1. k-Medoids
之前的kmeans算法 对于异常点数据特别敏感,更新中心点的时候,是对于该簇的所有样本点求平均,这种方式对于异常样本特别敏感,

kmedoids算法克服这个问题,实现方式所有属于该簇的样本点每一个维度 取中位数 这样得到新的中心点 就对于异常点没那么敏感了
总结:更新中心点的方法 由求平均改成求中位数
2. 二分KMEANS
为克服K-Means算法收敛于局部最小值问题,提出了二分K-Means算法
- 使用以前的KMEANS算法 k=2, 得到两个簇,两个中心点,
- 选取其中的一个簇,再使用k=2的KMEANS算法,相比上一步,只不过输入的样本换一下而已,选取其中的一个簇,根据一定的指标来选,例如:样本数量大的,需进行再分,或者 SSE总误差更大的
- 重复步骤,直到分类的总数等于目标分类数
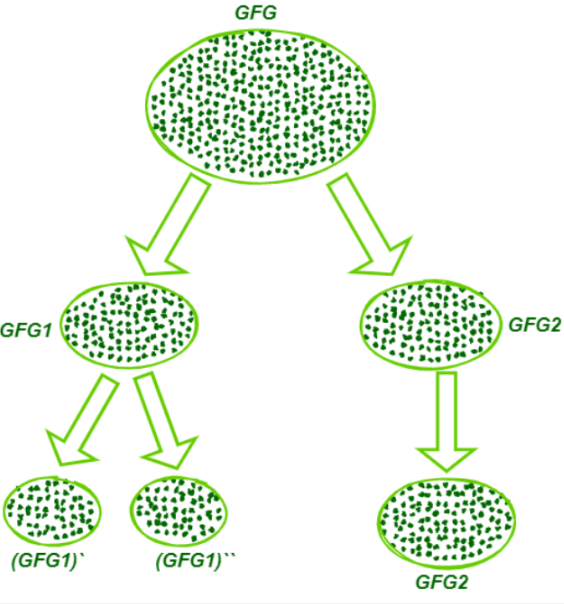
总结:每次分两个簇,选择其中一个簇再分成两个,直到分类的总数=k
3. KMeans++
KMeans++ 与KMeans的不同就是在初始中心点的选取上不同,初始中心点的选取会直接影响算法的收敛,容易只得到局部最优,所以初始中心点的选取就要尽量的相离的分散,如何实现
- 随机选取一个中心点
- 计算其他点到 已知中心点 中最近邻的的距离 根据这个距离 来选择他是否能做为下一个中心点,被选择的概率和计算出来的距离成正比
- 重复2 直到k个中心被选中
实现方式伪代码:
- 已知的中心点 c1, c2, c3
- 对于剩余的样本点 x4,x5,--- ,xn,
拿x4来说: min(d(c1, x4), d(x2, x4), d(c3,x4)) 得到x4 距离已知中心点的最近邻距离 记为 dist4, 依次得到 dist5, ---, distn
将这距离进行归一化操作, 记sum=sum(dist4, dist5, ---, distn)
(dist4, dist5, ---, distn)/sum 记为 (p4, p5, p6, ,,, pn)
将这些距离画在数轴上

np.random.rand() 0-1之间随机的取一个数,看下它落在数轴上的那个位置,则那个样本点就被选中,这也就是为什么距离远远的点越容易被选中。
4. elkan KMeans
由于计算每个样本到 类中心 的距离比较耗时
对于x样本 是属于b中心点还是c中心点 只需要作出判断 不需要全部计算出
利用两边之和大于第三边
假设x是一个点,b和c是中心点


bx 肯定是小于bc x点肯定是分类到b
elkan K-Means比起传统的K-Means迭代速
度有很大的提高。但是如果我们的样本的特征是稀疏的,有缺失值的话,这个方法就不使用了,此时某些距离无法计算,则不能使用该算法
5. min batch KMeans算法
KMeans算法 对所有的样本点 通过计算距离最近 将其划分到对应类 这样会特别耗时
能否只抽取部分的样本 计算距离最近 将其划分到对应类 输出新的中心点
这就叫做mini batch KMeans
与批量梯度下降法 计算梯度类似,计算梯度的时候也只使用部分样本 只要能大致的指明梯度的方向就行 不需要完全精确计算出梯度
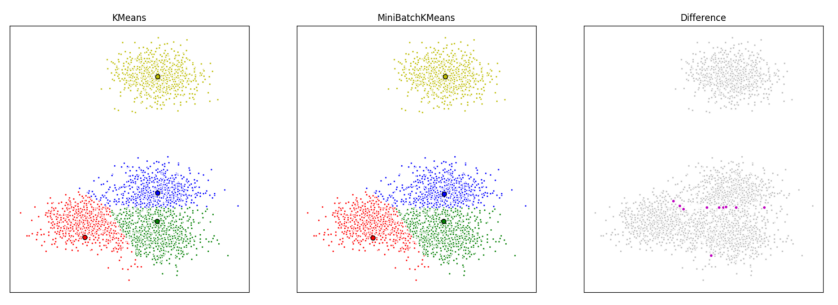
6.小结:
原理比较简单,实现也是很容易,收敛速度快(在大规模数据集上收敛较慢,可尝试使用Mini
Batch K-Means算法)。
1 原理比较简单,实现也是很容易,收敛速度快(在大规模数据集上收敛较慢,可尝试使用MiniBatch K-Means算法)
2 聚类效果较优。
3 算法的可解释度比较强。
4 主要需要调参的参数仅仅是簇数k。
缺点:
