1. 从已有数据中创建数组
a. 将列表转换成 ndarray:
import numpy as np ls1 = [10, 42, 0, -17, 30] nd1 =np.array(ls1) print(nd1) print(type(nd1))
运行结果:
[ 10 42 0 -17 30] <class 'numpy.ndarray'>
b.嵌套列表可以转换成多维 ndarray:
import numpy as np ls2 = [[8, -2, 0, 34, 7], [6, 7, 8, 9, 10]] nd2 =np.array(ls2) print(nd2) print(type(nd2))
运行结果:
[[ 8 -2 0 34 7] [ 6 7 8 9 10]] <class 'numpy.ndarray'>
2. 利用 random 模块生成数组
几种 np.random 模块中常用的方法,如下表所示。

下面来看一些使用:
import numpy as np
import random
nd3 =np.random.random([4, 3]) #生成4行3列的数组
print(nd3)
print("nd3的形状为:",nd3.shape)
执行结果:
[[0.59115057 0.52022516 0.05992361] [0.5077815 0.81313999 0.70061259] [0.24654561 0.11705634 0.71399966] [0.73964407 0.57138345 0.89284498]] nd3的形状为: (4, 3)
为了每次生成同一份数据,可以指定一个随机种子,使用 shuffle() 函数打乱生成的随机数。

import numpy as np
np.random.seed(123)
nd4 = np.random.randn(4, 3)
print(nd4)
np.random.shuffle(nd4)
print("随机打乱后数据:")
print(nd4)
print(type(nd4))
执行结果:
[[-1.0856306 0.99734545 0.2829785 ] [-1.50629471 -0.57860025 1.65143654] [-2.42667924 -0.42891263 1.26593626] [-0.8667404 -0.67888615 -0.09470897]] 随机打乱后数据: [[-1.50629471 -0.57860025 1.65143654] [-2.42667924 -0.42891263 1.26593626] [-0.8667404 -0.67888615 -0.09470897] [-1.0856306 0.99734545 0.2829785 ]] <class 'numpy.ndarray'>
3. 创建特定形状的多维数组
参数初始化时,有时需要生成一些特殊矩阵,如全是 0 或 1 的数组或矩阵,这时我们可以利用 np.zeros、np.ones、np.diag 来实现,如下表所示。
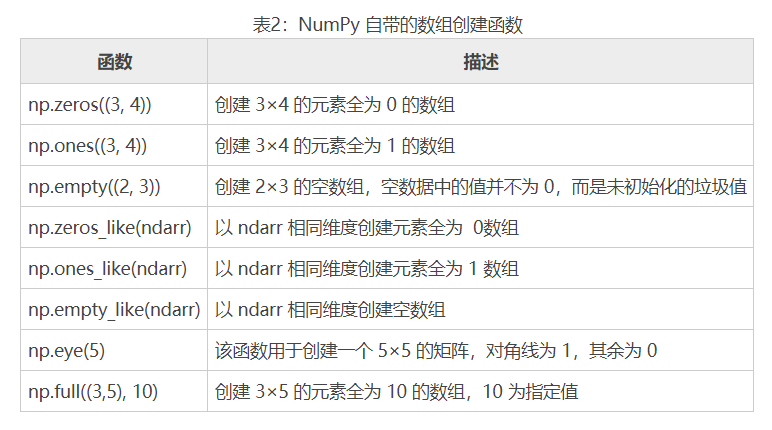
下面通过几个示例说明:
import numpy as np
# 生成全是 0 的 3x3 矩阵
nd5 =np.zeros([3, 3])
# 生成全是 1 的 3x3 矩阵
nd6 = np.ones([3, 3])
# 生成 4 阶的单位矩阵
nd7 = np.eye(4)
# 生成 4 阶对角矩阵
nd8 = np.diag([1, 8, 3, 10])
print("nd5 =\n", nd5)
print("nd6 =\n", nd6)
print("nd7 =\n", nd7)
print("nd8 =\n", nd8)
运行结果:
nd5 = [[0. 0. 0.] [0. 0. 0.] [0. 0. 0.]] nd6 = [[1. 1. 1.] [1. 1. 1.] [1. 1. 1.]] nd7 = [[1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]] nd8 = [[ 1 0 0 0] [ 0 8 0 0] [ 0 0 3 0] [ 0 0 0 10]]
有时还可能需要把生成的数据暂时保存到文件中,以备后续使用。
import numpy as np
nd9 =np.random.random([3, 5])
np.savetxt(X=nd9, fname='./data.txt')
nd10 = np.loadtxt('./data.txt')
print(nd10)
运行结果:
[[0.1744383 0.15515217 0.74885812 0.57633094 0.06300636] [0.24340527 0.65213913 0.07284238 0.52232677 0.58538849] [0.83611286 0.76508018 0.26018483 0.20485587 0.95476232]]
打开当前目录下的 data.txt 也可以看到格式化的数据。
4. 利用 arange() 和 linspace() 函数生成数组
arange() 是 numpy 模块中的函数,其格式为:
arange([start,] stop[,step,], dtype=None)
其中,start 与 stop 用来指定范围,step 用来设定步长。在生成一个 ndarray 时,start 默认为0,步长 step 可为小数。Python 有个内置函数 range,其功能与此类似。
import numpy as np print(np.arange(10)) print(np.arange(0, 10)) print(np.arange(1, 4, 0.5)) print(np.arange(9, -1, -1))
运行结果:
[0 1 2 3 4 5 6 7 8 9] [0 1 2 3 4 5 6 7 8 9] [1. 1.5 2. 2.5 3. 3.5] [9 8 7 6 5 4 3 2 1 0]
linspace() 也是 numpy 模块中常用的函数,其格式为:
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
linspace() 可以根据输入的指定数据范围以及等份数量,自动生成一个线性等分向量,其中 endpoint(包含终点)默认为 True,等分数量 num 默认为 50。如果将 retstep 设置为True,则会返回一个带步长的 ndarray。
import numpy as np print(np.linspace(0, 1, 10))
运行结果:
[0. 0.11111111 0.22222222 0.33333333 0.44444444 0.55555556 0.66666667 0.77777778 0.88888889 1. ]
<2>. numpy中数组元素的获取
在 NumPy 中,既可以获取 ndarray 数组的单个元素,也可以获取一组元素(也即切片),这与 Python 中的列表(list)和元组(tuple)非常类似。
import numpy as np np.random.seed(2019) nd1 = np.random.random([10]) # 获取指定位置的数据, 获取第4个元素 nd1[3] #截取一段数据 nd1[3:6] # 截取固定间隔数据 nd1[1:6:2] # 倒序取数 nd1[::-2] # 截取一个多维数组的一个区域内数据 nd2=np.arange(25).reshape([5,5]) nd2[1:3,1:3] # 截取一个多维数组中, 数值在一个值域之内的数据 nd2[(nd2>3)&(nd2<10)] # 截取多维数组中, 指定的行,如读取第2,3行 nd2[[1,2]] #或nd12[1:3,:] # 截取多维数组中, 指定的列,如读取第2,3列 nd2[:,1:3]
获取数组中的部分元素除了通过指定索引标签来实现外,还可以通过使用一些函数来实现,如通过random.choice函数从指定的样本中随机抽取数据。
import numpy as np from numpy import random as nr a=np.arange(1,25,dtype=float) c1=nr.choice(a,size=(3,4)) #size指定输出数组形状 c2=nr.choice(a,size=(3,4),replace=False) #replace缺省为True, 即可重复抽取。 #下式中参数p指定每个元素对应的抽取概率, 缺省为每个元素被抽取的概率相同。 c3=nr.choice(a,size=(3,4),p=a / np.sum(a)) print("随机可重复抽取") print(c1) print("随机但不重复抽取") print(c2) print("随机但按制度概率抽取") print(c3)
结果如下:
随机可重复抽取 [[ 7. 22. 19. 21.] [ 7. 5. 5. 5.] [ 7. 9. 22. 12.]] 随机但不重复抽取 [[ 21. 9. 15. 4.] [ 23. 2. 3. 7.] [ 13. 5. 6. 1.]] 随机但按制度概率抽取 [[ 15. 19. 24. 8.] [ 5. 22. 5. 14.] [ 3. 22. 13. 17.]]
<3>. NumPy的算术运算
a.对应元素相乘
对应元素相乘(Element-Wise Product)是两个矩阵中对应元素乘积。np.multiply() 函数用于数组或矩阵对应元素相乘,输出与相乘数组或矩阵的大小一致
>>> A = np.array([[1, 2], [-1, 4]])
>>> B = np.array([[2, 0], [3, 4]])
>>> A*B
array([[ 2, 0],
[-3, 16]])
>>> np.multiply(A, B)
array([[ 2, 0],
[-3, 16]])
b.点积运算
点积运算(Dot Product)又称为内积,在 NumPy 中用 np.dot() 函数表示
X1=np.array([[1,2],[3,4]]) X2=np.array([[5,6,7],[8,9,10]]) X3=np.dot(X1,X2) print(X3)
运行结果:
[[21 24 27] [47 54 61]]
<3>. NumPy数组的变形
修改指定数组的形状是 NumPy 中最常见的操作之一,常见的方法有很多,下表列出了一些常用函数和属性。

reshape() 函数用来改变向量的维度(不修改向量本身),请看下面的代码:
import numpy as np arr =np.arange(10) print(arr) # 将向量 arr 维度变换为2行5列 print(arr.reshape(2, 5)) # 指定维度时可以只指定行数或列数, 其他用 -1 代替 print(arr.reshape(5, -1)) print(arr.reshape(-1, 5))
运行结果:
[0 1 2 3 4 5 6 7 8 9] [[0 1 2 3 4] [5 6 7 8 9]] [[0 1] [2 3] [4 5] [6 7] [8 9]] [[0 1 2 3 4] [5 6 7 8 9]]
resize() 函数用来改变向量的维度(修改向量本身),请看下面的代码:
import numpy as np arr =np.arange(10) print(arr) # 将向量 arr 维度变换为2行5列 arr.resize(2, 5) print(arr)
运行如下:
[0 1 2 3 4 5 6 7 8 9] [[0 1 2 3 4] [5 6 7 8 9]]
<4>. NumPy ndarray合并数组
在 NumPy 中,合并数组也是最常见的操作之一,下表列举了常见的用于数组或向量合并的方法
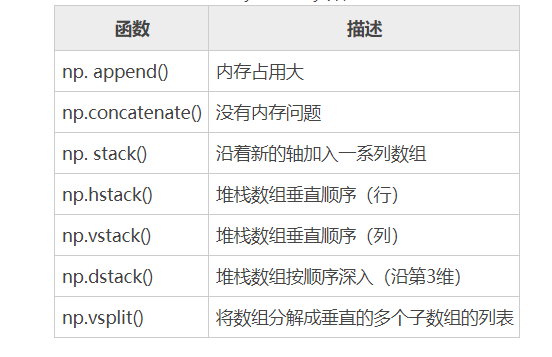
几点说明:
- append()、concatenate() 以及 stack() 都有一个 axis 参数,用于控制数组的合并方式是按行还是按列。
- 对于 append() 和 concatenate(),待合并的数组必须有相同的行数或列数(满足一个即可)。
- stack()、hstack()、dstack() 要求待合并的数组必须具有相同的形状(shape)
下面选择一些常用函数进行说明。
append() 函数可以合并一维数组:
import numpy as np a =np.array([1, 2, 3]) b = np.array([4, 5, 6]) c = np.append(a, b) print(c) # [1 2 3 4 5 6]
append() 也可以合并多维数组:
import numpy as np
a =np.arange(4).reshape(2, 2)
b = np.arange(4).reshape(2, 2)
# 按行合并
c = np.append(a, b, axis=0)
print('按行合并后的结果')
print(c)
print('合并后数据维度', c.shape)
# 按列合并
d = np.append(a, b, axis=1)
print('按列合并后的结果')
print(d)
print('合并后数据维度', d.shape)
运行如下:
按行合并后的结果 [[0 1] [2 3] [0 1] [2 3]] 合并后数据维度 (4, 2) 按列合并后的结果 [[0 1 0 1] [2 3 2 3]] 合并后数据维度 (2, 4)
concatenate() 沿指定轴连接数组或矩阵:
import numpy as np a =np.array([[1, 2], [3, 4]]) b = np.array([[5, 6]]) c = np.concatenate((a, b), axis=0) print(c) d = np.concatenate((a, b.T), axis=1) print(d)
运行如下:
[[1 2] [3 4] [5 6]] [[1 2 5] [3 4 6]]
stack() 沿指定轴堆叠数组或矩阵:
import numpy as np a =np.array([[1, 2], [3, 4]]) b = np.array([[5, 6], [7, 8]]) print(np.stack((a, b), axis=0))
运行如下:
[[[1 2] [3 4]] [[5 6] [7 8]]]
<5>.NumPy ufunc通用函数
NumPy 的 Universal functions 中要求输入的数组 shape 是一致的,当数组的 shape 不相等时,则会使用广播机制。
不过,调整数组使得 shape 一样,需要满足一定的规则,否则将出错。
这些规则可归纳为以下 4 条。
1) 让所有输入数组都向其中 shape 最长的数组看齐,不足的部分则通过在前面加 1 补齐

2) 输出数组的 shape 是输入数组 shape 的各个轴上的最大值。
3) 如果输入数组的某个轴和输出数组的对应轴的长度相同或者某个轴的长度为 1 时,这个数组能被用来计算,否则出错。
4) 当输入数组的某个轴的长度为 1 时,沿着此轴运算时都用(或复制)此轴上的第一组值。
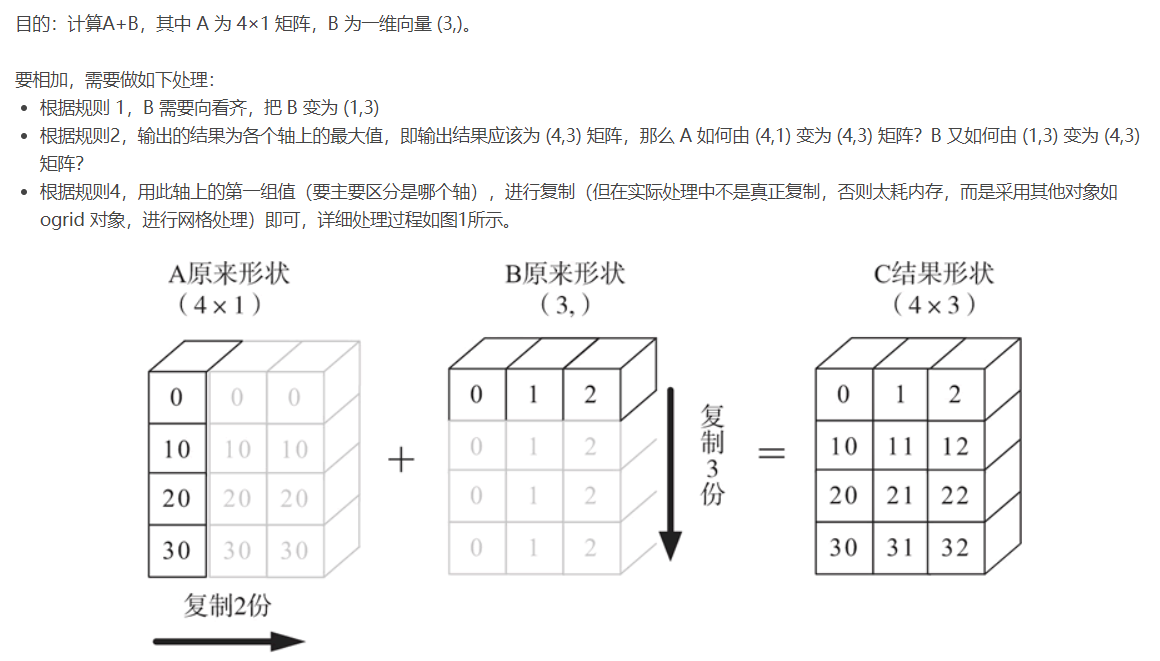
import numpy as np
A = np.arange(0, 40,10).reshape(4, 1)
B = np.arange(0, 3)
print("A矩阵的形状:{},B矩阵的形状:{}".format(A.shape,B.shape))
C=A+B
print("C矩阵的形状:{}".format(C.shape))
print(C)
运行如下:
A矩阵的形状:(4, 1),B矩阵的形状:(3,) C矩阵的形状:(4, 3) [[ 0 1 2] [10 11 12] [20 21 22] [30 31 32]]