转换函数映射到数据集的每一个元素,并将嵌套的Dataset压平。
- interleave: 效果类似flat_map,但可以将不同来源的数据夹在一起。
- filter: 过滤掉某些元素。
- zip: 将两个长度相同的Dataset横向铰合。
- concatenate: 将两个Dataset纵向连接。
- reduce: 执行归并操作。
- batch : 构建批次,每次放一个批次。比原始数据增加一个维度。 其逆操作为unbatch。
- padded_batch: 构建批次,类似batch, 但可以填充到相同的形状。
- window :构建滑动窗口,返回Dataset of Dataset.
- shuffle: 数据顺序洗牌。
- repeat: 重复数据若干次,不带参数时,重复无数次。
- shard: 采样,从某个位置开始隔固定距离采样一个元素。
- take: 采样,从开始位置取前几个元素。
-
-
提升管道性能
-
训练深度学习模型常常会非常耗时。
模型训练的耗时主要来自于两个部分,一部分来自数据准备,另一部分来自参数迭代。
参数迭代过程的耗时通常依赖于GPU来提升。
而数据准备过程的耗时则可以通过构建高效的数据管道进行提升。
以下是一些构建高效数据管道的建议。
- 1、使用 prefetch 方法让数据准备和参数迭代两个过程相互并行。
- 2、使用 interleave 方法可以让数据读取过程多进程执行,并将不同来源数据夹在一起。
- 3、使用 map 时设置num_parallel_calls 让数据转换过程多进行执行。
- 4、使用 cache 方法让数据在第一个epoch后缓存到内存中,仅限于数据集不大情形。
- 5、使用 map 转换时,先batch, 然后采用向量化的转换方法对每个batch进行转换。
-
-
-
特征列feature_column
-
特征列 通常用于对结构化数据实施特征工程时候使用,图像或者文本数据一般不会用到特征列
使用特征列可以将类别特征转换为one-hot编码特征,将连续特征构建分桶特征,以及对多个特征生成交叉特征等等。
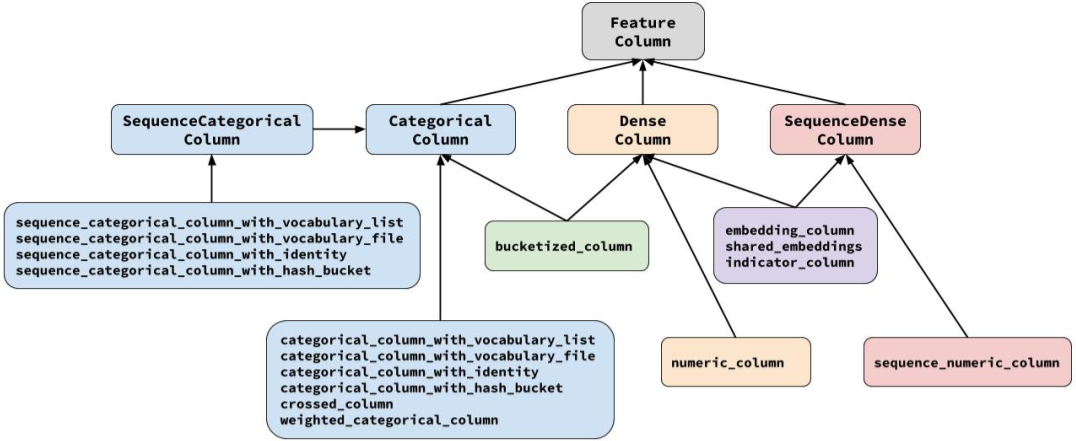
要创建特征列,请调用 tf.feature_column 模块的函数。该模块中常用的九个函数如下图所示,所有九个函数都会返回一个 Categorical-Column 或一个 Dense-Column 对象,但却不会返回 bucketized_column,后者继承自这两个类。
注意:所有的Catogorical Column类型最终都要通过indicator_column转换成Dense Column类型才能传入模型!
-
总体
-
介绍
-
- numeric_column 数值列,最常用。
- bucketized_column 分桶列,由数值列生成,可以由一个数值列出多个特征,one-hot编码。
- categorical_column_with_identity 分类标识列,one-hot编码,相当于分桶列每个桶为1个整数的情况。
- categorical_column_with_vocabulary_list 分类词汇列,one-hot编码,由list指定词典。
- categorical_column_with_vocabulary_file 分类词汇列,由文件file指定词典。
- categorical_column_with_hash_bucket 哈希列,整数或词典较大时采用。
- indicator_column 指标列,由Categorical Column生成,one-hot编码
- embedding_column 嵌入列,由Categorical Column生成,嵌入矢量分布参数需要学习。嵌入矢量维数建议取类别数量的 4 次方根。
- crossed_column 交叉列,可以由除categorical_column_with_hash_bucket的任意分类列构成。
-
-
代码示例
-
sex = tf.feature_column.indicator_column( tf.feature_column.categorical_column_with_vocabulary_list( key='sex', vocabulary_list=['male', 'female'] ) ) feature_columns.append(sex) pclass = tf.feature_column.indicator_column( tf.feature_column.categorical_column_with_vocabulary_list( key='pclass', vocabulary_list=[1, 2, 3] ) ) feature_columns.append(pclass) ticket = tf.feature_column.indicator_column( tf.feature_column.categorical_column_with_hash_bucket('ticket', 3) # 桶个数为3 ) feature_columns.append(ticket) embarked = tf.feature_column.indicator_column( tf.feature_column.categorical_column_with_vocabulary_list( key='embarked', vocabulary_list=['S', 'C', 'B'] ) ) feature_columns.append(embarked) # 嵌入列 cabin = tf.feature_column.embedding_column( tf.feature_column.categorical_column_with_hash_bucket('cabin', 32), 2 ) feature_columns.append(cabin) # 交叉列 pclass_cate = tf.feature_column.categorical_column_with_vocabulary_list( key='pclass', vocabulary_list=[1, 2, 3] ) crossed_feature = tf.feature_column.indicator_column( tf.feature_column.crossed_column([age_buckets, pclass_cate], hash_bucket_size=15) ) feature_columns.append(crossed_feature)
-
-
-
激活函数
- tf.keras.activations
-
模型层
- tf.keras.layers
-
损失函数
- tf.keras.losses
-
评估指标
- tf.keras.metrics
-
优化器
- tf.keras.optimizers
-
回调函数
- tf.keras.callbacks
3.如何构建及训练TensorFlow模型
-
构建TensorFlow模型的三种方法
-
对于顺序结构的模型,优先使用Sequential方法构建。
如果模型有多输入或者多输出,或者模型需要共享权重,或者模型具有残差连接等非顺序结构,推荐使用函数式API进行创建。
如果无特定必要,尽可能避免使用Model子类化的方式构建模型,这种方式提供了极大的灵活性,但也有更大的概率出错。
下面以IMDB电影评论的分类问题为例,演示3种创建模型的方法。 -
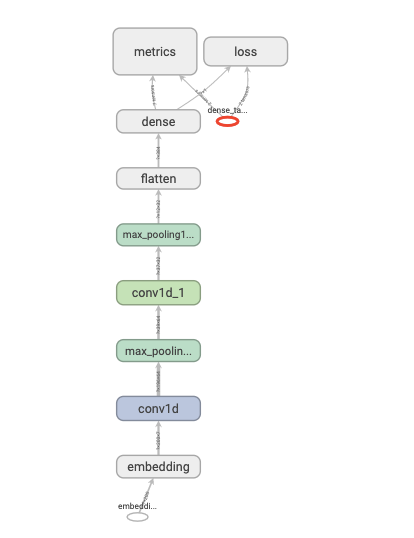
使用Sequential按层顺序构建模型
-
tf.keras.backend.clear_session() model = models.Sequential() model.add(layers.Embedding(MAX_WORDS, 7, input_length=MAX_LEN)) model.add(layers.Conv1D(filters=64, kernel_size=5, activation="relu")) # kernel_size: An integer or tuple/list of a single integer, specifying the length of the 1D convolution window. model.add(layers.MaxPool1D(2)) model.add(layers.Conv1D(filters=32, kernel_size=3, activation="relu")) model.add(layers.MaxPool1D(2)) model.add(layers.Flatten()) model.add(layers.Dense(1, activation="sigmoid")) model.compile(optimizer='Nadam', loss="binary_crossentropy", metrics=['accuracy', 'AUC']) -
-
-
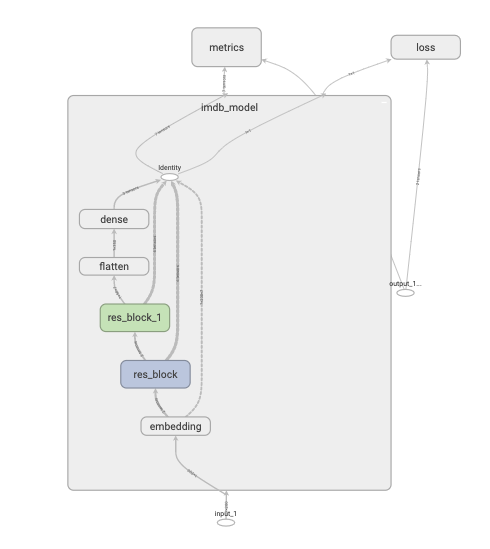
继承Model基类构建自定义模型
-
class ResBlock(layers.Layer): def __init__(self, kernel_size, **kwargs): super().__init__(**kwargs) self.kernel_size = kernel_size def build(self, input_shape): self.conv1 = layers.Conv1D(filters=64, kernel_size=self.kernel_size, activation="relu", padding="same") self.conv2 = layers.Conv1D(filters=32, kernel_size=self.kernel_size, activation="relu", padding="same") self.conv3 = layers.Conv1D(filters=input_shape[-1], kernel_size=self.kernel_size, activation="relu", padding="same") self.maxpool = layers.MaxPool1D(2) super().build(input_shape) # 相当于设置self.built=True def call(self, inputs): x = self.conv1(inputs) x = self.conv2(x) x = self.conv3(x) x = layers.Add()([inputs, x]) x = self.maxpool(x) return x # 如果要让自定义的Layer通过Functional API组合成模型时可以序列化,需要自定义 get_config方法 def get_config(self): config = super().get_config() config.update({"kernel_size": self.kernel_size}) return config class ImdbModel(models.Model): def __init__(self): super().__init__() def build(self, input_shape): self.embedding = layers.Embedding(MAX_WORDS, 7) self.block1 = ResBlock(7) self.block2 = ResBlock(5) self.dense = layers.Dense(1, activation="sigmoid") super().build(input_shape) def call(self, x): x = self.embedding(x) x = self.block1(x) x = self.block2(x) x = layers.Flatten()(x) x = self.dense(x) return x tf.keras.backend.clear_session() model = ImdbModel() model.build(input_shape=(None, 200)) model.compile(optimizer="Nadam", loss="binary_crossentropy", metrics=["accuracy", "AUC"]) -
-
-
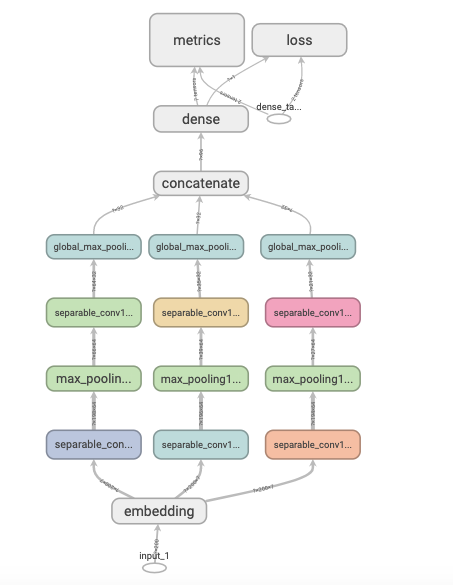
使用函数式API构建任意结构模型
-
tf.keras.backend.clear_session() inputs = layers.Input(shape=[MAX_LEN]) x = layers.Embedding(MAX_WORDS, 7)(inputs) branch1 = layers.SeparableConv1D(64, 3, activation="relu")(x) # 可分离卷积,用不同的卷积核在各个通道上进行卷积,然后再用一个卷积核将不同的通道合并 branch1 = layers.MaxPool1D(3)(branch1) branch1 = layers.SeparableConv1D(32, 3, activation="relu")(branch1) branch1 = layers.GlobalMaxPool1D()(branch1) branch2 = layers.SeparableConv1D(64, 5, activation="relu")(x) # 可分离卷积,用不同的卷积核在各个通道上进行卷积,然后再用一个卷积核将不同的通道合并 branch2 = layers.MaxPool1D(3)(branch2) branch2 = layers.SeparableConv1D(32, 5, activation="relu")(branch2) branch2 = layers.GlobalMaxPool1D()(branch2) branch3 = layers.SeparableConv1D(64, 7, activation="relu")(x) # 可分离卷积,用不同的卷积核在各个通道上进行卷积,然后再用一个卷积核将不同的通道合并 branch3 = layers.MaxPool1D(3)(branch3) branch3 = layers.SeparableConv1D(32, 7, activation="relu")(branch3) branch3 = layers.GlobalMaxPool1D()(branch3) concat = layers.Concatenate()([branch1, branch2, branch3]) outputs = layers.Dense(1, activation="sigmoid")(concat) model = models.Model(inputs=inputs, outputs=outputs) model.compile(optimizer="Nadam", loss="binary_crossentropy", metrics=["accuracy", "AUC"]) -
-
-
-
训练TensorFlow模型的三种方法
-
内置fit方法
-
该方法功能非常强大, 支持对numpy array, tf.data.Dataset以及 Python generator数据进行训练。
并且可以通过设置回调函数实现对训练过程的复杂控制逻辑。 -
history = model.fit(ds_train, validation_data=ds_test, epochs=10)
-
-
内置train_on_batch方法
-
该内置方法相比较fit方法更加灵活,可以不通过回调函数而直接在批次层次上更加精细地控制训练的过程。
-
def train_model(model, ds_train, ds_valid, epoches): for epoch in tf.range(1, epoches+1): model.reset_metrics() for x, y in ds_train: train_result = model.train_on_batch(x, y) for x, y in ds_valid: valid_result = model.test_on_batch(x, y, reset_metrics=False)
-
-
自定义训练循环
-
自定义训练循环无需编译模型,直接利用优化器根据损失函数反向传播迭代参数,拥有最高的灵活性。
-
optimizer = optimizers.Nadam() loss_func = losses.SparseCategoricalCrossentropy() train_loss = metrics.Mean(name="train_loss") train_metric = metrics.SparseCategoricalAccuracy(name="train_accuracy") valid_loss = metrics.Mean(name="valid_loss") valid_metric = metrics.SparseCategoricalAccuracy(name="valid_accuracy") @tf.function def train_step(model, features, labels): with tf.GradientTape() as tape: predictions = model(features, training=True) loss = loss_func(labels, predictions) gradients = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(gradients, model.trainable_variables)) train_loss.update_state(loss) train_metric.update_state(labels, predictions) @tf.function def valid_step(model, features, labels): predictions = model(features) batch_loss = loss_func(labels, predictions) valid_loss.update_state(batch_loss) valid_metric.update_state(labels, predictions) def train_model(model, ds_train, ds_valid, epochs): for epoch in tf.range(1, epochs+1): for features, labels in ds_train: train_step(model, features, labels) for features, labels in ds_valid: valid_step(model, features, labels) logs ='Epoch={},Loss={},Accuracy={},Valid Loss={},Valid Accuracy={}' if epoch % 1 == 0: printbar() tf.print(tf.strings.format(logs, (epoch, train_loss.result(), train_metric.result(), valid_loss.result(), valid_metric.result()))) tf.print() train_loss.reset_states() valid_loss.reset_states() train_metric.reset_states() valid_metric.reset_states() train_model(model, ds_train, ds_test, 10)
-
-
4.最佳实践
-
tf.nn与tf.keras
-
-
tf.nn:tf.nn模块提供了一系列的神经网络相关操作,用于构建自定义的神经网络层或其他计算图节点。这些操作包括卷积、池化、激活函数、归一化等。tf.nn主要关注底层的神经网络操作,提供了更灵活的接口和较低级别的控制。
-
tf.keras:tf.keras是一个高级API,用于构建和训练深度学习模型。它基于Keras库,并集成到TensorFlow中。tf.keras提供了更简洁易用的接口,可以方便地定义和训练各种类型的神经网络模型。它支持常见的深度学习任务,如图像分类、文本生成、序列建模等。
-
使用哪个模块取决于你对深度学习框架的需求和使用场景。如果你想进行更底层的操作或自定义层,可以使用tf.nn;如果你想快速构建和训练深度学习模型,并且对简洁性更看重,可以选择tf.keras。需要注意的是,这两个模块并不互斥,可以在同一个项目中根据需要同时使用它们。
-
-
本文档主要以tf.keras模块为主,tf.keras已经非常强大,基本可以满足当前的需求,不满足的一些特殊场景,再辅以tf.nn模块以及其他tf操作解决。
-
-
使用函数式API构建模型
- 灵活强大,基本可以实现所有结构的模型。
-
使用自定义训练循环训练模型
- 灵活强大,可以实现所有自定义的操作,比如各种自定义回调的实现、各种自定义打印信息的输出等。
-
如何通过最佳实践的方式快速构建模型
-
pip install -i http://10.177.153.169:8080/simple ec_tc_py_commons --trusted-host 10.177.153.169
-
from tf_best_practices_example.tf_code_examples import TfCodeBestPractices tf_code_best_practice = TfCodeBestPractices() code_examples = tf_code_best_practice.get_examples() tf_code_best_practice.show_all_functions() tf_code_best_practice.show_all_steps() tf_code_best_practice.get_source_code(code_examples.pipeline_train_model)
-
# -*- coding: utf-8 -*-
"""
@File : tf_code_examples.py
@Time : 2023/10/30 12:18
@Author : YH000780
@Email : nizhiwei@danghuan.com
@Desc : tf 2.8.0 python 3.7+ 函数式构建模型、自定义训练循环 示例
"""
from enum import Enum
import hashlib
from typing import Union, Dict, List
import inspect
import tensorflow as tf
import pandas as pd
class CodeExamples(Enum):
transform_by_hash = 0
df_to_dataset = 1
standard_num_feature = 2
examples_define_model_inputs = 3
examples_define_feature_column = 4
examples_define_model_layers = 5
examples_define_model = 6
printbar = 7
train_step = 8
valid_step = 9
pipeline_train_model = 10
examples_training = 11
plot_model = 12
def transform_by_hash(x: Union[str, int], reserved_digits: int = 4) -> int:
"""
使用md5算法将类别类特征转换为哈希值。
:param x: 接收字符串或int类型的原始值
:param reserved_digits: 保留的哈希值位数
:return: 哈希结果
"""
mod_num = 10 ** reserved_digits
m = hashlib.md5()
m.update(str(x).encode(encoding='utf-8'))
return int(m.hexdigest(), base=16) % mod_num
def df_to_dataset(df: pd.DataFrame, shuffle: bool = False, batch_size: int = 128) -> tf.data.Dataset:
"""
将DataFrame转换为Dataset。
:param df: 原始数据
:param shuffle: 是否shuffle,默认False
:param batch_size: Batch大小,默认128
:return: 转换后的Dataset
"""
dfdata = df.copy()
labels = dfdata.pop('label')
ds = tf.data.Dataset.from_tensor_slices((dfdata.to_dict(orient='list'), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dfdata))
ds = ds.batch(batch_size)
return ds
def standard_num_feature(feature: float, min_value: float, max_value: float):
"""
标准化数值特征。
:param feature: 原特征值
:param min_value: 最小值
:param max_value: 最大值
:return: 标准化后的特征值
"""
return (feature - min_value) / (max_value - min_value)
def examples_define_model_inputs() -> Dict:
"""
一个关于构建模型输入的示例,需要自己根据自己的模型特征定义。
:return: 示例模型输入定义。
"""
inputs = {
'model': tf.keras.layers.Input(name='model', shape=(), dtype='int32'),
'sku_color': tf.keras.layers.Input(name='sku_color', shape=(), dtype='int32'),
'sku_phone_source': tf.keras.layers.Input(name='sku_phone_source', shape=(), dtype='int32'),
'sku_running_memory': tf.keras.layers.Input(name='sku_running_memory', shape=(), dtype='float32'),
'sku_phone_storage': tf.keras.layers.Input(name='sku_phone_storage', shape=(), dtype='float32'),
'evaluation_level': tf.keras.layers.Input(name='evaluation_level', shape=(), dtype='int32')
}
return inputs
def examples_define_feature_column() -> List:
"""
一个关于定义特征列的示例,需要自己根据自己的模型输入定义。
:return: 定义好的特征列.
"""
model_emd_col = tf.feature_column.categorical_column_with_hash_bucket(key='model', hash_bucket_size=128, dtype=tf.int32)
model_emb_col = tf.feature_column.embedding_column(model_emd_col, 10)
sku_color_emb_col = tf.feature_column.categorical_column_with_hash_bucket(key='sku_color', hash_bucket_size=128, dtype=tf.int32)
sku_color_emb_col = tf.feature_column.embedding_column(sku_color_emb_col, 10)
vl_sku_phone_source = ['A', 'B', 'C']
sku_phone_source_col = tf.feature_column.categorical_column_with_vocabulary_list(key='sku_phone_source', vocabulary_list=vl_sku_phone_source)
sku_phone_source_col = tf.feature_column.indicator_column(sku_phone_source_col)
evaluation_level_emb_col = tf.feature_column.categorical_column_with_hash_bucket(key='evaluation_level', hash_bucket_size=64, dtype=tf.int32)
evaluation_level_emb_col = tf.feature_column.embedding_column(evaluation_level_emb_col, 10)
sku_phone_storage_col = tf.feature_column.numeric_column(key='sku_phone_storage')
feature_columns = [model_emb_col, sku_color_emb_col, sku_phone_source_col, evaluation_level_emb_col, sku_phone_storage_col]
return feature_columns
def examples_define_model_layers(inputs: Dict, feature_columns: List) -> tf.keras.layers.Layer:
"""
一个关于自定义模型层的示例,这里仅展示了一个顺序的块状结构,实际可以有多个块,块与块之间也可以拼接,实现任意的自定义结构。
:param inputs: 已经定义的模型输入
:param feature_columns: 与模型输入对应的特征列
:return: 定义好的模型层
"""
layer_dense_features = tf.keras.layers.DenseFeatures(feature_columns, name='layer_dense_features')(inputs)
layer_hidden1 = tf.keras.layers.Dense(32, name='layer_hidden1')(layer_dense_features)
layer_hidden1_prelu = tf.keras.layers.PReLU(name='layer_hidden1_prelu')(layer_hidden1)
layer_hidden2 = tf.keras.layers.Dense(8, name='layer_hidden2')(layer_hidden1_prelu)
layer_hidden2_prelu = tf.keras.layers.PReLU(name='layer_hidden2_prelu')(layer_hidden2)
layer_output = tf.keras.layers.Dense(1, name='layer_output')(layer_hidden2_prelu)
return layer_output
def examples_define_model(inputs: Dict, output: tf.keras.layers.Layer) -> tf.keras.Model:
"""
一个关于自定义模型的示例,只要定义好了输入和输出,这里只需用tf.keras.Model包装一下即可。
:param inputs: 已定义好的模型输入
:param output: 已定义好的模型输出
:return: 定义好的模型
"""
model = tf.keras.Model(inputs, output)
return model
@tf.function
def printbar() -> None:
"""
自定义TensorFlow模型训练打印时间线。
:return: None
"""
ts = tf.timestamp()
today_ts = ts % (24 * 60 * 60)
hour = tf.cast(today_ts // 3600 + 8, tf.int32) % tf.constant(24)
minite = tf.cast((today_ts % 3600) // 60, tf.int32)
second = tf.cast(tf.floor(today_ts % 60), tf.int32)
def timeformat(m):
if tf.strings.length(tf.strings.format("{}", m)) == 1:
return(tf.strings.format("0{}", m))
else:
return(tf.strings.format("{}", m))
timestring = tf.strings.join([timeformat(hour), timeformat(minite), timeformat(second)], separator=":")
tf.print("==========" * 8, end="")
tf.print(timestring)
@tf.function
def train_step(model: tf.keras.Model,
features: Dict,
labels: tf.Tensor,
optimizer: tf.keras.optimizers.Optimizer,
loss_func: tf.keras.losses.Loss,
train_loss: tf.keras.metrics.Mean) -> None:
"""
训练步骤函数。这里也可以自定义更多的内容,比如将样本权重也写入dataset,这里获取权重来进行损失的计算。
:param model: 已定义好的模型
:param features: 遍历Dataset得到的特征
:param labels: 遍历Dataset得到的标签
:param optimizer: 优化器
:param loss_func: 损失函数
:param train_loss: 训练损失
:return:
"""
with tf.GradientTape() as tape:
predictions = model(features, training=True)
loss = loss_func(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss.update_state(loss)
@tf.function
def valid_step(model: tf.keras.Model,
features: Dict,
labels: tf.Tensor,
loss_func: tf.keras.losses.Loss,
valid_loss: tf.keras.metrics.Mean) -> None:
"""
验证步骤函数,与训练步骤同理,注意,必须设置training=False。
:param model: 已定义好的模型
:param features: 遍历Dataset得到的特征
:param labels: 遍历Dataset得到的标签
:param loss_func: 损失函数
:param valid_loss: 训练损失
:return:
"""
predictions = model(features, training=False)
batch_loss = loss_func(labels, predictions)
valid_loss.update_state(batch_loss)
def pipeline_train_model(model: tf.keras.Model,
ds_train: tf.data.Dataset,
ds_valid: tf.data.Dataset,
epochs: int,
optimizer: tf.keras.optimizers.Optimizer,
loss_func: tf.keras.losses.Loss,
train_loss: tf.keras.metrics.Mean,
valid_loss: tf.keras.metrics.Mean) -> None:
"""
模型训练pipeline,注意,这里只监测了训练损失和验证损失,也可以加入更多的自定义控制,比如Metric指标,比如根据patience进行学习率调度等。
:param model: 已定义好的模型
:param ds_train: 训练集
:param ds_valid: 验证集
:param epochs: 训练轮数
:param optimizer: 优化器
:param loss_func: 损失函数
:param train_loss: 训练损失
:param valid_loss: 验证损失
:return:
"""
best_metric = float('inf')
best_weights = None
patience = 0
for epoch in tf.range(1, epochs + 1):
for i, (features, labels) in enumerate(ds_train):
train_step(model, features, labels, optimizer, loss_func, train_loss)
for i, (features, labels) in enumerate(ds_valid):
valid_step(model, features, labels, loss_func, valid_loss)
logs = 'Epoch={}, Train Loss={}, Valid Loss={}'
printbar()
tf.print(tf.strings.format(logs, (epoch, train_loss.result(), valid_loss.result())))
tf.print()
if valid_loss.result() < best_metric:
best_metric = valid_loss.result()
best_weights = model.get_weights()
patience = 0
else:
patience += 1
if patience > 10:
model.set_weights(best_weights)
break
train_loss.reset_states()
valid_loss.reset_states()
def examples_training(model: tf.keras.Model,
ds_train: tf.data.Dataset,
ds_valid: tf.data.Dataset) -> None:
"""
一个关于模型训练的示例。
:param model: 已定义好的模型
:param ds_train: 训练集
:param ds_valid: 验证集
:return:
"""
tf.keras.backend.clear_session()
optimizer = tf.keras.optimizers.Adam()
loss_func = tf.keras.losses.Huber()
train_loss = tf.keras.metrics.Mean(name='train_loss')
valid_loss = tf.keras.metrics.Mean(name='valid_loss')
pipeline_train_model(model, ds_train, ds_valid, 100, optimizer, loss_func, train_loss, valid_loss)
model.save('./my_model/1', save_format='tf')
def plot_model(model: tf.keras.Model) -> None:
"""
画出模型结构图,便于进一步分析理解模型。
注意:需要安装pydot包和graphviz工具。
:param model: 已定义好的模型
:return:
"""
tf.keras.utils.plot_model(model, './my_model.png', show_shapes=True)
function_list = [
transform_by_hash, df_to_dataset, standard_num_feature, examples_define_model_inputs,
examples_define_feature_column, examples_define_model_layers, examples_define_model,
printbar, train_step, valid_step, pipeline_train_model, examples_training, plot_model
]
class TfCodeBestPractices:
@staticmethod
def get_examples():
return CodeExamples
@staticmethod
def get_source_code(code_exp: CodeExamples) -> None:
print(inspect.getsource(function_list[code_exp.value]))
@staticmethod
def show_all_functions():
print({
'哈希转换': 'transform_by_hash',
'构建dataset': 'df_to_dataset',
'数值特征标准化': 'standard_num_feature',
'模型输入定义示例': 'examples_define_model_inputs',
'特征列定义示例': 'examples_define_feature_column',
'模型层定义示例': 'examples_define_model_layers',
'模型定义示例': 'examples_define_model',
'自定义模型训练打印时间线': 'printbar',
'训练步骤函数': 'train_step',
'验证步骤函数': 'valid_step',
'模型训练pipeline': 'pipeline_train_model',
'模型训练示例': 'examples_training',
'画模型结构图': 'plot_model',
})
@staticmethod
def show_all_steps():
print('特征处理->数据集转dataset->拆分训练集及验证集->定义模型输入->定义特征列->定义模型层->定义模型->模型训练及保存')
if __name__ == '__main__':
tf_code_best_practice = TfCodeBestPractices()
code_examples = tf_code_best_practice.get_examples()
tf_code_best_practice.get_source_code(code_examples.pipeline_train_model)
tf_code_best_practice.show_all_functions()
tf_code_best_practice.show_all_steps()