背景:
有场景会出现因没有关注到,导致es-data的磁盘使用占用超过85%,es 集群的默认配置是当集群中的某个节点磁盘达到使用率为 85% 的时候,就不会在该节点进行创建副本,当磁盘使用率达到 90% 的时候,尝试将该节点的副本重分配到其他节点。当磁盘使用率达到95% 的时候,当前节点的所有索引将被设置为只读索引。
这种情况的处理一般是清理一些历史无用的索引,腾出空间,但此时执行curl -X DELETE 删除索引命令会报如下错误
{"error":{"root_cause":[{"type":"process_cluster_event_timeout_exception","reason":"failed to process cluster event (delete-index [[kube-system-logstash-2022.02.06/mvJWj2LORo-SCBDEMyRKvQ]]) within 30s"}],"type":"process_cluster_event_timeout_exception","reason":"failed to process cluster event (delete-index [[kube-system-logstash-2022.02.06/mvJWj2LORo-SCBDEMyRKvQ]]) within 30s"},"status":503}
此时,建议先找一下占用空间大的索引,在curl -X DELETE命令后加上一个比较大的超时时间,将空间腾出来之后,删索引就会正常,例如
curl -X DELETE -u admin:xxxxxxxxxx -k https://xx.xx.xx.xx:9200/system-nacos-logstash-2022.07.23?master_timeout=10m
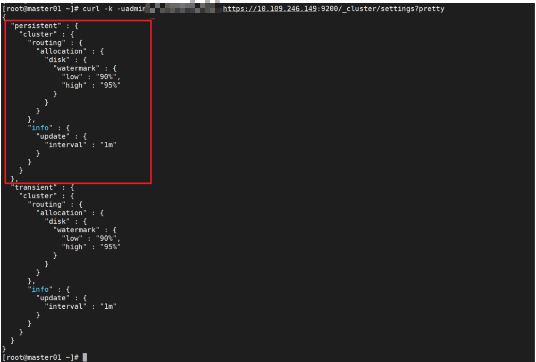
如果有需求可以将此限制调高,调整方式为通过 es 的 api 进行更改。transient 临时更改,persistent是永久更改。
api 接口 /_cluster/settings
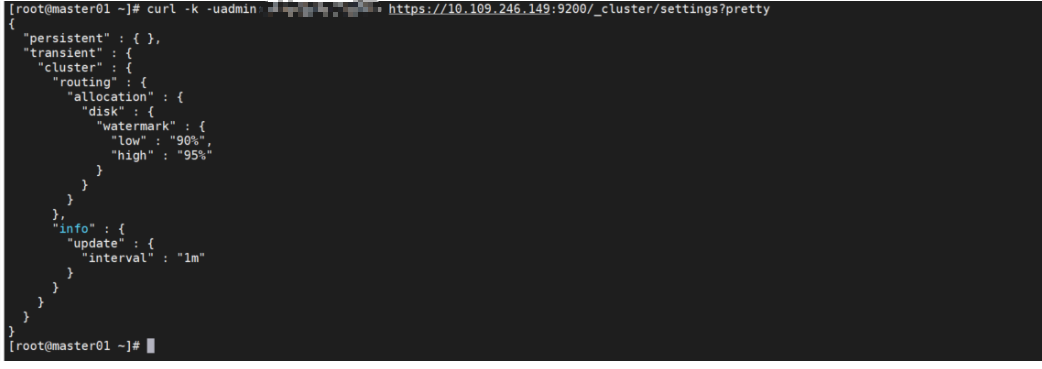
1、查看es 当前的配置
查看es 当前的配置 get 请求 /_cluster/settings
curl -k -uadmin:xxxxxxxxxxxxxx https://xx.xx.xx.xx:9200/_cluster/settings

2、更改配置
临时更改 transient重启后配置失效
{"transient":
{
"cluster.routing.allocation.disk.watermark.low": "90%",
"cluster.routing.allocation.disk.watermark.high": "95%",
"cluster.info.update.interval": "1m"
}
}
示例
curl -k -uadmin:xxxxxxxxxxxx -H "Content-Type: application/json" -XPUT https://10.109.246.149:9200/_cluster/settings -d ' {"transient": { "cluster.routing.allocation.disk.watermark.low": "90%", "cluster.routing.allocation.disk.watermark.high": "95%", "cluster.info.update.interval": "1m" } } '

永久更改 persistent重启后不失效。
{"persistent":
{
"cluster.routing.allocation.disk.watermark.low": "90%",
"cluster.routing.allocation.disk.watermark.high": "95%",
"cluster.info.update.interval": "1m"
}
}
#示例
curl -k -uadmin:xxxxxxxxx -H "Content-Type: application/json" -XPUT https://10.109.246.149:9200/_cluster/settings -d ' {"persistent": { "cluster.routing.allocation.disk.watermark.low": "90%", "cluster.routing.allocation.disk.watermark.high": "95%", "cluster.info.update.interval": "1m" } } '
二、fluentd日志积压严重处理
fluentd的配置文件kube-system 下的cm fluentd,中有关于缓冲区的配置,默认一般为20G,日志积压一旦超过20G,就会导致fluentd异常,无法写入
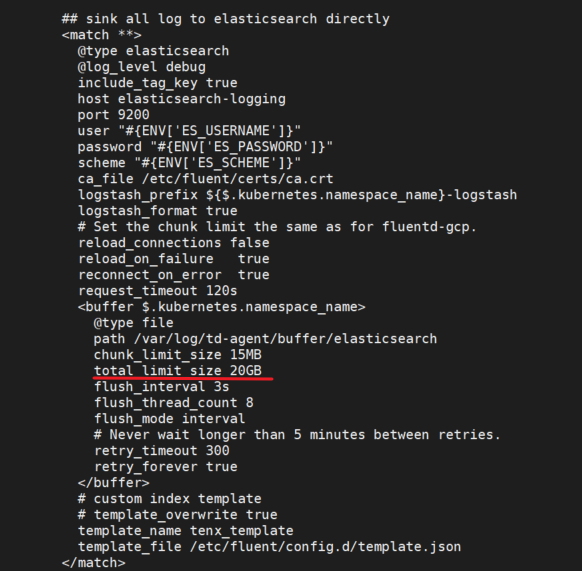
处理方法:
cd /var/log/td-agent/buffer/elasticsearch/ ls -lh |tail -100| awk '{print $9}' |xargs -i mv {} /root/linshi/
根据情况,将一部分缓冲区文件挪到一个其他目录,然后重启fluentd,让其正常写入es。
等到写完之后,再将移走的日志,重新放回缓冲区目录,再重启fluentd即可。