前言 现有的语义分割工作主要集中在设计有效的解-码器上,然而,一直以来都忽略了这其中的计算成本。本文提出了一种专门用于语义分割的 Head-Free 轻量级架构,称为 Adaptive Frequency Transformer (AFFormer) 。采用异构运算符(CNN 和 ViT)进行像素嵌入和原型表示,以进一步节省计算成本。由于语义分割对频率信息非常敏感,构建了一个具有复杂度 O(n) 的自适应频率滤波器的轻量级模块。
在 ADE20K 和 Cityscapes 数据集上,AFFormer 实现了比现有方法更高的精度和更低的参数量。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

论文:https://arxiv.org/pdf/2301.04648.pdf
代码:https://github.com/dongbo811/AFFormer
论文出发点
以前的语义分割方法侧重于使用分类网络作为 backbone 来提取多尺度特征,并设计一个复杂的解码器 head 来建立多尺度特征之间的关系。然而,这些改进是以模型尺寸大和计算成本高为代价的。这使得作者思考:语义分割是否可以像图像分类一样简单?
同时,由于ViT在语义分割方面性能显著,但当部署在超低计算能力的设备上时,它们面临着平衡性能和内存使用的挑战,并且它在空间域中的计算复杂度为 O(n2)。一些方法通过减小 tokens 数量等降低复杂度。这促使本文提出了另一个问题:能否设计一个高效、轻量级的 Transformer 网络用于超低计算场景下的语义分割?
创新思路
作者提出了一种无头轻量级语义分割特定架构,使用金字塔结构降低分辨率以探索语义并降低计算成本,并采用并行架构,利用原型表示作为特定的可学习局部描述,取代解码器并在高分辨率特征上保留丰富的图像语义。并行结构通过去除解码器压缩了大部分计算。此外,对像素嵌入特征和局部描述特征采用异构算子,并构建了一个复杂度为 O(n) 的轻量级自适应频率滤波器作为原型学习。该模块的核心由频率相似核、动态低通滤波器和动态高通滤波器组成,分别从强调重要频率成分和动态过滤频率的角度捕捉有利于语义分割的频率信息。最后,通过在高频和低频提取和增强模块中共享权重进一步降低了计算成本。在前馈网络 (FFN) 层中嵌入了一个简化的深度卷积层,以增强融合效果,减少两个矩阵变换的大小。
方法
整体架构
AFFormer 的总体框架如下图所示,首先对 patch embedding 后的特征进行聚类,得到原型特征 G,从而构建一个并行网络结构,其中包含两个异构算子。基于 Transformer 的模块作为原型学习以捕获 G 中有利的频率分量,从而产生原型表示 G‘。最后, G‘ 由基于 CNN 的像素描述符恢复,为下一阶段生成特征。
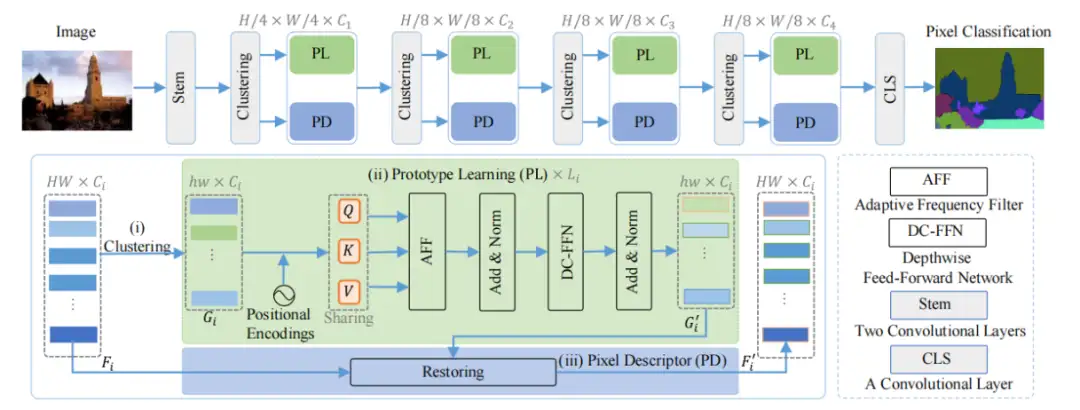
并行异构架构语义解码器将编码器获得的图像语义传播到每个像素,并恢复下采样中丢失的细节。一种直接的替代方法是在高分辨率特征中提取图像语义,但它会引入大量计算,尤其是对于视觉 Transformers。相比之下,这里提出了一种用原型语义描述像素语义信息的新策略。首先初始化一个网格作为图像原型,将网格中的每个点作为局部簇中心,然后在其区域内进行加权初始化。然后使用基于 Transformer 的模块作为原型学习来更新每个聚类中心。自适应频率滤波器
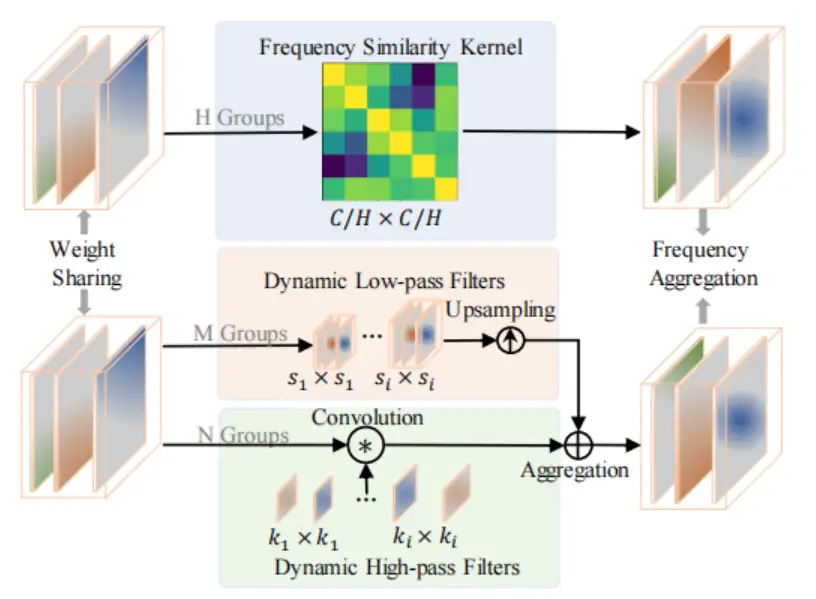
频率表示可以作为学习类别间差异的新范式,在网格中提取更多有益频率有助于区分每个聚类的属性,直接的方法是将空间域特征通过傅里叶变换转化为频谱特征,在频域使用简单的 mask filter 增强或减弱频谱的每个频率分量的强度。然后将提取的频率特征通过傅里叶逆变换转换到空间域。本文设计了一个基于 vanilla vision Transformer 的自适应频率滤波器块(如下图),从频谱相关性的角度来直接在空间域中捕获重要的高频和低频特征。
结果
作者在三个公开数据集上验证了 AFFormer:ADE20K、Cityscapes 和 COCO-stuff 。
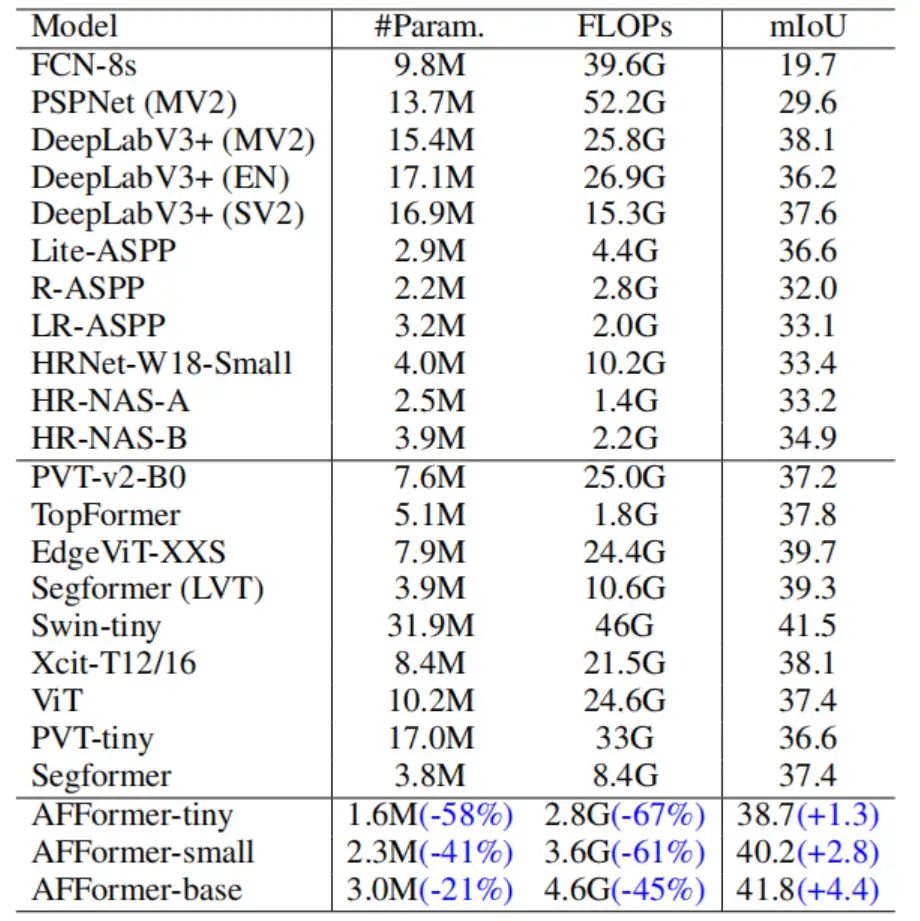
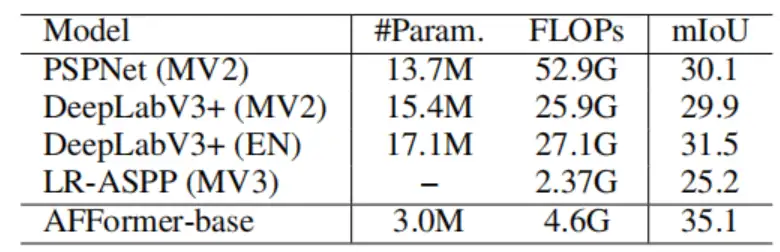
首先是在 ADE20K 数据集上的对比:
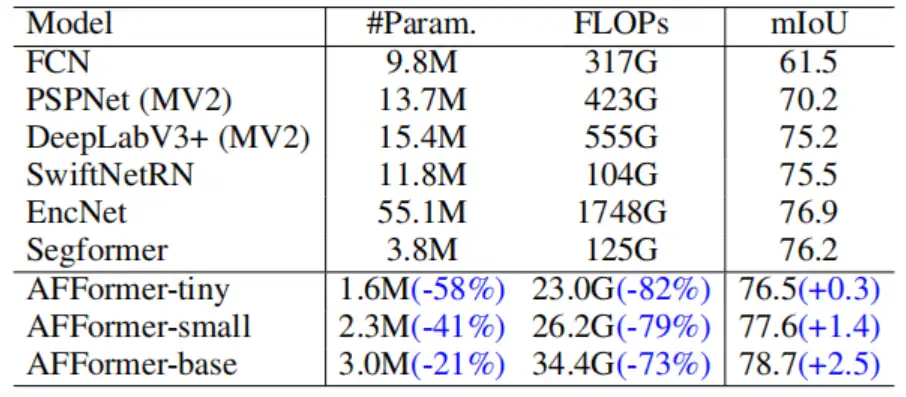
随后是在 Cityscapes 数据集上与先进方法的对比:
再是在 COCO-stuff 数据集上的比较:
总结
这篇论文的核心是从频率角度学习聚类原型的局部描述表示,而不是直接学习所有像素嵌入特征,在具有线性复杂度Transformer的同时去掉了复杂的decoder,实现了像正则分类一样简单的语义分割,以低计算成本拥有强大的准确性和稳定性和鲁棒性。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
AAAI 2023 | 轻量级语义分割新范式: Head-Free 的线性 Transformer 结构
TSCD:弱监督语义分割新方法,中科院自动化所和北邮等联合提出
如何用单个GPU在不到24小时的时间内从零开始训练ViT模型?
CVPR 2023 | 基于Token对比的弱监督语义分割新方案!
比MobileOne还秀,Apple将重参数与ViT相结合提出FastViT
CVPR 2023 | One-to-Few:没有NMS检测也可以很强很快
ICLR 2023 | Specformer: Spectral GNNs Meet Transformers
AAAI 2023 | 打破NAS瓶颈,AIO-P跨任务网络性能预测新框架
目标检测Trick | SEA方法轻松抹平One-Stage与Two-Stage目标检测之间的差距
CVPR 2023 | 标注500类,检测7000类!清华大学等提出通用目标检测算法UniDetector
CVPR 2023 | 超越MAE!谷歌提出MAGE:图像分类和生成达到SOTA!
CVPR2023 | 书生模型霸榜COCO目标检测,研究团队解读公开
Vision Transformer的重参化也来啦 | RepAdpater让ViT起飞
高效压缩99%参数量!轻量型图像增强方案CLUT-Net开源
一文了解 CVPR 2023 的Workshop 都要做什么
CVPR'23 最新 70 篇论文分方向整理|包含目标检测、图像处理、人脸、医学影像、半监督学习等方向
目标检测无痛涨点新方法 | DRKD蒸馏让ResNet18拥有ResNet50的精度
CVPR2023最新Backbone | FasterNet远超ShuffleNet、MobileNet、MobileViT等模型
CVPR2023 | 集成预训练金字塔结构的Transformer模型
AAAI 2023 | 一种通用的粗-细视觉Transformer加速方案